大家好,又见面了,我是你们的朋友全栈君。
学过数据结构的人应该对Queue 队列很熟悉了,队列是一种先进先出(FIFO)的数据结构,所以它出队列的优先级就是进入队列的次序。但我们有时候需要其它的优先级,很多高级语言都会提供带优先级的队列,在Java中就是PriorityQueue了,今天我们来看下PriorityQueue的使用和实现。
使用
PriorityQueue的使用很简单,如下。
public static void main(String[] args) {
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>();
priorityQueue.add(1);
priorityQueue.add(2);
priorityQueue.add(3);
System.out.println(priorityQueue.poll());
}
如果Queue中元素是整数,其优先级是最小最优先,其它类型或者其它优先级需要传入自定义comparator。下面代码我把优先级定义为最大优先。
public static void main(String[] args) {
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2-o1;
}
});
priorityQueue.add(1);
priorityQueue.add(3);
priorityQueue.add(2);
System.out.println(priorityQueue.poll());
}
在Java8及以后,可以传入lambda表达式,使得代码更简洁。 PriorityQueue<Integer> priorityQueue = new PriorityQueue<>((x, y) -> (y - x));
堆
在看PriorityQueue之前,我们先来了解一个数据结构 堆,堆是优先队列的基础,它能够在O(logn)的时间复杂下为Queue里的每个元素确定优先级。在插入新元素和删除元素后也能在O(logn)的时间复杂下完成优先级的维护。
堆的定义
堆是一颗近似的完全二叉树,除了最底层外,所有非叶子节点都是有两个子节点。除最底层外,也是一颗完全满二叉树。真是因为它是一颗近似满二叉树,所有可以用数组来实现。它有个非常重要的性质,每个节点都比其左右子节点(如有)大(备注:本文以最大堆为例)。
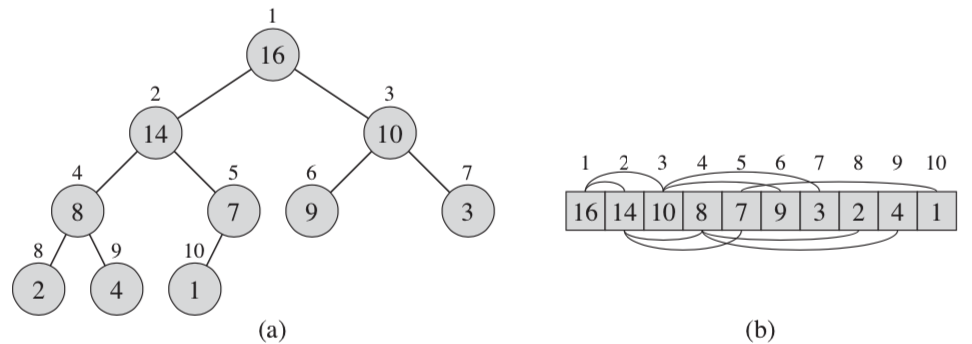

上图就是一颗最大堆,如果我们给每个节点按BFS次序编号,很容易发现编号x的节点左右子节点编号分别为2x和2x+1。所有可以采用图b的方式来存储一颗最大堆。通过这个性质可以很容易计算每个节点的父子节点编号。
堆性质的维护
堆最重要的性质,每个节点都比其左右子节点(如有)大。可能会在插入或者删除元素后遭到破坏,这个时候就需要每次修改操作后对其该性质做一次维护。 堆的维护很简单,只有两个操作,如果某个节点值大于父节点,就是上移,小于子节点就下移,下面两幅图分别展示了下移和上移的操作。
下移
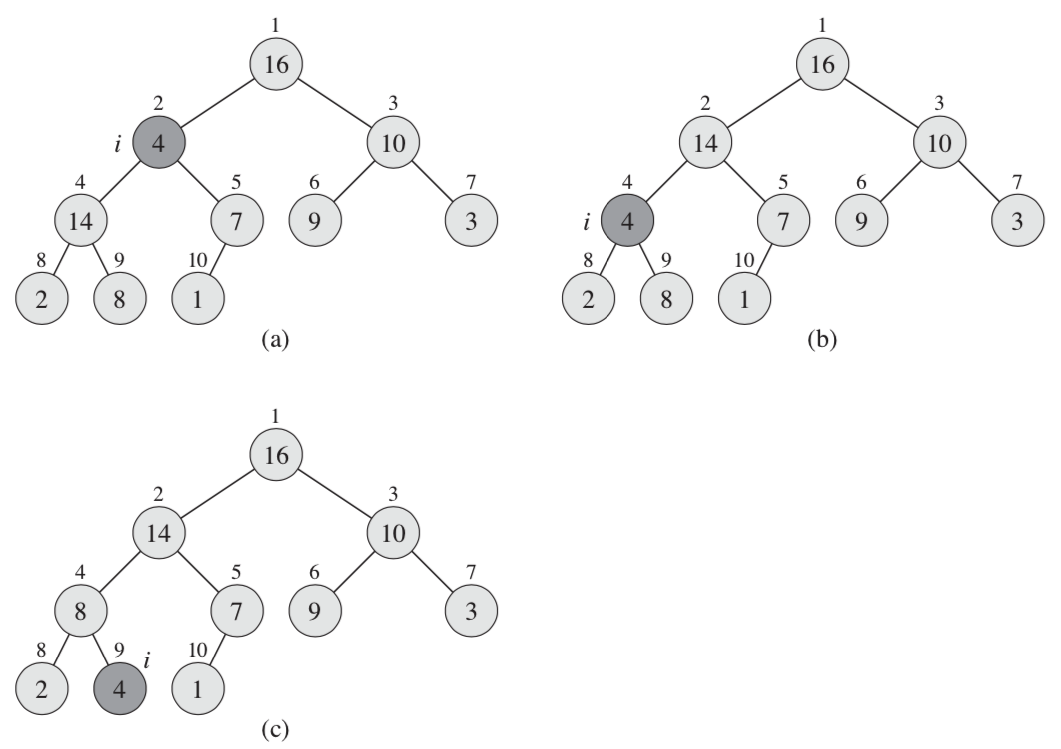

如图a中深色节点i(4)它比两个子节点都小,明显破坏了堆的性质,这个时候就需要对其下移,图b中与14交换了位置(与7交换也行),依旧不满足堆性质,再下移,结果见图c。
上移
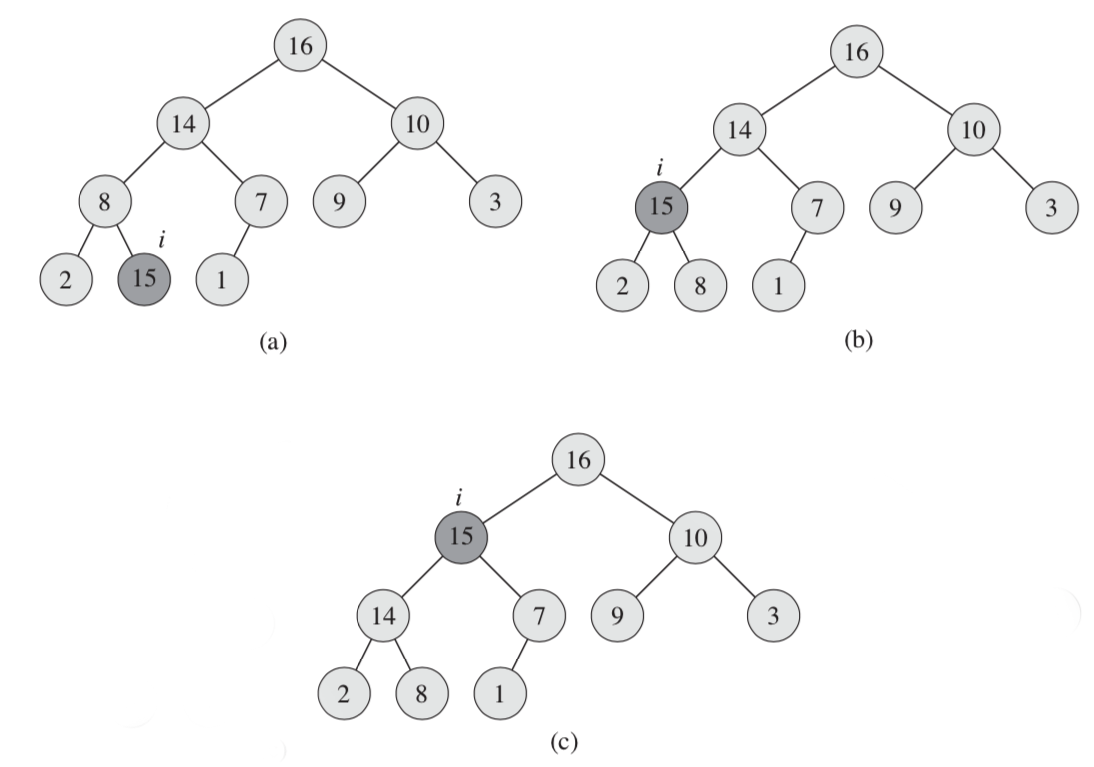
如上图a,节点i(15)比其父节点还大,所以对其上移到图b的状态,依旧比父节点大,再上移。
初始化
对不满足堆性质的节点通过上移或者下移操作,最终可以保证满足堆的性质。所以建堆的过程就对数组中每个元素做堆性质的维护,一般实现是从后往前,对不满足性质的节点做下移。
插入
插入很简单了,每次插入都插到最后一个节点,可能会破会堆性质,然后上移更新就行了。
删除
删除稍微复杂一些,删除时,如果是最后一个节点,就直接删掉。如果不是就拿堆里最后一个节点覆盖被删除的节点,再删掉最后一个节点。 这个时候有可能用覆盖后的节点比子节点小,所以需要下移。 也有可能该节点比父节点大,需要上移。
取最大堆的最大值
按最大堆的性质,根节点是最大的,取完后按删除的方法删掉跟节点就行了。
源代码
理解了什么叫堆,怎么维护堆的性质,理解PriorityQueue的源码就没什么困难了,PriorityQueue其实都是基于堆的操作来实现的。
初始化
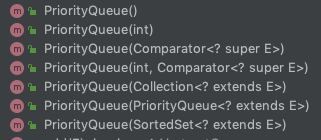
PriorityQueue提供了8个初始化方法,但其初始化的参数并不多,只有一个初始化容量 initialCapacity(默认是11)和自定义comparator。后面三个构造函数可以让你从其他的集合调用initElementsFromCollection和heapify()初始化一个PriorityQueue。
private void initElementsFromCollection(Collection<? extends E> c) {
Object[] es = c.toArray();
int len = es.length;
// If c.toArray incorrectly doesn't return Object[], copy it.
if (es.getClass() != Object[].class)
es = Arrays.copyOf(es, len, Object[].class);
if (len == 1 || this.comparator != null)
for (Object e : es)
if (e == null)
throw new NullPointerException();
this.queue = ensureNonEmpty(es);
this.size = len;
}
private void heapify() {
final Object[] es = queue;
int n = size, i = (n >>> 1) - 1;
final Comparator<? super E> cmp;
if ((cmp = comparator) == null)
for (; i >= 0; i--)
siftDownComparable(i, (E) es[i], es, n);
else
for (; i >= 0; i--)
siftDownUsingComparator(i, (E) es[i], es, n, cmp);
}
这两个函数其实就是首先将其他集合转化为连续的array,再将其堆化。
add offer
public boolean add(E e) {
return offer(e);
}
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
modCount++;
int i = size;
if (i >= queue.length)
grow(i + 1);
siftUp(i, e);
size = i + 1;
return true;
}
添加就是上文提到的堆的插入。但比较特别是的这里有个grow(),但数组容量不够时会对数组做一次扩容。其实就是申请一个更大的空间,把当前元素复制进入,然后丢掉旧数组。代码如下,但大小小于64时是逐2增加,之后是成倍增加。所以如果你的PriorityQueue存储元素比较多的化,建议构造函数指定initialCapacity大小,避免内部频繁扩容,提升性能。
private void grow(int minCapacity) {
int oldCapacity = queue.length;
// Double size if small; else grow by 50%
int newCapacity = oldCapacity + ((oldCapacity < 64) ?
(oldCapacity + 2) :
(oldCapacity >> 1));
// overflow-conscious code
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
queue = Arrays.copyOf(queue, newCapacity);
}
poll
poll是把队列里优先级最高的元素出队,就是上文中或者最大堆中最大值的方式。拿到根节点queue[0],然后用最后一个节点覆盖根节点,然后通过下移来维护堆的性质。
public E poll() {
final Object[] es;
final E result;
if ((result = (E) ((es = queue)[0])) != null) {
modCount++;
final int n;
final E x = (E) es[(n = --size)];
es[n] = null;
if (n > 0) {
final Comparator<? super E> cmp;
if ((cmp = comparator) == null)
siftDownComparable(0, x, es, n);
else
siftDownUsingComparator(0, x, es, n, cmp);
}
}
return result;
}
peek
偷偷瞄一眼最大值,很简单,直接返回根节点 queue[0]。
public E peek() {
return (E) queue[0];
}
remove
当删除某个元素时,先遍历定位到要删除元素的下标,然后运用堆元素删除的方式对其进行删除和堆性质的维护。
public boolean remove(Object o) {
int i = indexOf(o);
if (i == -1)
return false;
else {
removeAt(i);
return true;
}
}
E removeAt(int i) {
// assert i >= 0 && i < size;
final Object[] es = queue;
modCount++;
int s = --size;
if (s == i) // removed last element
es[i] = null;
else {
E moved = (E) es[s];
es[s] = null;
siftDown(i, moved);
if (es[i] == moved) {
siftUp(i, moved);
if (es[i] != moved)
return moved;
}
}
return null;
}
其它
除了几个核心API之外,它也实现了Collection的常用API,就没什么好讲的了。
参考资料
- 《算法导论》第三版
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/132262.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...