大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
在毕设中学习——卷积、python(0521)
2022.5.21
- np.random.normal()正态分布
numpy.random.normal(loc=0,scale=1e-2,size=shape)
意义如下:
- 参数loc(float):正态分布的均值,对应着这个分布的中心。loc=0说明这一个以Y轴为对称轴的正态分布,
- 参数scale(float):正态分布的标准差,对应分布的宽度,scale越大,正态分布的曲线越矮胖,scale越小,曲线越高瘦。
- 参数size(int 或者整数元组):输出的值赋在shape里,默认为None。
np.random.standard_normal(size=None)返回指定形状的标准正态分布的数组。
正态分布
期望值(均值)μ,标准差σ(方差开根号)
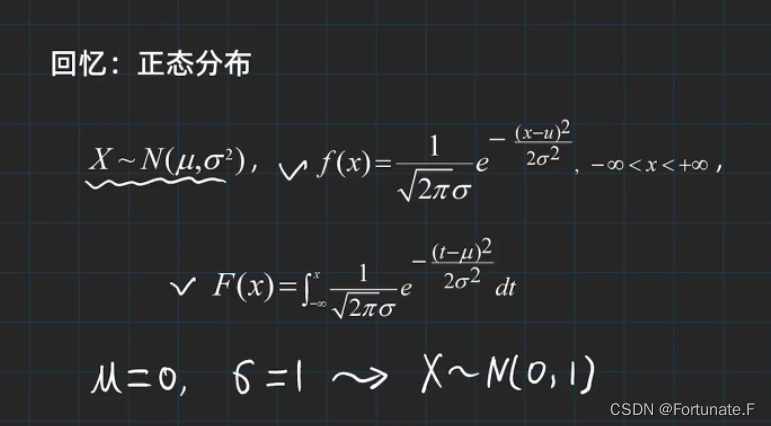

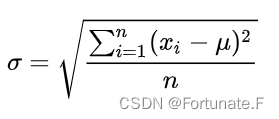
补充一下标准差:
标准差是一组数据平均值分散程度的一种度量。一个较小的标准差,代表这些数值较接近平均值。
两组数的集合{0,5,9,14}和{5,6,8,9}其平均值都是7,但第二个集合具有较小的标准差
-
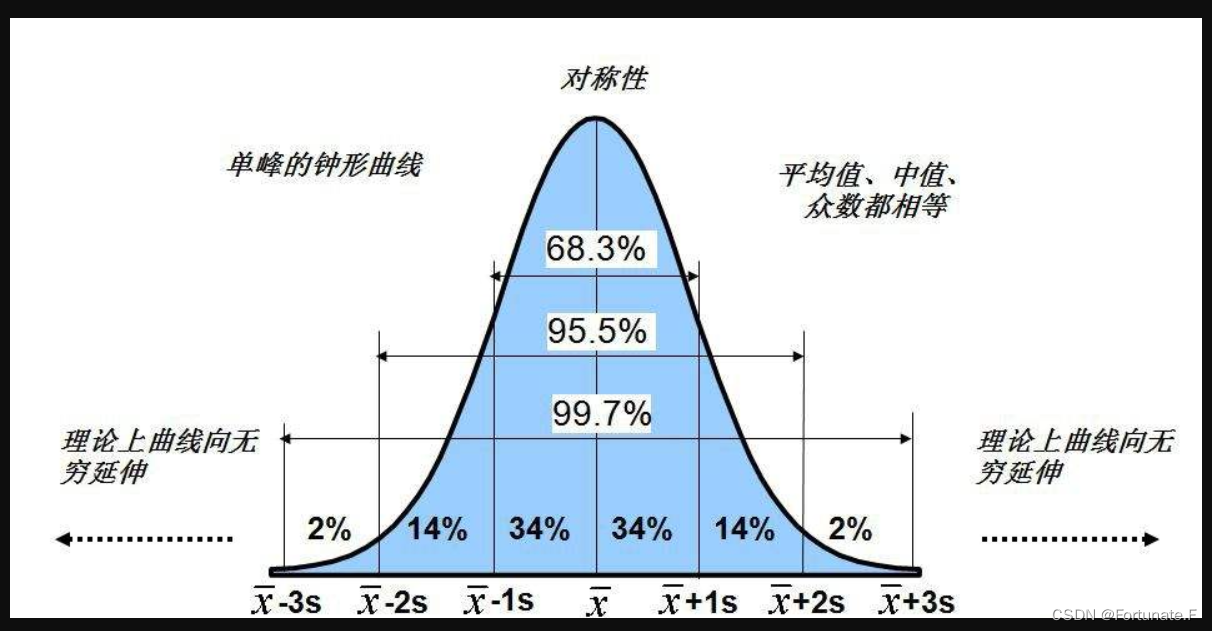
对称性质(那个小尾巴叫sigma)

-
最大值
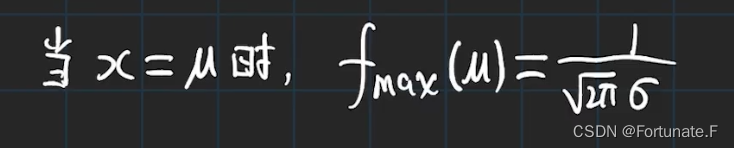
-
参数变化性质
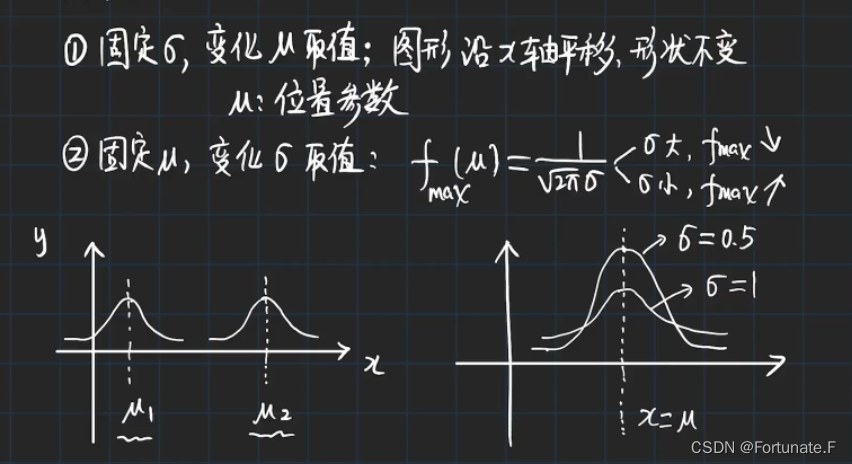

- sigma原则

- 正态分布图像
标准正态分布
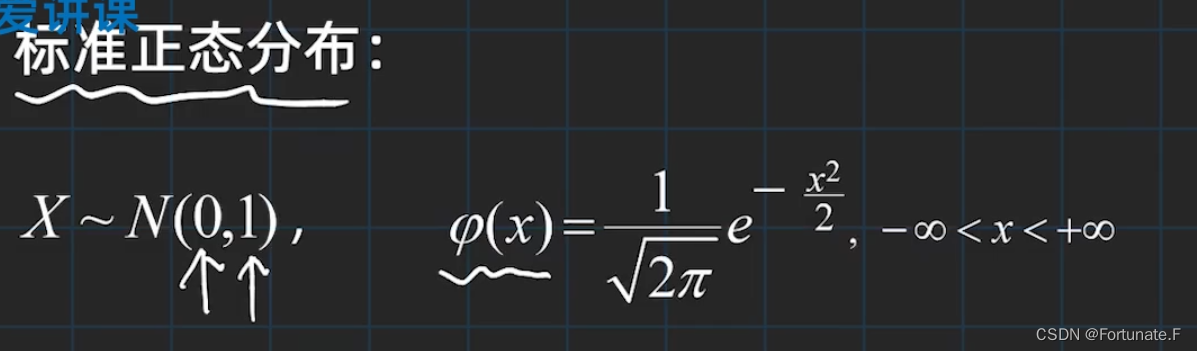
期望值μ=0,即曲线图象对称轴为Y轴,标准差σ=1条件下的正态分布,记为N(0,1)。
matplotlib.pyplot画图
引例
import matplotlib.pyplot as plt
import numpy as np
#随机生成100个符合标准正太分布的数(均值为0,方差为1)
# x1 = np.random.standard_normal(100)
x1 = np.random.normal()
print(x1)
# 画图看分布状况
# 1)创建画布
plt.figure(figsize=(20, 8), dpi=300) #画布长 宽 分辨率
# 2)绘制直方图
plt.hist(x1, 10) #参数1代表要使用的数据,参数2表示要划分区间数量
# 3)显示图像
plt.show()
- 关于matplotlib.pyplot
等待补充
Python中读取.mat文件
(针对的是BCI大赛第二届第三组数据-左右手运动想象EEG的matlab的训练集数据文件)
- .m文件是保存一段代码的文件,类似于C语言中的一个函数体; 这也是MATLAB中最常见的文件保存格式之一;
- .mat文件是matlab的数据存储的标准格式。也就是操作产生的数据的一个集合包,可以把一次处理的结果保存,供下一次使用。
import scipy.io as scio
import numpy as np
filepath = '文件路径' #注意路劲里的斜杠涉及到转义字符,要用双斜线
dict_labels = scio.loadmat(filepath) #获取到.m文件里的数据(数据类型是字典:6key-6value)
#查看数据类型print(type(变量名))
EEG_labels = dict_labels['x_test'] #这一步把'x_test'这个key对应的value给到了前面的变量
# 注解:
#本人所用的文件(dict_labels)的Key有六个,前三个是基本信息,后三个有用,如下
#dict_keys(['__header__', '__version__', '__globals__', 'Copyright', 'x_train', #'x_test', 'y_train'])
#查看这个文件的key值 a=dict_labels.keys(); print(a)
#查看这个文件的value值 b=dict_labels.values();print(b)
EEG_labels = np.array(EEG_labels) #将EEG_labels转换为矩阵数据
print(EEG_labels.shape) #输出这个矩阵的形状,发现是一个三维数组
#输出(1152, 3, 140)
#如果想要查看这个'x_test'对应的value的所有值
#print(EEG_labels)
#此处和上方输出值的时候由于数据量到达48万并且每个数据的小数位数都超过10位了,所以python会加省略号输出,导致我们无法看到数据原本的样子,可以再输出前加上下面这句,就不会有省略号
np.set_printoptions(threshold=sys.maxsize) #全部输出
#48万个数据确实很大,可以输出到文件
#(也就是完成了把.mat文件里的数据读出到普通文件)
# fp = open("新的文件地址", "a+")
#打开文件,a+表示,如果文件不存在就创建。存在就在文件内容的后面继续追加
# print(dict_labels.values(), file=fp) #这样就会输出到fp指向的文件
# fp.close() #关闭文件
#简单的说,打开.m文件:
# from scipy.io import loadmat
# a = loadmat('文件路径')
print(a)
print(type(a))
print(a.values()) //先确定a是字典类型哈
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/168456.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
