大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
本文基于文章“Deep Learning:Technical introduction”,对神经网络的知识点做一个总结,不会对某些概念性的东西做详细介绍,因此需要对神经网络有基本的了解。以下是一些符号定义。


FNN:前馈神经网络
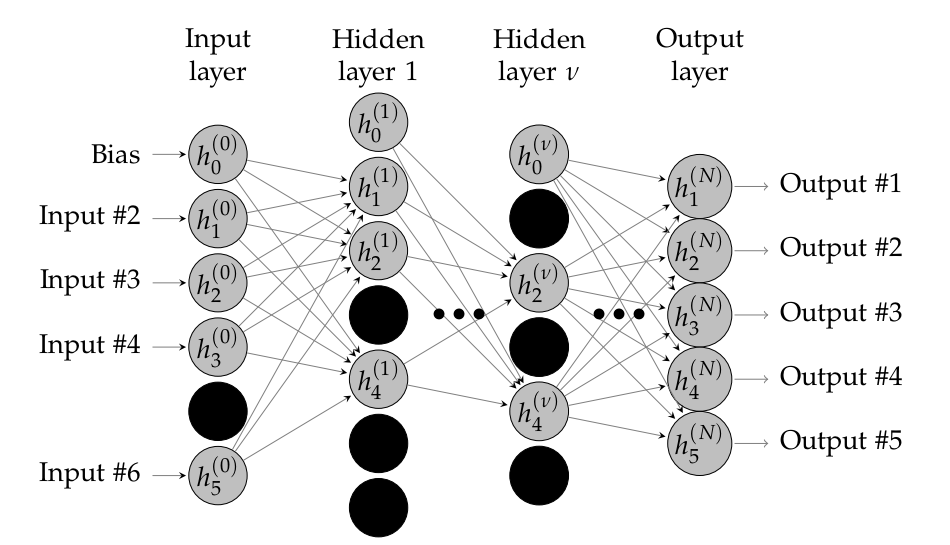
神经网络的最基本也是最经典的形式,结构包括输入层,隐藏层和输出层,根据隐藏层的多少,分为shallow network和deep network(deep learning由此而来)

Activation function
在神经网络的每一层中(不包括输出层),当前层的输出并不是直接作为下一层的输入,而是要经过一个函数变换,这个函数被称为激活函数(Activation function)。
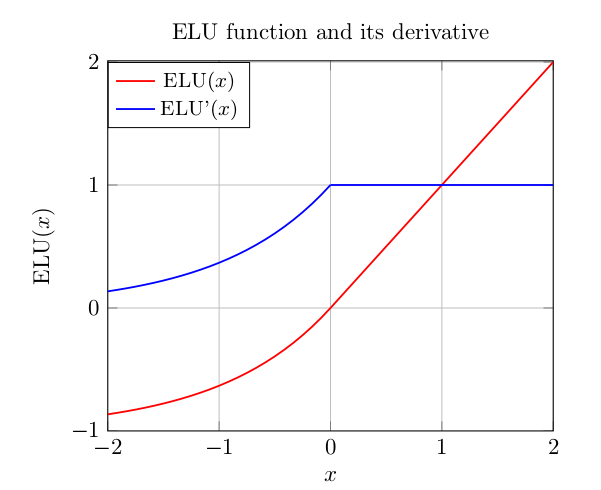
常见的激活函数:
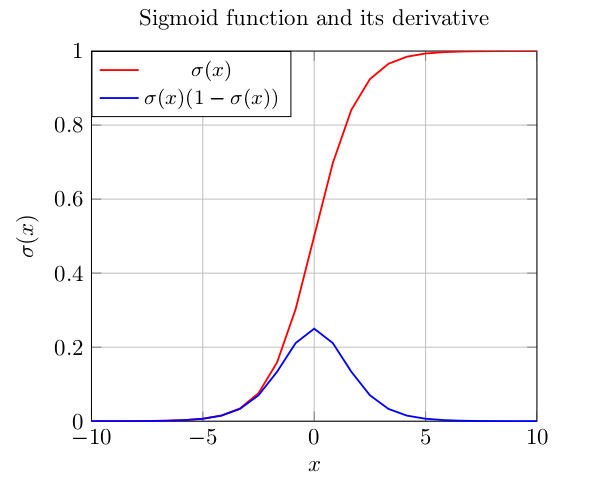
sigmoid函数: g(x)=11+e−x ,由于该函数很容易饱和,从而导致训练过程中梯度变化缓慢的问题,因此,除了在RNN-LSTM中,一般不再作为激活函数使用(但是可以作为输出层,将结果映射为概率)。导数为 g′(x)=g(x)(1−g(x)) 。
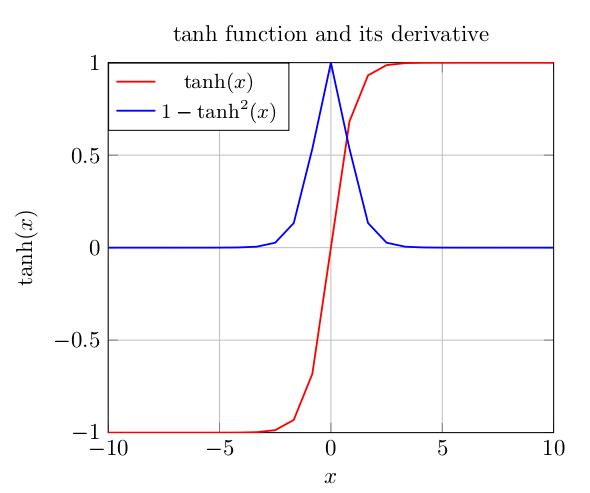
2.双曲正切函数: g(x)=tanh(x)=1−e−2x1+e−2x ,相比sigmoid函数,它是关于原点对称的,在某些情况下,这个对称性能够带来比sigmoid更好的性能。导数为 tanh′(x)=1−tanh2(x) 。
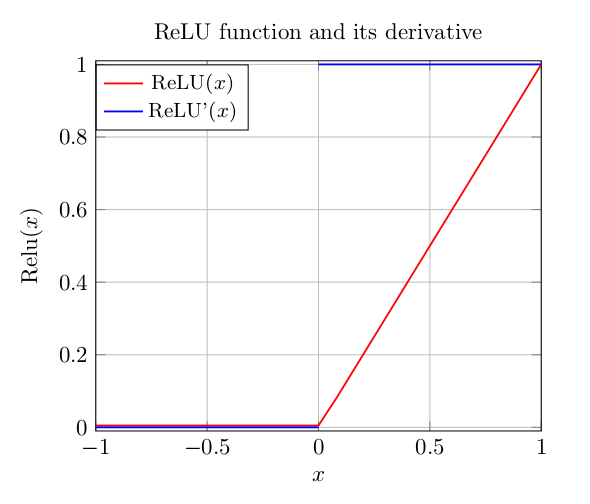
3.Relu:Rectified Linear Unit,线性整流单元,取值范围为 [0,+∞) ,函数形式: Relu(x)=max(0,x) ,这是目前使用最广的激活函数,它有两种变体:leaky Relu和ELU-Exponential Linear Unit。
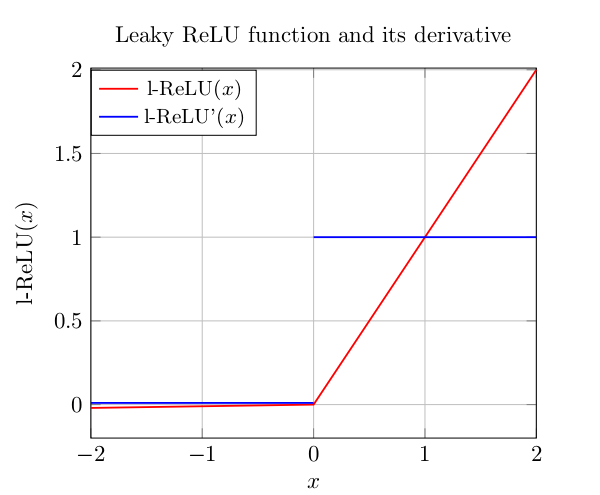
4.leaky Relu:相比较Relu,当x小于0时,它并不取值0,而是去一个很小的系数与x的乘积,这样做的好处是,可以避免当x小于0时,导致输出恒为0,进而导致神经元”死掉”的问题, g(x)=αx if x≤0 else g(x)=x ,一般地, α取0.01
5.ELU:leaky Relu的变体,当x小于0时,不再是一个线性函数: g(x)=ex−1 if x≤0 else g(x)=x
Input Layer
FNN的输入层接受的是一个n维向量,一般会对训练集进行中心化处理,即每个样本减去整个训练集的均值,特别地,当不同维度的连续特征量级不一样时,还需要做标准化或归一化处理。标准化和归一化的方式也有很多种,参见:标准化和归一化
Fully connected layer
FNN中,隐藏层相邻两层之间,前一层的所有单元都会有一个到下一层所有单元的输出,这样的层称为全连接层,后一层某个单元接受到的输入就是前一层所有单元的值的加权和。
Output layer
输出层的值即最后一层隐藏层经过一个output function得到的。输出层可能有一个单元也可能有多个单元
Loss function
损失函数是用来评估我们的预测和真实数据之间的差距,从而来优化我们的模型参数,因此,我们要做的就是最小化损失函数。在回归问题中,损失函数即均方误差(一般情况下);在分类问题中,损失函数即交叉熵。
Regularization
正则化是机器学习中一种重要的技术,它经常用来防止模型过拟合(L2,L1),当然,也可以针对不同的应用场景设置不同的正则化项来完成其他的功能的(譬如,吉洪诺夫正则化)。
L2 regularization
L2正则时使用最多的正则化技术,它通过对目标损失函数增加一个模型参数的L2范数(欧拉范数)的罚项来完成,, λ 称为正则化系数,一般取值为 10−4−10−2 。它有一个贝叶斯解释:L2正则可以理解为一个服从高斯分布的先验加权,即我们的似然函数不再是 P(Y|X) 而是一个具有服从高斯分布的先验 P(Y|X)P(X) 。L2正则最主要的应用就是岭回归。
L1 regularization
L1正则。它通过对目标损失函数增加一个模型参数的L1范数(绝对值)的罚项来完成。常用的主要有LASSO。
L1和L2
相比于L2更倾向于较小的模型参数,L1的解更倾向于稀疏解,即多个参数都为0。如果我们的损失函数是范数和,通过公式可以看到L2范数更关注于大于1的误差(平方会扩大该值),而L1更关注小于1(相比于L2的平方会缩小小于1的误差)的参数,因此对于离群点,L1并不会给该点赋予高的权重,结果影响不会波动的太大,而L2就会受到离群点的干扰。因此,L1正则又被称为鲁棒性正则。
Clipping
参数截断,一般应用于l2正则,通过设置一个阈值C,在迭代过程中,如果参数的L2范数大于了C,则将其重新设置为C:
Dropout
神经网络中正则化技术,称为随机失活,即在网络的反向传播过程中,在每一个隐藏层(也有应用在输入层的)随机选择一定数量(一般地,隐藏层取0.5,输入层取0.2)的神经元,让它‘死掉’,即不接受输入也不给出任何输出。当然,此时每一层的结果在上一层输入经过激活函数之后,还要乘一个系数,它的值等于随机失活的比例:
可以证明,这样做之后与未使用Dropout的结果的期望是相同的。Dropout在批正则化出现之前,一直是神经网络中效果最好的正则化技术。
Batch Normalization
在每一层接受上一层的输出作为输入之前,对输入数据进行标准化,该方法提出的作者认为,这个操作在卷积层之后执行,然后送入激活函数,但是实践表明,在激活之后进行标准化结果会更好。
我们知道在FNN中,参数的初始化和学习率的设置对于模型的最终结果有很大影响,因此我们需要十分小心的去设置和微调这些超参数,并且随着网络的加深,梯度弥散的问题越来越严重,但是有了BN,这些东西我们都不用太关心就能达到很好的效果。
BN在标准化后,为了能够还原原始的分布,在一层的每个神经元新增两个参数,这两个参数也要在反向传播的过程中优化,详细介绍参见原文:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift。
Backpropagation
反向传播就是神经网络中的梯度下降法,我们在前面通过前向传播,将数据输入,得到网络的预测输出,然后,我们根据预测值和实际值的区别,将梯度从网络输出层反向传递至输入层,并在此过程中优化模型参数,降低误差的过程,称为反向传播。它是当前神经网络最成功的训练方法。
定义wljk表示第(l−1)层的第k个神经元连接至第l层的第j个神经元的权重
定义blj表示第l层的第j个神经元的偏置
定义zlj表示第l层的第j个神经元的输入,即:
定义alj表示第l层的第j个神经元的输出,即:
损失函数为:L=12n∑x∥y(x)−y^(x)∥2
定义第l层第j个神经元的损失为δlj=∂C∂zlj,这里C代表当前层的损失。
推导:
1.计算最后一层神经网络产生的误差:
2.递推每一层的误差:
3.计算权重的梯度:
4.计算偏置的梯度:
如果使用了BN操作,则BN的 γ和β 参数也要同时更新,具体的推导公式见上述的论文。
Gradient method
使用梯度优化的方法有很多,在使用相关梯度法求解时,根据每次带入网络的数据量的不同分为full batch(每次迭代用全量样本),mini-batch和stochastic(每次迭代用一个样本),后两者用的较多。
优化算法的详解介绍,参见另一篇博文 最全的机器学习中的优化算法介绍
Weight initialization
在没有任何正则化的情况下,训练一个神经网络是十分困难,因为参数初始化的差异会给结果带来很大的波动(还好我们有了dropout和BN),仍然需要注意的是,不同于机器学习中的分类或者回归问题,我们不能将参数初始化为0(不然所有的神经元永远都没得输出,就没得玩了),当然,也不能将其初始化的过大,一般地,我们采用以下公式初始化参数:
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/234076.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
