大家好,又见面了,我是你们的朋友全栈君。
经典的two stage检测网络有:faster RCNN和SSD,它们用于做bbox regression的模型各有不同,faster RCNN是VGG,feature map经过不断地下采样,最后的feature map送入RPN层,这样不断地下采样使得小检测框的像素非常小,无法进行训练的到,得到很好的结果。而SSD则是分别对不同尺寸的feature map进行bbox regression,这就导致尺寸较大的feature map没有高级语义,对于全局语义没有很好地提取,无法判断出物体的位置和大小,同样对小检测框没有很好的检测效果。FPN则解决了这个问题。
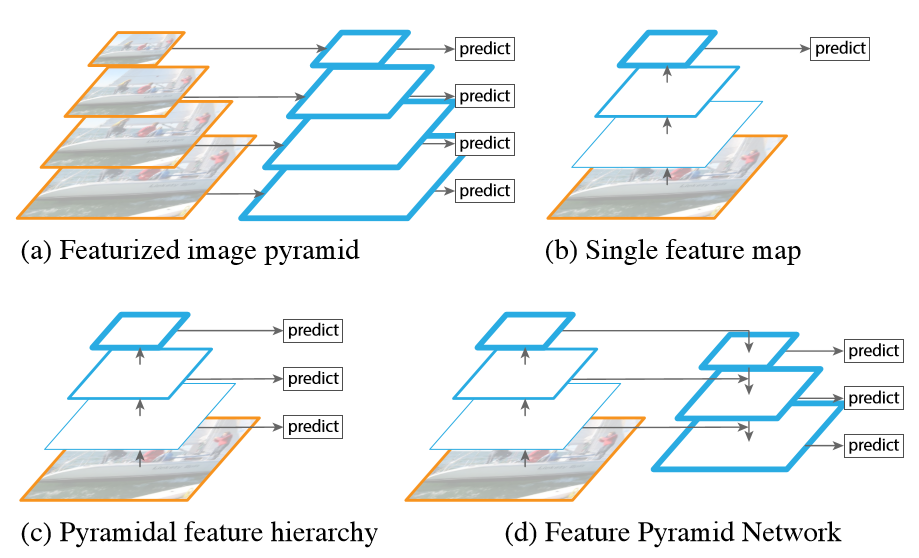

(a)是图像金字塔,我记得MTCNN中用的就是这个,这个很占用时间;(b)是常规的卷积网络,faster RCNN用的是这个;(c)是SSD的结构,SSD为了避免使用low-level的特征,放弃了浅层的feature map,而是从conv4_3开始建立金字塔,而且加入了一些新的层。因此SSD放弃了重利用更高分辨率的feature map,但是这些feature map对检测小目标非常重要。这就是SSD与FPN的区别;(d)是FPN,FPN是为了自然地利用CNN层级特征的金字塔形式,同时生成在所有尺度上都具有强语义信息的特征金字塔。所以FPN的结构设计了top-down结构和横向连接,以此融合具有高分辨率的浅层layer和具有丰富语义信息的深层layer。这样就实现了从单尺度的单张输入图像,快速构建在所有尺度上都具有强语义信息的特征金字塔,同时不产生明显的代价。
下面说一下长得很像的两个网络:
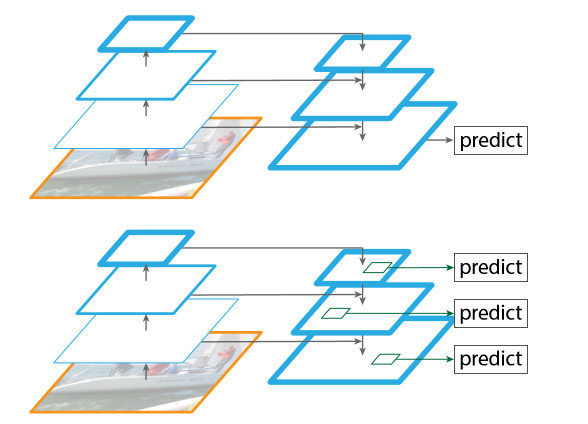
上面那张图并不是FPN,他只是用最后一张合成的feature map做预测,真实的feature map是每一层都用anchor做预测。事实证明,FPN的效果更好,因为在不同层使用anchor可以增加对于尺寸变化的鲁棒性。当然第一个也有anchor,它的数量即使远远大于FPN,效果也不如FPN,因为缺少鲁棒性。
下面说一下融合方式:
Bottom-up pathway
resnet的网络结构是这样的:他有4个stage,每个stage中的feature map尺寸都是一样的,stage之间用步长为2的3*3卷积做降采样。对于我们的特征金字塔,我们为每个stage定义了一个金字塔级别。我们选择每个stage的最后一层的输出作为我们的特征映射的参考集。因为每个阶段的最深层都应该具有最好的特征。具体来说,对于ResNets,我们使用每个stage最后一层的特征激活输出。对于conv2、conv3、conv4和conv5输出,我们将这些最后剩余块的输出表示为{C2、C3、C4、C5},并注意它们对输入图像的像素步长为{4、8、16、32}。由于conv1的内存占用很大,所以我们没有将它包括在金字塔中。
Top-down pathway and lateral connections.
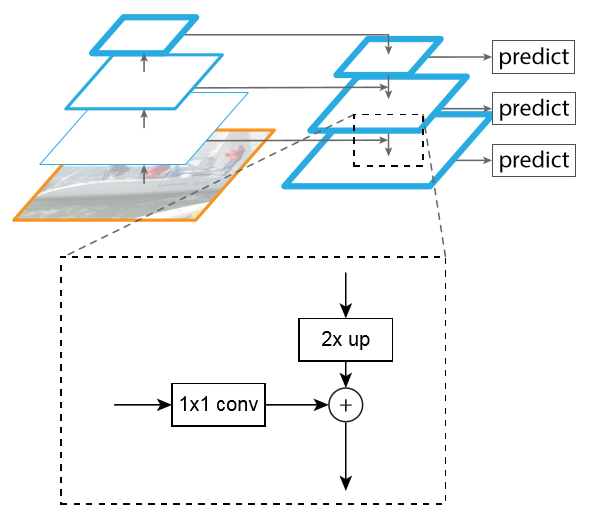
自顶向下路径通过从更高的金字塔层次上采样,从而产生更高分辨率的特征。这些特征通过自下而上的连接得到增强。每一个横向连接都融合了自底向上和自顶向下路径上相同空间尺度的特征图。自底向上的特征映射具有较低的语义级别,但更有利于定位,因为它的子采样次数更少。
它的连接过程为:首先使用上采样(如最近邻),然后使用1*1卷积核,改变channel,然后进行像素间相加,最后用3*3的卷积核处理已经融合的特征图,解决上采样带来的混叠效应。为了后面的应用能够在所有层级共享分类层,这里固定了3*3卷积后的输出通道为d,这里设为256.因此所有额外的卷积层(比如P2)具有256通道输出。这些额外层没有用非线性(实验发现作用很小)。{C2, C3, C4, C5}层对应的融合特征层为{P2, P3, P4, P5},对应的层空间尺寸是相通的。
FPN for RPN
RPN是一个与类别无关的,滑动窗口的检测器,它通过一个33的滑动卷积核,完成二分类和bbox的回归。他首先是一个33的卷积核,然后再是两个1*1的卷积核。但是现在要将FPN嵌在RPN网络中,生成不同尺度特征并融合作为RPN网络的输入。在每一个scale层,都定义了不同大小的anchor,对于 P 2 P_{2} P2, P 3 P_{3} P3, P 4 P_{4} P4, P 5 P_{5} P5, P 6 P_{6} P6这些层,定义anchor的大小为322,642,1282,2562,5122( P 6 P_{6} P6是对 P 5 P_{5} P5做stride=2的下采样),另外每个scale层都有3个长宽对比度:1:2,1:1,2:1。所以整个特征金字塔有15种anchor。
关于正负样本的选择,它和faster RCNN差不多,IOU>0.7的为正样本,<0.3的为负样本。
关于RPN层参数值(不同层的几个卷积核参数)有没有共享,作者做了一个实验,结果发现效果相同。这也间接地说明了,所有层的特征金字塔都有着相同的语义,这和图像金字塔大同小异。
Feature Pyramid Networks for Fast R-CNN
faster RCNN有ROI层,为了适应有FPN,ROI也有有不同的尺寸了。关于ROI映射的w,h,有如下公式:
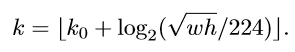
K 0 K_{0} K0取值为最后一层特征金字塔的编号,eg(5)(因为在论文中faster RCNN没有用 P 6 P_{6} P6),假设ROI是112 * 112的大小,那么 k = k 0 − 1 = 5 − 1 = 4 k = k_{0} – 1 = 5-1 = 4 k=k0−1=5−1=4,意味着该ROI应该使用 P 4 P_{4} P4的特征层。同时我们将ROI固定到7*7的feature的输出,然后再经过两个全连接层,再输出预测和分类。对于Resnet来说,conv4的层已经融合了conv5的语义,而且conv4的输出的特征金字塔不会在经过conv5,而是直接送入两个全连接层,weight会更少,而且更快。
Faster-RCNN利用conv1到conv4-x的91层为共享卷积层,然后从conv4-x的输出开始分叉,一路经过RPN网络进行区域选择,另一路直接连一个ROI Pooling层,把RPN的结果输入ROI Pooling层,映射成7 * 7的特征。
训练
这里说一下他训练的几个点吧
Implementation details
首先对image进行resize,短边有800像素,然后使用SGD,每个mini-batch有两张图片,每个图片有256个anchor,weight decay为0.0001,momentum为0.9,前30k的epoch,lr为0.02,后10k为0.002
关于测试结果对比,有一个博主整理的非常好,这里附上他的链接
我把这些总结用截图方式展示出来,便于大家查看
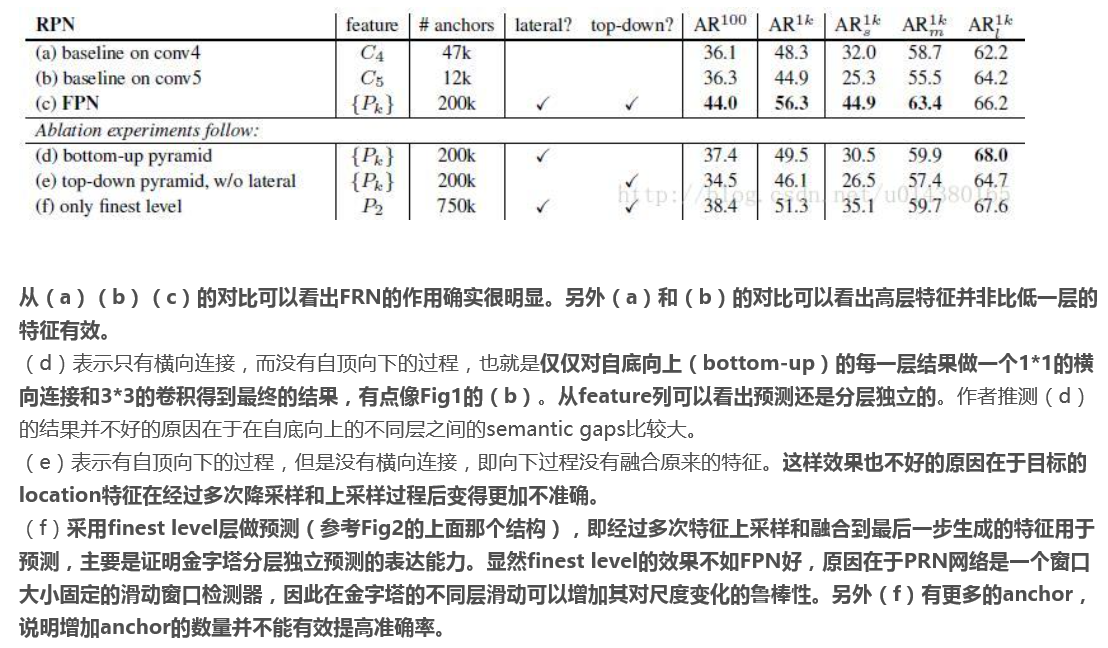
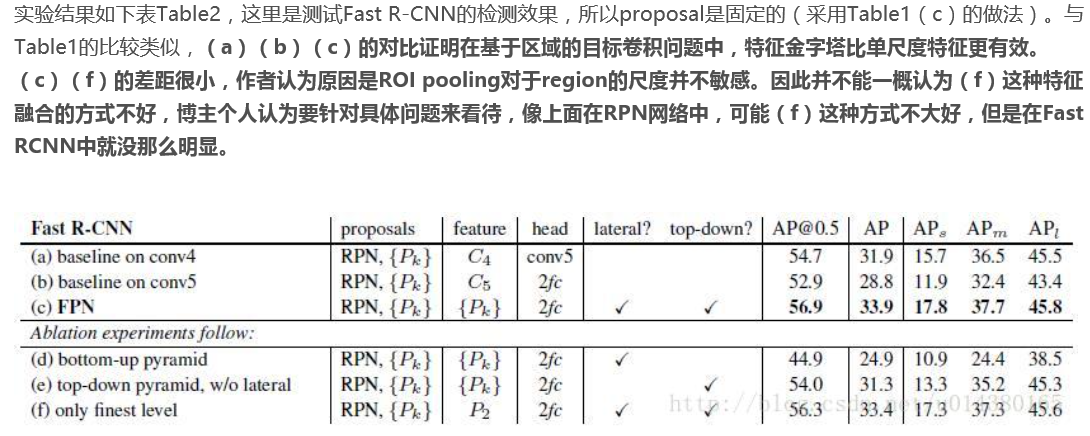
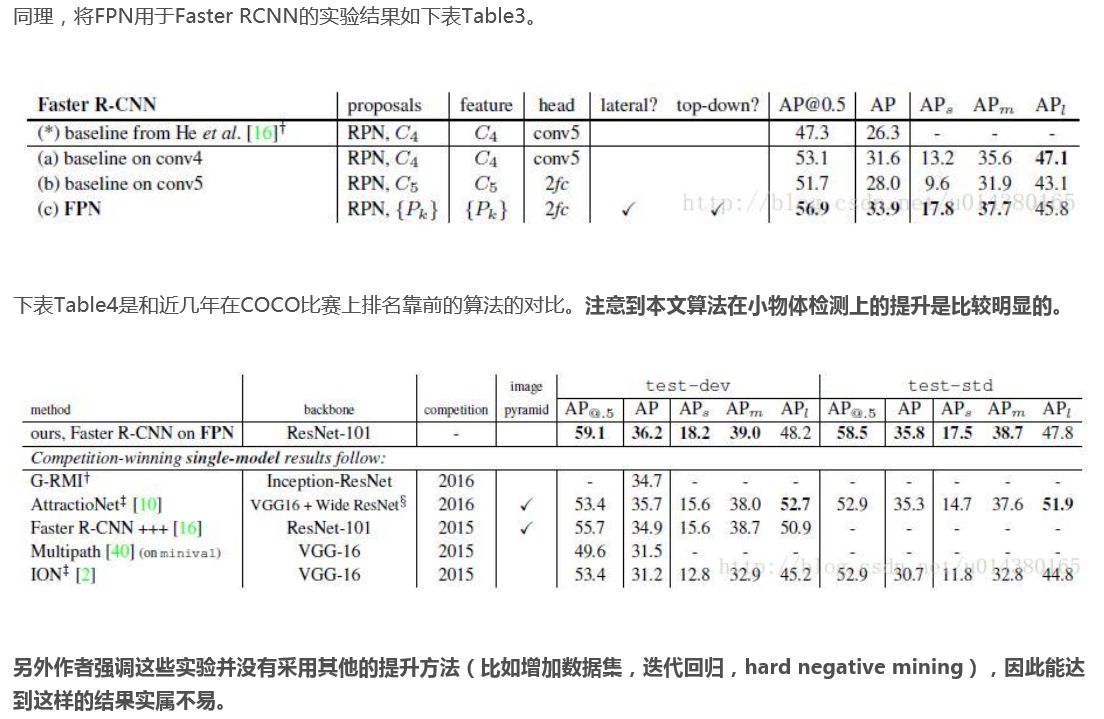
FPN也可以用于目标分割,这个后续再聊。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/134119.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
