大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
和“SPSS学习笔记”的其他方法不同,卡方检验是针对计数资料的
目录
一、卡方检验、Fisher精确检验(2*2)
分析:
案例:该医生招募了100名研究对象,按照吸烟状态分为两组,其中吸烟者52人,不吸烟者48人,探讨吸烟与阿尔兹海默症之间的关联性
需要先满足4项假设:
假设1:存在两个二分类变量,如本研究中的吸烟和阿尔兹海默症都是二分类变量。
假设2:存在2个分组,如本研究有2种不同的吸烟状态。
假设3:具有相互独立的观测值,如本研究中各位研究对象的信息都是独立的。
假设4:样本量足够大,最小的样本量要求为分析中的任一单元格期望频数大于5。
建立检验假设,确定检验水准:
H0:两种治疗方法的有效率相同
H1:两种治疗方法的有效率不相同
检验水准α=0.05
操作:
1、数据-个案加权
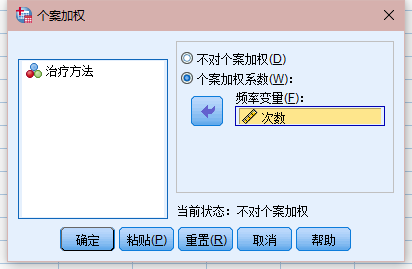

2、分析-描述统计-交叉表(行:方法 列:结果)
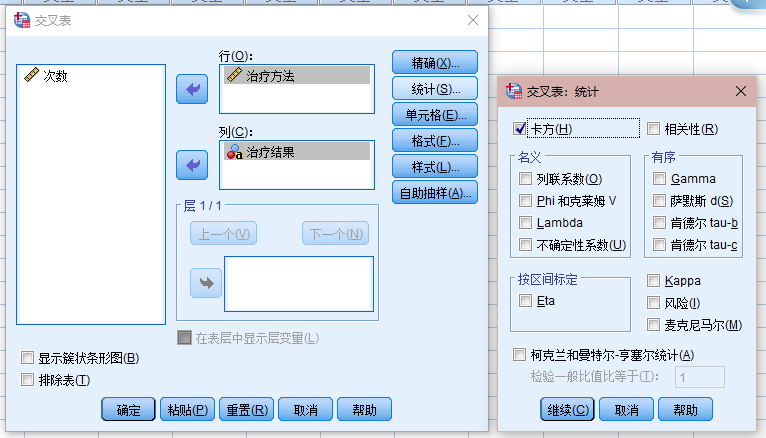
结果及分析:
- 本研究招募招募了100名研究对象,其中吸烟者52人,不吸烟者48人。经过长期随访,吸烟者有31人发生阿尔兹海默症(59.6%),不吸烟者有18人发生阿尔兹海默症(37.5%)
- 当总例数n≥40,最小期望计数>5,看第一个数;
当总例数n≥40,最小期望计数1-5,看第二个数;
当总例数n<40或最小期望计数<1,看第三个数
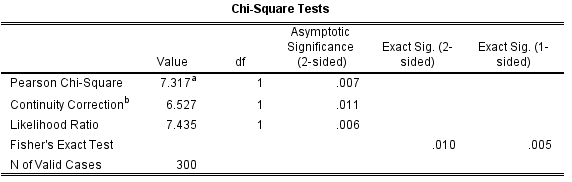
3、本研究中所有单元格的最小期望频数为【】,均大于5,样本量满足Pearson卡方检验的要求。所以使用Chi-Square Tests表格中的Pearson卡方检验的结果,X2==【】,P值=【】,按α=0.05检验水准,P<0.05,拒绝H0,差异有统计学意义,可以认为【。。不同】。结合Crosstabulation表格中,吸烟者发生阿尔兹海默症的比例为59.6%,可知吸烟者发生阿尔兹海默症的风险更高
二、卡方检验(R×C)
分析:
案例:某研究人员拟分析血型和职业之间的关系,共招募了333位研究对象,收集他们的血型(blood_type)和职业(occupation)信息。其中血型分为A、B、AB、O型共4种,职业分为律师(Lawyer)、医生(Doctor)、教师(Teacher)和工人(Worker)。
先满足3项假设:
假设1:存在两个无序多分类变量,如本研究中血型和职业类型均为无序分类变量。
假设2:具有相互独立的观测值,如本研究中各位研究对象的信息都是独立的
假设3:样本量足够大,最小的样本量要求为分析中的任一单元格期望频数大于5。
建立检验假设,确定检验水准:
H0:三种药物治疗中风的有效率相同
H1:三种药物治疗中风的有效率不全相同
检验水准α=0.05
操作:
1、数据-个案加权
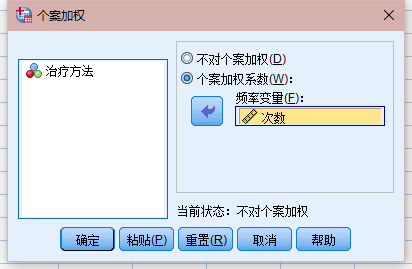
2、分析-描述统计-交叉表 (行:方法 列:结果)
结果及分析:
本研究招募了333位研究对象,分析血型和职业类型的关系。
1、卡方检验(R×C)结果显示χ2=42.959,P < 0.001,按α=0.05的检验水准,拒绝H0,差异有统计学意义,提示不同血型的研究对象职业类型不同,两者之间存在一定的相关性。
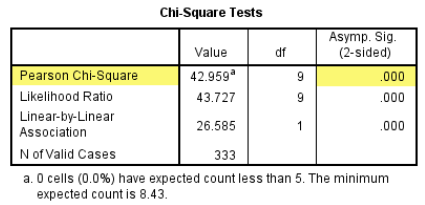
2、如果想了解血型与职业类型之间的相关强度,可以参看SPSS输出的Symmetric Measures表格。Phi(φ)(仅适用于2×2的数据格式)和Cramer’s V系数(适用范围较广)均是提供分类变量相关强度的指数。Cramer’s V系数的取值范围在0到1之间,数值越大相关性越强。
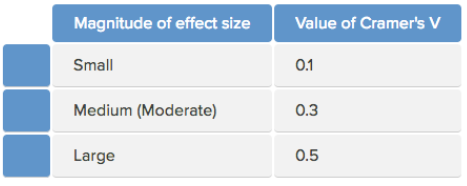
血型与职业类型之间存在弱相关性,Cramer’s V = 0.207,P < 0.001

三、配对卡方检验
分析:
把每一份样本平均分成两份,分别用两种方法进行化验,比较此两种化验方法的结果(两类计数资料)是否有本质的不同;或者分别采用甲、乙两种方法对同一批病人进行检查,比较此两种检查方法的阴阳性结果(两类计数资料)是否有本质的不同
案例:某研究者想要观察戒酒干预的效果,招募了50名研究对象,其中饮酒者24名,不饮酒者各26名。研究者收集了所有研究对象的干预前饮酒状态(before)和干预后饮酒状态(after)。两个变量均为二分类变量,即不饮酒与饮酒(分别赋值为1和2)
研究者想了解同一人群干预前后的饮酒状态,且饮酒状态为二分类变量。需要先满足2项假设。
假设1:观测变量为二分类,且两类之间互斥。
假设2:分组变量包含2个分类,且相关。
建立检验假设,确定检验水准:
H0:两种方法检测【】的阳性率相同
H1:两种方法检测【】的阳性率不同
检验水准α=0.05
操作:
1、数据-个案加权
2、分析-非参数检验-相关样本
结果及分析:
1、本研究招募了50例研究对象参与有关戒酒的干预试验,干预前饮酒者和不饮酒者各占52%和48%。干预后,不饮酒者比例增加到72%(36例),饮酒者比例降低至28%(14例)。15例饮酒者在干预后戒酒,另有5例不饮酒者在干预后开始饮酒。
2、如果非对角线的格子(左下和右上背景标黄的格子)中研究对象总数小于等于25时,采用精确法计算。
本例非对角线格子的观测数为20(15+5=20),小于25,因此采用McNemar精确检验发现,P=0.041,按检验水准α=0.05,P<0.05,拒绝原假设H0,干预前后不饮酒者比例的差异有统计学意义。
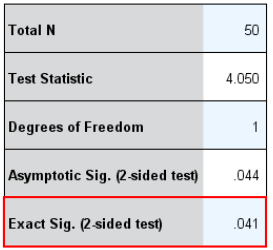
或者(观测数为【】,大于25,采用校正卡方检验发现。。)
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/180152.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
