大家好,又见面了,我是你们的朋友全栈君。
词向量的表示可以分成两个大类1:基于统计方法例如共现矩阵、奇异值分解SVD;2:基于语言模型例如神经网络语言模型(NNLM)、word2vector(CBOW、skip-gram)、GloVe、ELMo。
word2vector中的skip-gram模型是利用类似于自动编码的器网络以中心词的one-hot表示作为输入来预测这个中心词环境中某一个词的one-hot表示,即先将中心词one-hot表示编码然后解码成环境中某个词的one-hot表示(多分类模型,损失函数用交叉熵)。CBOW是反过来的,分别用环境中的每一个词去预测中心词。尽管word2vector在学习词与词间的关系上有了大进步,但是它有很明显的缺点:只能利用一定窗长的上下文环境,即利用局部信息,没法利用整个语料库的全局信息。鉴于此,斯坦福的GloVe诞生了,它的全称是global vector,很明显它是要改进word2vector,成功利用语料库的全局信息。
1. 共现概率
什么是共现?
单词 i i i出现在单词 j j j的环境中(论文给的环境是以 j j j为中心的左右10个单词区间)叫共现。
什么是共现矩阵?
单词对共现次数的统计表。我们可以通过大量的语料文本来构建一个共现统计矩阵。
例如,有语料如下:
I like deep learning.
I like NLP.
I enjoy flying.
我以窗半径为1来指定上下文环境,则共现矩阵就应该是[2]:
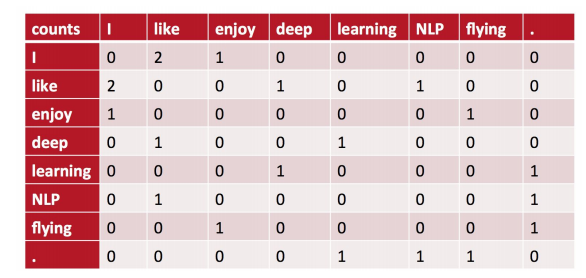

取 x 01 x_{01} x01解释:它表示 l i k e like like出现在 I I I的环境( I l i k e I like Ilike区间)中的次数(在整个语料库中的总计次数),此处应当为2次,故第一行第二列应当填2。还应当发现,这个共现矩阵它是对称阵,因为 l i k e like like出现在 I I I的环境中,那么必然 I I I也会出现在 l i k e like like的环境中,所以 x 10 x_{10} x10=2。
共现矩阵它有以下3个特点:
·统计的是单词对在给定环境中的共现次数;所以它在一定程度上能表达词间的关系。
·共现频次计数是针对整个语料库而不是一句或一段文档,具有全局统计特征。
·共现矩阵它是对称的。
共现矩阵的生成步骤:
· 首先构建一个空矩阵,大小为 V × V V ×V V×V,即词汇表×词汇表,值全为0。矩阵中的元素坐标记为 ( i , j ) (i,j) (i,j)。
· 确定一个滑动窗口的大小(例如取半径为m)
· 从语料库的第一个单词开始,以1的步长滑动该窗口,因为是按照语料库的顺序开始的,所以中心词为到达的那个单词即 i i i。
· 上下文环境是指在滑动窗口中并在中心单词 i i i两边的单词(这里应有2m-1个 j j j)。
· 若窗口左右无单词,一般出现在语料库的首尾,则空着,不需要统计。
· 在窗口内,统计上下文环境中单词 j j j出现的次数,并将该值累计到 ( i , j ) (i,j) (i,j)位置上。
· 不断滑动窗口进行统计即可得到共现矩阵。
什么是叫共现概率?
我们定义 X X X为共现矩阵,共现矩阵的元素 x i j x_{ij} xij为词 j j j出现在词 i i i环境的次数,令 x i = ∑ k x i k x_i=\sum_kx_{ik} xi=∑kxik为任意词出现在 i i i的环境的次数(即共现矩阵行和),那么, P i j = P ( j ∣ i ) = x i j x i P_{ij}=P(j|i)={x_{ij}\over x_{i}} Pij=P(j∣i)=xixij
为词 j j j出现在词 i i i环境中的概率(这里以频率表概率),这一概率被称为词 i i i和词 j j j的共现概率。共现概率是指在给定的环境下出现(共现)某一个词的概率。注意:在给定语料库的情况下,我们是可以事先计算出任意一对单词的共现概率的。
2. 共现概率比
接下来阐述为啥作者要提共现概率和共现概率比这一概念。下面是论文中给的一组数据:
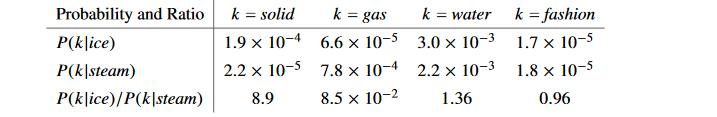
先看一下第一行数据,以 i c e ice ice为中心词的环境中出现 s o l i d solid solid固体的概率是大于 g a s 、 f a s h i o n gas、fashion gas、fashion的而且是小于 w a t e r water water的,这是很合理的,对吧!因为有 i c e ice ice的句子中出现 s o l i d 、 w a t e r solid、water solid、water的概率确实应当比 g a s 、 f a s h i o n gas、fashion gas、fashion大才对,实验数据也说明的确是如此。同理可以解释第二行数据。我们来重点考虑第三行数据:共现概率比。我们把共现概率进行一比,我们发现:
1.看第三行第一列:当 i c e ice ice的语境下共现 s o l i d solid solid的概率应该很大,当 s t r e a m stream stream的语境下共现 s o l i d solid solid的概率应当很小,那么比值就>1。
2.看第三行第二列:当 i c e ice ice的语境下共现 g a s gas gas的概率应该很小,当 s t r e a m stream stream的语境下共现 g a s gas gas的概率应当很大,那么比值就<1。
3.看第三行第三列:当 i c e ice ice的语境下共现 w a t e r water water的概率应该很大,当 s t r e a m stream stream的语境下共现 w a t e r water water的概率也应当很大,那么比值就近似=1。
4.看第三行第四列:当 i c e ice ice的语境下共现 f a s h i o n fashion fashion的概率应该很小,当 s t r e a m stream stream的语境下共现 f a s h i o n fashion fashion的概率也应当很小,那么比值也是近似=1。
因为作者发现用共现概率比也可以很好的体现3个单词间的关联(因为共现概率比符合常理),所以glove作者就大胆猜想,如果能将3个单词的词向量经过某种计算可以表达共现概率比就好了(glove思想)。如果可以的话,那么这样的词向量就与共现矩阵有着一致性,可以体现词间的关系。
3. 设计词向量函数
想要表达共现概率比,这里涉及到的有三个词即 i , j , k i,j,k i,j,k,它们对应的词向量我用 v i 、 v j 、 v ~ k v_i、v_j、\widetilde{v}_k vi、vj、v
k表示,那么我们需要找到一个映射 f f f,使得 f ( v i , v j , v ~ k ) = P i k P j k f(v_i,v_j,\widetilde{v}_k)={P_{ik}\over P_{jk}} f(vi,vj,v
k)=PjkPik (1)。前面我说过,任意两个词的共现概率可以用语料库事先统计计算得到,那这里的给定三个词,是不是也可以确定共现概率比啊。这个比值可以作为标签,我们可以设计一个模型通过训练的方式让映射值逼近这个确定的共现概率比。很明显这是个回归问题,我们可以用均方误差作为 l o s s loss loss。明显地,设计这个函数或者这个模型当然有很多途径,我们来看看作者是怎么设计的。
我们可以发现公式(1)等号右侧结果是个标量,左边是个关于向量的函数,如何将函数变成标量。于是作者这么设计: f ( ( v i − v j ) T v ~ k ) = P i k P j k f((v_i-v_j)^T\widetilde{v}_k)={P_{ik}\over P_{jk}} f((vi−vj)Tv
k)=PjkPik (2)即向量做差再点积再映射到目标。再次强调,这只是一种设计,它可能不是那么严谨,合理就行。于是乎:

于是,glove模型的学习策略就是通过将词对儿的词向量经过内积操作和平移变换去趋于词对儿共现次数的对数值,这是一个回归问题。于是作者这样设计损失函数: J = ∑ i = 1 N ∑ j = 1 N f ( x i j ) ( v i T v ~ j + b i + b j − l o g ( x i j ) ) 2 J=\sum_{i=1}^{N}\sum_{j=1}^{N}f(x_{ij})(v_i^T\widetilde{v}_j+b_i+b_j-log(x_{ij}))^2 J=i=1∑Nj=1∑Nf(xij)(viTv
j+bi+bj−log(xij))2
这里用的是误差平方和作为损失值,其中N表示语料库词典单词数。它这里在误差平方前给了一个权重函数 f ( x i j ) f(x_{ij}) f(xij),这个权重是用来控制不同大小的共现次数( x i j x_{ij} xij)对结果的影响的。作者是这么设计这个权重函数的:
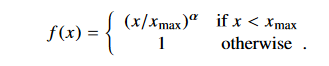
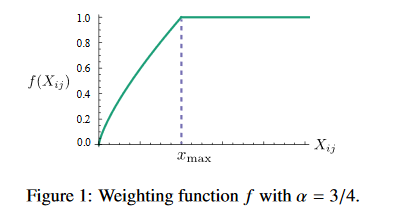
也就是说词对儿共现次数越多的它有更大的权重将被惩罚得更厉害些,次数少的有更小的权重,这样就可以使得不常共现的词对儿对结果的贡献不会太小,而不会过分偏向于常共现的词对儿。此外,当 x i j x_{ij} xij=0时,加入了这个权重函数此时该训练样本的损失直接为0,从而避免了 l o g ( x i j ) log(x_{ij}) log(xij)为无穷小导致损失值无穷大的问题。
4. GloVe模型算法
最后,关于glove模型算法,大致是这样的:从共现矩阵中随机采集一批非零词对作为一个mini-batch的训练数据;随机初始化这些训练数据的词向量以及随机初始化两个偏置;然后进行内积和平移操作并与 l o g ( x i j ) log(x_{ij}) log(xij)计算损失值,计算梯度值;然后反向传播更新词向量和两个偏置;循环以上过程直到结束条件。论文中还提到一个词最终的glove词向量用的是训练后的两个词向量之和,关于这一点论文中有解释,如果感兴趣的话最好阅读一下原论文。
reference:
[1] 来b站搞学习
[2] https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1184/lectures/midterm-review.pdf
[3] GloVe论文
[4] glove开源代码
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/133216.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
