大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
一、关系数据结构及形式化定义
1、关系
关系模型的数据结构非常简单,只包含单一的数据结构——关系。在用户看来,关系模型中数据的逻辑结构是一张扁平的二维表。
1.1 域
域是一组具有相同数据类型值的集合。
1.2 笛卡儿积
笛卡儿积是域上的一种集合运算。
定义:给定一组域D1,D2,…,Dn,允许其中某些域是相同的,D1,D2,…,Dn的笛卡儿积为D1×D2×…Dn = {(d1,d2,…,dn)|di∈Di,i = 1,2,…,n}
每一个元素(d1,d2,…,dn)叫做一个元组,元素中的每一个值di叫做一个分量。
一个域允许的不同取值个数称为这个域的基数。若Di(i = 1,2,…,n)为有限集,其基数为mi(i = 1,2,…,n)。
笛卡儿积可表示为一张二维表,表中的每行对应一个元组,表中每一列的值来自一个域。
1.3 关系
定义:D1×D2×…×Dn的子集叫做在域D1,D2,…,Dn上的关系,表示为R(D1,D2,…,Dn)。这里R表示关系的名字,n是关系的目或度,关系中的每个元素是关系中的元组,通常用t表示。当n=1时,称该关系为单元关系或一元关系;当n=2时,称该关系为二元关系。
关系是笛卡儿积的有限子集,所以关系也是一张二维表,表的每行对应一个元组,表的每列对应一个域。由于域可以相同,为了加以区分,必须对每列起一个名字,称为属性。n目关系必有n个属性。
若关系中的某一属性组的值能唯一的标识一个元组,而其子集不能,则称该属性组为候选码。若一个关系中有多个候选码,则选定其中一个为主码(primary key)。候选码的诸属性称为主属性。不包含在候选码中的属性称为非主属性或非码属性。简单的情况下,候选码只包含一个属性。最坏情况下,关系模式的所有属性是这个关系模式的候选码,称为全码。
一般来说,笛卡儿积是没有实际语义的,只有它的真子集才有实际含义。
⑴ 关系的三种类型
基本关系(基本表):是实际存在的表,是实际存储的逻辑表示;
查询表:查询结果对应的表;
视图表:是由基本一或其他视图表导出的表,是虚表,不对应实际存储的数据。
⑵ 关系的限定和扩充
① 无限关系在数据库系统中是无意义的,限定关系数据模型中的关系必须是有限集合;
② 通过为关系的每个列附加一个属性名的方法取消关系属性的有序性。
⑶ 基本关系具备的性质
① 列是同质的,每一列中的分量是同一类型的数据,来自同一个域;
② 不同的列可出自同一个域,称其中的每一个列为一个属性,不同的属性要给予不同的属性名;
③ 列的次序可以任意交换;
④ 任意两个元组的候选码不能取相同的值;
⑤ 行的次序可以任意交换;
⑥ 分量必须取原子值,每一个分量都必须是不可再分的数据项。
关系模型要求关系必须是规范化的,即要求关系必须满足一定的规范条件。规范化的关系称为范式。
2、关系模式
定义:关系的描述称为关系模式,它可以表示为R(U,D,DOM,F)。R是关系名,U为组成该关系的属性名集合,D为U中属性所来自的域,DOM为属性向域的映像集合(说明它们出自哪个域,常常直接说明为属性的类型和长度),F为属性间数据的依赖关系集合。
关系是关系模式在某一时刻的状态或内容,关系模式是静态的、稳定的,而关系是动态的、随时间不断变化的,因为关系操作在不断的更新着数据库中的数据。
3、关系数据库
所有关系的集合构成一个关系数据库。
关系数据库也有型和值之分。关系数据库的型称为关系数据库模式,是对关系数据库的描述。关系数据库的值是这些关系模式在某些时刻对应的关系的集合,通常称作关系数据库。
4、关系模型的存储结构
表是关系数据的逻辑模型。
在关系数据库的物理组织中,有的一个表对应一个操作系统文件,将物理数据组织交给操作系统来完成;有的从操作系统那里申请若干个大的文件,自己划分文件空间,组织表、索引等存储结构,并进行存储管理。
二、关系操作
1、基本的关系操作
关系模型中常用的关系操作包括查询(query)操作和插入(insert)、删除(delete)、修改(update)操作两大部分。
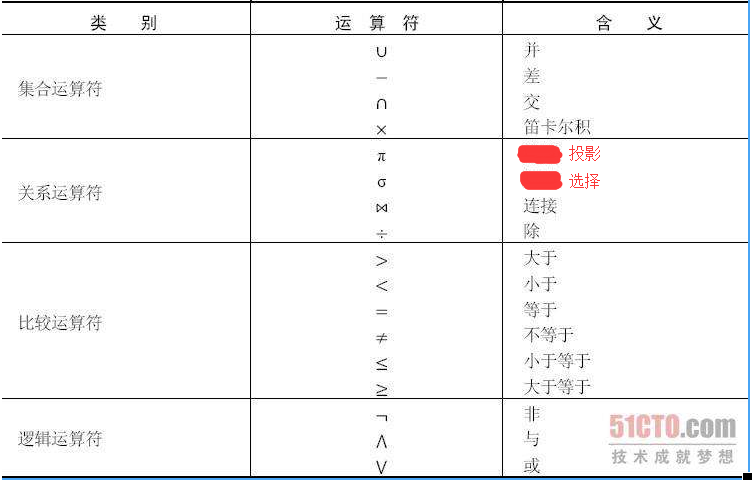
查询操作又可以分为选择(select)、投影(project)、连接(join)、除(divide)、并(union)、差(except)、交(intersection)、笛卡儿积等。其中选择、投影、并、差、笛卡儿积是5种基本操作,其他操作可以用基本操作来定义和导出。
2、关系数据语言的分类
关系数据语言可以分为三类:关系代数语言(如ISBL),关系演算语言,具有关系代数和关系演算双重特点的语言(如SQL)。
2.1 关系代数语言
关系代数用对关系的运算来表达查询要求。
2.2 关系演算语言
关系演算用谓词来表达查询要求。它可按谓词变元的基本对象是元组变量还是域变量分为元组关系演算和域关系演算。
一个关系数据语言能够表示关系代数可以表示的查询,称为具有完备的表达能力,简称关系完备性。已经证明关系代数、元组关系演算和域关系演算三种语言在表达能力上是等价的,都具有完备的表达能力。
2.3 结构化查询语言
它是一种具有关系代数和关系演算双重特点的语言,是集查询、数据定义语言、数据操纵语言和数据控制语言于一体的关系数据语言。
三、关系的完整性
关系模型中有三类完整性约束:实体完整性、参照完整性和用户定义的完整性,其中实体完整性和参照完整性是关系数据模型必须满足的完整性约束条件,被称作是关系的两个不变性,应该由关系系统自动支持。
1、实体完整性
1.1 实体完整性规则
若属性(一个或一组属性)A是基本关系R的主属性,则A不能取空值。
1.2 实体完整性规则说明
⑴ 一个基本表通常对应现实世界的一个实体集;
⑵ 实体在现实世界中是可区分的,它们具有某种唯一性的标识,关系模型中以主码作为唯一性标识;
⑶ 主码中的属性即主属性不能取空值。
2、参照完整性
2.1 参照完整性规则
若属性(一个或一组属性)F是基本关系R的外码,它与基本关系S的主码相对应(R和S有可能是相同的关系),则对于R中每个元组在F上的值必须:或者取空值,或者等于S中某个元组的主码值。
参照完整性规则就是定义外码和主码之间的引用规则。
2.2 参照完整性规则说明
⑴ 不仅两个或两个以上的关系间存在引用关系,同一关系内部属性间也可能存在引用关系(如学生(学员,…,班长));
⑵ 如果F是关系R的一个或一组属性,但不是关系R的主码,K是基本关系S的主码。如果F与K相对应,则称F是R的外码,并称基本关系R为参照关系,基本关系S为被参照关系。关系R和S有可能是相同的关系。
⑶ 外码并不一定发与相对应的主码同名,但实际应用中为了方便识别,一般使用同名;
⑷ 当参照完整性约束和实体完整性约束无法同时满足时,优先满足实体完整性约束,如成绩关系中学号和课程号分别参照学生关系和课程关系中的主码,此时由于学号和课程号是成绩关系中的主属性,则它们不能取空值,只能取被参照关系中已经存在的主码值。
3、用户定义的完整性
用户定义的完整性约束就是针对某一具体关系数据库的约束条件,它反映某一具体应用所涉及的数据必须满足的语义要求,如某个属性必须取唯一值、某个非主属性不能取空值。
四、关系代数
关系代数是一门抽象的查询语言,它用对关系的运算来表达查询。
运算对象、运算符、运算结果是运算的三大要素。关系代数的运算对象是关系,运算结果也是关系,运算符包括:集合运算符和关系运算符。

1、传统的集合运算
传统的集合运算是二目运算,包括并、交、差、笛卡儿积四种运算。以下以oracle为例:
1.1 并(union)
R∪S
其结果仍为n目关系,由属于R或属于S的元组组成。
--结果:2条记录
select * from emp where empno=7369
union
select * from emp where empno=7788--结果:11条记录
select * from emp where sal < 2000 --只有2个20号部门的人,一共8条记录
union
select * from emp where deptno = 20 --20号部门共有5个人,一共5条记录1.2 差(except)
R-S
其结果关系仍为n目关系,由属于R而不属于S的所有元组组成。
--结果:1条记录
select * from emp where deptno=30 --30号部门共有6个人,一共6条记录
minus
select * from emp where deptno=30 and mgr=7698 --部门经理为7698的员工有5个,一共5条记录1.3 交(intersection)
R∩S
其结果仍为n目关系,由既属性R又属于S的元组组成。交可以用差来表示,即R∩S=R-(R-S)。
--结果:5个
select * from emp where deptno=30 --6个
intersect
select * from emp where deptno=30 and mgr=7698 --5个1.4 笛卡儿积
关系R和S的笛卡儿积是一个(n+m)列的元组的集合,元组的前n列是关系R的一个元组,后m列是关系S的一个元组。若R有x个元组,S有y个元组,则关系R和S的笛卡儿积有x*y个元组。
--笛卡儿积(若关系R有n列x行,关系S有m列y行,则R和S的笛卡儿积为列n+m,行x*y)
select a.*,b.* from emp a,dept b --第一种
select * from emp cross join dept --第二种2、专门的关系运算
专门的关系运算包括选择、投影、连接、除运算等。以下以oracle为例:
2.1 选择(selection)
选择的逻辑表达式的基本形式为:XθY。其中θ代表比较运算符,它可以是比较运算符。X、Y是属性名或常量或简单函数。它是从行的角度进行的运算。
select * from emp where sal > 30002.2 投影(projection)
关系R上的投影是从关系R中选出若干属性列组成新的关系。它是从列的角度进行的运算。由于投影取消了某些列之后可能出现重复的行,应取消这些完全相同的行。
select distinct deptno from emp2.3 连接(join)
也称θ连接,它是从两个关系的笛卡儿积中选取属性间满足一定条件的元组。
--向dept中添加列(平均工资)设置10、20、30号部门的平均工资并提交
alter table dept add (avgsal number(10))
update dept set avgsal=3000 where deptno = 10;
update dept set avgsal=2000 where deptno = 20;
update dept set avgsal=1500 where deptno = 30;
commit;
--向emp中添加一条没有部门的员工信息记录并提交
insert into emp(empno,ename,job,mgr,hiredate,sal,comm,deptno) values(8888,'ZHANG','ENGINEER',7788,sysdate,3000,2000,null);
commit;⑴ 非等值连接
θ不为“=”的连接称为非等值连接
select * from emp e join dept d on e.sal > d.avgsal⑵ 等值连接
θ为“=”的连接称为等值连接,它是从关系R和S的笛卡儿积中选取A、B属性值相等的那些元组。等值连接的属性名可以相同也可以不相同。
select * from emp e join dept d on e.sal = d.avgsal
select * from emp e join dept d on e.deptno = d.deptno⑶ 自然连接
自然连接是一种特殊的等值连接,它要求两个关系进行比较的分量必须是同名的属性组,并且在结果中把重复的属性列去掉。一般的连接是从行的角度进行操作,自然连接需要取消重复列,所以它是从行和列的角度进行操作。
select * from emp natural join dept⑷ 外连接
两个关系R和S在做自然连接时,选择两个关系在公共属性上值相等的元组构成新的关系。此时,关系R和S可能有在公共属性上不相等的元组,从而造成R或S中元组的舍弃,这些舍弃的元组被称为悬浮元组。如果把悬浮元组也保存在结果关系中,而在其他属性上填空值,那么这种连接就叫做外连接。
① 左外连接
如果只保留左边关系R中的悬浮元组就叫做左外连接。
select * from emp e left join dept d on e.deptno = d.deptno --员工8888没有部门,只保留左表的悬浮元组,其他属性为null② 右外连接
如果只保留右边关系S中的悬浮元组就叫做右外连接。
select * from emp e right join dept d on e.deptno = d.deptno --40号部门没有人,只保留右表的悬浮元组,其他属性为null③ 全外连接
如果保留两边关系R和S中的所有悬浮无级就叫做全外连接。
select * from emp e full join dept d on e.deptno = d.deptno --保留两边的悬浮元组,左表和右表各有一条悬浮元组记录,一共16行⑸ 自连接
select * from emp e1 join emp e2 on e1.empno = e2.mgr2.4 除运算(division)
设关系R除以关系S的结果为关系T,则关系T包含所有在R但不在S中的属性及其值,且T的元组与S的元组的所有组合都在R中。
⑴ 象集
给定一个关系R(X,Z),X和Z为属性组。它表示R中属性组X上值为x的若干元组在Z上分量的集合。
例:关系R
| x1 | y1 |
| x1 | y2 |
| x1 | y3 |
| x2 | y3 |
| x2 | y1 |
x1在R中的象集Z1={y1,y2,y3}
x2在R中的象集Z2={y3,y1}
⑵ 用象集来定义除法
① 给定关系R(X,Y)和S(Y,Z),其中X、Y、Z为属性组,R中的Y与S中的Y可以有不同的属性名,但必须出自相同的域集;
② 元组在X上的分量值x的象集K要包含S在Y上投影的集合,满足前面条件的元组在X属性上的投影就是R除以S的结果关系;
③ 除操作是同时从行和列角度进行的操作。
例:
关系R
| X | Y |
| x1 | y1 |
| x1 | y2 |
| x1 | y3 |
| x2 | y3 |
| x2 | y5 |
关系S
| Y | Z |
| y1 | z1 |
| y3 | z2 |
R÷S=P,P如下:
| X |
| x1 |
分析:
① S在(Y)上的投影的集合是:{(y1),(y3)};
② 元组在X上的分量值x的象集有两组;
x1的象集K1={(y1),(y2),(y3)}
x2的象集K2={(y3),(y5)}
③ 从①②得知只有象集K1包含了S在(Y)上的投影;
④ 满足以上条件的象集K1在X属性上的投影为{(x1)}。
小结:
在关系代数运算中,并、差、笛卡儿积、选择和投影这5种运算为基本的运算,其他三种运算交、连接、除,均可使用这5种基本运算来表达。它些运算经过有限次复合后形成的表达式称为关系代数表达式。
五、关系数据库的规范化理论
1、关系模式中可能存在的冗余和异常问题
① 数据冗余
数据冗余是指同一数据反复被存取的情况。
② 更新异常
数据冗余将导致存储空间的浪费和潜在数据不一致性以及修改麻烦等问题。
③ 插入异常
数据的插入操作异常是指应该插入到数据库中的数据不能执行插入操作的情形。
④ 删除异常
数据的删除操作异常是指不应该被删除的数据被删去的情形。
小结:
关系模式产生上述问题的原因,以及消除这些问题的方法,都与数据依赖的概念密切相关。数据依赖是可以作为关系模式的取值的任何一种关系所必须满足的一种约束条件,是通过一个关系中各个元组的某些属性之间的相等与否体现出来的相互关系。这是现实世界属性间相互联系的抽象,是数据内在的性质,是语义的体现。
数据依赖,其中最重要的是函数依赖和多值依赖。
2、函数依赖与关键字
函数依赖是指关系中属性间的对应关系。
定义一:
设R为任一给定关系,如果对于R中属性X的每一个值,R中的属性Y只有唯一值与之对应,则称X函数决定Y或称Y函数依赖于X,记作X → Y,其中X称为决定因素。反之,对于关系R中的属性X和Y,若X不能函数决定Y,则其符号记作X →× Y。
例:SNO → SNAME SNAME →× SNO(人名可能有同名同姓的,不能决定学号)
注意:函数依赖是针对关系的所有元组,即某个关系中只要有一个元组的有关属性值不满足函数依赖的定义,则相对应的函数依赖就不成立。
函数依赖根据其不同性质可分为完全函数依赖、部分函数依赖和传递函数依赖。
① 完全函数依赖
定义二:
设R为任一给定关系,X、Y为其属性集,若X → Y,且任何X中的真子集X1都有X1 →× Y,则称Y完全函数依赖于X。
例:(SNO,CNO)→ GRADE(学号和课程编号决定成绩)
② 部分函数依赖
定义三:
设R为任一给定关系,X、Y为其属性集,若X → Y,且X中存在一个真子集X1满足X1 → Y,则称Y部分函数依赖于X。
例:(SNO,SNAME)→ SSEX,但其中SNO → SSEX(学号和姓名可以决定性别,但其中学号可以直接决定性别)
③ 传递函数依赖
定义四:
设R为任一给定关系,X、Y、Z为其不同的属性子集,若X → Y,Y →× X,Y → Z ,则有X → Z,称为Z传递函数依赖于X。(加入条件Y →× X,是因为若Y → X,即有X ←→ Y,这实际上是X直接函数决定Z,而不是X传递函数决定Z)
例:BNO → PNAME (书号决定出版社)和 PNAME → PADDRESS(出版社决定出版社地址),但PNAME →× BNO(一个出版社可能出版多种书),因此有PADDRESS对BNO的传递函数依赖。
定义五:
设R为任一给定关系,U为其所含的全部属性集合,X为U的子集,若有完全函数依赖X → U,则X为R的一个候选关键字。作为候选关键字的属性集X唯一标识R中的元组,但该属性集的任何真子集不能唯一标识R中的元组。显然,一个关系R中可能存在多个候选关键字,通常选择其中之一作为主键,候选关键字中所含的属性称为主属性。
例:属性集(SNO,CNO)为候选关键字,SNO和CNO为主属性
3、范式与关系规范化的过程
关系数据库中的关系需要满足一定的要求,不同程度的要求称为不同的范式。满足最低要求的称为第一范式,简称1NF,这是最基本的范式;在第一范式的基础上进一步满足一些新的要求称为第二范式(2NF);以此类推,再进一步的范式是第三范式(3NF)及其改进形式BCNF。
一个低一级范式的关系模式通过模式分解,可以转换为若干个高一级范式的关系模式的集合,这种过程叫做规范化。
⑴ 第一范式
定义:设R为任一给定关系,如果R中每个列与行的交点处的取值都是不可再分的基本元素,则R为第一范式。
由此可见,第一范式是一个不含重复组的关系,其中不存在嵌套结构,不满足第一范式的关系为非规范关系。下面是一个非规范关系,因为在学号为80154的学生数据中出现了重复组。
| SNO | CNO | CTITLE | INAME | IPLACE | GRADE |
| 80152 | C01 | 操作系统 | 五忠 | 东01 | 70 |
| 80153 | C02 | 数据库 | 高国 | 东02 | 85 |
| 80154 | C01 | 操作系统 | 五忠 | 东01 | 86 |
| C03 | 人工智能 | 杨凡 | 东03 | 72 | |
| 80155 | C04 | C语言 | 高国 | 东02 | 92 |
非规范关系转化为1NF比较容易,可以通过重写关系中属性值相同部分的数据来实现,转化后如下:
| SNO | CNO | CTITLE | INAME | IPLACE | GRADE | |
| 80152 | C01 | 操作系统 | 五忠 | 东01 | 70 | |
| 80153 | C02 | 数据库 | 高国 | 东02 | 85 | |
| 80154 | C01 | 操作系统 | 五忠 | 东01 | 86 | |
| 80154 | C03 | 人工智能 | 杨凡 | 东03 | 72 | |
| 80155 | C04 | C语言 | 高国 | 东02 | 92 | |
然而,上面表中所示的关系存在着冗余高、插入和删除操作异常等问题。比如,若操作系统这门课程被1000个同学选修,那么该授课老师的办公地址就要被存储1000次,这就带来了大量的数据“冗余”;如果学校开设了一门新课程,但尚未有学生选修,则这个课程的信息就无法存储到关系中,此时就出现了“插入异常”的现象;如果删除上面关系中的最后一条记录,则同时也会删除和C语言相关的授课老师的信息,此时会面临“删除异常的问题”。所以,在满足1NF的基础,需要对其进一步进行规范化。
经分析,SC关系出现冗余高、插入异常、删除异常的问题原因在于:非主属性GRADE完全函数依赖于(SNO,CNO),其他非主属性(CTITLE,INAME,IPLACE)都是函数依赖于CNO,即它们与(SNO,CNO)为部分函数依赖关系。那么,解决1NF关系存在问题的方法是:将满足部分函数依赖关系和满足完全函数依赖关系的属性分解并组成两个关系,从而消除非主属性对候选关键字的部分函数依赖,由此获得更高一级的范式。按照此方法关系SC可分解为关系SG和关系CI,如下所示:
| SNO | CNO | GRADE |
| 80152 | C01 | 70 |
| 80153 | C02 | 85 |
| 80154 | C01 | 86 |
| 80154 | C03 | 72 |
| 80155 | C04 | 92 |
| CNO | CTITLE | INAME | IPLACE |
| C01 | 操作系统 | 五忠 | 东01 |
| C02 | 数据库 | 高国 | 东02 |
| C03 | 人工智能 | 杨凡 | 东03 |
| C04 | C语言 | 高国 | 东02 |
⑵ 第二范式
定义:设R为任一给定关系,若R为1NF,且所有非主属性都完全函数依赖于候选关键字,则R为第二范式。
然而,2NF并不能解决所有问题,在关系CI中,如果有一位新老师报到,需将其有关数据插入到CI中去,但该老师暂时还未承担任何教学工作,则因缺失关键字CNO的值而不能进行插入操作。
经分析,产生上述现象的原因在于:关系CI中存在非主属性对主属性的传递函数依赖,即CNO → INAME、INAME →× CNO、INAME → IPLACE。因此,需要将2NF的关系CI进行一步进行规范化,消除非主属性对候选关键字的传递函数依赖。
| CNO | CTITLE | INAME |
| C01 | 操作系统 | 五忠 |
| C02 | 数据库 | 高国 |
| C03 | 人工智能 | 杨凡 |
| C04 | C语言 | 高国 |
| INAME | IPLACE |
| 五忠 | 东01 |
| 高国 | 东02 |
| 杨凡 | 东03 |
⑶ 第三范式
定义:设R为任一给定关系,若R为2NF,且其每一个非主属性都不传递函数依赖于候选关键字,则R为第三范式。
通常,第三范式的关系大多数都能解决插入和删除操作异常的问题,数据冗余也能得到有效的控制,但也存在一些例外。例如如下关系中,若每一个学生可选修多门课程,每一门课程可有多个指导老师,但每个老师只能指导一门课程,则其候选关键字为(SNO,CTITLE)和(SNO,TNAME),故不存在非主属性,也就不存在非主属性对主属性的传递函数依赖。所以,该关系是一个3NF,但其中仍存在插入和删除操作异常问题。例如,一个新课程和指导老师的数据要插入到数据库中,必须至少有一个学生选修该课程且该指导老师已被分配给他时才能进行。
| SNO | CTITLE | TNAME |
| S01 | 英语 | 王华 |
| S01 | 数学 | 沈飞 |
| S02 | 物理 | 高俊 |
| S03 | 英语 | 袁晓 |
| S04 | 英语 | 王华 |
经分析,上述问题的原因在于:主属性之间存在函数依赖TNAME → CTITLE,这里需要对其进一步进行规范化,其结果如下:
| SNO | TNAME |
| S01 | 王华 |
| S01 | 沈飞 |
| S02 | 高俊 |
| S03 | 袁晓 |
| S04 |
王华 |
| TNAME | CTITLE |
| 王华 | 英语 |
| 沈飞 | 数学 |
| 高俊 | 物理 |
| 袁晓 | 英语 |
⑷ BCNF
定义:设R为任一给定关系,X、Y为其属性集,F为其函数依赖集,若R为3NF,且其F中所有函数依赖X → Y(Y不属于X)中的X必包含候选关键字,则R为BCNF
简而言之,若R中每一个函数依赖的决定因素都包含一个候选关键字,则R为BCNF,其中,决定因素可以是单一属性或组合属性。
根据BCNF的定义可知,在关系SCT中,有函数依赖TNAME → CTITLE,但TNAME不是候选关键字。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/234535.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
