大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
数据库备份
- Mysqldump:逻辑备份,热备份,全量
- xtrabackup:物理,热,全量 + 增量备份
一、 什么是 MySQL 主备
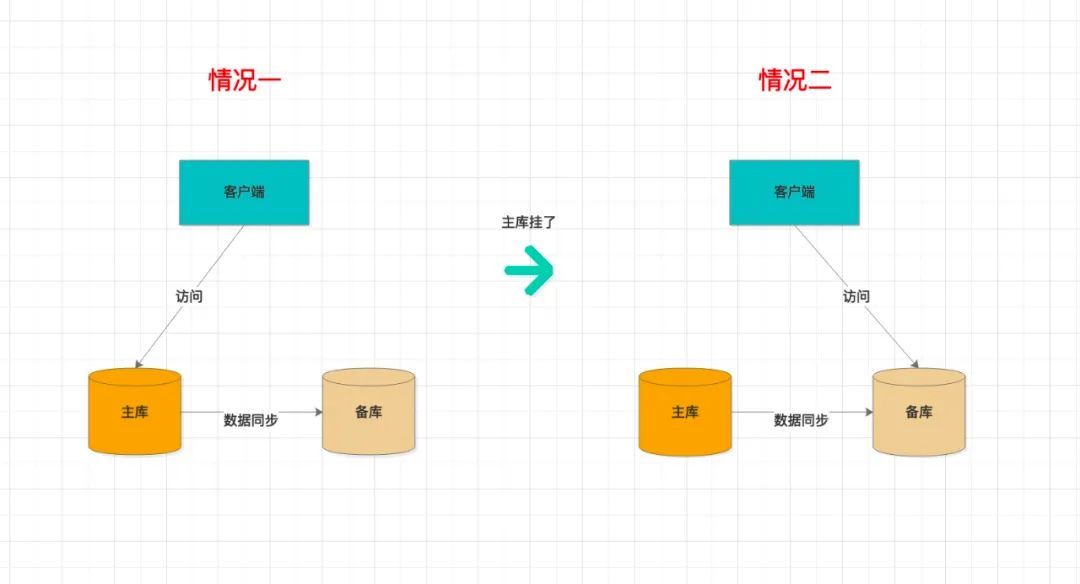

情况一:
- 客户端的业务操作,
读、写访问的是主库 - 主库通过某种机制,将数据实时同步给备库
- 主库由于有些原因,无法正常响应客户端的请求
情况二:
- 完成主备切换
- 客户端读写,访问的是备库(此时备库升级为新主库)
数据同步是如何实现的?
1.主从同步原理
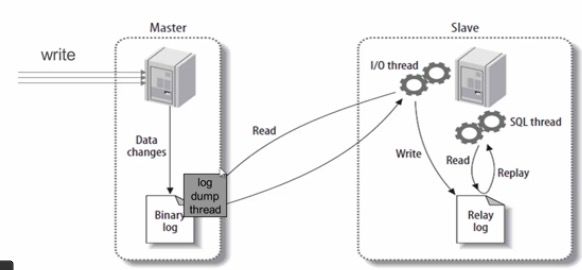
1、在备库执行 change master 命令 ,绑定主库的信息
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.1.1', MASTER_USER = 'repl', MASTER_PASSWORD = 'replpassword', MASTER_PORT = 3306, MASTER_AUTO_POSITION = 1, MASTER_RETRY_COUNT = 0, MASTER_HEARTBEAT_PERIOD = 10000;
- MASTER_HOST :master主机名(或IP地址)
- MASTER_PORT :mysql实例端口号
- MASTER_USER:用户名
- MASTER_PASSWORD:密码
- MASTER_AUTO_POSITION:如果进行change master to时使用MASTER_AUTO_POSITION = 1,slave连接master将使用基于GTID的复制协议
- MASTER_RETRY_COUNT:重连次数
- MASTER_HEARTBEAT_PERIOD:复制心跳的周期
MySql 中文文档https://www.docs4dev.com/docs/zh/mysql/5.7/reference/change-master-to.html
2、备库执行 start slave 命令,备库启动两个线程:I/O thread 和 SQL thread
3、master主库,有数据更新,将此次更新的事件类型写入到主库的 binlog 文件中
4、主库会创建log dump 线程,通知slave有数据更新
5、slave,向master节点的 log dump线程请求一份指定binlog文件位置的副本,并将请求回来的binlog存到本地的Relay log 中继日志中
6、slave 再开启一个SQL 线程读取Relay log日志,解析出日志里的命令,并执行,从而保证主备库数据同步
2.mysqldump逻辑备份及恢复
全量备份
全量备份基本模式:
- 进入到mysql容器中
- 创建备份目录
- 通过mysqldump命令,执行数据库逻辑备份操作,将结果输出到 sql文件中。
主要命令如下:
# 级联创建数据备份目录
mkdir -p /data/backups/dmp
# 实现所有数据库备份
mysqldump --opt --single-transaction --master-data=2 --host=localhost --user=root --password=admin --all-databases > /data/backups/dmp/dmp1.sql
mysqldump相关参数说明:
- –opt 适用于备份大表,同时激活了-add-drop-table –add-locks –create-options –disable-keys –extended-insert –lock-tables –quick –set-charset 命令
- –single-transaction 开启一个事务,并设置备份事务为可重复读,保持备份数据一致性
- –master-data=2 表示在备份过程中记录主库的binlog和pos点,并且在dump文件中注释改行
- –all-databases 导出所有数据库,包括mysql库
全量恢复
通过在上述库中,执行drop table t_user1,删除该表后,开展恢复:
- 通过mysql命令,即可将 dump sql文件执行到对应的数据库中。
mysql -h localhost -u root -p < /data/backups/dmp/dmp1.sql
其他备份
1、导出指定数据库的指定表:
- –databases 指定备份的数据库
- –tables 指定备份的具体数据库表
mysqldump --opt --single-transaction --master-data=2 --host=localhost --user=root -p --databases user --tables t_user1 > /data/backups/dmp/dmp2.sql
2、只导出建表语句:
- –no-data 申明不导出数据,只导出表结构
mysqldump --host=localhost --user=root -p --databases user --tables t_user1 --no-data > /data/backups/dmp/dmp3.sql
3、条件备份:
- –where 来指定具体的查询条件
- –no-create-db 申明不导出数据库创建等信息
- –no-create-info 申明不导出创建表等信息,这样就可以避免数据表被删除
mysqldump --single-transaction --no-create-db --no-create-info --default-character-set=utf8 --host=localhost --user=root --password=admin --databases user --tables t_user1 --where="id >=3" > /data/backups/dmp/dmp4.sql
3.Xtrabackup物理备份及恢复
Xtrabackup一直作为MEB((MySQL Enterprise Backup)就是MySQL企业版中非常重要的工具之一,是为企业级客户提供的数据备份方案) 开源版备胎而存在
当前xtrabackup的8.0.13已经支持 mysql 8.0.20版本(8.0.20版本对innodb的数据文件模式进行了修改)
程序安装
与mysql环境一样,需要将xtrabackup安装到mysql容器中:
- 在 https://www.percona.com/downloads/Percona-XtraBackup-LATEST/ 中下载二进制包,例如当前docker-mysql容器是 debian的buster系统,则下载对应的文件
percona-xtrabackup-80_8.0.13-1.buster_amd64.deb - 因为上述文件安装会还会依赖其他库,因此要将
/etc/apt/sources.list内容替换为国内镜像,例如阿里云的。 - 更多安装说明,参考https://www.percona.com/doc/percona-xtrabackup/8.0/installation/apt_repo.html
原/etc/apt/sources.list文件内容如下:
# deb http://snapshot.debian.org/archive/debian/20200422T000000Z buster main
deb http://deb.debian.org/debian buster main
# deb http://snapshot.debian.org/archive/debian-security/20200422T000000Z buster/updates main
deb http://security.debian.org/debian-security buster/updates main
# deb http://snapshot.debian.org/archive/debian/20200422T000000Z buster-updates main
deb http://deb.debian.org/debian buster-updates main
将内容全部替换为:
deb http://mirrors.aliyun.com/debian/ buster main non-free contrib
deb http://mirrors.aliyun.com/debian-security buster/updates main
deb http://mirrors.aliyun.com/debian/ buster-updates main non-free contrib
deb http://mirrors.aliyun.com/debian/ buster-backports main non-free contribb
具体命令操作:
# 将容器中的文件拷贝出来
docker cp mysql-dump-test:/etc/apt/sources.list D:\dev2\test\mysqldump
# 将修改后的文件覆盖回容器中
docker cp D:\dev2\test\mysqldump\sources.list mysql-dump-test:/etc/apt/
# 进入容器以后,执行下面命令更新apt信息
apt-get update
完成上述准备工作以后,即可开始安装xtrabackup:
- 将下载好的文件percona-xtrabackup-80_8.0.13-1.buster_amd64.deb,拷贝到容器中
- 通过dpkg来安装,第一次执行会报错,根据错误提示信息,发现最底部依赖libev4
- 执行apt install libev4,此时依然会报错,根据提示信息,执行apt –fix-broken install,此时会下载和安装所有依赖包。
- 上一步执行完成后,再次执行dpkg名称,完成安装
具体命令操作如下:
# 将下载文件拷贝到容器中
docker cp D:\dev2\test\mysqldump\percona-xtrabackup-80_8.0.13-1.buster_amd64.deb mysql-dump-test:/data
# 执行第一次安装,此时会出现错误提示
dpkg -i percona-xtrabackup-80_8.0.13-1.buster_amd64.deb
# 执行libev4 安装,也会出错
apt install libev4
# 执行相关依赖安装
apt --fix-broken install
# 再次执行,完成安装
dpkg -i percona-xtrabackup-80_8.0.13-1.buster_amd64.deb
全量备份及恢复
安装成功后,即可测试全量备份:
- 提前建立好 /data/backups/ 目录
- 通过查看用户手册,整个备份及恢复主要是三个过程:backup、prepa、copy-back
具体命令操作如下:
# 启动全量备份
xtrabackup --backup --target-dir=/data/backups/base1 --user=root --password=admin
# 通过执行drop table t_user1来模拟误操作
# 准备全量恢复
xtrabackup --prepare --target-dir=/data/backups/base1
# 将备份文件同步到mysql数据文件目录中
rsync -avrP /data/backups/base1/ /var/lib/mysql/
# 退出容器后,执行容器重启,完成恢复
docker restart mysql-dump-test
同时,上述rsync也可以用如下命令替代,但需要保证datadir(也即/var/lib/mysql/)是空的:
xtrabackup --copy-back --target-dir=/data/backups/base1
增量备份及恢复
增量备份及恢复过程如下:
- 先创建全量备份
- 再在全量备份基础上,执行增量备份
- 恢复时,先执行全量路径的prepare,再执行增量路径的prepare
备份具体操作:
# 全量备份
xtrabackup --backup --target-dir=/data/backups/base2 --user=root --password=admin
# 第一次增量备份
xtrabackup --backup --target-dir=/data/backups/inc1 --incremental-basedir=/data/backups/base2 --user=root --password=admin
# 第二次增量备份
xtrabackup --backup --target-dir=/data/backups/inc2 --incremental-basedir=/data/backups/inc1 --user=root --password=admin
恢复具体操作:
# 先恢复全量备份
xtrabackup --prepare --apply-log-only --target-dir=/data/backups/base2
# 逐项恢复增量备份
xtrabackup --prepare --apply-log-only --target-dir=/data/backups/base2 --incremental-dir=/data/backups/inc1
xtrabackup --prepare --apply-log-only --target-dir=/data/backups/base2 --incremental-dir=/data/backups/inc2
# 将恢复文件进行同步
rsync -avrP /data/backups/base2/ /var/lib/mysql/
# 退出容器后,执行容器重启,完成恢复
docker restart mysql-dump-test
4.binlog 的几种格式
binlog 格式有三种:row、statement、mixed
案例:
先创建一个表
CREATE TABLE `person` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`income` bigint(20) NOT NULL COMMENT '收入',
`expend` bigint(20) NOT NULL COMMENT '支出',
PRIMARY KEY (`id`),
KEY `idx_income` (`income`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='个人收支表';
插入4条记录:
insert into person values(50,500,500);
insert into person values(60,600,600);
insert into person values(70,700,700);
insert into person values(80,800,800);
查看binlog模式:
查看当前正在写入的binlog文件:
查看 binlog 中的内容,我们先来看下 row 模式
show binlog events in 'mysql-bin.000001';
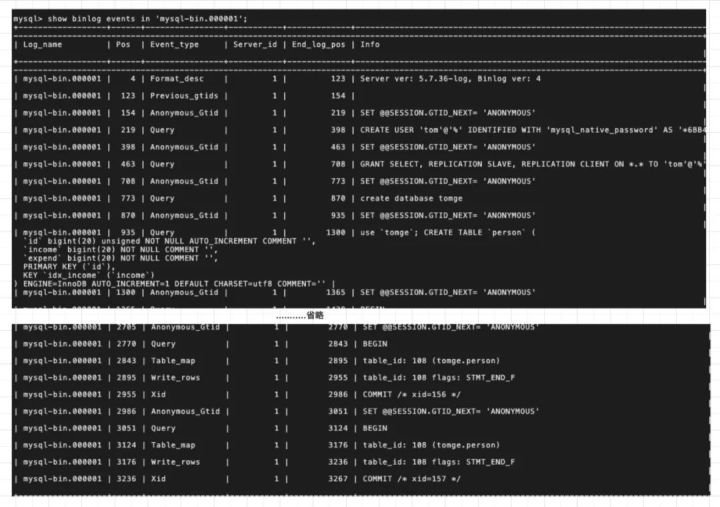
说明:
- SET @@SESSION.GTID_NEXT=’ANONYMOUS’
- BEGIN 开始一个事务
- Table_map 记录更新了哪个库、哪张表
- Write_rows 记录做了什么操作,详细看binlog需要借助mysqlbinlog工具。
- COMMIT /* xid=157 */ 结束一个事务
查找 binlog 文件的物理位置:
root@167bfa3785f1:/# find / -name mysql-bin.000001
/var/lib/mysql/mysql-bin.000001
借助 mysqlbinlog 命令,查看具体内容:
mysqlbinlog -vv mysql-bin.000001 --start-position=2986;
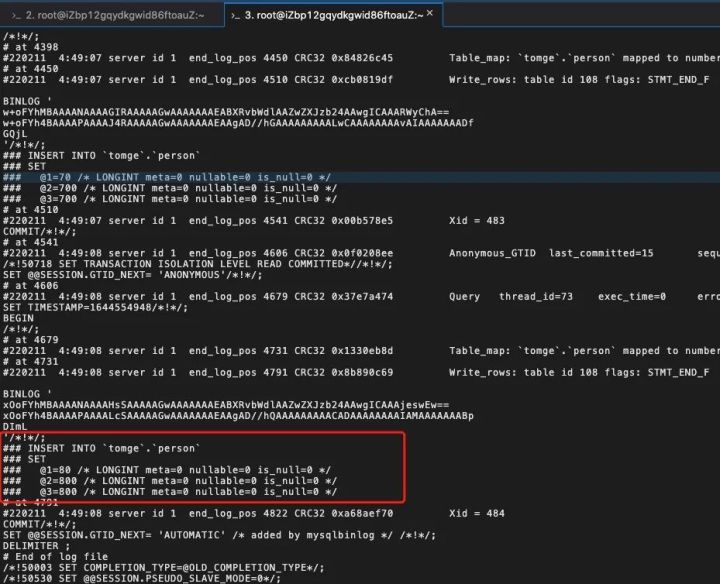
红框中的内容表示执行了插入命令,insert into person values(80,800,800);
其中,@1、@2、@3 表示表 person 的第几个字段,不用原始名称,是为了节省空间。
修改 binlog 格式,设置为 STATEMENT ,查看日志格式:
set global binlog_format='STATEMENT';
设置之后,需要退出mysql重新连接,才能看到生效
show binlog events in 'mysql-bin.000001';
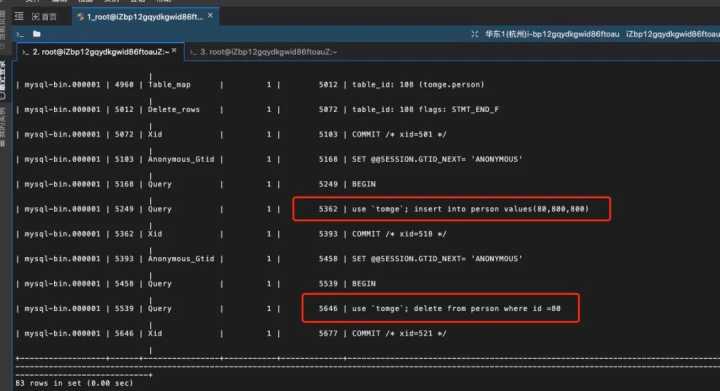
从图中我们可以看出,当 binlog_format=statement 时,binlog 里面记录的就是 SQL 语句的原文。
其中,use tomge :表示要先切到对应的数据库
如果想从指定位置查看binlog,可以增加 from 可选参数,如下:
show binlog events in 'mysql-bin.000001' from 5168;
statement 与 row 对比:
statement 格式的binlog记录的是sql语句;row 格式的binlog记录的是event(Table_map,Write_rows,Delete_rows)
当 binlog 在 statement 格式下,记录的是sql语句,在主库执行时可能使用的是索引 A;但是同步给备库执行时,可能用了 索引B。
索引不同,同一条sql语句,运行结果可能也不一样。
针对这个场景,我们建议采用 row 格式的 binlog。
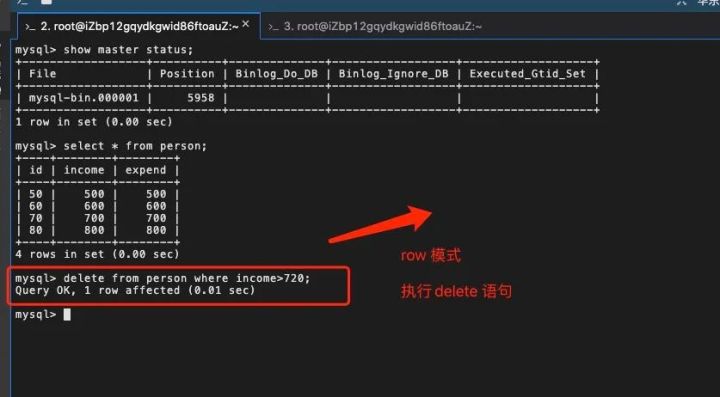
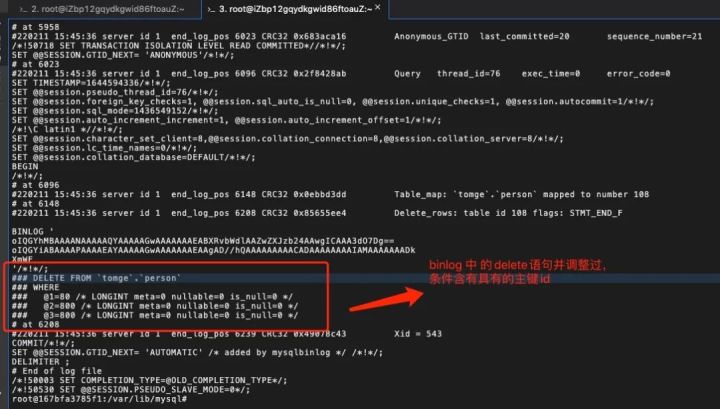
即使我们使用了带where 条件(如:income>720)的delete语句,但 binlog 记录的是要删除的主键id(id =80 ),所以不会出现差错。
mixed 格式 的binlog 是个啥?
由于 statement 格式的binlog 可能会导致主库、备库间的数据同步不一致,因此我们会采用 row 格式。
但是,row 格式占用的空间很大,写 binlog 也要占用大量的 IO 资源。
所以,官方提出一种mixed混合模式,集成了两者的优点。
内容如下:
- mysql会自动判断
statement格式,是否会引发主备不一致的问题 - 如果
statement格式会引起主备不一致的问题,自动使用row格式。 - 如果
statement格式不会引起主备不一致的问题,那么就用statement格式,
5.恢复数据
当然,我们还建议把MySQL 的binlog设置成 row 模式,因为它可以用于数据恢复。我们来看下 insert、update、delete 三种DML操作如何来恢复数据的。
1、delete:
当我们执行 delete 命令时,如果 binlog_row_image 设置了 ‘FULL’,那么 Delete_rows 里面,包含了删掉的行的所有字段的值。
如果误删了,因为 binlog 记录了所有字段的值,反向执行 insert 就可以了。
当
binlog_row_image设置为MINIMAL,只记录关键信息,比如 id=80
2、insert:
row 格式下,binlog 会 记录 insert 的所有字段值。
如果误操作,只需要根据这些值找到对应的行,再执行 delete 操作即可
3、update:
row 格式下,binlog 会 记录 update 修改前、修改后的整行数据。
如果误操作,只需要用修改前的数据覆盖即可。
通过命令来恢复数据:
如果要执行数据恢复,可以使用下面命令
mysqlbinlog mysql-bin.000001 --start-position=1 --stop-position=3000 | mysql -h192.168.0.1 -P3306 -u$user -p$pwd;
将 mysql-bin.000001 文件位置从 1到3000 的 binlog 在 192.168.0.1机器的数据库上回放,还原。
参考文献:
1.https://www.zhihu.com/question/38374712/answer/2431612490
3、update:
row 格式下,binlog 会 记录 update 修改前、修改后的整行数据。
如果误操作,只需要用修改前的数据覆盖即可。
通过命令来恢复数据:
如果要执行数据恢复,可以使用下面命令
mysqlbinlog mysql-bin.000001 --start-position=1 --stop-position=3000 | mysql -h192.168.0.1 -P3306 -u$user -p$pwd;
将 mysql-bin.000001 文件位置从 1到3000 的 binlog 在 192.168.0.1机器的数据库上回放,还原。
参考文献:
1.https://www.zhihu.com/question/38374712/answer/2431612490
2.https://www.zhihu.com/question/38374712/answer/1354598956
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/234823.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
