大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺

 

图片来自电影’Quo Vadis'(拉丁语, 何去何从)(1951)。
在发生什么? 这些演员正要亲吻对方,还是已经这样做了?
《你往何处去?Quo Vadis?》, 这部完成于一八九六年的著作,史诗般的重现了使徒时期罗马皇帝尼禄残害基督徒,基督教经过殉道后而兴起的历史。大师显克维奇也因此书在历史小说中的卓越贡献,1905年力挫大文豪托尔斯泰获得诺贝尔文学奖。
背景介绍
什么是动作识别?
动作识别的主要目标是判断一段视频中人的行为的类别,所以也可以叫做 Human Action Recognition。
动作识别的难点在哪里?
(1)类内和类间差异, 同样一个动作,不同人的表现可能有极大的差异。
(2)环境差异, 遮挡、多视角、光照、低分辨率、动态背景.
(3)时间变化, 人在执行动作时的速度变化很大,很难确定动作的起始点,从而在对视频提取特征表示动作时影响最大。
(4)缺乏标注良好的大的数据集
有那些解决方法?
最好的传统的方法? iDT
当前的深度学习的方法?
- RGB + 光流
- 3D卷积
- lstm + 单帧
- skeleton(数据集缺乏)
概述
单帧的潜力有多大?
单帧的潜力结束后, 运动(多帧的信息)怎么获取?
数据集

The HMDB-51 dataset(2011)
Brown university 大学发布的 HMDB51, 视频多数来源于电影,还有一部分来自公共数据库以及YouTube等网络视频库.数据库包含有6849段样本,分为51类,每类至少包含有101段样本。
UCF-101(2012)
来源为YouTube视频,共计101类动作,13320段视频。共有5个大类的动作:
1)人-物交互;2)肢体运动;3)人-人交互;4)弹奏乐器;5)运动.
[Sport-1M(2014)] (https://cs.stanford.edu/people/karpathy/deepvideo/)
Sports1M 包含487类各项运动, 约110万个视频. 此外,Sports1M 的视频长度平均超过 5 分钟,而标签预测的动作可能仅在整个视频的很小一部分时间中发生。 Sports1M 的标注通过分析和 youtube视频相关的文本元数据自动地生成,因此是不准确的。
Kinetics-600是一个大规模,高质量的YouTube视频网址数据集,其中包括各种人的行动。
该数据集由大约50万个视频剪辑组成,涵盖600个人类行为类,每个行为类至少有600个视频剪辑。每个剪辑持续约10秒钟,并标记一个类。所有剪辑都经过了多轮人工注释,每个剪辑都来自单独的YouTube视频。这些行为涵盖了广泛的类别,包括人与物体的互动,如演奏乐器,以及人与人之间的互动,如握手和拥抱。
算法
光流
光流是视觉领域的一个独立分支
光流通常被表述为估计世界真实三维运动的二维投影的问题。
In spite of the fast computation time (0.06s for a pair of frames),
 

(a)(b) 视频中的连续的两帧, (c) 蓝绿色框中的光流信息, (d) 位移向量的水平信息, (e) 位移向量的垂直信息;
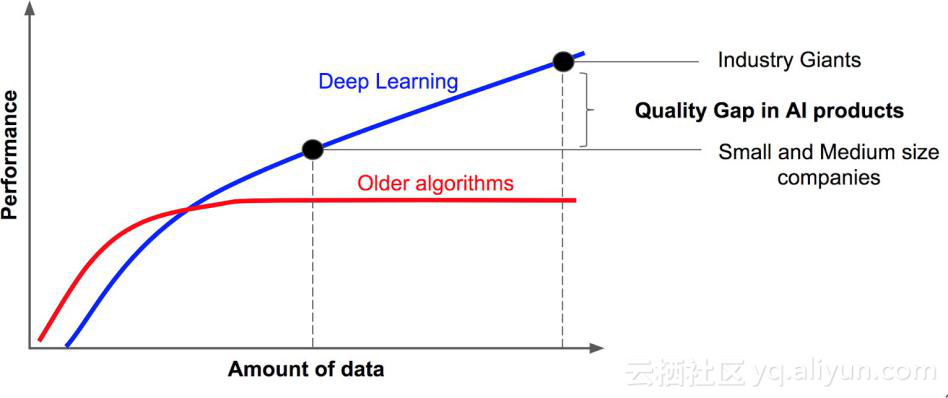
iDT
iDT(13年)(improved dense trajectories(轨迹))
iDT 方法(是深度学习进入该领域前效果最好,稳定性最好,可靠性最高的方法,不过算法速度很慢(在于计算光流速度很慢)。
基本思路为利用光流场来获得视频序列中的一些轨迹,再沿着轨迹提取HOF,HOG,MBH,trajectory4种特征,其中HOF基于灰度图计算,另外几个均基于dense optical flow(密集光流)计算。最后利用FV(Fisher Vector)方法对特征进行编码,再基于编码结果训练SVM分类器。
早期尝试
Large-scale Video Classification with Convolutional Neural Networks(2014)
2DCNN, 能不能自动的捕捉运动信息?
- single frame
- stacked frames
双流法
迁移学习
- 最后一层(或者最后L层)
- fine-tune 所有层(小学习率)
Two-Stream Convolutional Networks for Action Recognition in Videos(2014)
双流架构:
- 空域网络(spatial networks)
- 时域网络(temporal networks)
理论支撑: 双流体系结构与双流假设相关,即人类视觉皮层包含两条路径, 如下
- 腹侧流(ventral stream, 执行物体识别)
- 背侧流(dorsal stream, 识别运动信息)
将空时网络解耦的好处:
时域网络可以使用预训练的 ImageNet 上预训练的模型.
 

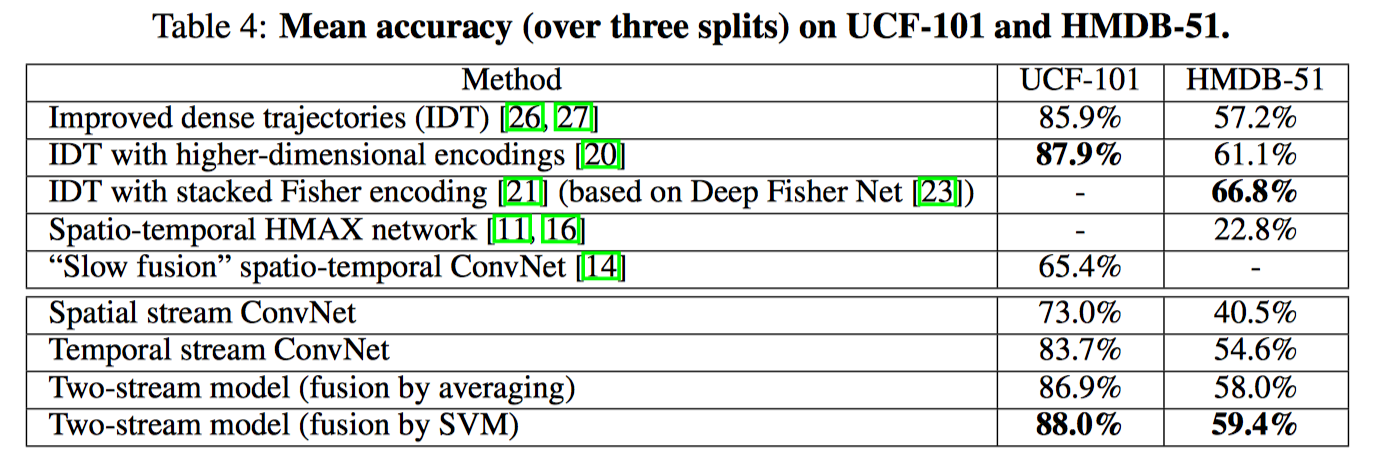 

TSN: Temporal Segment Networks: Towards Good Practices for Deep Action Recognition(2016)
光流的作用
On the Integration of Optical Flow and Action Recognition(2017) (2018CVPR)
大多数表现优秀的动作识别算法使用光流作为“黑匣子”输入。 在这里,我们更深入地考察光流与动作识别的结合,并研究为什么光流有帮助, 光流算法对动作识别有什么好处,以及如何使其更好。
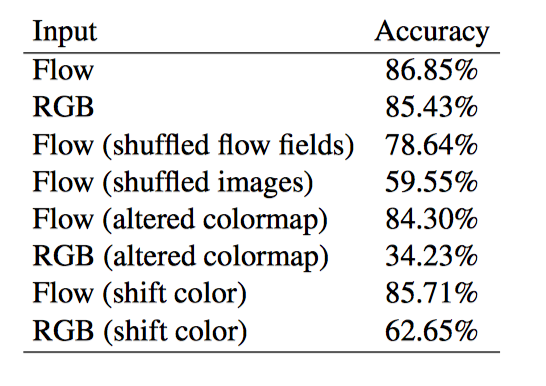 

实验结果表明: 当前体系结构中光流的大部分价值在于它对场景表示的表观不变(invariant to appearance), 也表明运动轨迹不是光流成功的根源,并且建立有用的运动表示仍然是光流自身无法解决的一个悬而未决的问题。
由于光流是从图像序列计算出来的,所以有人可能会争辩说,训练有素的网络可以学习如何计算光流,如果光流是有用的,则不需要明确计算光流。
尽管使用显式运动估计作为涉及视频任务的输入可能看起来很直观,但人们可能会争辩说使用运动并不是必需的。 一些可能的论点是,当前数据集中的类别可以从单帧中识别出来,并且可以从单帧中识别视觉世界中更广泛的许多对象和动作.
C3D
Learning Spatiotemporal Features with 3D Convolutional Networks(2015)
3D 卷积
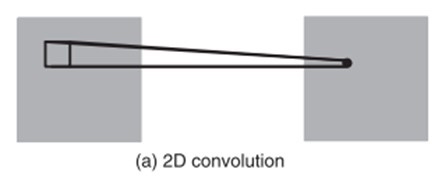 

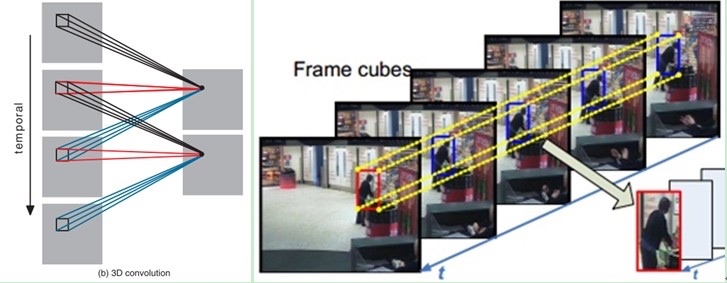 

C3D
能把 ImageNet 的成功(迁移学习)复制到视频领域吗?
 

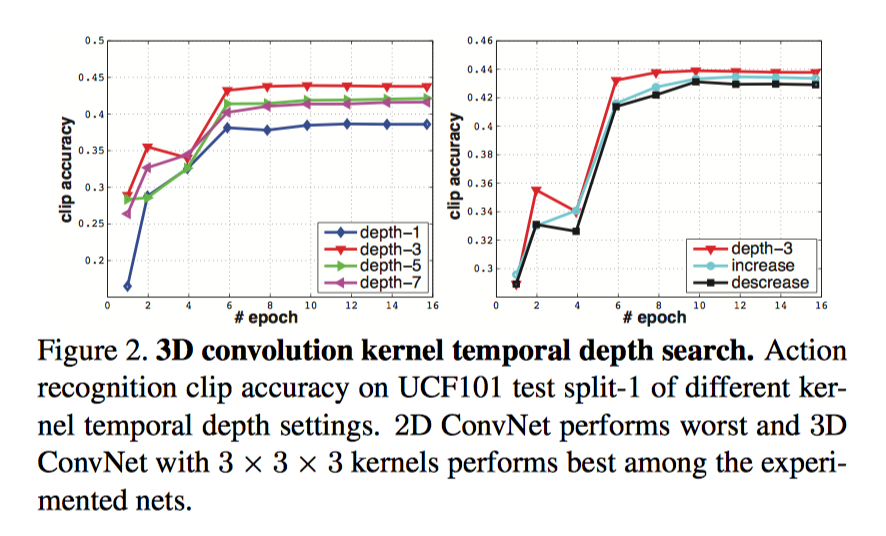 

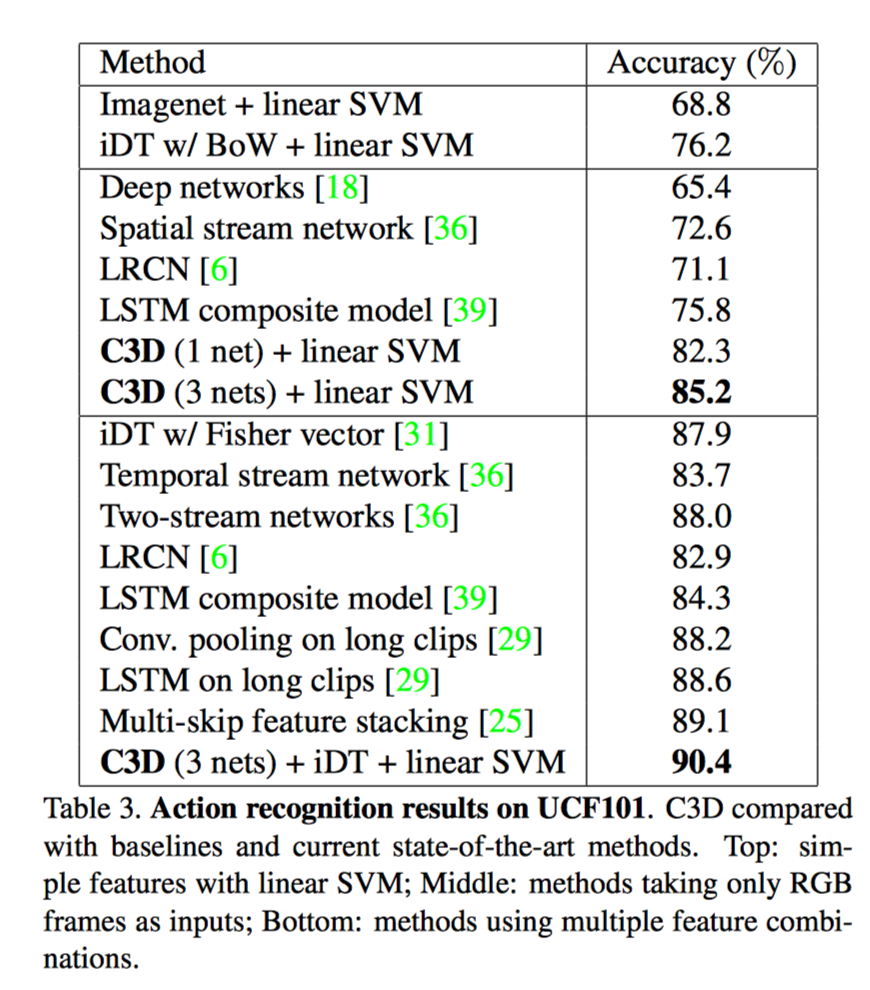 

速度
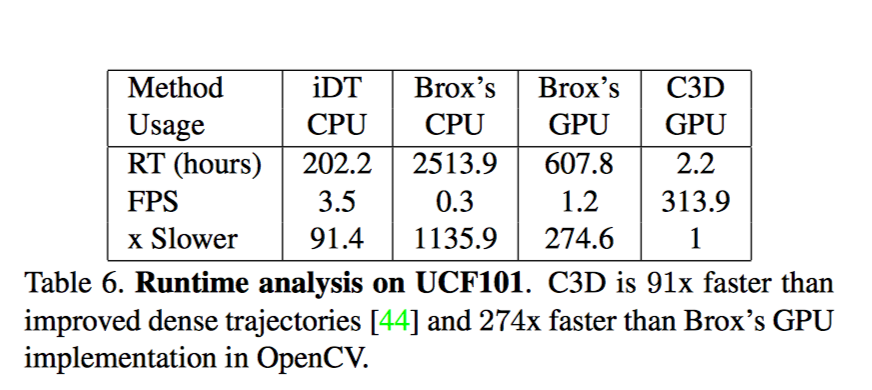 

iDT官方提供的计算法方法没有 GPU 版本
Brox一种计算光流的方法; 包括 I/O 时间, 平均一组图片的光流计算时间为0.85-0.9s
I3D(Two-Stream Inflated 3D ConvNet)
动作在单个帧中可能不明确,然而, 现有动作识别数据集的局限性意味着性能最佳的视频架构不会明显偏离单图分析,因为他们依赖在ImageNet上训练的强大图像分类器。
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
数据集: Kinetics
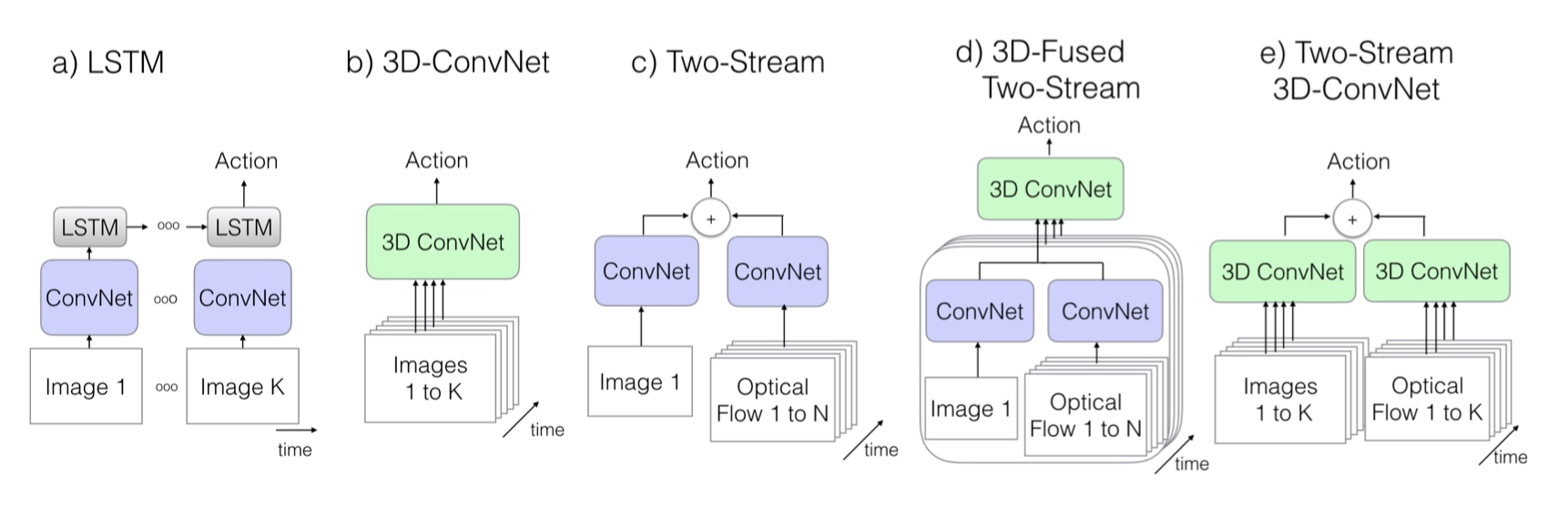 

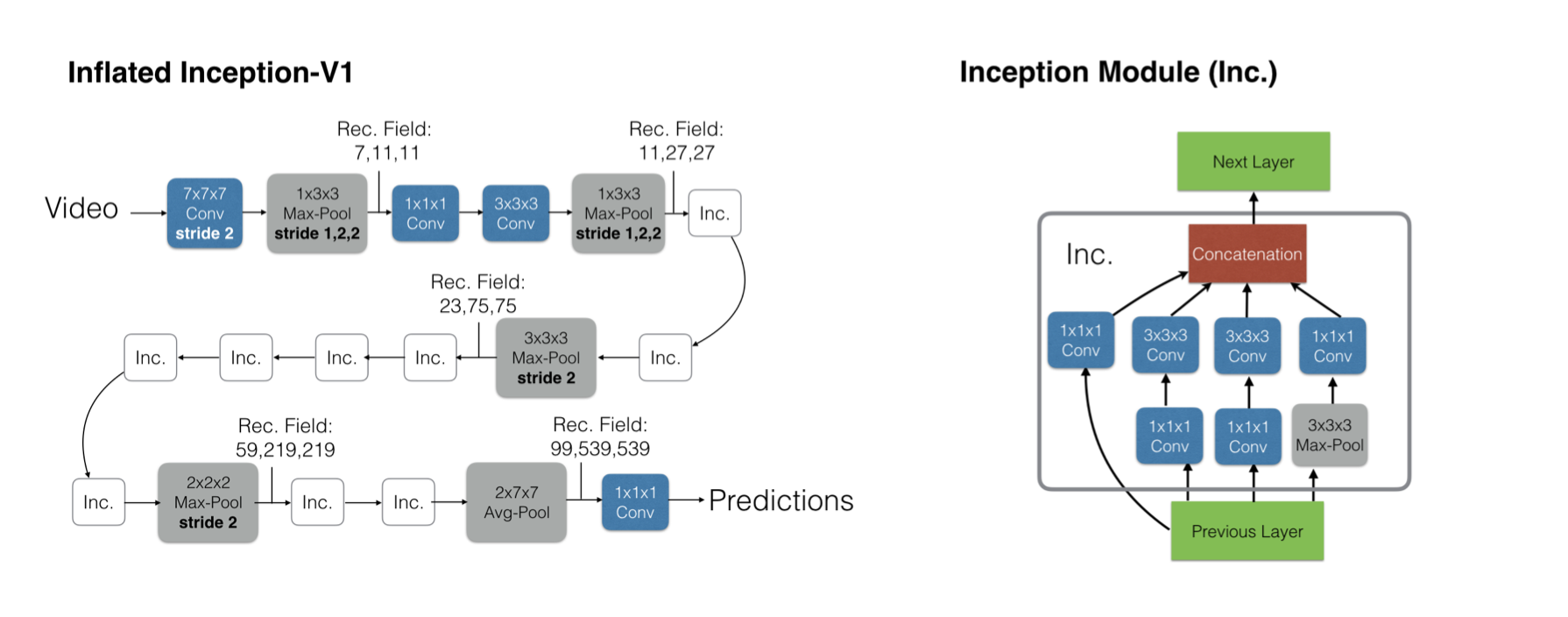
网络架构

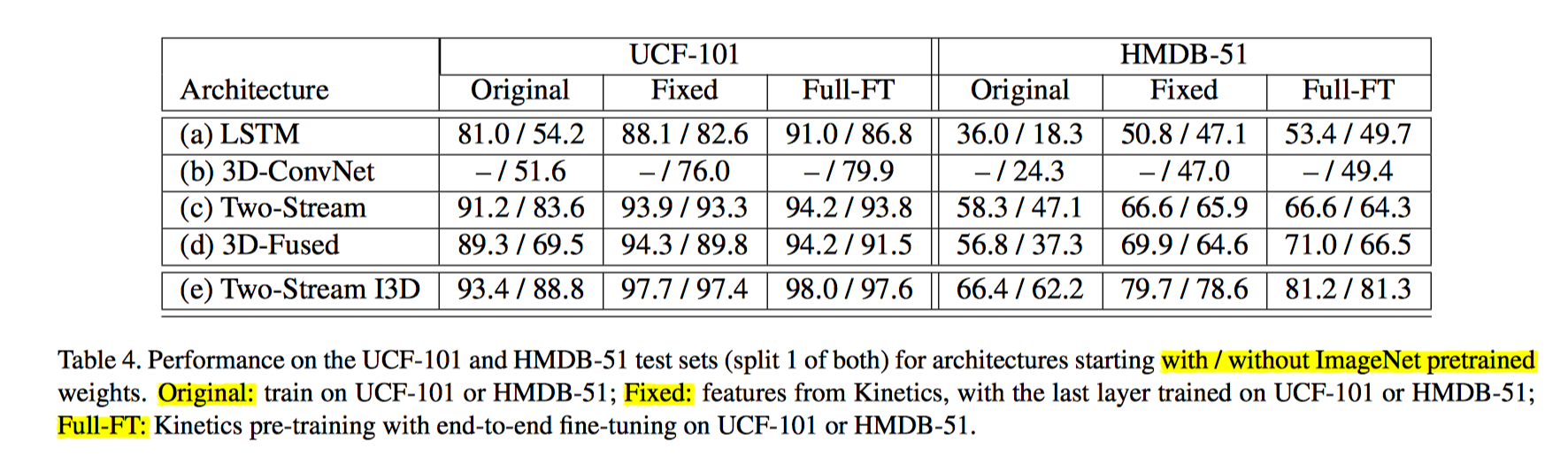 

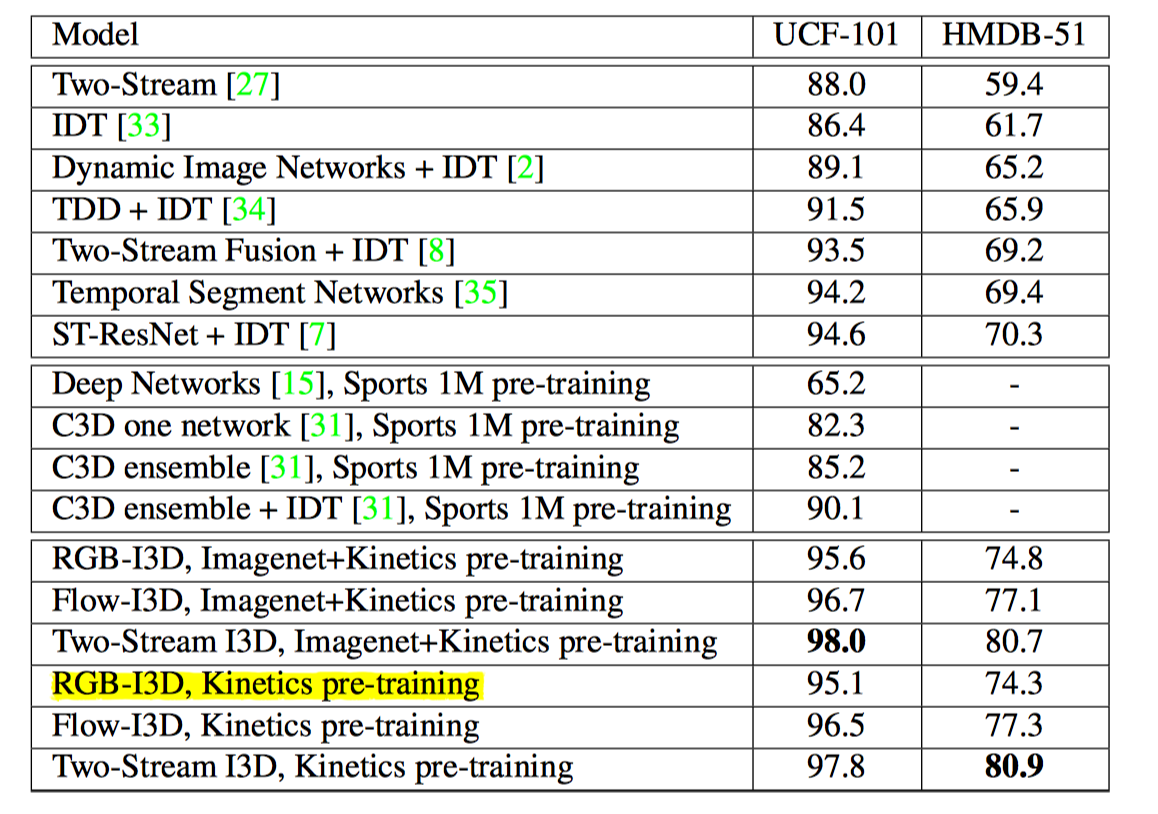 

I3D 性能更好的原因:
一是 I3D的架构更好,
二是 Kinetic 数据集更具有普适性
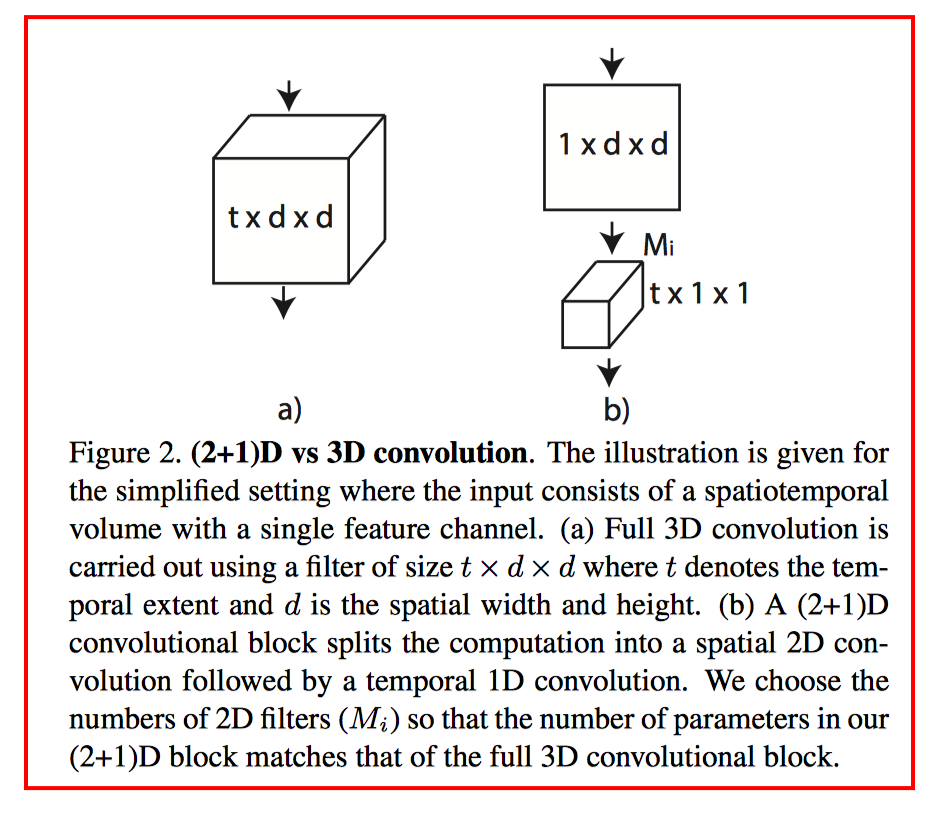
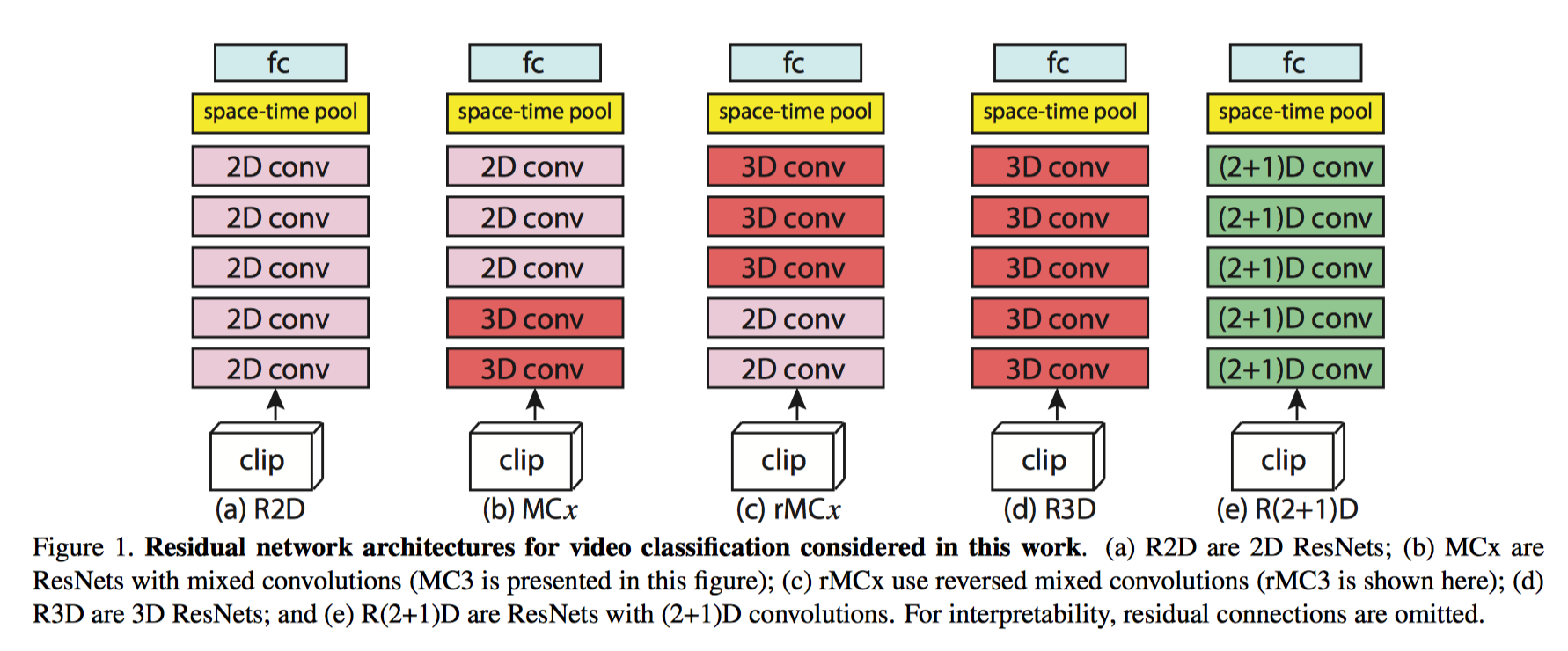
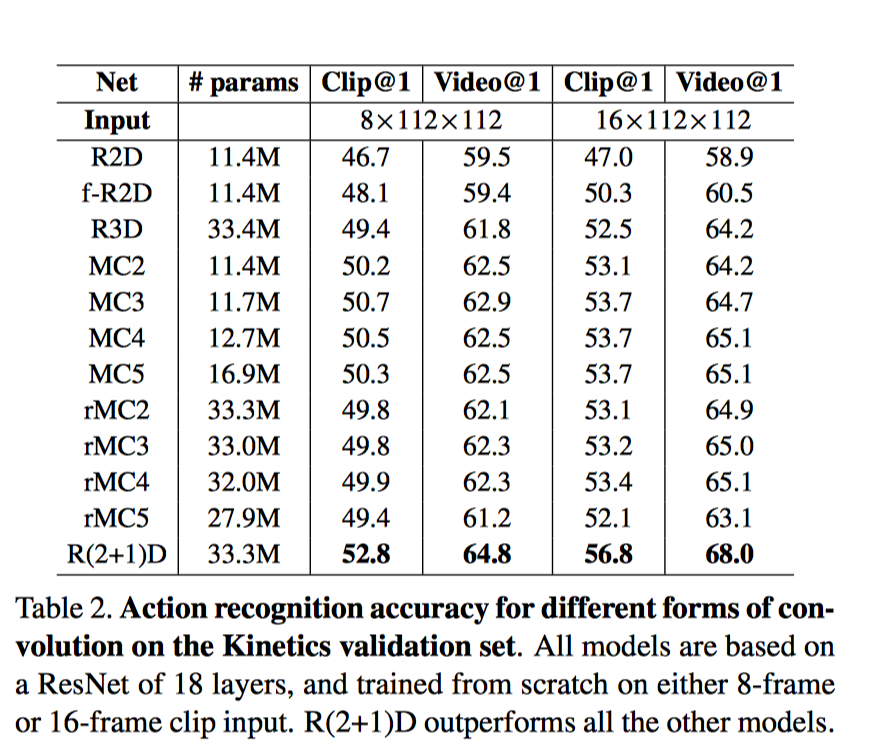
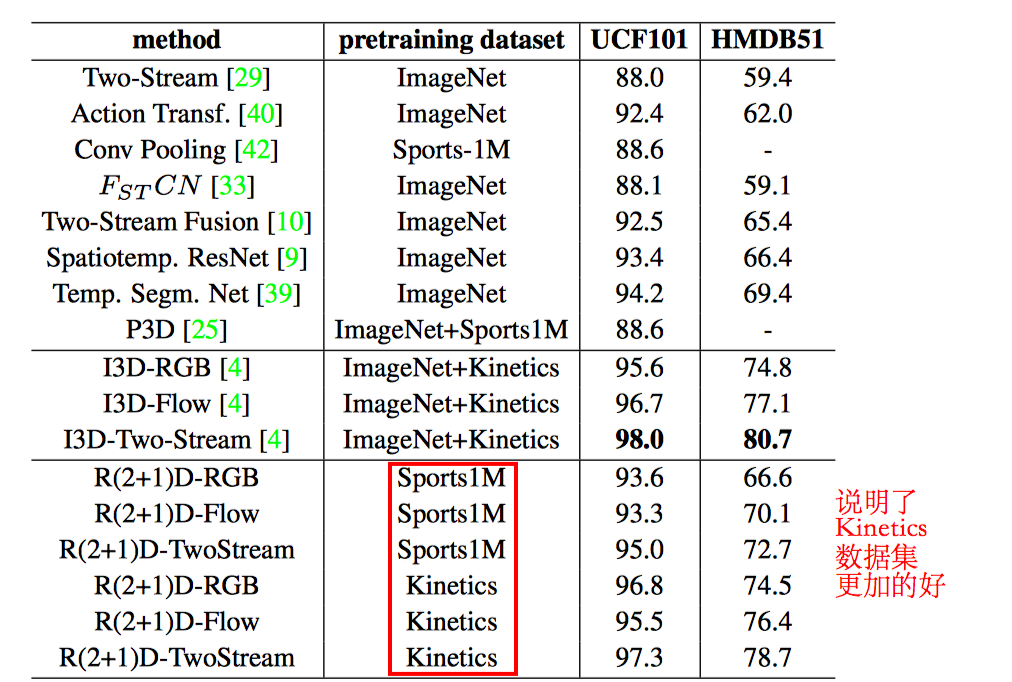
R(2+1)D
S3D?
P3D?
我们的研究动机源于观察到这样一个现象, 在动作识别中, 基于视频的单帧的2D CNN在仍然是不错的表现。
基于视频单帧的 2D CNN(RESNET-152[1])的性能非常接近的Sport-1M基准上当前最好的算法。这个结果是既令人惊讶和沮丧,因为2D CNN 无法建模时间和运动信息。基于这样的结果,我们可以假设,时间结构对的识别作用并不是至关重要,因为已经包含一个序列中的静态画面已经能够包含强有力的行动信息了。
研究目标: 我们表明,3D ResNets显著优于为相同的深度2D ResNets, 从而说明时域信息对于动作识别来说很重要.
[1]Learning spatio-temporal representation with pseudo-3d residual networks




当前这个领域需要考虑的问题?
专注于动作, 还是场景理解
一个视频中多个动作同时进行
严重依赖物体和场景首先无论是双流法还是3D卷积核,网络到底学到了什么?
会不会只是物体或场景的特征呢?而动作识别,重点在于action。MIT最近公布了新的数据集 Moments in time,Moments in Time,在这个数据集里,action成为关键。例如,opening这个动作,可以是小孩双眼open,也可以是门open,还可以是鸟的翅膀open。这样的数据集对当前主流的算法提出了挑战,把video这块的注意力聚焦在action,而不是物体和场景。
一些算法实现
| 算法 | 实现 |
|---|---|
| TSN(双流法) | http://yjxiong.me/others/tsn/ |
| I3D | https://github.com/deepmind/kinetics-i3d |
| R(2+1)D | https://github.com/facebookresearch/R2Plus1D |
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/167502.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
