大家好,又见面了,我是你们的朋友全栈君。
根据MIT的 Learning Deep Features for Discriminative Localization论文中的描述,在使用类响应图class activation mapping (CAM) 对比全局平均池化Global average pooling (GAP) vs 全局最大池化global max pooling (GMP):
类响应图示例:


图中高亮区域就是根据label的注意图高响应区域
具体得到的这个相应区的方法是
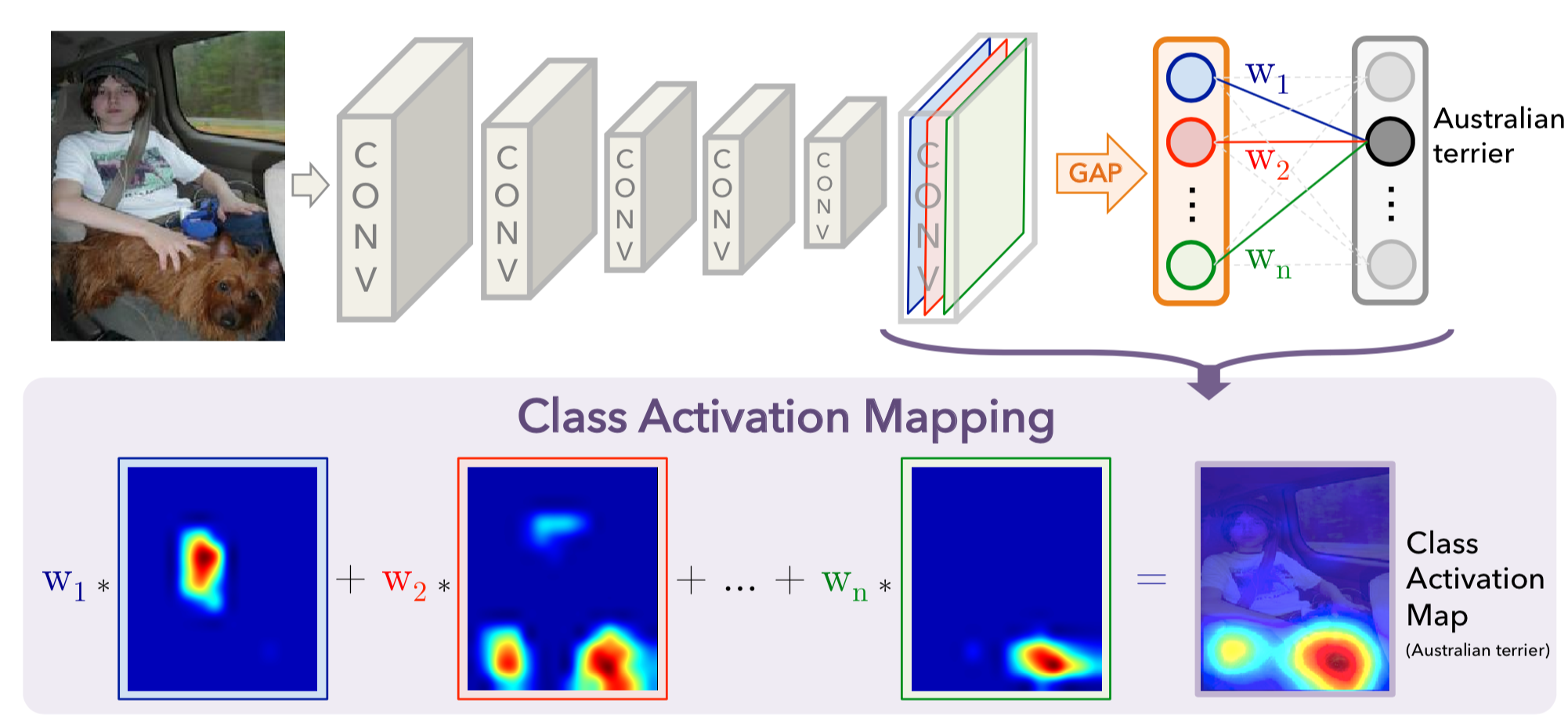
1) 训练主干网络得到特征图
2) 进行全局池化(图中用的GAP,也可以使用GMP)
3) 对全局池化的结果做全连接得到全连接参数 w
4) 把全连接参数作为权重对特征图进行加权求和 上图最下方的公式
根据对图像的研究发现,不同的类别的特征图相应区域不一样,原始的卷积网络具有一定的定位能力。而且如下图所示,不同类别的注意力区域也大不相同也呈现出非常准确的特征区域。
模型可以预测出不同类别概率,根据类注意图发现。即使是错误预测的类别,比如上图预测狗狗预测成了人,但是人也在图中特征区域也是定位在了人的身上。
说了这么多就是论证GAP和GMP具有定位能力。那么具体那个好呢
先看一组实验
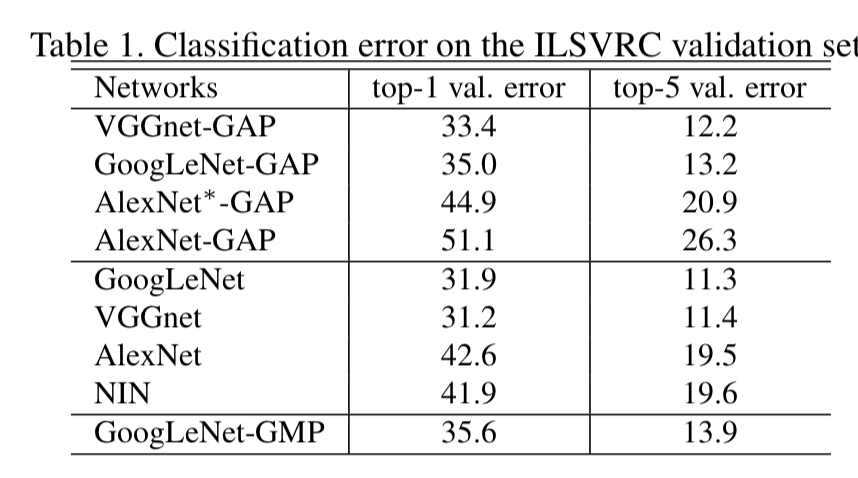
我们发现相比GAP,GMP在同一个类别上的top1 和top5 的损失都有所升高。
原因分析:
GAP 是对全局求平均,GAP LOSS 促使网络区分辨每个类别的程度,找到所有的目标可区分区域进行预测。
GMP 是对全局求最大,只去找分数最高的那个区域。而去忽略其他分数低的区域
因此在定位方面,GAP 比GMP要好
GAP outperforms GMP for localization.
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/127458.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
