大家好,又见面了,我是你们的朋友全栈君。
人脸表情识别介绍与演示视频(视频链接:https://www.bilibili.com/video/BV18C4y1H7mH/)

摘要:这篇博文介绍基于深度卷积神经网络实现的人脸表情识别系统,系统程序由Keras, OpenCv, PyQt5的库实现,训练测试集采用fer2013表情库。如图系统可通过摄像头获取实时画面并识别其中的人脸表情,也可以通过读取图片识别,本文提供完整的程序文件并详细介绍其实现过程。博文要点如下:
点击跳转至博文涉及的全部文件下载页
链接:博主在面包多网站上的完整资源下载页
1. 前言
在这个人工智能成为超级大热门的时代,人脸表情识别已成为其中的一项研究热点,而卷积神经网络、深度信念网络和多层感知器等相关算法在人脸面部表情识别领域的运用最为广泛。面部的表情中包含了太多的信息,轻微的表情变化都会反映出人心理的变化,可想而知如果机器能敏锐地识别人脸中表达的情感该是多么令人兴奋的事。
学习和研究了挺久的深度学习,偶然看到IEEE上面一篇质量很高的文章,里面介绍的是利用深度神经网络实现的面部表情识别,研读下来让我深受启发。于是自己动手做了这个项目,如今SCI论文已投稿,这里特此将前期工作作个总结,希望能给类似工作的朋友带来一点帮助。由于论文尚未公开,这里使用的是已有的模型——如今CNN的主流框架之mini_XCEPTION,该模型性能也已是不错的了,论文中改进的更高性能模型尚不便给出,后面会分享给大家,敬请关注。
2. 表情识别数据集
目前,现有的公开的人脸表情数据集比较少,并且数量级比较小。比较有名的广泛用于人脸表情识别系统的数据集Extended Cohn-Kanada (CK+)是由P.Lucy收集的。CK+数据集包含123 个对象的327 个被标记的表情图片序列,共分为正常、生气、蔑视、厌恶、恐惧、开心和伤心七种表情。对于每一个图片序列,只有最后一帧被提供了表情标签,所以共有327 个图像被标记。为了增加数据,我们把每个视频序列的最后三帧图像作为训练样本。这样CK+数据总共被标记的有981 张图片。这个数据库是人脸表情识别中比较流行的一个数据库,很多文章都会用到这个数据做测试,可通过下面的链接下载。
官网链接:The Extended Cohn-Kanade Dataset(CK+)
网盘链接:百度网盘下载(提取码:8r15)

Kaggle是Kaggle人脸表情分析比赛提供的一个数据集。该数据集含28709 张训练样本,3859 张验证数据集和3859 张测试样本,共35887 张包含生气、厌恶、恐惧、高兴、悲伤、惊讶和正常七种类别的图像,图像分辨率为48×48。该数据集中的图像大都在平面和非平面上有旋转,并且很多图像都有手、头发和围巾等的遮挡物的遮挡。该数据库是2013年Kaggle比赛的数据,由于这个数据库大多是从网络爬虫下载的,存在一定的误差性。这个数据库的人为准确率是65%±5%。
官网链接:FER2013
网盘链接:百度网盘下载(提取码:t7xj)

由于FER2013数据集数据更加齐全,同时更加符合实际生活的场景,所以这里主要选取FER2013训练和测试模型。为了防止网络过快地过拟合,可以人为的做一些图像变换,例如翻转,旋转,切割等。上述操作称为数据增强。数据操作还有另一大好处是扩大数据库的数据量,使得训练的网络鲁棒性更强。下载数据集保存在fer2013的文件夹下,为了对数据集进行处理,采用如下代码载入和进行图片预处理:
import pandas as pd
import cv2
import numpy as np
dataset_path = 'fer2013/fer2013/fer2013.csv' # 文件保存位置
image_size=(48,48) # 图片大小
# 载入数据
def load_fer2013():
data = pd.read_csv(dataset_path)
pixels = data['pixels'].tolist()
width, height = 48, 48
faces = []
for pixel_sequence in pixels:
face = [int(pixel) for pixel in pixel_sequence.split(' ')]
face = np.asarray(face).reshape(width, height)
face = cv2.resize(face.astype('uint8'),image_size)
faces.append(face.astype('float32'))
faces = np.asarray(faces)
faces = np.expand_dims(faces, -1)
emotions = pd.get_dummies(data['emotion']).as_matrix()
return faces, emotions
# 将数据归一化
def preprocess_input(x, v2=True):
x = x.astype('float32')
x = x / 255.0
if v2:
x = x - 0.5
x = x * 2.0
return x
载入数据后将数据集划分为训练集和测试集,在程序中调用上面的函数代码如下:
from load_and_process import load_fer2013
from load_and_process import preprocess_input
from sklearn.model_selection import train_test_split
# 载入数据集
faces, emotions = load_fer2013()
faces = preprocess_input(faces)
num_samples, num_classes = emotions.shape
# 划分训练、测试集
xtrain, xtest,ytrain,ytest = train_test_split(faces, emotions,test_size=0.2,shuffle=True)
3. 搭建表情识别的模型
接下来就是搭建表情识别的模型了,这里用到的是CNN的主流框架之mini_XCEPTION。XCEPTION是Google继Inception后提出的对Inception v3的另一种改进,主要是采用深度可分离的卷积(depthwise separable convolution)来替换原来Inception v3中的卷积操作。XCEPTION的网络结构在ImageNet数据集(Inception v3的设计解决目标)上略优于Inception v3,并且在包含3.5亿个图像甚至更大的图像分类数据集上明显优于Inception v3,而两个结构保持了相同数目的参数,性能增益来自于更加有效地使用模型参数,详细可参考论文:Xception: Deep Learning with Depthwise Separable Convolutions,论文Real-time Convolutional Neural Networks for Emotion and Gender Classification等。
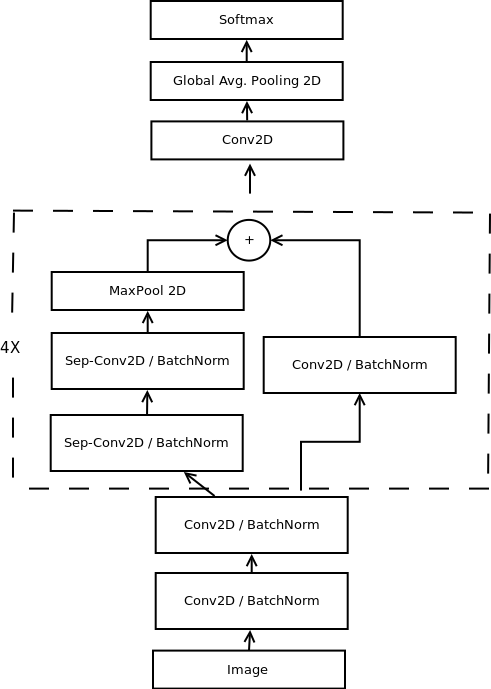
既然这样的网络能获得更好结果又是主流,那当然有必要作为对比算法实现以下了,这里博主模型这部分的代码引用了GitHub:https://github.com/oarriaga/face_classification中的模型(其他地方也能找到这个模型的类似代码),模型框图如上图所示,其代码如下:
def mini_XCEPTION(input_shape, num_classes, l2_regularization=0.01):
regularization = l2(l2_regularization)
# base
img_input = Input(input_shape)
x = Conv2D(8, (3, 3), strides=(1, 1), kernel_regularizer=regularization,
use_bias=False)(img_input)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(8, (3, 3), strides=(1, 1), kernel_regularizer=regularization,
use_bias=False)(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
# module 1
residual = Conv2D(16, (1, 1), strides=(2, 2),
padding='same', use_bias=False)(x)
residual = BatchNormalization()(residual)
x = SeparableConv2D(16, (3, 3), padding='same',
kernel_regularizer=regularization,
use_bias=False)(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = SeparableConv2D(16, (3, 3), padding='same',
kernel_regularizer=regularization,
use_bias=False)(x)
x = BatchNormalization()(x)
x = MaxPooling2D((3, 3), strides=(2, 2), padding='same')(x)
x = layers.add([x, residual])
# module 2
residual = Conv2D(32, (1, 1), strides=(2, 2),
padding='same', use_bias=False)(x)
residual = BatchNormalization()(residual)
x = SeparableConv2D(32, (3, 3), padding='same',
kernel_regularizer=regularization,
use_bias=False)(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = SeparableConv2D(32, (3, 3), padding='same',
kernel_regularizer=regularization,
use_bias=False)(x)
x = BatchNormalization()(x)
x = MaxPooling2D((3, 3), strides=(2, 2), padding='same')(x)
x = layers.add([x, residual])
# module 3
residual = Conv2D(64, (1, 1), strides=(2, 2),
padding='same', use_bias=False)(x)
residual = BatchNormalization()(residual)
x = SeparableConv2D(64, (3, 3), padding='same',
kernel_regularizer=regularization,
use_bias=False)(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = SeparableConv2D(64, (3, 3), padding='same',
kernel_regularizer=regularization,
use_bias=False)(x)
x = BatchNormalization()(x)
x = MaxPooling2D((3, 3), strides=(2, 2), padding='same')(x)
x = layers.add([x, residual])
# module 4
residual = Conv2D(128, (1, 1), strides=(2, 2),
padding='same', use_bias=False)(x)
residual = BatchNormalization()(residual)
x = SeparableConv2D(128, (3, 3), padding='same',
kernel_regularizer=regularization,
use_bias=False)(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = SeparableConv2D(128, (3, 3), padding='same',
kernel_regularizer=regularization,
use_bias=False)(x)
x = BatchNormalization()(x)
x = MaxPooling2D((3, 3), strides=(2, 2), padding='same')(x)
x = layers.add([x, residual])
x = Conv2D(num_classes, (3, 3),
#kernel_regularizer=regularization,
padding='same')(x)
x = GlobalAveragePooling2D()(x)
output = Activation('softmax',name='predictions')(x)
model = Model(img_input, output)
return model
4. 数据增强的批量训练
神经网络的训练需要大量的数据,数据的量决定了网络模型可以达到的高度,网络模型尽量地逼近这个高度。然而对于人脸表情的数据来说,都只存在少量的数据Extended Cohn-Kanada (CK+)的数据量是远远不够的,并且CK+多是比较夸张的数据。Kaggle Fer2013数据集也不过只有3万多数据量,而且有很多遮挡、角度等外界影响因素。既然收集数据要花费很大的人力物力,那么我们就用技术解决这个问题,为避免重复开发首先还是看看有没有写好的库。博主又通读了遍Keras官方文档,其中ImageDataGenerator的图片生成器就可完成这一目标。
为了尽量利用我们有限的训练数据,我们将通过一系列随机变换堆数据进行提升,这样我们的模型将看不到任何两张完全相同的图片,这有利于我们抑制过拟合,使得模型的泛化能力更好。在Keras中,这个步骤可以通过keras.preprocessing.image.ImageGenerator来实现,这个类使你可以:在训练过程中,设置要施行的随机变换通过.flow或.flow_from_directory(directory)方法实例化一个针对图像batch的生成器,这些生成器可以被用作keras模型相关方法的输入,如fit_generator,evaluate_generator和predict_generator。——Keras官方文档
ImageDataGenerator()是一个图片生成器,同时也可以在batch中对数据进行增强,扩充数据集大小(比如进行旋转,变形,归一化等),增强模型的泛化能力。结合前面的模型和数据训练部分的代码如下:
""" Description: 训练人脸表情识别程序 """
from keras.callbacks import CSVLogger, ModelCheckpoint, EarlyStopping
from keras.callbacks import ReduceLROnPlateau
from keras.preprocessing.image import ImageDataGenerator
from load_and_process import load_fer2013
from load_and_process import preprocess_input
from models.cnn import mini_XCEPTION
from sklearn.model_selection import train_test_split
# 参数
batch_size = 32
num_epochs = 10000
input_shape = (48, 48, 1)
validation_split = .2
verbose = 1
num_classes = 7
patience = 50
base_path = 'models/'
# 构建模型
model = mini_XCEPTION(input_shape, num_classes)
model.compile(optimizer='adam', # 优化器采用adam
loss='categorical_crossentropy', # 多分类的对数损失函数
metrics=['accuracy'])
model.summary()
# 定义回调函数 Callbacks 用于训练过程
log_file_path = base_path + '_emotion_training.log'
csv_logger = CSVLogger(log_file_path, append=False)
early_stop = EarlyStopping('val_loss', patience=patience)
reduce_lr = ReduceLROnPlateau('val_loss', factor=0.1,
patience=int(patience/4),
verbose=1)
# 模型位置及命名
trained_models_path = base_path + '_mini_XCEPTION'
model_names = trained_models_path + '.{epoch:02d}-{val_acc:.2f}.hdf5'
# 定义模型权重位置、命名等
model_checkpoint = ModelCheckpoint(model_names,
'val_loss', verbose=1,
save_best_only=True)
callbacks = [model_checkpoint, csv_logger, early_stop, reduce_lr]
# 载入数据集
faces, emotions = load_fer2013()
faces = preprocess_input(faces)
num_samples, num_classes = emotions.shape
# 划分训练、测试集
xtrain, xtest,ytrain,ytest = train_test_split(faces, emotions,test_size=0.2,shuffle=True)
# 图片产生器,在批量中对数据进行增强,扩充数据集大小
data_generator = ImageDataGenerator(
featurewise_center=False,
featurewise_std_normalization=False,
rotation_range=10,
width_shift_range=0.1,
height_shift_range=0.1,
zoom_range=.1,
horizontal_flip=True)
# 利用数据增强进行训练
model.fit_generator(data_generator.flow(xtrain, ytrain, batch_size),
steps_per_epoch=len(xtrain) / batch_size,
epochs=num_epochs,
verbose=1, callbacks=callbacks,
validation_data=(xtest,ytest))
以上代码中设置了训练时的结果输出,在训练结束后会将训练的模型保存为hdf5文件到自己指定的文件夹下,由于数据量大模型的训练时间会比较长,建议使用GPU加速。训练结束后测试得到混淆矩阵如下:
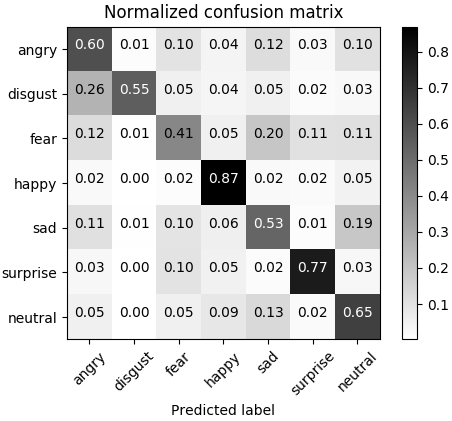
训练的模型综合在FER2013数据集上的分类准确率为66%,后续调整之后达到了70%,算是中等偏上水平,其实并非模型不好而是在数据预处理、超参数的选取上有很大的可提升空间,当然也可使用其他的模型,譬如可参考论文:Extended deep neural network for facial emotion recognition,大家可自行研究,这里就不多介绍了。
5. 系统UI界面的实现
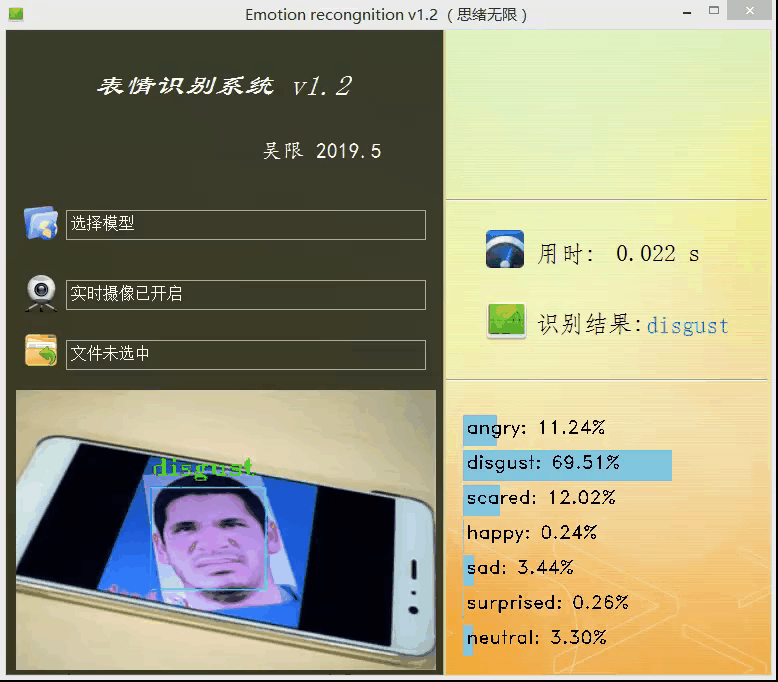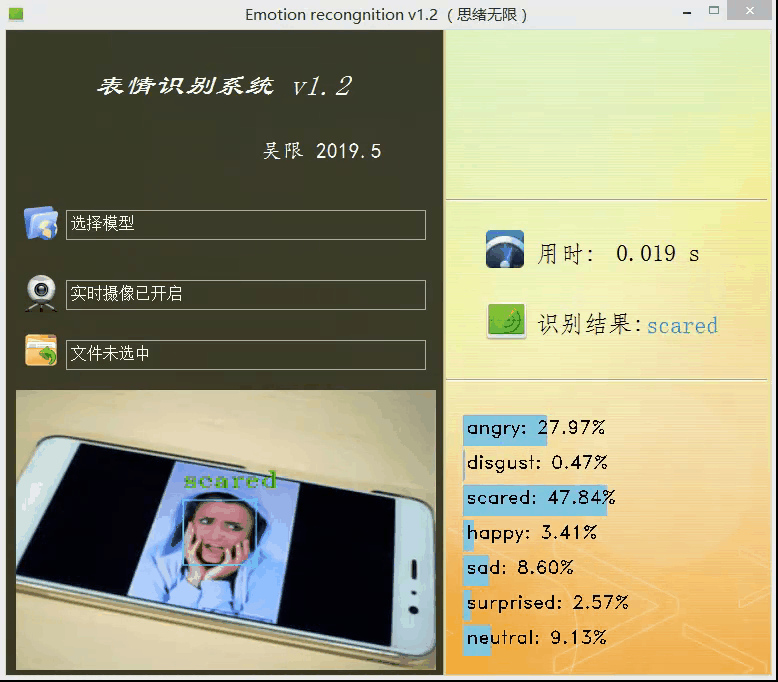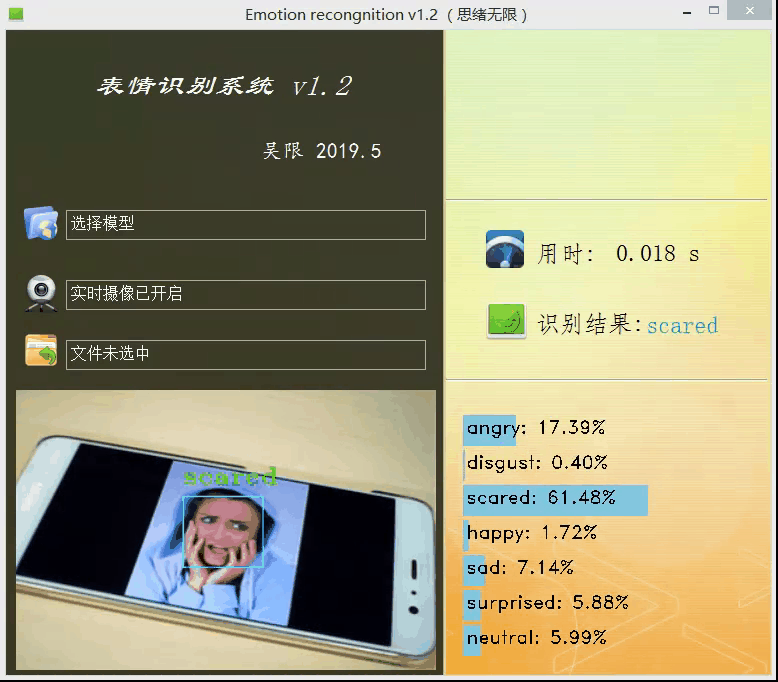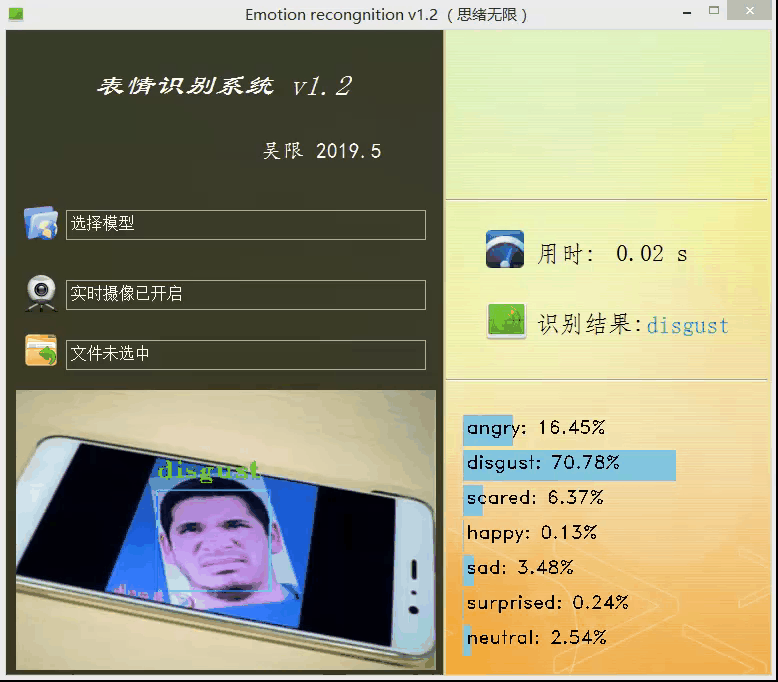
上面的模型训练好了,但对于我们来说它的作用就只是知道了其准确率还行,其实深度学习的目的最重要还是应用,是时候用上面的模型做点酷酷的东西了。可不可以用上面的模型识别下自己表达的情绪呢?不如做个系统调取摄像头对实时画面中的表情进行识别并显示识别结果,既能可视化的检测模型的实用性能,同时使得整个项目生动有趣激发自己的创造性,当你向别人介绍你的项目时也显得高大上。这里采用PyQt5进行设计,首先看一下最后的效果图,运行后的界面如下:
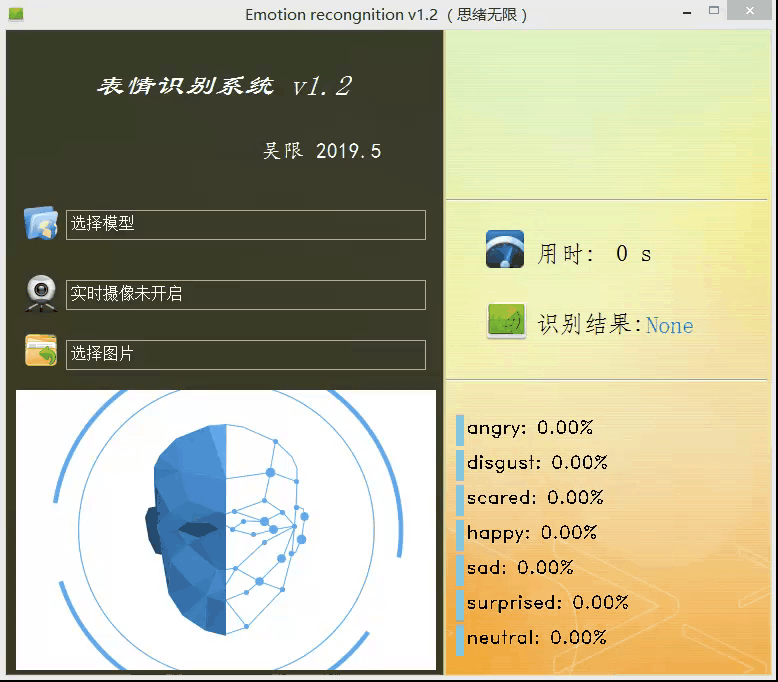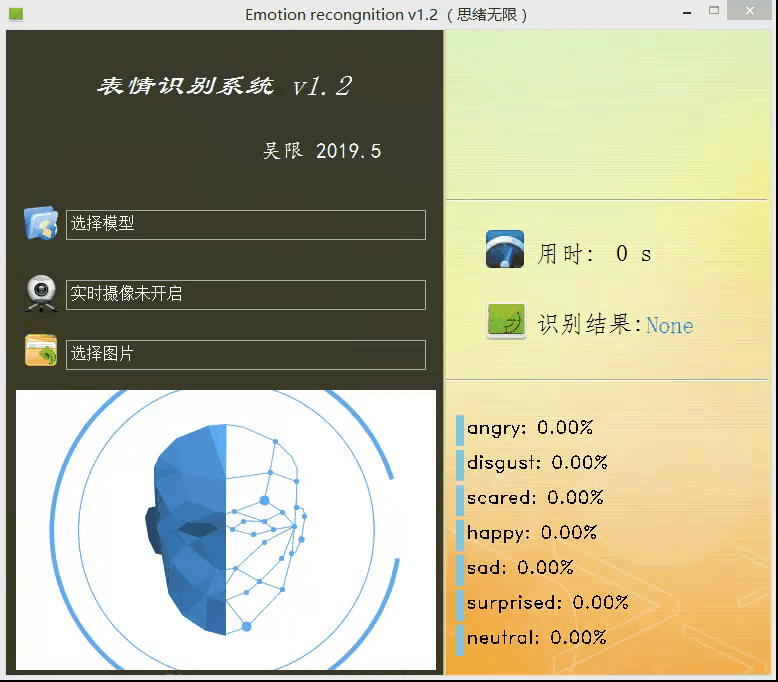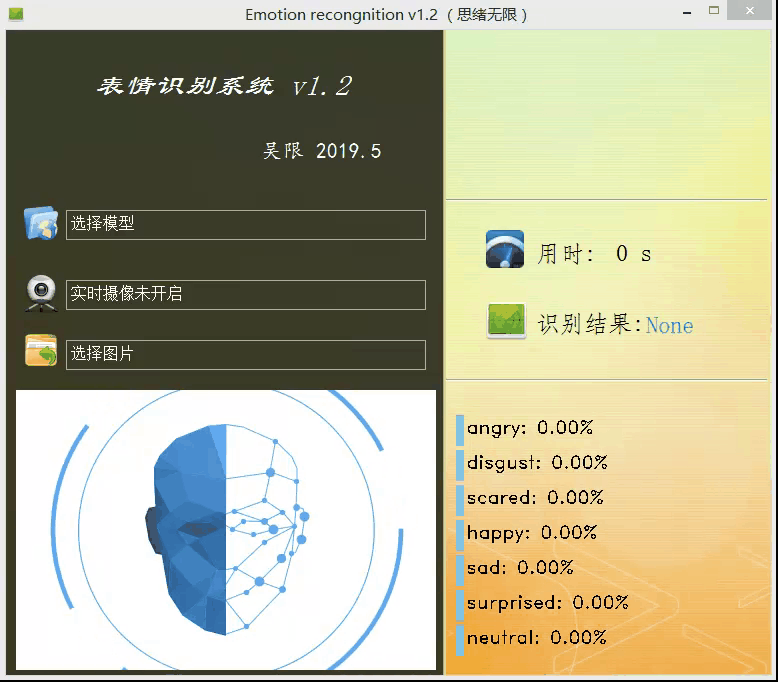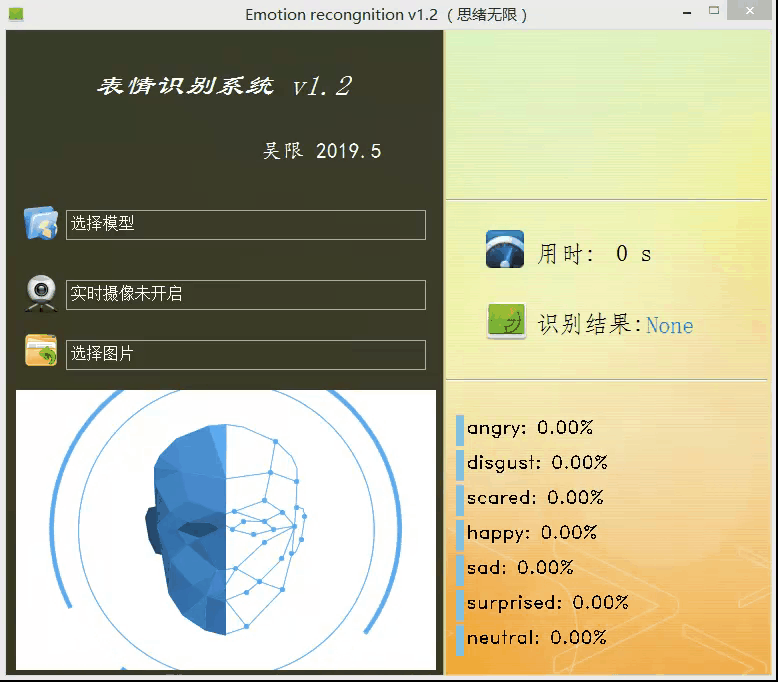
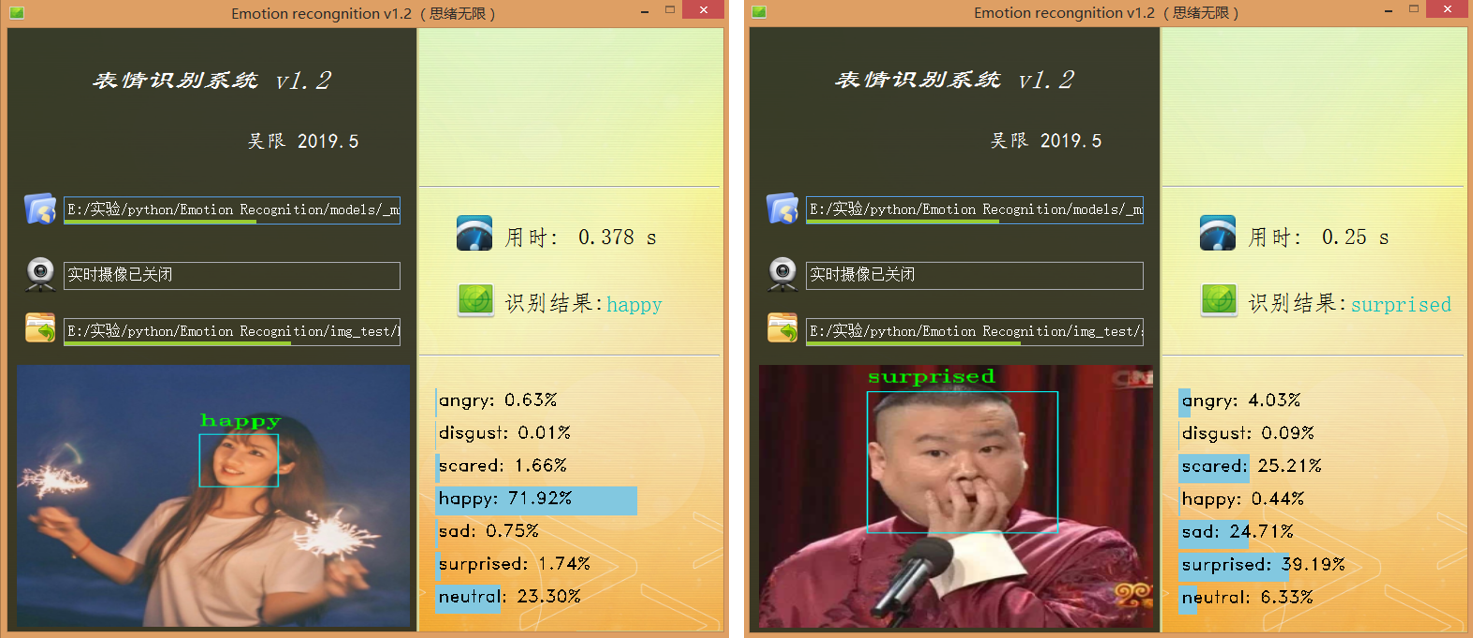
设计功能:一、可选择模型文件后基于该模型进行识别;二、打开摄像头识别实时画面中的人脸表情;三、选择一张人脸图片,对其中的表情进行识别。选择一张图片测试识别效果,如下图所示:

博主对UI界面的要求是可以简单但颜值必须高,必须高,实用简约高颜值是我奉行的标准,以上的界面几经修改才有了上面的效果。当然博主的目的并不单纯的想秀,而是借此做一个测试模型的系统,可以选择模型、训练测试集等以便界面化地对后面的模型进行各种测试评估,生成用于论文的特定结果数据图或表格等,这个测试系统后面有机会分享给大家。
系统UI界面的实现这部分又设计PyQt5的许多内容,在这一篇博文中介绍恐怕尾大不掉,效果也不好,所以更多的细节内容将在后面的博文中介绍,敬请期待!有需要的朋友可通过下面的链接下载这部分的文件。
【下载链接】
若您想获得博文中涉及的实现完整全部程序文件(包括数据集,py, UI文件等,如下图),这里已打包上传至博主的面包多下载资源中。文件下载链接如下:
数据链接:训练用到的数据集(提取码:t7xj)
本资源已上传至面包多网站,可以点击以下链接获取,已将数据集同时打包到里面,点击即可运行,完整文件下载链接如下:
完整资源下载链接:博主在面包多网站上的完整资源下载页
【公众号获取】
本人微信公众号已创建,扫描以下二维码并关注公众号“AI技术研究与分享”,后台回复“ER20190609”获取。

【运行程序须知】
要安装的库如上图(以上是博主安装的版本),如您想直接运行界面程序,只需在下载链接1中的文件后,运行runMain.py程序。
如您想重新训练模型,下载链接1中的文件后,运行前请下载链接2中的数据集解压到的csv文件放到 fer2013\fer2013 的文件夹下,运行train_emotion_classifier.py程序即可重新训练。
详细安装教程:人脸表情识别系统介绍——离线环境配置篇
5. 结束语
由于博主能力有限,博文中提及的方法与代码即使经过测试,也难免会有疏漏之处。希望您能热心指出其中的错误,以便下次修改时能以一个更完美更严谨的样子,呈现在大家面前。同时如果有更好的实现方法也请您不吝赐教。
大家的点赞和关注是博主最大的动力,博主所有博文中的代码文件都可分享给您,如果您想要获取博文中的完整代码文件,可通过C币或积分下载,没有C币或积分的朋友可在关注、点赞博文后提供邮箱,我会在第一时间发送给您。博主后面会有更多的分享,敬请关注哦!
参考文献:
[1] Chollet F. Xception: Deep learning with depthwise separable convolutions[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 1251-1258.
[2] Arriaga O, Valdenegro-Toro M, Plöger P. Real-time convolutional neural networks for emotion and gender classification[J]. arXiv preprint arXiv:1710.07557, 2017.
[3] Jain D K, Shamsolmoali P, Sehdev P. Extended deep neural network for facial emotion recognition[J]. Pattern Recognition Letters, 2019, 120: 69-74.
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/131360.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
