大家好,又见面了,我是你们的朋友全栈君。
softmax


softmax ,顾名思义,就是 soft 版本的 max。
在了解 softmax 之前,先看看什么是 hardmax。
hardmax 就是直接选出一个最大值,例如 [1,2,3] 的 hardmax 就是 3,而且只选出最大值,非黑即白,但是实际中这种方式往往是不合理的,例如对于文本分类来说,一篇文章或多或少包含着各种主题信息,我们更期望得到文章属于各种主题的概率值,而不是简单直接地归类为某一种唯一的主题。这里就需要用到soft的概念,即不再唯一地确定某一个最大值,而是为每个输出分类的结果都赋予一个概率值,表示属于每个类别的可能性。
hardmax 简单直观,但是有很严重的梯度问题,求最大值这个函数本身的梯度是非常非常稀疏的,例如神经网络中的 max pooling,经过 hardmax 后,只有被选中的那个变量上才有梯度,其他变量都没有梯度。
那么,什么是 softmax?
softmax 就是把原始的变量做一个数学变换,变换公式为

例如原始变量为 [1,2,3],经过 softmax 后就变成了
[ e^1 / ( e1+e2+e^3 ) ,e^2 / ( e1+e2+e^3 ) ,e^3 / ( e1+e2+e^3 ) ]
=[ 2.718/(2.718+7.389+20.085), 7.389/(2.718+7.389+20.085), 20.085/(2.718+7.389+20.085)]
=[ 0.09, 0.245, 0.665 ]
可以看到,softmax 有以下特征:
- 所有值都在 [0,1] 之间;
- 所有值的和加起来等于1;
而上述特征刚好跟概率的概念相符合,因此,可以把它当作概率值。
softmax 不会像 hardmax 那样有严重的梯度问题,能够很方便地求梯度,很适合用于神经网络的反向传播,进行梯度更新。
总的来说,softmax可以将任意一组变量变为概率分布的形式。
softmax 损失函数
由上面可知,softmax函数的表达式为:

其中i表示输出节点的编号。
假设此时第i个输出节点为正确类别对应的输出节点,则Pi是正确类别对应输出节点的概率值。添加log运算不影响函数的单调性,首先为Pi添加log运算:

此时Pi是正确类别对应的输出节点的概率,当然希望此时的Pi越大越好。通常情况下使用梯度下降法来迭代求解,因此只需要为 logPi 加上一个负号变成损失函数,变成了希望损失函数越小越好:
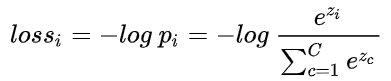
对上面的式子进一步处理:
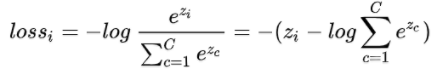
上式就是 softmax 损失函数。
softmax 损失函数只针对正确类别的对应的输出节点,将这个位置的softmax值最大化。
卷积神经网络系列之softmax,softmax loss和cross entropy的讲解
cross-entropy 交叉熵损失函数
cross-entropy 不是机器学习独有的概念,本质上是用来衡量两个概率分布的相似性的。
![softmax、softmax损失函数、cross-entropy损失函数[通俗易懂]](https://img-blog.csdnimg.cn/20210127165550747.png)
上式中,p代表正确答案,q代表的是预测值。交叉熵值越小,两个概率分布越接近。
需要注意的是,交叉熵刻画的是两个概率分布之间的距离,然而神经网络的输出却不一定是一个概率分布,很多情况下是实数。如何将神经网络前向传播得到的结果也变成概率分布,Softmax回归就是一个非常有用的方法。
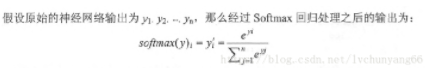
Softmax将神经网络的输出变成了一个概率分布,这个新的输出可以理解为经过神经网络的推导,一个样例为不同类别的概率分别是多大。这样就把神经网络的输出也变成了一个概率分布,从而可以通过交叉熵来计算预测的概率分布和真实答案的概率分布之间的距离了。

交叉熵损失函数表达式为:
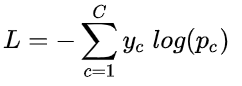
上述式子中 yc 是指真实样本的标签值,Pc 是指 实际的输出 经过 softmax 计算 后得到的概率值,该式子能够衡量真实分布和实际输出的分布之间的距离,
由于 softmax 可以将一组变量转换为概率分布,而 cross-entropy 又能够衡量两个概率分布之间的距离,因此,softmax 和 cross-entropy 经常结合在一起使用
总的来说,交叉熵损失函数刻画了两个概率分布之间的距离,通常用在神经网络的多分类任务中,可以表示 真实标签值 与 神经网络输出经softmax计算后得到的预测概率值 之间的损失大小
一文详解Softmax函数
你 真的 懂 Softmax 吗?
交叉熵(Cross-Entropy)
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/153148.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
