大家好,又见面了,我是你们的朋友全栈君。
Video Analysis之Action Recognition(行为识别)
行为识别就是对时域预先分割好的序列判定其所属行为动作的类型,即“读懂行为”。
博文末尾支持二维码赞赏哦 _
科研成果—-中国科学院深圳先进技术研究院 面向人体姿态行为理解的深度学习方法
CVPR 2014 Tutorial on Emerging Topics in Human Activity Recognition
行为检测 Action Detection 类似图像目标检测
但在现实应用中更容易遇到的情况是序列尚未在时域分割(Untrimmed),
因此需要同时对行为动作进行时域定位(分割)和类型判定,这类任务一般称为行为检测。
传统 DTW 动态时间规整 分割视频
现在 利用RNN网络对未分割序列进行行为检测(行为动作的起止点的定位 和 行为动作类型的判定)
Action Detection
目的:不仅要知道一个动作在视频中是否发生,还需要知道动作发生在视频的哪段时间
特点:需要处理较长的,未分割的视频。且视频通常有较多干扰,目标动作一般只占视频的一小部分。
分类:根据待检测视频是一整段读入的还是逐次读入的,分为online和offline两种
Offline action detection:
特点:一次读入一整段视频,然后在这一整段视频中定位动作发生的时间
Online action detection:
特点:不断读入新的帧,在读入帧的过程中需要尽可能早的发现动作的发生(在动作尚未结束时就检测到)。
同时online action detection 还需要满足实时性要求,这点非常重要。
这导致online action detection不能采用计算复杂度过大的方法(在现有的计算能力下)
现有方法:
逐帧检测法:
即在视频序列的每帧上独立判断动作的类型,可以用CNN等方法,仅用上了spatial的信息
滑窗法: 即设置一个固定的滑窗大小,在视频序列上进行滑窗,然后对滑窗得到的视频小片断利用action recognition的方法进行分类。
现状:由于此问题难度比action recognition高很多,所以现在还没有效果较好的方法
1. 任务特点及分析
目的
给一个视频片段进行分类,类别通常是各类人的动作
特点
简化了问题,一般使用的数据库都先将动作分割好了,一个视频片断中包含一段明确的动作,
时间较短(几秒钟)且有唯一确定的label。
所以也可以看作是输入为视频,输出为动作标签的多分类问题。
此外,动作识别数据库中的动作一般都比较明确,周围的干扰也相对较少(不那么real-world)。
有点像图像分析中的Image Classification任务。
难点/关键点
强有力的特征:
即如何在视频中提取出能更好的描述视频判断的特征。
特征越强,模型的效果通常较好。
特征的编码(encode)/融合(fusion):
这一部分包括两个方面,
第一个方面是非时序的,在使用多种特征的时候如何编码/融合这些特征以获得更好的效果;
另外一个方面是时序上的,由于视频很重要的一个特性就是其时序信息,
一些动作看单帧的图像是无法判断的,只能通过时序上的变化判断,
所以需要将时序上的特征进行编码或者融合,获得对于视频整体的描述。
算法速度:
虽然在发论文刷数据库的时候算法的速度并不是第一位的。
但高效的算法更有可能应用到实际场景中去.
2. 常用数据库
行为识别的数据库比较多,这里主要介绍两个最常用的数据库,也是近年这个方向的论文必做的数据库。
1. UCF101:来源为YouTube视频,共计101类动作,13320段视频。
共有5个大类的动作:
1)人-物交互;
2)肢体运动;
3)人-人交互;
4)弹奏乐器;
5)运动。
2. HMDB51:来源为YouTube视频,共计51类动作,约7000段视频。
HMDB: a large human motion database
3. 在Actioin Recognition中,实际上还有一类骨架数据库,
比如MSR Action 3D,HDM05,SBU Kinect Interaction Dataset等。
这些数据库已经提取了每帧视频中人的骨架信息,基于骨架信息判断运动类型。
4. ACTIVITYNET Large Scale Activity Recognition Challenge
3. 研究进展
如今人体行为识别是计算机视觉研究的一个热点,
人体行为识别的目标是从一个未知的视频或者是图像序列中自动分析其中正在进行的行为。
简单的行为识别即动作分类,给定一段视频,只需将其正确分类到已知的几个动作类别,
复杂点的识别是视频中不仅仅只包含一个动作类别,而是有多个,
系统需自动的识别出动作的类别以及动作的起始时刻。
行为识别的最终目标是分析视频中
哪些人 who
在什么时刻 when
什么地方, where
干什么事情, what
即所谓的“W4系统”
人体行为识别应用背景很广泛,主要集中在智能视频监控,
病人监护系统,人机交互,虚拟现实,智能家居,智能安防,
运动员辅助训练,另外基于内容的视频检索和智能图像压缩等
有着广阔的应用前景和潜在的经济价值和社会价值,
其中也用到了不少行为识别的方法。
3.1 传统方法
特征综述
密集轨迹算法(DT算法) iDT(improved dense trajectories)特征
Action Recognition by Dense Trajectories
Action recognition with improved trajectories
[DT论文](Action Recognition by Dense Trajectories)
基本思路:
DT算法的基本思路为利用光流场来获得视频序列中的一些轨迹,
再沿着轨迹提取HOF,HOG,MBH,trajectory4种特征,其中HOF基于灰度图计算,
另外几个均基于dense optical flow计算。
最后利用FV(Fisher Vector)方法对特征进行编码,再基于编码结果训练SVM分类器。
而iDT改进的地方在于它利用前后两帧视频之间的光流以及SURF关键点进行匹配,
从而消除/减弱相机运动带来的影响,改进后的光流图像被成为warp optical flow
总结:
A. 利用光流场来获得视频序列中的一些轨迹;
a. 通过网格划分的方式在图片的多个尺度上分别密集采样特征点,滤除一些变换少的点;
b. 计算特征点邻域内的光流中值来得到特征点的运动速度,进而跟踪关键点;
B. 沿轨迹提取HOF,HOG,MBH,trajectory,4种特征
其中HOG基于灰度图计算,
另外几个均基于稠密光流场计算。
a. HOG, 方向梯度直方图,分块后根据像素的梯度方向统计像素的梯度幅值。
b. HOF, 光流直方图,光流通过当前帧梯度矩阵和相邻帧时间上的灰度变换矩阵计算得到,
之后再对光流方向进行加权统计。
c. MBH,运动边界直方图,实质为光流梯度直方图。
d. Trajectories, 轨迹特征,特征点在各个帧上位置点的差值,构成轨迹变化特征。
C.特征编码—Bag of Features;
a. 对训练集数据提取上述特征,使用K_means聚类算法,对特征进行聚类,得到特征字典;
b. 使用字典单词对测试数据进行量化编码,得到固定长度大小的向量,可使用VQ或则SOMP算法。
D. 使用SVM进行分类
对编码量化之后的特征向量使用SVM支持向量机进行分类。
iDT(improved dense trajectories) 改进
LEAR实验室 这个实验室个人感觉很不错,放出来的代码基本都能work,而且有不错的的效果。
1. 剔除相机运动引起的背景光流
a. 使用SURF特征算法匹配前后两帧的 匹配点对,这里会使用人体检测,剔除人体区域的匹配点,运动量大,影响较大;
b. 利用光流算法计算匹配点对,剔除人体区域的匹配点对;
c. 合并SURF匹配点对 和 光流匹配点对,利用RANSAC 随机采样序列一致性算法估计前后两帧的 单应投影变换矩阵H;
d. 利用矩阵H的逆矩阵,计算得到当前帧除去相机运动的状态I’= H.inv * I ;
e. 计算去除相机运动后的帧I' 的 光流。
f. 光流算法 Ft
假设1:光照亮度恒定:
I(x, y, t) = I(x+dx, y+dy, t+dt)
泰勒展开:
I(x+dx, y+dy, t+dt) =
I(x, y, t) + dI/dx * dx + dI/dy * dy + dI/dt * dt
= I(x, y, t) + Ix * dx + Iy * dy + It * dt
得到:
Ix * dx + Iy * dy + It * dt = 0
因为 像素水平方向的运动速度 u=dx/dt, 像素垂直方向的运动速度 v=dy/dt
等式两边同时除以 dt ,得到:
Ix * dx/dt + Iy * dy/dt + It = 0
Ix * u + Iy * v + It = 0
写成矩阵形式:
[Ix, Iy] * [u; v] = -It, 式中Ix, Iy为图像空间像素差值(梯度), It 为时间维度,像素差值
假设2:局部区域 运动相同
对于点[x,y]附近的点[x1,y1] [x2,y2] , ... , [xn,yn] 都具有相同的速度 [u; v]
有:
[Ix1, Iy1; [It1
Ix2, Iy2; It2
... * [u; v] = - ...
Ixn, Iyn;] Itn]
写成矩阵形式:
A * U = b
由两边同时左乘 A逆 得到:
U = A逆 * b
由于A矩阵的逆矩阵可能不存在,可以曲线救国改求其伪逆矩阵
U = (A转置*A)逆 * A转置 * b
得到像素的水平和垂直方向速度以后,可以得到:
速度幅值:
V = sqrt(u^2 + v^2)
速度方向:Cet = arctan(v/u)
2. 特征归一化方式
在iDT算法中,对于HOF,HOG和MBH特征采取了与DT算法(L2范数归一化)不同的方式。
L2范数归一化 : Xi' = Xi/sqrt(X1^2 + ... + Xn^2)
L1正则化后再对特征的每个维度开平方。
L1范数归一化 : Xi' = Xi/(abs(X1) + ... + abs(Xn))
Xi'' = sqrt(Xi')
这样做能够给最后的分类准确率带来大概0.5%的提升
3. 特征编码—Fisher Vector
特征编码阶段iDT算法不再使用Bag of Features/ BOVM方法,
(提取图像的SIFT特征,通过(KMeans聚类),VQ矢量量化,构建视觉词典(码本))
而是使用效果更好的Fisher Vector编码.
FV采用混合高斯模型(GMM)构建码本,
但是FV不只是存储视觉词典的在一幅图像中出现的频率,
并且FV还统计视觉词典与局部特征(如SIFT)的差异
Fisher Vector同样也是先用大量特征训练码书,再用码书对特征进行编码。
在iDT中使用的Fisher Vector的各个参数为:
1. 用于训练的特征长度:trajectory+HOF+HOG+MBH = 30+96+108+192 = 426维
2. 用于训练的特征个数:从训练集中随机采样了256000个
3. PCA降维比例:2,即维度除以2,降维后特征长度为 D = 426 / 2 = 213。
先降维,后编码
4. Fisher Vector中 高斯聚类的个数K:K=256
故编码后得到的特征维数为2*K*D个,即109056维。
在编码后iDT同样也使用了SVM进行分类。
在实际的实验中,推荐使用liblinear,速度比较快。
4. 其他改进思想
原先是沿着轨迹提取手工设计的特征,可以沿着轨迹利用CNN提取特征。
Fisher Vector 特征编码 主要思想是使用高斯分布来拟合单词 而不是简简单单的聚类产生中心点
在一般的分类问题中,通常的套路都是提取特征,将特征输入分类器训练,得到最终的模型。
但是在具体操作时,一开始提出的特征和输入分类器训练的特征是不一样的。
比如假设有N张100×100的图像,分别提取它们的HoG特征x∈Rp×q,p为特征的维数,q为这幅图像中HoG特征的个数。
如果把直接把这样的一万个x直接投入分类器训练,效果不一定好,
因为不一定每个像素点的信息都是有价值的,里面可能有很多是冗余的信息。
而且特征维度太高会导致最终的训练时间过长。
所以通常会对raw features做一些预处理。最常用的就是词袋模型(bag of words)。
K-means是最常用的聚类方法之一,我们的例子中,有N幅图像,每幅图像有x∈Rp×q的特征,
那么所有数据的特征矩阵为X∈Rp×Nq。也就是说现在一共存在Nq个数据点,它们分布在一个p维的空间中,
通过聚类后可以找到M个聚类中心。然后对于每一幅图像而言,
分别计算它的q个p维特征属于哪一个聚类中心(距离最近),最终统计M个聚类中心分别拥有多少特征,
得到一个M维的向量。这个向量就是最终的特征。
k-means的缺点在于,它是一个hard聚类的方法,比如有一个点任何一个聚类中心都不属于,
但是词袋模型仍然可能会把它强行划分到一个聚类中心去。
对于一个点,它属不属于某个聚类中心的可能性是个属于(0,1)的整数值。
相反,高斯混合模型(Gaussian Mixture Model) 就是一种soft聚类的方法,
它建立在一个重要的假设上,即任意形状的概率分布都可以用多个高斯分布函数去近似。
类似傅里叶变换,任何信号曲线都可以用正余弦函数来近似。
顾名思义,高斯混合模型是由很多个高斯分布组成的模型,每一个高斯分布都是一个component。
每一个component Nk∼(μk,σk),k=1,2,…K对应的是一个聚类中心,这个聚类中心的坐标可以看作(μk,σk)
一般解高斯混合模型都用的是EM算法(期望最大化算法)。
EM算法分为两步:
在E-step中,估计数据由每个component生成的概率。
假设μ,Σ,ϕ已知,对于每个数据 xi 来说,它由第k个component 生成的概率为
在M-step中,估计每个component的参数μk,Σk,πkk=1,…K。
利用上一步得到的pik,它是对于每个数据 xi 来说,它由第k个component生成的概率,
也可以当做第k个component在生成这个数据上所做的贡献,或者说,
我们可以看作 xi这个值其中有pikxi 这部分是由 第k个component所生成的。
现在考虑所有的数据,可以看做第k个component生成了 p1kx1,…,pNkxN 这些点。
由于每个component 都是一个标准的 Gaussian 分布,可以很容易的根据期望、方差的定义求出它们:
重复迭代前面两步,直到似然函数的值收敛为止。
FV采用GMM构建视觉词典,为了可视化,这里采用二维的数据,
然这里的数据可以是SIFT或其它局部特征,
具体实现代码如下:
%采用GMM模型对数据data进行拟合,构建视觉词典
numFeatures = 5000 ; %样本数
dimension = 2 ; %特征维数
data = rand(dimension,numFeatures) ; %这里随机生成一些数据,这里data可以是SIFT或其它局部特征
numClusters = 30 ; %视觉词典大小
[means, covariances, priors] = vl_gmm(data, numClusters); %GMM拟合data数据分布,构建视觉词典
这里得到的means、covariances、priors分别为GMM的均值向量,协方差矩阵和先验概率,也就是GMM的参数。
这里用GMM构建视觉词典也存在一个问题,这是GMM模型固有的问题,
就是当GMM中的高斯函数个数,也就是聚类数,也就是numClusters,
若与真实的聚类数不一致的话,
GMM表现的不是很好(针对期望最大化EM方法估计参数),具体请参见GMM。
接下来,我们创建另一组随机向量,这些向量用Fisher Vector和刚获得的GMM来编码,
具体代码如下:
numDataToBeEncoded = 1000;
dataToBeEncoded = rand(dimension,numDataToBeEncoded); %2*1000维数据
% 进行FV编码
encoding = vl_fisher(datatoBeEncoded, means, covariances, priors);
idt算法总结
1、密集采样:
多尺度(8个)
间隔采样(5)
无纹理区域点的剔除
2、光流法跟踪:
I(x, y, t) = I(x+dx, y+dy, t+dt)
泰勒展开:
[Ix, Iy] * [u; v] = -It
局部区域 运动相同:
A * U = b
U = (A转置*A)逆 * A转置 * b 伪逆求解
光流中指滤波:
Pt+1=(xt+1,yt+1)=(xt,yt)+(M∗Ut)|xt,yt
3、特征计算:
区域选取:
1、选取相邻L帧(15);
2、对每条轨迹在每个帧上取N*N
的像素区域(32*32)
3、对上述区域划分成nc*nc个
格子(2*2)
4、在时间空间上划分成nt段(3段)
5、这样就有 nc*nc*nt个空间划
分区域。
传统视频行为分析算法总结
a. 特征提取方法
1. 方向梯度直方图 HOG
图像平面像素水平垂直误差;
再求和成梯度幅值和梯度方向;
划分梯度方向,按梯度大小加权统计。
2. 光流直方图 HOF
需要梯度图和时间梯度图来计算像素水平和垂直速度,
再求合成速度幅值和方向,
按上面的方式统计。
这里还可以使用 目标检测 去除背景光溜,只保留人体区域的光流。
3. 光流梯度直方图 MBH
在光流图上计算水平和垂直光流梯度,
计算合成光流梯度幅值和方向,
再统计。
4. 轨迹特征 Trajectories,
匹配点按照光流速度得到坐标,
获取相邻帧匹配点的坐标差值;
按一条轨迹串联起来;
正则化之后就是一个轨迹特征。
5. 人体骨骼特征
通过RGB图像进行关节点估计(Pose Estimation)获得;
或是通过深度摄像机直接获得(例如Kinect)。
b. 特征归一化方法
L2范数归一化 :
Xi' = Xi/sqrt(X1^2 + ... + Xn^2)
L1范数归一化后再对特征的每个维度开平方。
L1范数归一化 : Xi' = Xi/(abs(X1) + ... + abs(Xn))
开平方 :Xi'' = sqrt(Xi')
c. 特征编码方法
1) 视觉词袋BOVM模型
1. 使用K_mean聚类算法对训练数据集特征集合进行聚类,
得到特征单词字典;
2. 使用矢量量化VQ算法 或者 同步正交匹配追踪SOMP算法
对分割后的测试样本数据的特征 用特征单词字典进行编码;
3.计算一个视频的 字典单词 的视频表示向量,得到视频的特征向量。
2) Fisher Vector 特征编码,高斯混合模型拟合中心点
1. 使用高斯混合模型GMM算法提取训练集特征中的聚类信息,得到 K个高斯分布表示的特征单词字典;
2. 使用这组组K个高斯分布的线性组合来逼近这些 测试集合的特征,也就是FV编码.
Fisher vector本质上是用似然函数的梯度vector来表达一幅图像, 说白了就是数据拟合中对参数调优的过程。
由于每一个特征是d维的,需要K个高斯分布的线性组合,有公式5,一个Fisher vector的维数为(2*d+1)*K-1维。
3.计算一个视频的 字典单词 的视频表示向量,得到视频的特征向量。
Fisher Vector步骤总结:
1.选择GMM中K的大小
1.用训练图片集中所有的特征(或其子集)来求解GMM(可以用EM方法),得到各个参数;
2.取待编码的一张图像,求得其特征集合;
3.用GMM的先验参数以及这张图像的特征集合按照以上步骤求得其fv;
4.在对训练集中所有图片进行2,3两步的处理后可以获得fishervector的训练集,然后可以用SVM或者其他分类器进行训练。
3) 两种编码方式对比
经过fisher vector的编码,大大提高了图像特征的维度,能够更好的用来描述图像。
FisherVector相对于BOV的优势在于,BOV得到的是一个及其稀疏的向量,
由于BOV只关注了关键词的数量信息,这是一个0阶的统计信息;
FisherVector并不稀疏,同时,除了0阶信息,
Fisher Vector还包含了1阶(期望)信息、2阶(方差信息),
因此FisherVector可以更加充分地表示一幅图片。
d. 视频分割 类似语言识别中的 间隔点检测
1) 动态时间规整DTW
1) 按b的方法提取训练集和测试集的特征
2) 计算训练集和测试集特征相似度距离
3) 使用动态规划算法为测试机样本在训练集中找出最匹配的一个
4) 对训练集剩余部分采用3) 的方法依次找出最匹配的一个
1)输入:
1. 所有单个训练视频样本的量化编码后的特征向量.
2. 包含多个行为动作的测试视频的量化编码后的特征向量.
2)算法描述:
1. 测试样本特征向量 和 多个训练样本特征向量分别计算特征匹配距离。
2. 单个测试视频的每一帧的特征向量和测试视频的每一帧的特征向量计算相似度(欧氏距离).
3. 以训练视频的最后一帧的特征向量和测试视频的每一帧的特征向量的距离点位起点,
使用 动态规划 的方法,找出一条最优匹配路径,最后计算路径上特征匹配距离之和,
找出一个最小的,对应的分割点即为测试视频与当前训练样本的最优匹配。
4. 迭代找出测试视频样本和其他训练样本的最有匹配,得到最优匹配距离。
5. 在所有的好的匹配距离中找出一个最小的距离,即为对应测试视频匹配的行为动作。
6. 将测试视频中已经分割出去的视频序列剔除,剩余的视频重复1~5的步骤,获取对应的标签和时间分割信息。
2) CDP
3) HMM
1) 将训练集的每一种行为当成系统的隐含状态
2) 根据测试视频这个可见状态链推测最有可能的隐含状态链
3)需要求的每种隐含状态之间的状态转移概率,
以及每种隐含状态输出一个可见状态的概率。
4) 使用维特比算法进行求解出一个最大概率的隐含状态链(即行为状态序列)
1) 将训练集的每一种行为当成系统的隐含状态
2) 根据测试视频这个可见状态链推测最有可能的隐含状态链
3)需要求的每种隐含状态之间的状态转移概率,
以及每种隐含状态输出一个可见状态的概率。
4) 使用维特比算法进行求解出一个最大概率的隐含状态链(即行为状态序列)
4) 深度学习的方法分割动作
DTW/HMM/CRBM/高斯过程
e. 分类器分类
1. SVM 支持向量机进行分类。
2. KNN 最近邻分类器进行分类。
3.2 深度学习方法
时空双流网络结构 Two Stream Network及衍生方法
空时注意力模型(Attention)之于行为识别
提出
“Two-Stream Convolutional Networks for Action Recognition in Videos”(2014NIPS)
Two Stream方法最初在这篇文章中被提出:
在空间部分,以单个帧上的外观形式,携带了视频描绘的场景和目标信息。
其自身静态外表是一个很有用的线索,因为一些动作很明显地与特定的目标有联系。
在时间部分,以多帧上的运动形式,表达了观察者(摄像机)和目标者的运动。
基本原理为:
1. 对视频序列中每两帧计算密集光流,得到密集光流的序列(即temporal信息)。
2. 然后对于视频图像(spatial)和密集光流(temporal)分别训练CNN模型,
两个分支的网络分别对动作的类别进行判断,
3. 最后直接对两个网络的class score进行fusion(包括直接平均和svm两种方法),得到最终的分类结果。
注意,对与两个分支使用了相同的2D CNN网络结构,其网络结构见下图。
实验效果:UCF101-88.0%,HMDB51-59.4%
结构:


光流 和 轨迹
改进1 CNN网络进行了spatial以及temporal的融合
Convolutional Two-Stream Network Fusion for Video Action Recognition“(2016CVPR)

这篇论文的主要工作为:
1. 在two stream network的基础上,
利用CNN网络进行了spatial以及temporal的融合,从而进一步提高了效果。
2. 此外,该文章还将基础的spatial和temporal网络都换成了VGG-16 network。
实验效果:UCF101-92.5%,HMDB51-65.4%
改进2 LSTM网络 融合双流 spatial以及temporal
这篇文章主要是用LSTM来做two-stream network的temporal融合。效果一般
TSN 结构
Temporal Segment Networks: Towards Good Practices for Deep Action Recognition
TSN(Temporal Segment Networks)代码实验
这篇文章是港中文Limin Wang大神的工作,他在这方面做了很多很棒的工作,
可以followt他的主页:http://wanglimin.github.io/ 。
这篇文章提出的TSN网络也算是spaital+temporal fusion,结构图见下图。
这篇文章对如何进一步提高two stream方法进行了详尽的讨论,主要包括几个方面(完整内容请看原文):
1. 据的类型:除去two stream原本的RGB image和 optical flow field这两种输入外,
章中还尝试了RGB difference及 warped optical flow field两种输入。
终结果是 RGB+optical flow+warped optical flow的组合效果最好。
2. 构:尝试了GoogLeNet,VGGNet-16及BN-Inception三种网络结构,其中BN-Inception的效果最好。
3. 包括 跨模态预训练,正则化,数据增强等。
4. 果:UCF101-94.2%,HMDB51-69.4%
two-stream 卷积网络对于长范围时间结构的建模无能为力,
主要因为它仅仅操作一帧(空间网络)或者操作短片段中的单堆帧(时间网络),
因此对时间上下文的访问是有限的。
视频级框架TSN可以从整段视频中建模动作。
和two-stream一样,TSN也是由空间流卷积网络和时间流卷积网络构成。
但不同于two-stream采用单帧或者单堆帧,TSN使用从整个视频中稀疏地采样一系列短片段,
每个片段都将给出其本身对于行为类别的初步预测,从这些片段的“共识”来得到视频级的预测结果。
在学习过程中,通过迭代更新模型参数来优化视频级预测的损失值(loss value)。
TSN网络示意图如下:
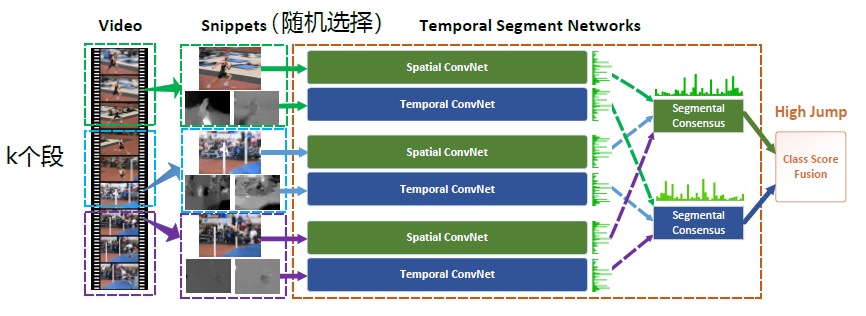
由上图所示,一个输入视频被分为 K 段(segment),一个片段(snippet)从它对应的段中随机采样得到。
不同片段的类别得分采用段共识函数(The segmental consensus function)
进行融合来产生段共识(segmental consensus),这是一个视频级的预测。
然后对所有模式的预测融合产生最终的预测结果。
具体来说,给定一段视频 V,把它按相等间隔分为 K 段 {S1,S2,⋯,SK}。
接着,TSN按如下方式对一系列片段进行建模:
TSN(T1,T2,⋯,TK)=H(G(F(T1;W),F(T2;W),⋯,F(TK;W)))
其中:
(T1,T2,⋯,TK) 代表片段序列,每个片段 Tk 从它对应的段 Sk 中随机采样得到。
F(Tk;W) 函数代表采用 W 作为参数的卷积网络作用于短片段 Tk,函数返回 Tk 相对于所有类别的得分。
段共识函数 G(The segmental consensus function)结合多个短片段的类别得分输出以获得他们之间关于类别假设的共识。
基于这个共识,预测函数 H 预测整段视频属于每个行为类别的概率(本文 H 选择了Softmax函数)。
结合标准分类交叉熵损失(cross-entropy loss);
网络结构
一些工作表明更深的结构可以提升物体识别的表现。
然而,two-stream网络采用了相对较浅的网络结构(ClarifaiNet)。
本文选择BN-Inception (Inception with Batch Normalization)构建模块,
由于它在准确率和效率之间有比较好的平衡。
作者将原始的BN-Inception架构适应于two-stream架构,和原始two-stream卷积网络相同,
空间流卷积网络操作单一RGB图像,时间流卷积网络将一堆连续的光流场作为输入。
网络输入
TSN通过探索更多的输入模式来提高辨别力。
除了像two-stream那样,
空间流卷积网络操作单一RGB图像,
时间流卷积网络将一堆连续的光流场作为输入,
作者提出了两种额外的输入模式:
RGB差异(RGB difference)和
扭曲的光流场(warped optical flow fields,idt中去除相机运动后的光流)。
TSN改进版本之一 加权融合
改进的地方主要在于fusion部分,不同的片段的应该有不同的权重,而这部分由网络学习而得,最后由SVM分类得到结果。
Deep Local Video Feature for Action Recognition 【CVPR2017】
TSN改进版本二 时间推理
这篇是MIT周博磊大神的论文,作者是也是最近提出的数据集 Moments in time 的作者之一。
该论文关注时序关系推理。
对于哪些仅靠关键帧(单帧RGB图像)无法辨别的动作,如摔倒,其实可以通过时序推理进行分类。
除了两帧之间时序推理,还可以拓展到更多帧之间的时序推理。
通过对不同长度视频帧的时序推理,最后进行融合得到结果。
该模型建立TSN基础上,在输入的特征图上进行时序推理。
增加三层全连接层学习不同长度视频帧的权重,及上图中的函数g和h。
除了上述模型外,还有更多关于时空信息融合的结构。
这部分与connection部分有重叠,所以仅在这一部分提及。
这些模型结构相似,区别主要在于融合module的差异,细节请参阅论文。
Temporal Relational Reasoning in Videos
LSTM 结构融合双流特征
Beyond Short Snippets: Deep Networks for Video Classification Joe
这篇文章主要是用LSTM来做two-stream network的temporal融合。效果一般
实验效果:UCF101-88.6%
RNN的展开结构 ht = f(w1*xt + w2*ht-1 + b) 复合函数+递推数列
后一项的值由前一项的值ht-1 和 当前时刻的输入值xt 决定,有机会通过当前的输入值改变自己的命运。
ht-1提现了记忆功能,ht-1是由ht-2和xt-1所决定,所以ht的值实际上是由 x1, x2, x3,..., xt决定的,
它记住了之前完整的序列信息。
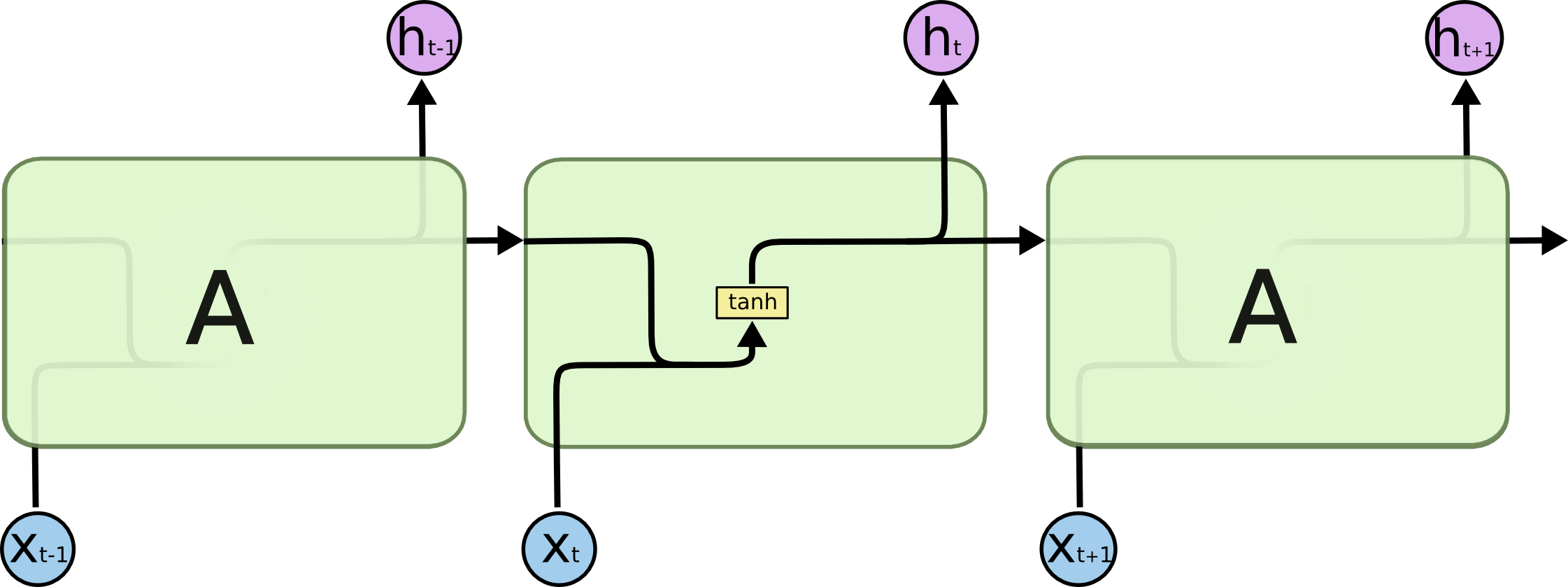
LSTM的展开结构
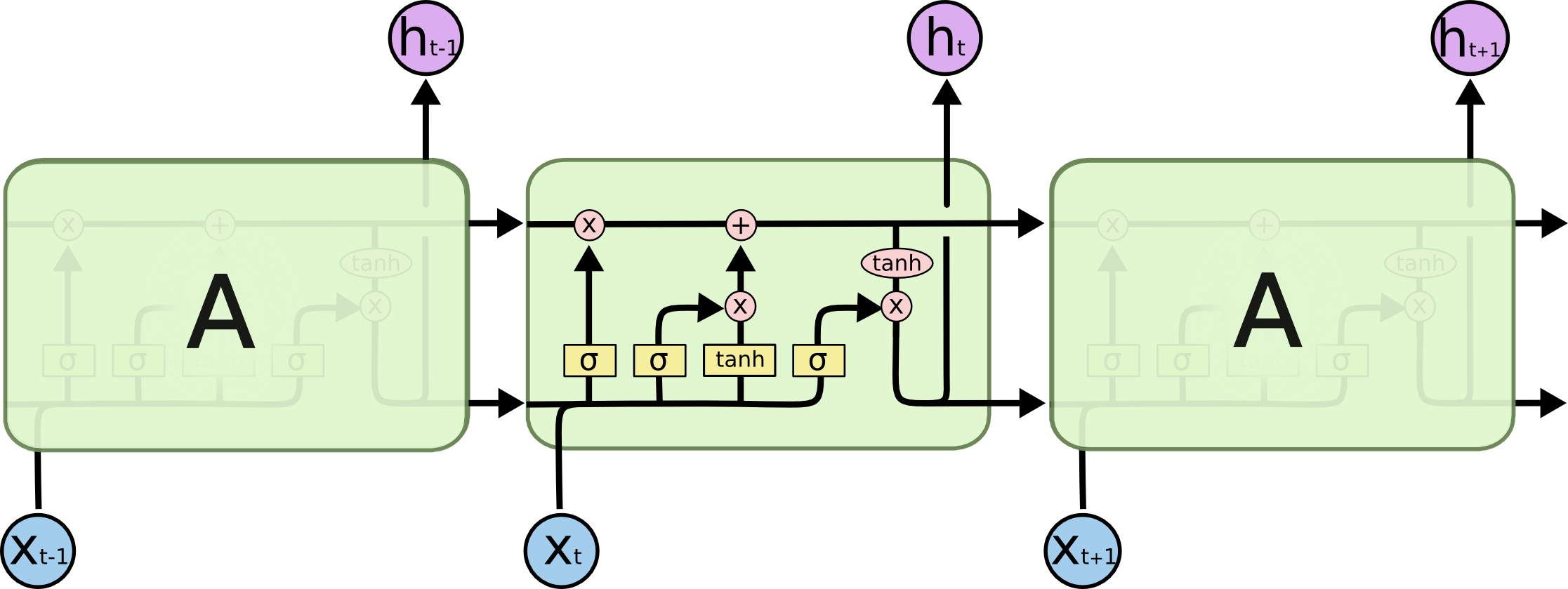
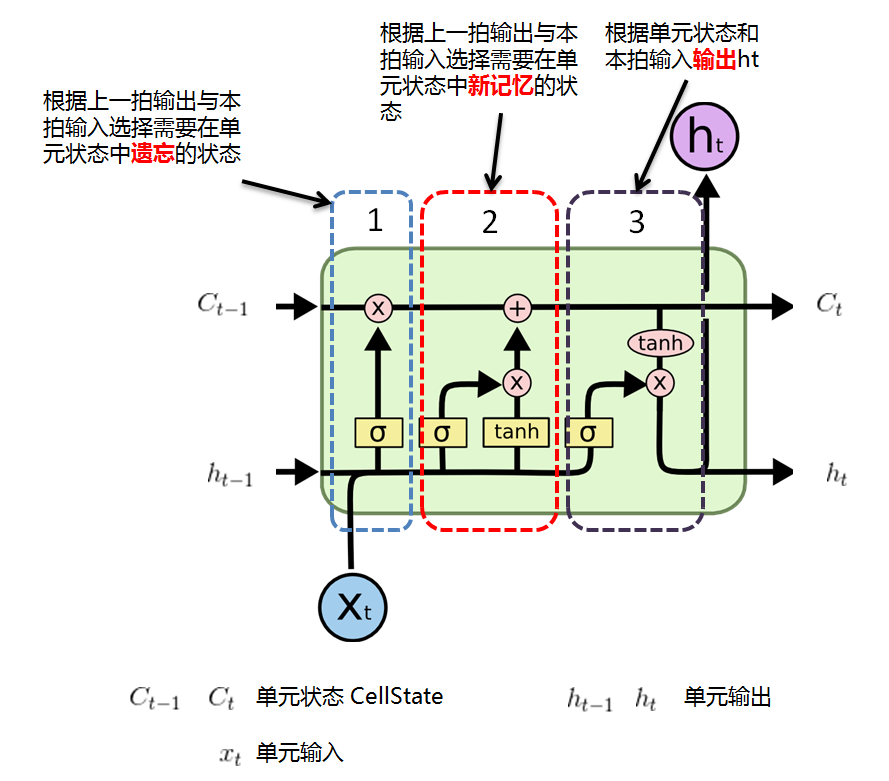
LSTM 功能
行为识别 人体骨架检测+LSTM
人体骨架怎么获得呢?
主要有两个途径:
通过RGB图像进行关节点估计(Pose Estimation openpose工具箱)获得,
或是通过深度摄像机直接获得(例如Kinect)。
每一时刻(帧)骨架对应人体的K个关节点所在的坐标位置信息,一个时间序列由若干帧组成。
3 骨架获取 Stacked Hourglass Networks for Human Pose Estimation
4 骨架获取 Realtime Multi-person 2D Pose Estimation using Part Affinity Fields
基于部分亲和字段PAF(Part Affinity Field)的2D图像姿态估计 博客参考
Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition 骨骼时空网络兴趣点
思路:
在视频上先对每一帧做姿态估计(Kinetics 数据集上文章用的是OpenPose),然后可以构建出一个空间上的骨架时序图。
然后应用ST-GCN网络提取高层特征
最后用softmax分类器进行分类
1. 空时注意力模型(Attention)之于行为识别
An End-to-End Spatio-Temporal Attention Model for Human Action Recognition from Skeleton Data
LSTM网络框架和关节点共现性(Co-occurrence)的挖掘之于行为识别。
时域注意力模型:
设计了时域注意力模型,通过一个LSTM子网络来自动学习和获知序列中不同帧的重要性,
使重要的帧在分类中起更大的作用,以优化识别的精度。
空域注意力:
设计了一个LSTM子网络,依据序列的内容自动给不同关节点分配不同的重要性,即给予不同的注意力。
由于注意力是基于内容的,即当前帧信息和历史信息共同决定的,
因此,在同一个序列中,关节点重要性的分配可以随着时间的变化而改变。
2. LSTM网络框架和关节点共现性(Co-occurrence)的挖掘之于行为识别
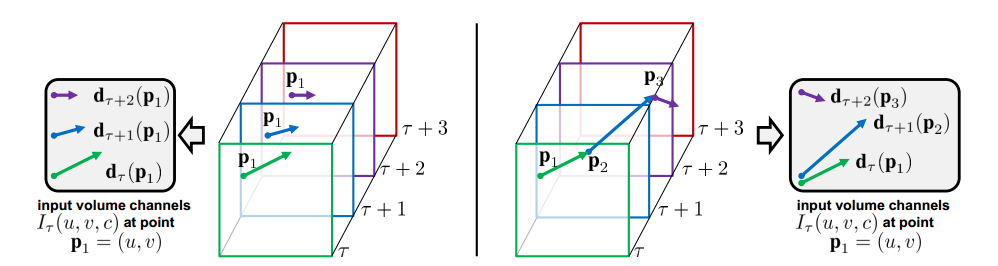
3. RNN 基于联合分类和回归的循环神经网络之于行为动作检测
Online Human Action Detection Using Joint Classification-Regression Recurrent Neural Networks
3D卷积 C3D Network
提出 C3D
Learning spatiotemporal features with 3d convolutional networks
C3D是facebook的一个工作,采用3D卷积和3D Pooling构建了网络。
通过3D卷积,C3D可以直接处理视频(或者说是视频帧的volume)
实验效果:UCF101-85.2% 可以看出其在UCF101上的效果距离two stream方法还有不小差距。
我认为这主要是网络结构造成的,C3D中的网络结构为自己设计的简单结构,如下图所示。
速度:
C3D的最大优势在于其速度,在文章中其速度为314fps。而实际上这是基于两年前的显卡了。
用Nvidia 1080显卡可以达到600fps以上。
所以C3D的效率是要远远高于其他方法的,个人认为这使得C3D有着很好的应用前景。
改进 I3D[Facebook]
即基于inception-V1模型,将2D卷积扩展到3D卷积。
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
T3D 时空 3d卷积
Temporal 3D ConvNets:New Architecture and Transfer Learning for Video Classificati
该论文值得注意的,
一方面是采用了3D densenet,区别于之前的inception和Resnet结构;
另一方面,TTL层,即使用不同尺度的卷积(inception思想)来捕捉讯息。
P3D [MSRA]
Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks
改进ResNet内部连接中的卷积形式。然后,超深网络,一般人显然只能空有想法,望而却步。
CDC 3D卷积方式的 改进 TPC 时序保留卷积 这里也是 行为检测
Exploring Temporal Preservation Networks for Precise Temporal Action Localization TPC 时序保留卷积
思路:
这篇文章是在CDC网络的基础进行改进的,CDC最后是采用了时间上上采样,
空间下采样的方法做到了 per-frame action predictions,而且取得了可信的行为定位的结果。
但是在CDC filter之前时间上的下采样存在一定时序信息的丢失。
作者提出的TPC网络,采用时序保留卷积操作,
这样能够在不进行时序池化操作的情况下获得同样大小的感受野而不缩短时序长度。
其他方法
TPP Temporal Pyramid Pooling
End-to-end Video-level Representation Learning for Action Recognition
Pooling。时空上都进行这种pooling操作,旨在捕捉不同长度的讯息。
TLE 时序线性编码层
1. 本文主要提出了“Temporal Linear Encoding Layer” 时序线性编码层,主要对视频中不同位置的特征进行融合编码。
至于特征提取则可以使用各种方法,文中实验了two stream以及C3D两种网络来提取特征。
2. 实验效果:UCF101-95.6%,HMDB51-71.1% (特征用two stream提取)。
应该是目前为止看到效果最好的方法了(CVPR2017里可能会有更好的效果)
Deep Temporal Linear Encoding Networks
key volume的自动识别
A Key Volume Mining Deep Framework for Action Recognition
本文主要做的是key volume的自动识别。
通常都是将一整段动作视频进行学习,而事实上这段视频中有一些帧与动作的关系并不大。
因此进行关键帧的学习,再在关键帧上进行CNN模型的建立有助于提高模型效果。
本文达到了93%的正确率吗,为目前最高。
实验效果:UCF101-93.1%,HMDB51-63.3%
使用LSTM,RNN循环神经网络来完成时间上的建模
CNN提取特征->LSTM建模 A Torch Library for Action Recognition and Detection Using CNNs and LSTMs
Long-term Recurrent Convolutional Networks for Visual Recognition and Description
caffe examples/LRCN_activity_recognition”
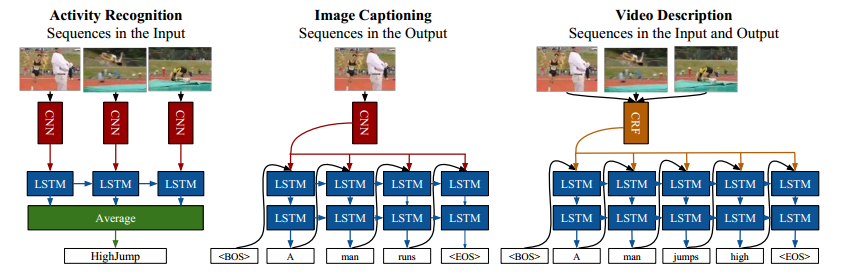
Multimodal Keyless Attention Fusion for Video Classification 多模态 LSTM
[行为识别]RPAN:An end-to-end recurrent pose-attention network for action recognition CNN+姿态注意力+lstm](https://blog.csdn.net/neu_chenguangq/article/details/79164830)
数据数据的提纯
输入一方面指输入的数据类型和格式,也包括数据增强的相关操作。
双流网络中,空间网络通道的输入格式通常为单RGB图像或者是多帧RGB堆叠。
而空间网络一般是直接对ImageNet上经典的网络进行finetune。
虽然近年来对motion信息的关注逐渐上升,指责行为识别过度依赖背景和外貌特征,
而缺少对运动本身的建模,但是,事实上,运动既不是名词,
也不应该是动词,而应该是动词+名词的形式,例如:play+basketball,也可以是play+football。
所以,个人认为,虽然应该加大的时间信息的关注,但不可否认空间特征的重要作用。
空间流上 改进 提取关键帧
空间网络主要捕捉视频帧中重要的物体特征。
目前大部分公开数据集其实可以仅仅依赖单图像帧就可以完成对视频的分类,
而且往往不需要分割,那么,在这种情况下,
空间网络的输入就存在着很大的冗余,并且可能引入额外的噪声。
是否可以提取出视频中的关键帧来提升分类的水平呢?下面这篇论文就提出了一种提取关键帧的方法。
A Key Volume Mining Deep Framework for Action Recognition 【CVPR2016】
提取关键帧 改进
虽然上面的方法可以集成到一个网络中训练,
但是思路是按照图像分类算法RCNN中需要分步先提出候选框,挑选出关键帧。
既然挑选前需要输入整个视频,可不可以省略挑选这个步骤,
直接在卷积/池化操作时,重点关注那些关键帧,而忽视那些冗余帧呢?
去年就有人提出这样的解决方法。
注:AdaScan的效果一般,关键帧的质量比上面的Key Volume Mining效果要差一点。不过模型整体比较简单。
时间流 上输入的改进 光流信息
输入方面,空间网络目前主要集中在关键帧的研究上。
而对于temporal通道而言,则是更多人的关注焦点。
首先,光流的提取需要消耗大量的计算力和时间(有论文中提到几乎占据整个训练时间的90%);
其次,光流包含的未必是最优的的运动特征。
On the Integration of Optical Flow and Action Recognition
cnn网络自学习 光流提取
那么,光流这种运动特征可不可以由网络自己学呢?
Hidden Two-Stream Convolutional Networks for Action Recognition
该论文主要参考了flownet,即使用神经网络学习生成光流图,然后作为temporal网络的输入。
该方法提升了光流的质量,而且模型大小也比flownet小很多。
有论文证明,光流质量的提高,尤其是对于边缘微小运动光流的提升,对分类有关键作用。
另一方面,该论文中也比较了其余的输入格式,如RGB diff。但效果没有光流好。
目前,除了可以考虑尝试新的数据增强方法外,如何训练出替代光流的运动特征应该是接下来的发展趋势之一。
信息的融合
这里连接主要是指双流网络中时空信息的交互。
一种是单个网络内部各层之间的交互,如ResNet/Inception;
一种是双流网络之间的交互,包括不同fusion方式的探索,
目前值得考虑的是参照ResNet的结构,连接双流网络。
基于 ResNet 的双流融合
空间和时序网络的主体都是ResNet,
增加了从Motion Stream到Spatial Stream的交互。论文还探索多种方式。
Spatiotemporal Multiplier Networks for Video Action Recognition
金字塔 双流融合
Spatiotemporal Pyramid Network for Video Action Recognition
行为识别的关键就在于如何很好的融合空间和时序上的特征。
作者发现,传统双流网络虽然在最后有fusion的过程,但训练中确实单独训练的,
最终结果的失误预测往往仅来源于某一网络,并且空间/时序网络各有所长。
论文分析了错误分类的原因:
空间网络在视频背景相似度高的时候容易失误,
时序网络在long-term行为中因为snippets length的长度限制容易失误。
那么能否通过交互,实现两个网络的互补呢?
该论文重点在于STCB模块,详情请参阅论文。
交互方面,在保留空间、时序流的同时,对时空信息进行了一次融合,最后三路融合,得出最后结果
SSN(structured segment network,结构化的段网络)
通过结构化的时间金字塔对每个行为实例的时间结构进行建模。
金字塔顶层有decomposed discriminative model(分解判别模型),
包含两个分类器:用于分类行为(针对recognition)和确定完整性(针对localization)。
集成到统一的网络中,可以以端到端的方式高效地进行训练。
为了提取高质量行为时间proposal,采用temporal actionness grouping (TAG)算法。
这两篇论文从pooling的层面提高了双流的交互能力
Attentional Pooling for Action Recognition
ActionVLAD: Learning spatio-temporal aggregation for action classification
基于ResNet的结构探索新的双流连接方式
Deep Convolutional Neural Networks with Merge-and-Run Mappings
4. 视频行为检测
CDC 用于未修剪视频中精确时间动作定位的卷积-反-卷积网络
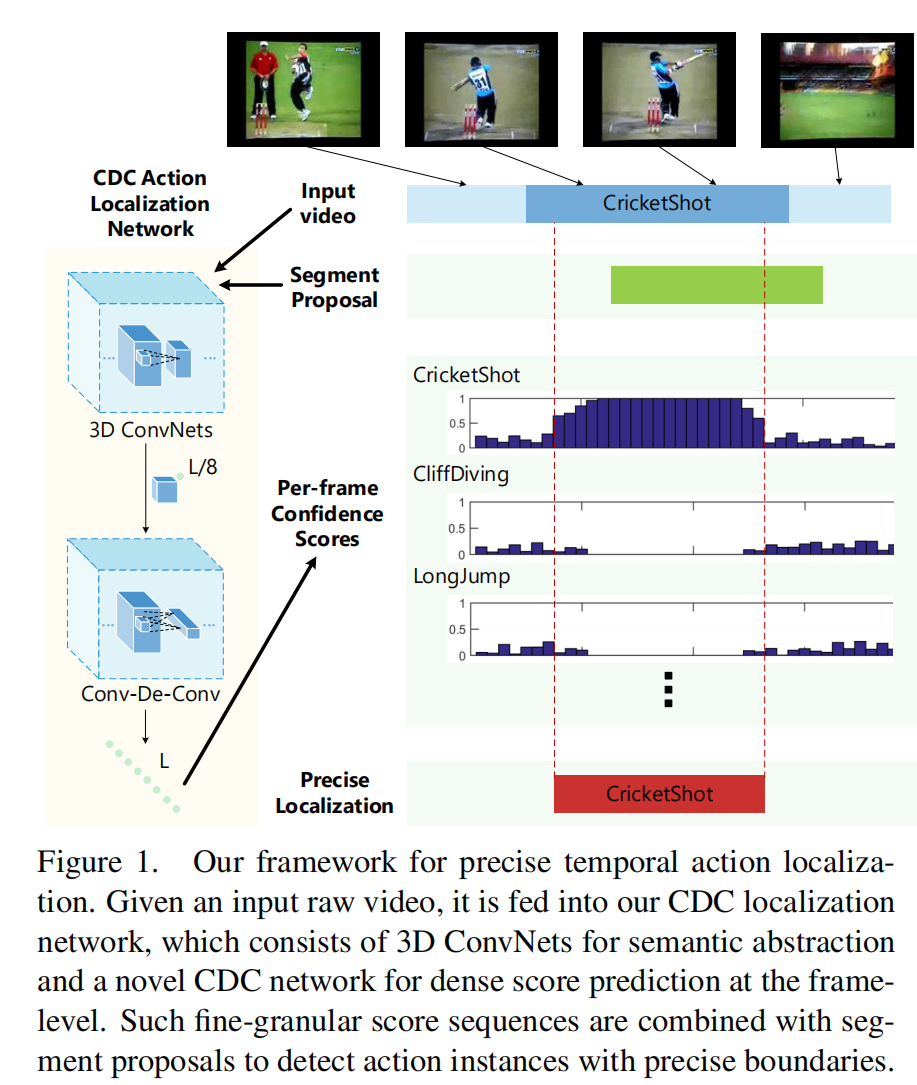
CDC网络[13]是在C3D网络基础上,借鉴了FCN的思想。
在C3D网络的后面增加了时间维度的上采样操作,做到了帧预测(frame level labeling)。
1、第一次将卷积、反卷积操作应用到行为检测领域,CDC同时在空间下采样,在时间域上上采样。
2、利用CDC网络结构可以做到端到端的学习。
3、通过反卷积操作可以做到帧预测(Per-frame action labeling)。

CDC6 反卷积
3DCNN能够很好的学习时空的高级语义抽象,但是丢失了时间上的细粒度,
众所周知的C3D架构输出视频的时序长度减小了8倍
在像素级语义分割中,反卷积被证明是一种有效的图像和视频上采样的方法,
用于产生与输入相同分辨率的输出。
对于时序定位问题,输出的时序长度应该和输入视频一致,
但是输出大小应该被减小到1x1。
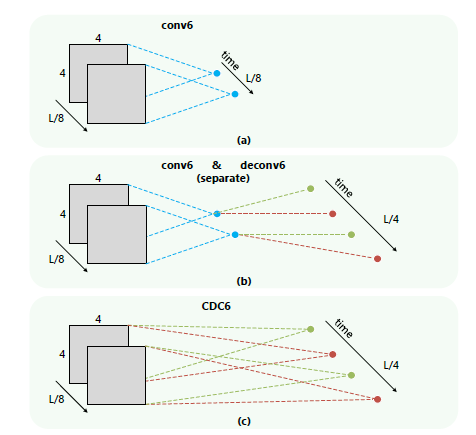
网络步骤如下所示:
输入的视频段是112x112xL,连续L帧112x112的图像
经过C3D网络后,时间域上L下采样到 L/8, 空间上图像的大小由 112x112下采样到了4x4
CDC6: 时间域上上采样到 L/4, 空间上继续下采样到 1x1
CDC7: 时间域上上采样到 L/2
CDC8:时间域上上采样到 L,而且全连接层用的是 4096xK+1, K是类别数
softmax层
R-C3D(Region 3-Dimensional Convolution)网络
R-C3D-Resgion Convolutional 3D Network for Temporal Activity Detection
是基于Faster R-CNN和C3D网络思想。
对于任意的输入视频L,先进行Proposal,然后用3D-pooling,最后进行分类和回归操作。
文章主要贡献点有以下3个。
1、可以针对任意长度视频、任意长度行为进行端到端的检测
2、速度很快(是目前网络的5倍),通过共享Progposal generation 和Classification网络的C3D参数
3、作者测试了3个不同的数据集,效果都很好,显示了通用性。
R-C3D网络可以分为4个部分
1、特征提取网络:对于输入任意长度的视频使用C3D进行特征提取;
2、Temporal Proposal Subnet: 用来提取可能存在行为的时序片段(Proposal Segments);
3、Activity Classification Subnet: 行为分类子网络;
4、Loss Function。
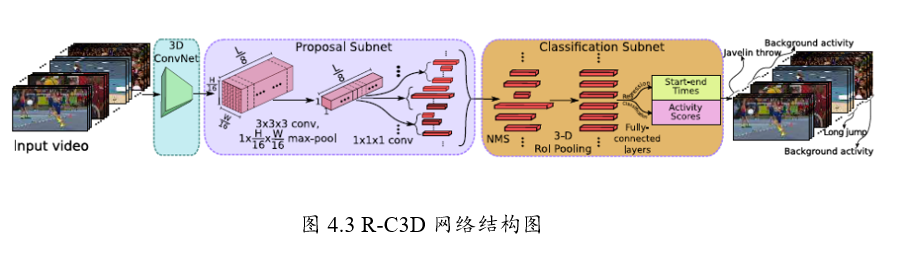
1、特征提取网络
骨干网络作者选择了C3D网络,经过C3D网络的5层卷积后,
可以得到512 x L/8 x H/16 x W/16大小的特征图。
这里不同于C3D网络的是,R-C3D允许任意长度的视频L作为输入。
2、时序候选区段提取网络
类似于Faster R-CNN中的RPN,用来提取一系列可能存在目标的候选框。
这里是提取一系列可能存在行为的候选时序。
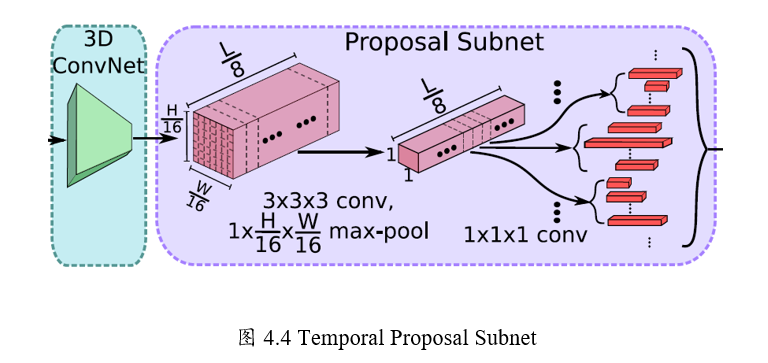
Step1:候选时序生成
输入视频经过上述C3D网络后得到了512 x L/8 x H/16 x W/16大小的特征图。
然后作者假设anchor均匀分布在L/8的时间域上,
也就是有L/8个anchors,
每个anchors生成K个不同scale的候选时序。
Step2: 3D Pooling
得到的 512xL/8xH/16xW/16的特征图后,
为了获得每个时序点(anchor)上每段候选时序的中心位置偏移和时序的长度,
作者将空间上H/16 x W/16的特征图经过一个3x3x3的卷积核
和一个3D pooling层下采样到 1x1。最后输出 512xL/8x1x1.
Step3: Training
类似于Faster R-CNN,这里也需要判定得到的候选时序是正样本还是负样本。\
文章中的判定如下。
正样本:IoU > 0.7,候选时序帧和ground truth的重叠数
负样本: IOU < 0.3
为了平衡正负样本,正/负样本比例为1:1.
3、行为分类子网络
行为分类子网络有如下几个功能:
1、从TPS(Temporal Proposal subnet)中选择出Proposal segment
2、对于上述的proposal,用3D RoI 提取固定大小特征
3、以上述特征为基础,将选择的Proposal做类别判断和时序边框回归。
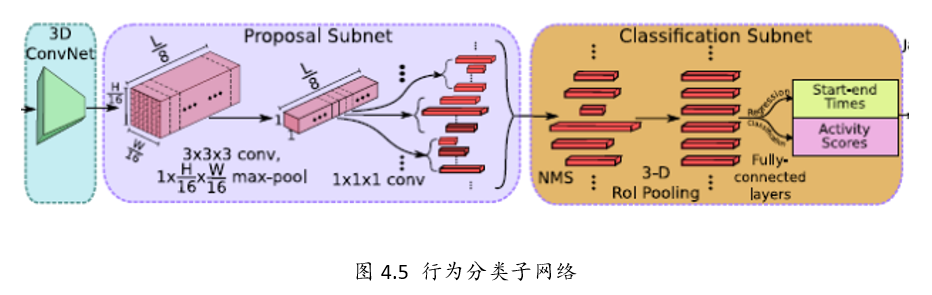
Step1: NMS
针对上述Temporal Proposal Subnet提取出的segment,
采用NMS(Non-maximum Suppression)非极大值抑制生成优质的proposal。
NMS 阈值为0.7.
Step2:3D RoI
RoI (Region of interest,兴趣区域).
这里,个人感觉作者的图有点问题,提取兴趣区域的特征图的输入应该是C3D的输出,
也就是512xL/8xH/16xW/16,可能作者遗忘了一个输入的箭头。
假设C3D输出的是 512xL/8x7x7大小的特征图,假设其中有一个proposal的长度(时序长度)为lp,
那么这个proposal的大小为512xlpx7x7,这里借鉴SPPnet中的池化层,
利用一个动态大小的池化核,ls x hs x ws。
最终得到 512x1x4x4大小的特征图
Step3: 全连接层
经过池化后,再输出到全连接层。
最后接一个边框回归(start-end time )和类别分类(Activity Scores)。
Step4: Traning
在训练的时候同样需要定义行为的类别,
如何给一个proposal定label?
同样采用IoU。
IoU > 0.5,那么定义这个proposal与ground truth相同
IoU 与所有的ground truth都小于0.5,那么定义为background
这里,训练的时候正/负样本比例为1:3。
文章将分类和回归联合,而且联合两个子网络。分类采用softmax,回归采用smooth L1。
新结构 非局部神经网络(Non-local Neural Networks) 非局部操作可以作为设计深度神经网络的一个通用的部件。
非局部网络优势:
在深层神经网络中,捕获长期依赖关系是至关重要的。
对于连续的数据(例如演讲中语言),循环操作是时间域上长期依赖问题的主要解决方案。
对于图像数据,长距离依赖关系是对大量的卷积操作形成的大的感受野进行建模的。
卷积操作或循环操作都是处理空间或者时间上的局部邻域的。
这样,只有当这些操作被反复应用的时候,长距离依赖关系才能被捕获,信号才能通过数据不断地传播。
重复的局部操作有一些限制:
首先,计算效率很低;
其次,增加优化难度;
最后,这些挑战导致多跳依赖建模,
例如,当消息需要在远距离之间来回传递时,是非常困难的。
将非局部操作作为一个高效的、简单的、通用的组件,并用深度神经网络捕捉长距离依赖关系。
我们提出的非局部操作受启发于计算机视觉中经典非局部操作的一般含义。
直观地说,非局部操作在一个位置的计算响应是输入特性图中所有位置的特征的加权总和(如图1)。
一组位置可以在空间、时间或时空上,暗示我们的操作可以适用于图像、序列和视频问题。
非局部操作在视频分类应用中的有效性。
在视频中,远距离的相互作用发生在空间或时间中的长距离像素之间。
一个非局部块是我们的基本单位,可以直接通过前馈方式捕捉这种时空依赖关系。
在一些非局部块中,我们的网络结构被称为非局部神经网络,
比2D或3D卷积网络(包括其变体)有更准确的视频分类效果。
另外,非局部神经网络有比3D卷积网络有更低的计算开销。
我们在Kinetics和Charades数据集上进行了详细的研究(分别进行了光流、多尺度测试)。
我们的方法在所有数据集上都能获得比最新方法更好的结果。
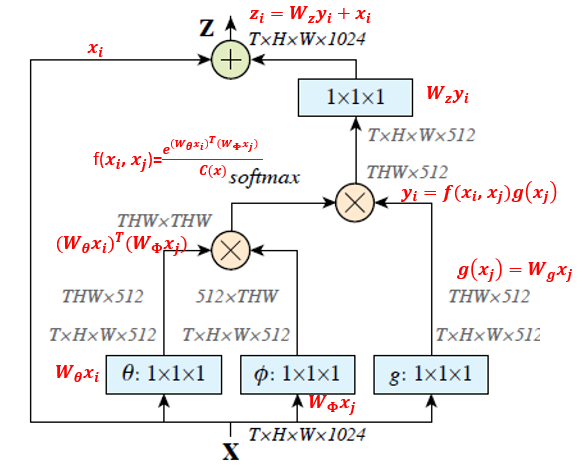
Non-local算法代码解析

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/152012.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
