大家好,又见面了,我是你们的朋友全栈君。
硬盘的种类主要是SCSI 、IDE 、以及现在流行的SATA等;任何一种硬盘的生产都要一定的标准;随着相应的标准的升级,硬盘生产技术也在升级;比如 SCSI标准已经经历了SCSI-1 、SCSI-2、SCSI-3;其中目前咱们经常在服务器网站看到的 Ultral-160就是基于SCSI-3标准的;IDE 遵循的是ATA标准,而目前流行的SATA,是ATA标准的升级版本;IDE是并口设备,而SATA是串口,SATA的发展目的是替换IDE;
我们知道信息存储在硬盘里,把它拆开也看不见里面有任何东西,只有些盘片。假设,你用显微镜把盘片放大,会看见盘片表面凹凸不平,凸起的地方被磁化,凹的地方是没有被磁化;凸起的地方代表数字1(磁化为1),凹的地方代表数字0。因此硬盘可以以二进制来存储表示文字、图片等信息。
1、硬盘的组成
硬盘大家一定不会陌生,我们可以把它比喻成是我们电脑储存数据和信息的大仓库。一般说来,无论哪种硬盘,都是由盘片、磁头、盘片主轴、控制电机、磁头控制器、数据转换器、接口、缓存等几个部份组成。


平面图:
立体图
所有的盘片都固定在一个旋转轴上,这个轴即盘片主轴。而所有盘片之间是绝对平行的,在每个盘片的存储面上都有一个磁头,磁头与盘片之间的距离比头发 丝的直径还小。所有的磁头连在一个磁头控制器上,由磁头控制器负责各个磁头的运动。磁头可沿盘片的半径方向动作,(实际是斜切向运动),每个磁头同一时刻也必须是同轴的,即从正上方向下看,所有磁头任何时候都是重叠的(不过目前已经有多磁头独立技术,可不受此限制)。而盘片以每分钟数千转到上万转的速度在高速旋转,这样磁头就能对盘片上的指定位置进行数据的读写操作。

由于硬盘是高精密设备,尘埃是其大敌,所以必须完全密封。
2、硬盘的工作原理
硬盘在逻辑上被划分为磁道、柱面以及扇区.
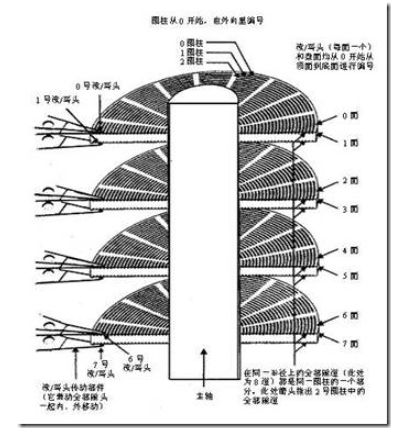
硬盘的每个盘片的每个面都有一个读写磁头,磁盘盘面区域的划分如图所示。
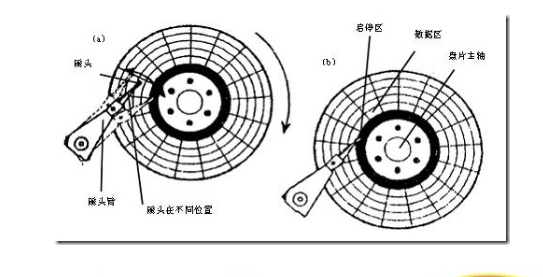
磁头靠近主轴接触的表面,即线速度最小的地方,是一个特殊的区域,它不存放任何数据,称为启停区或着陆区(LandingZone),启停区外就是数据区。在最外圈,离主轴最远的地方是“0”磁道,硬盘数据的存放就是从最外圈开始的。那么,磁头是如何找到“0”磁道的位置的 呢?在硬盘中还有一个叫“0”磁道检测器的构件,它是用来完成硬盘的初始定位。“0”磁道是如此的重要,以致很多硬盘仅仅因为“0”磁道损坏就报废,这是 非常可惜的。
早期的硬盘在每次关机之前需要运行一个被称为Parking的程序,其作用是让磁头回到启停区。现代硬盘在设计上已摒弃了这个虽不复杂却很让人不愉快的小缺陷。硬盘不工作时,磁头停留在启停区,当需要从硬盘读写数据时,磁盘开始旋转。旋转速度达到额定的高速时,磁头就会因盘片旋转产生的气流而抬起, 这时磁头才向盘片存放数据的区域移动。
盘片旋转产生的气流相当强,足以使磁头托起,并与盘面保持一个微小的距离。这个距离越小,磁头读写数据的灵敏度就越高,当然对硬盘各部件的要求也越 高。早期设计的磁盘驱动器使磁头保持在盘面上方几微米处飞行。稍后一些设计使磁头在盘面上的飞行高度降到约0.1μm~0.5μm,现在的水平已经达到 0.005μm~0.01μm,这只是人类头发直径的千分之一。
气流既能使磁头脱离开盘面,又能使它保持在离盘面足够近的地方,非常紧密地跟随着磁盘表面呈起伏运动,使磁头飞行处于严格受控状态。磁头必须飞行在盘面上方,而不是接触盘面,这种位置可避免擦伤磁性涂层,而更重要的是不让磁性涂层损伤磁头。
但是,磁头也不能离盘面太远,否则,就不能使盘面达到足够强的磁化,难以读出盘上的磁化翻转(磁极转换形式,是磁盘上实际记录数据的方式)。
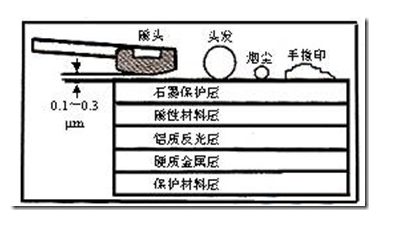
硬盘驱动器磁头的飞行悬浮高度低、速度快,一旦有小的尘埃进入硬盘密封腔内,或者一旦磁头与盘体发生碰撞,就可能造成数据丢失,形成坏块,甚至造成 磁头和盘体的损坏。所以,硬盘系统的密封一定要可靠,在非专业条件下绝对不能开启硬盘密封腔,否则,灰尘进入后会加速硬盘的损坏。另外,硬盘驱动器磁头的寻道伺服电机多采用音圈式旋转或直线运动步进电机,在伺服跟踪的调节下精确地跟踪盘片的磁道,所以,硬盘工作时不要有冲击碰撞,搬动时要小心轻放。
这种硬盘就是采用温彻斯特(Winchester)技术制造的硬盘,所以也被称为温盘,目前绝大多数硬盘都采用此技术。
3、盘面、磁道、柱面和扇区
硬盘的读写是和扇区有着紧密关系的。在说扇区和读写原理之前先说一下和扇区相关的”盘面”、“磁道”、和“柱面”。
1. 盘面
硬盘的盘片一般用铝合金材料做基片,高速硬盘也可能用玻璃做基片。硬盘的每一个盘片都有两个盘面(Side),即上、下盘面,一般每个盘面都会利用,都可以存储数据,成为有效盘片,也有极个别的硬盘盘面数为单数。每一个这样的有效盘面都有一个盘面号,按顺序从上至下从“0”开始依次编号。在硬盘系统中,盘面号又叫磁头号,因为每一个有效盘面都有一个对应的读写磁头。硬盘的盘片组在2~14片不等,通常有2~3个盘片,故盘面号(磁头号)为0~3或 0~5。
2. 磁道
磁盘在格式化时被划分成许多同心圆,这些同心圆轨迹叫做磁道(Track)。磁道从外向内从0开始顺序编号。硬盘的每一个盘面有300~1 024个磁道,新式大容量硬盘每面的磁道数更多。信息以脉冲串的形式记录在这些轨迹中,这些同心圆不是连续记录数据,而是被划分成一段段的圆弧,这些圆弧的角速度一样。由于径向长度不一样,所以,线速度也不一样,外圈的线速度较内圈的线速度大,即同样的转速下,外圈在同样时间段里,划过的圆弧长度要比内圈 划过的圆弧长度大。每段圆弧叫做一个扇区,扇区从“1”开始编号,每个扇区中的数据作为一个单元同时读出或写入。一个标准的3.5寸硬盘盘面通常有几百到几千条磁道。磁道是“看”不见的,只是盘面上以特殊形式磁化了的一些磁化区,在磁盘格式化时就已规划完毕。
3. 柱面
所有盘面上的同一磁道构成一个圆柱,通常称做柱面(Cylinder),每个圆柱上的磁头由上而下从“0”开始编号。数据的读/写按柱面进行,即磁 头读/写数据时首先在同一柱面内从“0”磁头开始进行操作,依次向下在同一柱面的不同盘面即磁头上进行操作,只在同一柱面所有的磁头全部读/写完毕后磁头 才转移到下一柱面(同心圆的再往里的柱面),因为选取磁头只需通过电子切换即可,而选取柱面则必须通过机械切换。电子切换相当快,比在机械上磁头向邻近磁道移动快得多,所以,数据的读/写按柱面进行,而不按盘面进行。也就是说,一个磁道写满数据后,就在同一柱面的下一个盘面来写,一个柱面写满后,才移到下一个扇区开始写数据。读数据也按照这种方式进行,这样就提高了硬盘的读/写效率。
一块硬盘驱动器的圆柱数(或每个盘面的磁道数)既取决于每条磁道的宽窄(同样,也与磁头的大小有关),也取决于定位机构所决定的磁道间步距的大小。
4.扇区
操作系统以扇区(Sector)形式将信息存储在硬盘上,每个扇区包括512个字节的数据和一些其他信息。一个扇区有两个主要部分:存储数据地点的标识符和存储数据的数据段。
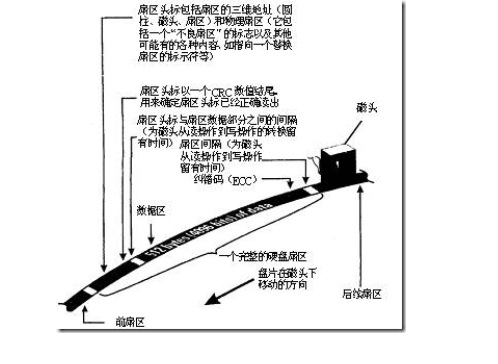
扇区的第一个主要部分是标识符。标识符,就是扇区头标,包括组成扇区三维地址的三个数字:
盘面号:扇区所在的磁头(或盘面)
柱面号:磁道,确定磁头的径向方向。
扇区号:在磁道上的位置。也叫块号。确定了数据在盘片圆圈上的位置。
头标中还包括一个字段,其中有显示扇区是否能可靠存储数据,或者是否已发现某个故障因而不宜使用的标记。有些硬盘控制器在扇区头标中还记录有指示字,可在原扇区出错时指引磁盘转到替换扇区或磁道。最后,扇区头标以循环冗余校验(CRC)值作为结束,以供控制器检验扇区头标的读出情况,确保准确无误。
扇区的第二个主要部分是存储数据的数据段,可分为数据和保护数据的纠错码(ECC)。在初始准备期间,计算机用512个虚拟信息字节(实际数据的存放地)和与这些虚拟信息字节相应的ECC数字填入这个部分。
5. 访盘请求完成过程 :
确定磁盘地址(柱面号,磁头号,扇区号),内存地址(源/目):
当需要从磁盘读取数据时,系统会将数据逻辑地址传给磁盘,磁盘的控制电路按照寻址逻辑将逻辑地址翻译成物理地址,即确定要读的数据在哪个磁道,哪个扇区。
为了读取这个扇区的数据,需要将磁头放到这个扇区上方,为了实现这一点:
1)首先必须找到柱面,即磁头需要移动对准相应磁道,这个过程叫做寻道,所耗费时间叫做寻道时间,
2)然后目标扇区旋转到磁头下,即磁盘旋转将目标扇区旋转到磁头下。这个过程耗费的时间叫做旋转时间。
即一次访盘请求(读/写)完成过程由三个动作组成:
1)寻道(时间):磁头移动定位到指定磁道
2)旋转延迟(时间):等待指定扇区从磁头下旋转经过
3)数据传输(时间):数据在磁盘与内存之间的实际传输
因此在磁盘上读取扇区数据(一块数据)所需时间:
Ti/o=tseek +tla + n *twm
其中:
tseek 为寻道时间
tla为旋转时间
twm 为传输时间
4、磁盘的读写原理
系统将文件存储到磁盘上时,按柱面、磁头、扇区的方式进行,即最先是第1磁道的第一磁头下(也就是第1盘面的第一磁道)的所有扇区,然后,是同一柱面的下一磁头,……,一个柱面存储满后就推进到下一个柱面,直到把文件内容全部写入磁盘。
(文件的记录在同一盘组上存放是,应先集中放在一个柱面上,然后再顺序存放在相邻的柱面上,对应同一柱面,则应该按盘面的次序顺序存放。)
(从上到下,然后从外到内。数据的读/写按柱面进行,而不按盘面进行,先)
系统也以相同的顺序读出数据。读出数据时通过告诉磁盘控制器要读出扇区所在的柱面号、磁头号和扇区号(物理地址的三个组成部分)进行。磁盘控制器则 直接使磁头部件步进到相应的柱面,选通相应的磁头,等待要求的扇区移动到磁头下。在扇区到来时,磁盘控制器读出每个扇区的头标,把这些头标中的地址信息与期待检出的磁头和柱面号做比较(即寻道),然后,寻找要求的扇区号。待磁盘控制器找到该扇区头标时,根据其任务是写扇区还是读扇区,来决定是转换写电路, 还是读出数据和尾部记录。找到扇区后,磁盘控制器必须在继续寻找下一个扇区之前对该扇区的信息进行后处理。如果是读数据,控制器计算此数据的ECC码,然 后,把ECC码与已记录的ECC码相比较。如果是写数据,控制器计算出此数据的ECC码,与数据一起存储。在控制器对此扇区中的数据进行必要处理期间,磁 盘继续旋转。
5、局部性原理与磁盘预读
由于存储介质的特性,磁盘本身存取就比主存慢很多,再加上机械运动耗费,磁盘的存取速度往往是主存的几百分分之一,因此为了提高效率,要尽量减少磁盘I/O。为了达到这个目的,磁盘往往不是严格按需读取,而是每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。这样做的理论依据是计算机科学中著名的局部性原理:
当一个数据被用到时,其附近的数据也通常会马上被使用。
程序运行期间所需要的数据通常比较集中。
由于磁盘顺序读取的效率很高(不需要寻道时间,只需很少的旋转时间),因此对于具有局部性的程序来说,预读可以提高I/O效率。
预读的长度一般为页(page)的整倍数。页是计算机管理存储器的逻辑块,硬件及操作系统往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页(在许多操作系统中,页得大小通常为4k),主存和磁盘以页为单位交换数据。当程序要读取的数据不在主存中时,会触发一个缺页异常,此时系统会向磁盘发出读盘信号,磁盘会找到数据的起始位置并向后连续读取一页或几页载入内存中,然后异常返回,程序继续运行。
6、磁盘碎片的产生
俗话说一图胜千言,先用一张ACSII码图来解释为什么会产生磁盘碎片。

上面的ASCII图表示磁盘文件系统,由于目前上面没有任何数据文件,所以我把他表示成0。
在图的最上侧和左侧各有a-z 26个字母,这是用来定位每个数据字节的具体位置,如第1行1列是aa,26行26列是zz。
我们创建一个新文件,理所当然的,我们的文件系统就产生了变化,现在是
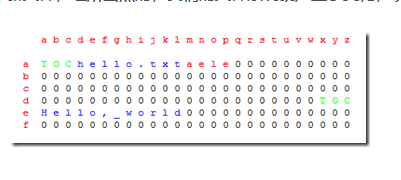
如图所示:”内容表”(TOC)占据了前四行,在TOC里存贮着每件文件在系统里所在的位置。
在上图,TOC包括了一个名字叫hello.txt的文件,其具体内容是”Hello, world”,在系统里的位置是ae到le。
接下来再新建一个文件

如图,我们新建的文件bye.txt紧贴着第一个文件hello.txt。
其实这是最理想的系统结构,如果你将你的文件都按照上图所表示的那样一个挨着一个,紧紧的贴放在一起的话,那么读取他们将会非常的容易和迅速,这是因为在硬盘里动得最慢的(相对来说)就是传动手臂,少位移一些,读取文件数据的时间就会快一些。
然而恰恰这就是问题的所在。现在我想在”Hello, World”后加上些感叹号来表达我强烈的感情,现在的问题是:在这样的系统上,文件所在的行就没有地方让我放这些感叹号了,因为bye.txt占据了剩下的位置。
现在有俩个方法可以选择,但是没有一个是完美的
1.我们从原位置删除文件,重新建个文件重新写上”Hello, World!!”. –这就无意中延长了文件系统的读和写的时间。
2.打碎文件,就是在别的空的地方写上感叹号,也就是”身首异处”–这个点子不错,速度很快,而且方便,但是,这就同时意味着大大的减慢了读取下一个新文件的时间。
如果你对上面的文字没概念,上图

这里所说的方法二就像是我们的windows系统的存储方式,每个文件都是紧挨着的,但如果其中某个文件要更改的话,那么就意味着接下来的数据将会被放在磁盘其他的空余的地方。
如果这个文件被删除了,那么就会在系统中留下空格,久而久之,我们的文件系统就会变得支离破碎,碎片就是这么产生的。
试着简单点,讲给mm听的硬盘读写原理简化版
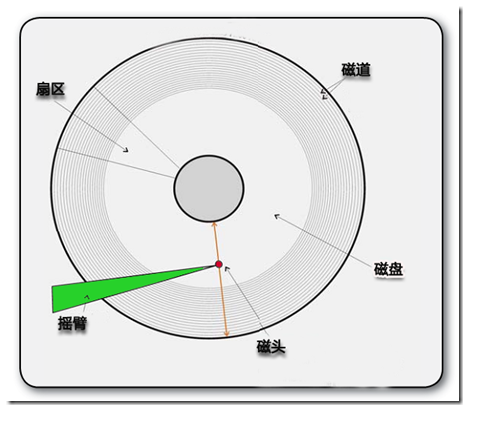
硬盘的结构就不多说了,我们平常电脑的数据都是存在磁道上的,大致上和光盘差不多.读取都是靠磁头来进行.
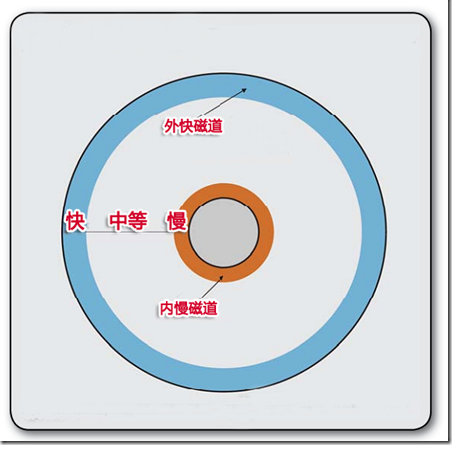
我们都知道,我们的数据资料都是以信息的方式存储在盘面的扇区的磁道上,硬盘读取是由摇臂控制磁头从盘面的外侧向内侧进行读写的.所以外侧的数据读取速度会比内侧的数据快很多.

其实我们的文件大多数的时候都是破碎的,在文件没有破碎的时候,摇臂只需要寻找1次磁道并由磁头进行读取,只需要1次就可以成功读取;但是如果文件破碎成 11处,那么摇臂要来回寻找11次磁道磁头进行11次读取才能完整的读取这个文件,读取时间相对没有破碎的时候就变得冗长.
因此,磁盘碎片往往也是拖慢系统的重要因素之一,Vista之家团队也计划在Vista优化大师后续版本内加入磁盘碎片整理功能,敬请期待。
7、硬盘容量及分区大小的计算
在linux系统,要计算硬盘容量及分区大小,我们先通过fdsik -l查看硬盘信息:
Disk /dev/hda: 80.0 GB, 80026361856 bytes
255 heads, 63 sectors/track, 9729 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System
/dev/hda1 * 1 765 6144831 7 HPFS/NTFS
/dev/hda2 766 2805 16386300 c W95 FAT32 (LBA)
/dev/hda3 2806 9729 55617030 5 Extended
/dev/hda5 2806 3825 8193118+ 83 linux
/dev/hda6 3826 5100 10241406 83 linux
/dev/hda7 5101 5198 787153+ 82 linux swap / Solaris
/dev/hda8 5199 6657 11719386 83 linux
/dev/hda9 6658 7751 8787523+ 83 linux
/dev/hda10 7752 9729 15888253+ 83 linux
其中
heads 是磁盘面;
sectors 是扇区;
cylinders 是柱面;
每个扇区大小是 512byte,也就是0.5K;
通过上面的例子,我们发现此硬盘有 255个磁盘面,有63个扇区,有9729个柱面;所以整个硬盘体积换算公式应该是:
磁面个数 * 扇区个数 * 每个扇区的大小512 * 柱面个数 = 硬盘体积 (单位bytes)
所以在本例中磁盘的大小应该计算如下:
255 x 63 x 512 x 9729 = 80023749120 bytes
提示:由于硬盘生产商和操作系统换算不太一样,硬盘厂家以10进位的办法来换算,而操作系统是以2进位制来换算,所以在换算成M或者G 时,不同的算法结果却不一样;所以我们的硬盘有时标出的是80G,在操作系统下看却少几M;
上面例子中,硬盘厂家算法 和 操作系统算数比较:
硬盘厂家: 80023749120 bytes = 80023749.120 K = 80023.749120 M (向大单位换算,每次除以1000)
操作系统: 80023749120 bytes = 78148192.5 K = 76316.594238281 M (向大单位换算,每次除以1024)
我们在查看分区大小的时候,可以用生产厂家提供的算法来简单推算分区的大小;把小数点向前移动六位就是以G表示的大小;比如 hda1 的大小约为 6.144831G ;
磁盘阵列
磁盘阵列是由很多块独立的磁盘,组合成一个容量巨大的磁盘组,利用个别磁盘提供数据所产生加成效果提升整个磁盘系统效能。利用这项技术,将数据切割成许多区段,分别存放在各个硬盘上。
独立磁盘冗余阵列(RAID,redundant array of independent disks)是把相同的数据存储在多个硬盘的不同的地方(因此,冗余地)的方法。通过把数据放在多个硬盘上,输入输出操作能以平衡的方式交叠,改良性能。因为多个硬盘增加了平均故障间隔时间(MTBF),储存冗余数据也增加了容错。
RAID技术主要有以下三个基本功能:
(1)通过对磁盘上的数据进行条带化,实现对数据成块存取,减少磁盘的机械寻道时间,提高了数据存取速度。
(2)通过对一个阵列中的几块磁盘同时读取,减少了磁盘的机械寻道时间,提高数据存取速度。
(3)通过镜像或者存储奇偶校验信息的方式,实现了对数据的冗余保护。
优点
1)提高传输速率。RAID通过在多个磁盘上同时存储和读取数据来大幅提高存储系统的数据吞吐量(Throughput)。在RAID中,可以让很多磁盘驱动器同时传输数据,而这些磁盘驱动器在逻辑上又是一个磁盘驱动器,所以使用RAID可以达到单个磁盘驱动器几倍、几十倍甚至上百倍的速率。这也是RAID最初想要解决的问题。因为当时CPU的速度增长很快,而磁盘驱动器的数据传输速率无法大幅提高,所以需要有一种方案解决二者之间的矛盾。RAID最后成功了。
2)通过数据校验提供容错功能。普通磁盘驱动器无法提供容错功能,如果不包括写在磁盘上的CRC(循环冗余校验)码的话。RAID容错是建立在每个磁盘驱动器的硬件容错功能之上的,所以它提供更高的安全性。在很多RAID模式中都有较为完备的相互校验/恢复的措施,甚至是直接相互的镜像备份,从而大大提高了RAID系统的容错度,提高了系统的稳定冗余性。
缺点
RAID0没有冗余功能,如果一个磁盘(物理)损坏,则所有的数据都无法使用。
RAID1磁盘的利用率最高只能达到50%(使用两块盘的情况下),是所有RAID级别中最低的。
RAID0+1以理解为是RAID 0和RAID 1的折中方案。RAID 0+1可以为系统提供数据安全保障,但保障程度要比 Mirror低而磁盘空间利用率要比Mirror高。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/143627.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
