大家好,又见面了,我是全栈君。
一、字典用法
字典是一种key-value数据类型,通过key获取具体value的内容,字典的特性是无序、去重。
增删改查用法如下:
1.1基本增删改查操作
1 name = { "name":"alex","age":"18","xx":{ "ed":3000,"ye":2000}} 2 print(name["name"]) #打印name对应的value的内容 3 print(name.get("name")) #select 4 name["sex"] = "boy" # add 5 print(name) 6 del name["sex"] #del 7 print(name) 8 name.pop("name") #del 9 print(name) 10 name.clear() #清空字典 11 print(name) 12 name2 = name.copy() #浅copy,只修改第一层,第二层不变。 13 name2["sex"] = "girl" 14 name2["xx"]["ye"] = "1000" 15 print(name) 16 print(name2) 17 print(name.fromkeys("alex","3")) #分别赋值 18 print(name.keys()) #打印所有key
1.2 字典循环用法
1 方法1. 2 name = { "name":"alex","age":"18","xx":{ "ed":3000,"ye":2000}} 3 for i in name: #这种for 以后常用 4 print(i,name[i]) #打印key value的值 5 6 方法2. 7 for k,v in name: #会先把dict转成list,数据里大时莫用 8 print(k,v)
1.3 三级菜单经典版



1 menu = { 2 '北京':{ 3 '海淀':{ 4 '五道口':{ 5 'soho':{}, 6 '网易':{}, 7 'google':{} 8 }, 9 '中关村':{ 10 '爱奇艺':{}, 11 '汽车之家':{}, 12 'youku':{}, 13 }, 14 '上地':{ 15 '百度':{}, 16 }, 17 }, 18 '昌平':{ 19 '沙河':{ 20 '老男孩':{}, 21 '北航':{}, 22 }, 23 '天通苑':{}, 24 '回龙观':{}, 25 }, 26 '朝阳':{}, 27 '东城':{}, 28 }, 29 '上海':{ 30 '闵行':{ 31 "人民广场":{ 32 '炸鸡店':{} 33 } 34 }, 35 '闸北':{ 36 '火车战':{ 37 '携程':{} 38 } 39 }, 40 '浦东':{}, 41 }, 42 '山东':{}, 43 } 44 current_level = menu #定义当前层 45 last_levels = [] #标记级别 46 while True: 47 for key in current_level: 48 print(key) 49 choice = input("pls input city:").strip() 50 if choice == 0:continue #输入为空,继续输入 51 if choice =='b': #退出判断 52 if len(last_levels) ==0: break #回到第一层,退出程序 53 current_level = last_levels[-1] #返回上一层 54 last_levels.pop() #删掉当前层 55 if choice not in current_level:continue #如果输入错误,继续输入 56 last_levels.append(current_level) #记录当前层 57 current_level = current_level[choice] #进入下一层
三级菜单程序
二、集合用法
集合是无序的不重复的数据组合,可以测试两个集合直接的交集、并集、差集等
2.1集合的基本用法
1 s1 = {1,2,3,4,5} 2 s2 = {2,3,6,7} 3 s3 = {2,3} 4 print(s1.intersection(s2))#交集 5 print(s1&s2) #交集 6 print(s1.difference(s2))#差集 7 print(s2.difference(s1))#差集 8 print(s1-s2) #差集 9 print(s1.union(s2)) #合集 10 print(s1|s2) #合计 11 print(s1.symmetric_difference(s2))#对称差集 12 print(s2.symmetric_difference(s1))#对称差集 13 print(s1^s2) #对称差集 14 print(s3.issuperset(s1)) #子集 15 print(s1.issuperset(s3)) #子集 16 print(s3<s1) #子集
三、字符编码集
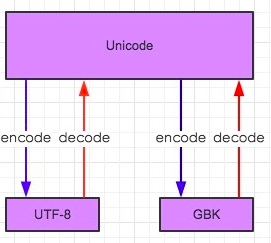
用什么字符集写入就用什么字符集读取。
内存都是unicode编码,统一字节,高效。
四、文件操作
4.1基本操作
主要分三步,打开文件,处理文件,关闭文件。
1 f =open('a.txt','r') #只读方式打开文件 2 first_line = f.readline() #只读一行 3 data = f.read()# 读取剩下的所有内容,文件大时不要用 4 f.close() #关闭文件
4.2 基本选项
r,只读模式打开(默认)
w,只写模式打开(清空原文件内容)
a,追加模式(相当于列表里面的append),可以读。
r+,读写模式
w+, 写读模式
rb wb ab 表示处理二进制文件。
4.3 文件字符替换
1 f = open('test',encoding="utf-8") 2 for i in f: 3 if "hello" in i: 4 i = i.replace("hello","good") 5 print(i)
4.4 文件光标移动
f = open('test',encoding="utf-8") f.seek(10) #移动文件光标到第10个字节 print(f.read()) print(f.tell()) #显示当前光标位置
转载于:https://www.cnblogs.com/liumj0305/p/5991904.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/108824.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
