大家好,又见面了,我是你们的朋友全栈君。
写在开头
身处数据爆炸增长的时代,各种各样的数据都飞速增长,视频数据也不例外。我们可以使用 python 来提取视频中的音频,而这仅仅需要安装一个体量很小的python包,然后执行三行程序!
语音数据在数据分析领域极为重要。比如可以分析语义、口音、根据人的情绪等等。可以应用于偏好分析、谎话检测等等。
提取音频
需要用到 python 包 moviepy,这里是moviepy 的 github 地址
安装 python 包
安装 moviepy,cmd 或 bash 输入
pip install moviepy
提取音频
假设有一个 mp4 文件路径为”e:/chrome/my_video.mp4″,我们想提取其音频保存到”“e:/chrome/my_audio.wav””,那么三行程序为:
from moviepy.editor import AudioFileClip
my_audio_clip = AudioFileClip("e:/chrome/my_video.mp4")
my_audio_clip.write_audiofile("e:/chrome/my_audio.wav")
执行上面的三行程序,就会发现音频文件已经成功提取到指定文件夹了~ 这里的视频格式和音频格式都支持其他格式,比如读取 m4v 格式视频,保存 MP3 格式音频,下面是我电脑的示例
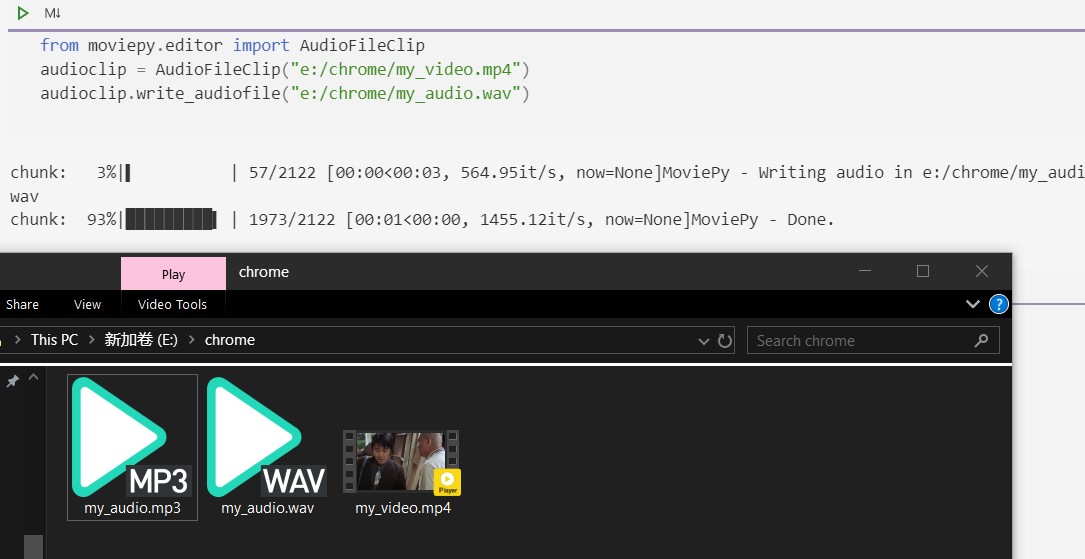

分析音频
可以使用 librosa 包来分析音频,这里是librosa 的 github 地址
安装 python 包
安装 librosa,cmd 或 bash 输入
pip install librosa
需要说明,librosa 包本身不支持 MP3 格式,需要一些相关包的支持。官网上说使用 conda 安装则自动安装 MP3 支持的相关包。具体请去librosa 的 github 地址了解。
读取音频
假设有一个 wav 文件路径为”e:/chrome/my_audio.wav”。科普一下音频数据的内容,可以认为记录采样频率和每个采样点的信号强度两个部分即可构成一个音频文件。数据流可理解为一个数组,按照字节存储。
下面我们读取音频
import librosa
audio, freq = librosa.load('e:/chrome/my_audio.wav')
time = np.arange(0, len(audio)) / freq
print(len(audio), type(audio), freq, sep="\t")
下图是我电脑的示例,可以看到读取到了采样频率和每个采样点的信号强度,采样点共 2121210,频率为 22050,音频长度约 96 秒
matplotlib 画信号强度图
bash 输入
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
ax.plot(time, audio)
ax.set(xlabel='Time(s)', ylabel='Sound Amplitude')
plt.show()
下图是本人电脑示例: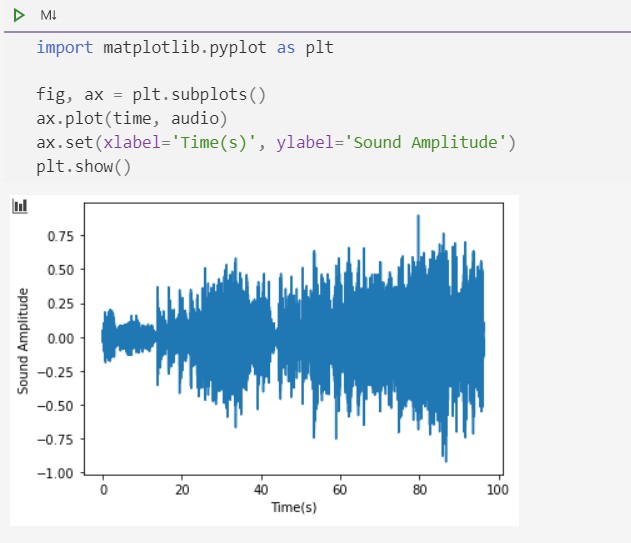
librosa 画信号强度图
当然我们可以使用 librosa 库的工具来分析,可以修掉音频首尾的其他信息,画信号强度图的方式如下:
import librosa.display
audio, _ = librosa.effects.trim(audio)#Trim leading and trailing #silence from an audio signal.
librosa.display.waveplot(audio, sr=freq)
plt.show()
下图是我电脑的示例: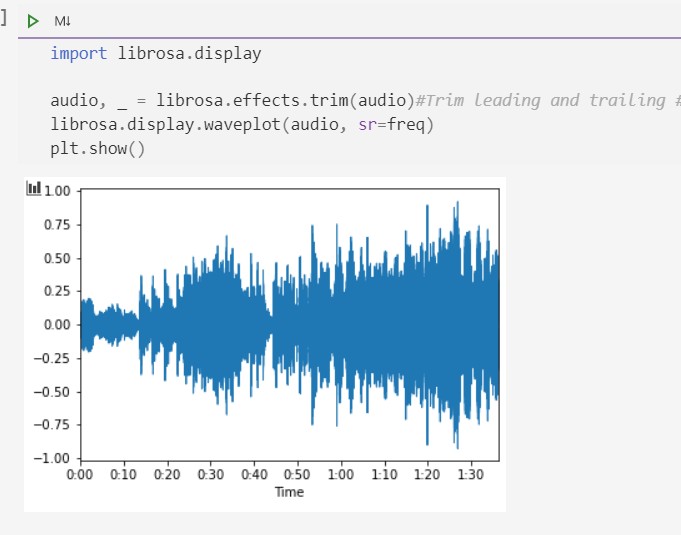
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/144149.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
