大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
High Quality Monocular Depth Estimation via Transfer Learning
arXiv:1812.11941v2 [
cs.CV] 10 Mar 2019
贡献
三个方面。
第一,提出简单的基于转移学习的网络结构,它可以产生更高精度和质量的深度估计。比现有的方法使用更少的参数和迭代次数产生了更为可靠的深度图。
第二,定义了一个相应的损失函数、学习策略和能够使网络更快的学习的简单的数据扩充策略。
第三,我们提出了一个新的具有极好的Ground-truth的逼真的合成室内场景测试数据集,以更好地评估深度估计神经网络的泛化性能。
方法
在本节中,我们将描述从单个RGB图像估计深度图的方法。我们首先描述所采用的编解码器架构。然后讨论我们对编码器和解码器的复杂性及其与性能的关系的观察。接下来,我们针对给定的任务提出一个适当的损失函数。最后,我们描述了有效的增强策略,它显著地帮助培训过程。
网络结构
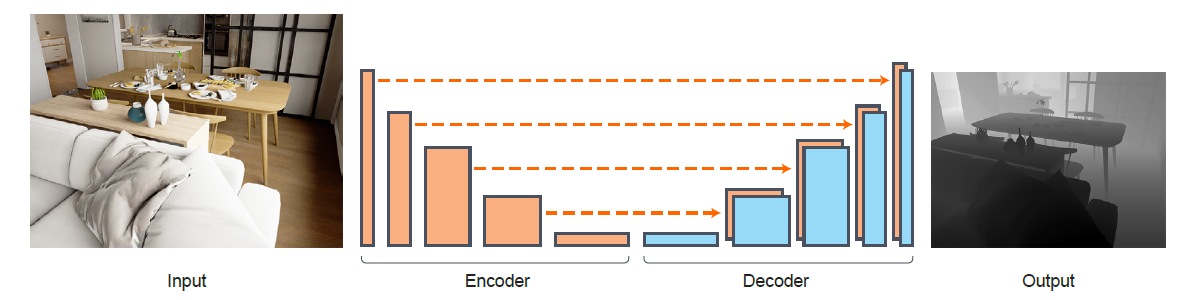

在编码器部分,输入的RGB图像经过一个在ImageNet上预训练过的DenseNet-169网络编码成一个特征向量,这个特征向量接着进入一系列连续的上采样层,使能够在输入分辨率的一半上恢复最终深度图。这些上采样层及其相关的跳频连接构成了我们的解码器。我们的解码器不包含任何BN层或其他先进的层推荐在最近的最先进的方法。附录中描述了关于体系结构及其各层的详细信息以及它们的确切形状。
复杂性和性能
在简单架构下的突出表现引发了以下问题:哪些组件对实现这些高质量的深度图贡献最大。我们用不同的最先进的编码器进行了实验,其复杂度比DenseNet-169要高或低,我们还研究了不同的解码器类型。实验发现,在深度估计的编解码器架构的设置中,卷积块呈现出更复杂的趋势并不一定有助于性能的提高。这使得我们提倡在采用这种复杂的组件和体系结构时进行更彻底的研究。
实验结果表明,由一个2×双线性上采样步跟着标准卷积层组成的简单解码器性能良好。
学习
损失函数
深度回归问题的标准损失函数考虑了深度图(ground-truth)y与深度回归网络的预测 y ^ \hat y y^之间的差异。不同的损失函数考虑会对训练速度和总体深度估计性能产生显著影响。在深度估计的文献中,可以发现许多用于优化神经网络的损失函数的变化。
在我们的方法中,我们试图定义一个损失函数,通过最小化深度值的差异来平衡重建深度图像之间的关系,同时惩罚深度图的图像域中高频细节的失真。这些细节通常对应于场景中对象的边界。
为了训练我们的网络,我们将y和 y ^ \hat y y^之间的损失L定义为三个损失函数的加权和:
L ( y ; y ^ ) = L d e p t h ( y ; y ^ ) + L g r a d ( y ; y ^ ) + L S S I M ( y ; y ^ ) L(y;\hat y) = L_{depth}(y;\hat y) + L_{grad}(y; \hat y) + L_{SSIM}(y; \hat y) L(y;y^)=Ldepth(y;y^)+Lgrad(y;y^)+LSSIM(y;y^)
其中 L d e p t h L_{depth} Ldepth定义为
L d e p t h ( y ; y ^ ) = 1 n ∑ p n ∣ y p − y ^ p ∣ L_{depth}(y;\hat y)=\frac1{n}\sum_{p}^n |y_p-\hat y _p| Ldepth(y;y^)=n1p∑n∣yp−y^p∣
第二损失项 L g r a d L_{grad} Lgrad是深度图像梯度g上定义的L1损失:
L g r a d ( y ; y ^ ) = 1 n ∑ p n ∣ g x ( y p , y ^ p ) ∣ + ∣ g y ( y p , y ^ p ) ∣ L_{grad}(y; \hat y) =\frac1{n}\sum_p^n|g_x(y_p,\hat y_p)|+|g_y(y_p,\hat y_p)| Lgrad(y;y^)=n1p∑n∣gx(yp,y^p)∣+∣gy(yp,y^p)∣
其中 g x g_x gx和 g y g_y gy分别计算深度图像梯度的x分量和y分量的差值。
最后, L S S I M L_{SSIM} LSSIM使用结构相似性(SSIM)项,是图像重建任务中常用的度量指标。最近的研究表明,它是用cnn估计深度的一个很好的损失项。由于SSIM的上界为1,我们将其定义为 L S S I M L_{SSIM} LSSIM,如下
L S S I M ( y , y ^ ) = 1 − S S I M ( y , y ^ ) 2 L_{SSIM}(y,\hat y)=\frac{1-SSIM(y,\hat y)}2 LSSIM(y,y^)=21−SSIM(y,y^)
只为 L d e p t h L_{depth} Ldepth设置一个权重参数 λ \lambda λ=0.1
这种损失项的一个继承问题是,当真值深度值较大时,它们往往更大。为了弥补这个问题,我们考虑深度的倒数,其中对于原始深度图 y o r i g y_{orig} yorig,我们定义目标深度图y为y = m y o r i g \frac{m}{y_{orig}} yorigm,其中m是场景中最大深度(例如在NYU Depth v2数据集中m=10米)。其他方法考虑转换深度值和计算对数空间中的损失)
增强策略
通过几何和尺度变换来增强数据是减少过拟合从而提高泛化性能的一种标准做法。由于我们的网络是用来估计整个图像的深度图的,所以并不是所有的几何变换都是合适的,因为图像域中的畸变并不总是对真实深度有意义的几何解释。将垂直翻转应用于捕捉室内场景的图像可能无助于学习预期的统计特性(例如地板和天花板的几何形状)。
因此,我们只考虑以0.5的概率水平翻转(即镜像)图像。图像旋转是另一种有用的增强策略,然而由于它为相应的真值深度引入了无效数据,所以我们不包括它。
对于光度量转换,我们发现应用不同的颜色通道排列,例如在输入端交换红色和绿色通道,可以提高性能,同时也非常高效。我们将这个颜色通道的扩展概率设置为0.25。寻找改进的数据增强策略及其对深度估计问题的概率值是未来工作的一个有趣的主题。
实验结果
在本节中,我们描述了我们的实验结果,并将我们的网络性能与现有的最先进的方法进行了比较。更重要的是,我们进行了ablation study分析了我们所提出方法的不同部分的影响。最后,我们对一个新提出的高质量深度图数据集的结果进行了比较,以便更好地测试我们的训练模型的泛化性和鲁棒性。
模型简化测试ablation study。
看看取消掉一些模块后性能有没有影响。
根据奥卡姆剃刀法则,简单和复杂的方法能达到一样的效果,那么简单的方法更可靠。
实际上ablation study就是为了研究模型中所提出的一些结构是否有效而设计的实验。
比如你提出了某某结构,但是要想确定这个结构是否有利于最终的效果,那就要将去掉该结构的网络与加上该结构的网络所得到的结果进行对比,这就是ablation study.
数据集
NYU Depth v2是一个提供不同室内场景的图像和深度图的图像数据集,分辨率为640×480。数据集包含120K训练样本和654个测试样本。我们在一个50K子集上训练我们的方法。使用A. Levin, D. Lischinski, and Y. Weiss. Colorization using optimization. ACM Trans. Graph., 23:689–694, 2004. 4的inpainting方法填充缺失的深度值。深度图的上限是10米。我们的网络以输入分辨率的一半进行预测,即分辨率为320×240。对于训练,我们以原始分辨率获取输入图像,并将真实深度下采样到320×240。注意,我们不裁剪任何输入图像-深度映射对,即使它们包含由于失真校正预处理而丢失的像素。在测试期间,我们计算了整个测试图像的深度图预测,然后对其进行2次上采样,以匹配真实分辨率,并对Eigen等人预先定义的中心裁剪进行了评估。在测试时,我们通过对一幅图像的预测和对其镜像的预测的平均值来计算最终的输出。
原文还有对KITTI数据集的训练,有兴趣的朋友可以自行参考。
实验细节
我们使用TensorFlow实现了我们提出的深度估计网络,并在四个NVIDIA TITAN上进行了训练。我们的编码器是一个在ImageNet上预训练好的DenseNet-169。在整个实验中,我们使用学习率为0.0001并且参数值 β 1 = 0.9 , β 2 = 0.999 \beta_1=0.9,\beta_2=0.999 β1=0.9,β2=0.999的ADAM优化器,The batch size设置为8。整个网络的可训练参数总数约为42.6M。1M的迭代次数,需要20小时才能完成。
评估
质量评估
我们使用之前工作中使用的标准6个指标,将我们的方法与最先进的方法进行了定量比较。这些错误度量定义为:
average relative error (rel)(平均相对误差): 1 n ∑ p n y p − y ^ p y \frac1{n}\sum_p^n{\frac{y_p-\hat y_p}y} n1p∑nyyp−y^p
root mean squared error (rms)(均方根误差):
1 n ∑ p n ( y p − y ^ p ) 2 \sqrt{\frac1{n}\sum_p^n(y_p-\hat y_p)^2} n1p∑n(yp−y^p)2
average (log10) error(平均误差):
1 n ∑ p n ∣ l o g 10 ( y p ) − l o g 10 ( y ^ p ) ∣ \frac1{n}\sum_p^n|log_{10}(y_p)-log_{10}(\hat y_p)| n1p∑n∣log10(yp)−log10(y^p)∣
threshold accuracy(阈值精度):
m a x ( y p y ^ p , y ^ p y p ) = δ < t h r , t h r = 1.25 , 1.2 5 2 , 1.2 5 3 max(\frac{y_p}{\hat y_p},\frac{\hat y_p}{y_p})=\delta<thr, thr=1.25,1.25^2,1.25^3 max(y^pyp,ypy^p)=δ<thr,thr=1.25,1.252,1.253
定性结果
我们在NYU Depth v2测试集上进行了三个实验,使用三个测度来近似地评估结果的质量。
第一个度量是一个基于感知的定性度量,它通过查看图像空间结果的相似性来度量结果的质量。我们通过绘制真值和预测深度图的灰度可视化,然后计算整个测试数据集的平均结构相似项来实现这一点.(mSSIM) 1 T ∑ i T S S I M ( y i , y ^ i ) \frac1{T}\sum_i^TSSIM(y_i,\hat y_i) T1i∑TSSIM(yi,y^i)
第二种方法考虑深度图中形成的边缘。对于每个样本,我们使用Sobel梯度算子计算了真值和预测深度图像的梯度幅值,然后在大于0.5的值处对图像进行阈值化,然后计算整个集合的F1平均分数。
F1分数(F1 Score),是统计学中用来衡量二分类模型精确度的一种指标。它同时兼顾了分类模型的精确率和召回率。F1分数可以看作是模型精确率和召回率的一种加权平均,它的最大值是1,最小值是0。(出自百度百科)
数学定义:F1分数(F1-Score),又称为平衡F分数(BalancedScore),它被定义为精确率和召回率的调和平均数。
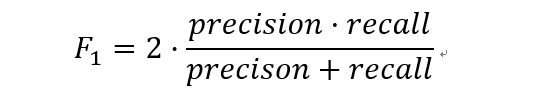
第三个度量是从深度图真值中提取的法线贴图与整个集合的预测深度之间的平均余弦距离。

定性的措施。最左边的一列显示了输入图像(顶部)及其使用ground truth depth提取的法线贴图(底部)。对于下面的列,顶部一行显示了使用Laina等人的[23]、Fu等人的[9]和我们的方法计算的估计深度的阈值梯度大小图像中的差异。亮区域表示错误的边缘,而暗区域表示剩余的缺失边缘。中间一行显示了相应的提取法线映射。下面一行显示了表面法向误差。注意,由于[9]方法生成的深度图具有清晰的步骤,因此计算合理的法线图并不简单。
Ablation Studies
我们进行Ablation Studies来分析我们提出结构的细节。图5展示了在改变我们的标准模型的某些部分或修改我们的训练策略时,从验证损失的角度对测试性能的代表性观察。注意,我们在NYU Depth v2数据集的一个较小子集上执行了这些测试。
深度编码
在这个实验中,我们用具有更密集编码的Densenet-201替换了预先训练好的DenseNet-169。在图5(红色)中,我们可以看到验证损失低于我们的标准模型。不过,需要注意的是,网络中的参数数量增加了2倍以上。当考虑使用DenseNet-201作为我们的编码器,我们发现虽然性能提高,但学习速度慢和GPU内存增加。
深度解码
在这个实验中,我们应用了一个深度约简卷积,使得特征输入解码器只有标准DenseNet-169的一半。在图5(蓝色)中,我们看到性能降低,且总体不稳定。由于这些实验并不能代表一个完整的训练过程,在将特征减半方面的性能差异可能不像我们在运行完整的训练过程中所观察到的那样明显。
颜色增强
在这个实验中,我们关闭了基于颜色通道切换的数据增强。在图5(绿色),我们可以看到一个显著的减少,因为模型往往很快陷入对训练数据的过拟合。我们认为这种简单的数据增强及其对神经网络的显著影响是未来工作的一个有趣的话题。

泛化到其他数据集
为了说明我们的方法是如何推广到其他数据集,我们提出了一个新的数据集,有逼真的室内场景照片和与其对应的完美的深度真值。这些场景是从Unreal marketplace community收集的。我们将这个数据集称为Unreal-1k。这是一个使用虚幻引擎从32个虚拟场景的效果图中随机抽取1000张图片,并绘制相应的深度图的数据集。有关此数据集的详细信息可以在附录中找到。我们将NYU Depth v2训练模型与同样在同一数据集上训练的两种监督方法进行了比较。
我们还计算了前面描述的定性度量mSSIM。图给出了不同预测深度图与地面真实情况的可视化比较。
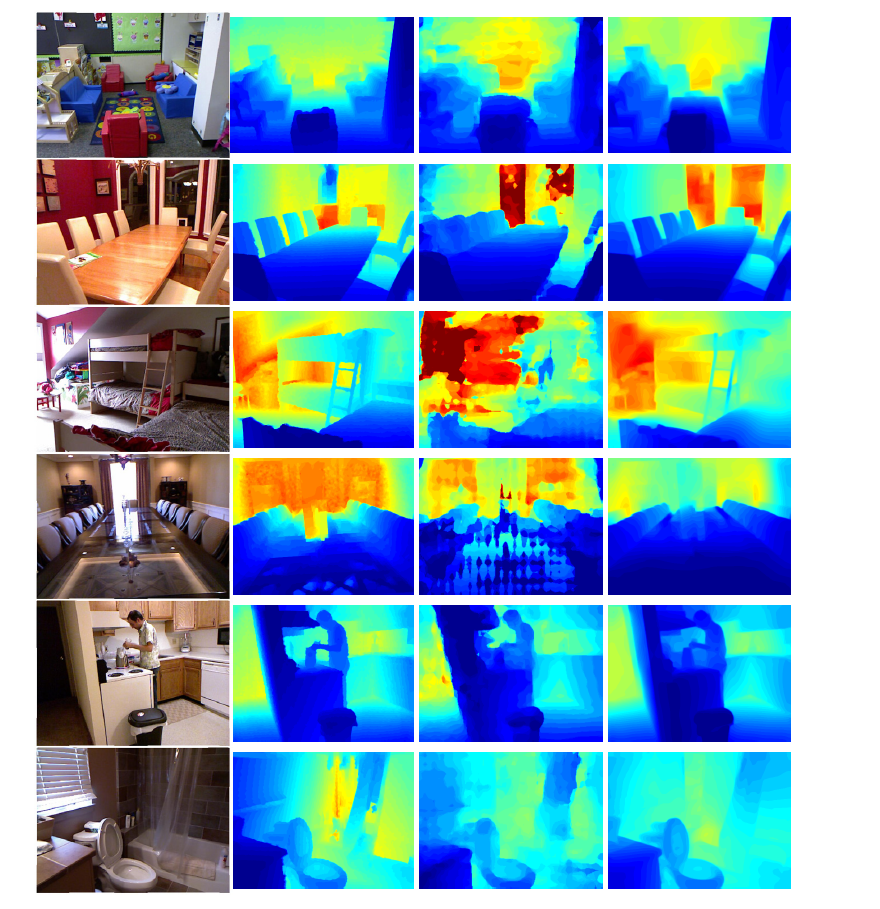
输入RGB图像,深度真值图,最新的[9]结果(由作者提供),我们的估计深度图。请注意,为了更好地可视化,我们对所有深度图的特定真值范围进行标准化

输入RGB图像,深度真值图,结果使用Laina等人的结果[23],我们的估计深度图,傅等人的结果[9]。
结论
在这项工作中,我们利用网络架构的最新进展和高性能预训练模型的可用性,提出了一种卷积神经网络用于单RGB图像的深度图估计。我们证明,有一个构造良好的编码器,初始化有意义的权重,可以比依赖于昂贵的多级深度估计网络或需要设计和结合多个特征编码层的最先进的方法有更好的效果。我们的方法在NYU Depth v2数据集和我们提出的Unreal-1k数据集上展现出最好的性能。我们在这项工作中的目标是推动生成更高质量的深度图,从而更可信地捕捉对象边界,我们已经证明,使用现有的体系结构确实可以做到这一点。按照我们的简单架构,未来工作的一个途径是用一个更紧凑更简洁的编码器替代现有的编码器,以便在嵌入式设备上启用高质量深度图估计。关于我们所提议的网络的局限性的许多问题,以及更清楚地确定不同编码器、扩展和学习策略对性能和贡献的影响,都是未来工作中值得关注的内容。
【9】H. Fu, M. Gong, C. Wang, N. Batmanghelich, and D. Tao.Deep ordinal regression network for monocular depth estimation.2018 IEEE/CVF Conference on Computer Visionand Pattern Recognition, pages 2002–2011, 2018.
【23】I. Laina, C. Rupprecht, V. Belagiannis, F. Tombari, andN. Navab. Deeper depth prediction with fully convolutional residual networks. 2016 Fourth International Conference on3D Vision (3DV), pages 239–248, 2016.
附录
表5显示了带有跳过连接网络(skip connection network)的编解码器的结构。我们的编码器是基于DenseNet-169[17]网络,我们删除了与原始ImageNet分类任务相关的顶层。对于我们的解码器,我们从一个1×1个卷积层开始,它的输出通道数与我们截断的编码器的输出相同。然后我们依次添加上采样块,每个上采样块由2个双线性上采样,然后是2个3×3个卷积层,输出滤波器设置为输入滤波器数量的一半,并且两个的第一个卷积层应用于输出的串联。 前一层和来自编码器的池化层具有相同的空间维度。除最后一个外,每个上采样块后面都有一个带参数的泄漏ReLU激活函数[28]= 0.2。
输入图像由不带数据归一的原始数据在[0,1]内的图像组成,目标深度图裁剪到[0.4;10]米
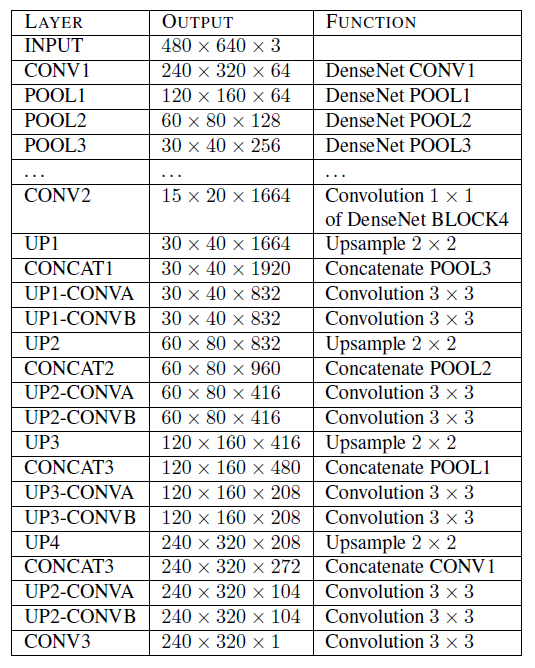 CONV2之前的层正是DenseNet-169[17]的层。上采样是双线性上采样。
CONV2之前的层正是DenseNet-169[17]的层。上采样是双线性上采样。
每个CONVB层后面都有一个泄漏ReLU激活函数[28],参数为0.2。注意,在这个表中,我们使用与数据集NYU Depth v2的空间分辨率相对应的输出形状。
代码实现
https://github.com/ialhashim/DenseDepth
明天进行代码调试。
在使用matplotlib时出现QT平台错误,经过多天实验
安装尝试更新matplotlib
python -m pip install -U pip 更新pip
python -m pip install -U matplotlib 更新matplotlib
成功修复
更新了scikit-image库之后,demo成功运行,结果如下

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/234329.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
