大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
simhash与重复信息识别
来源:
http://grunt1223.iteye.com/blog/964564
在工作学习中,我往往感叹数学奇迹般的解决一些貌似不可能完成的任务,并且十分希望将这种喜悦分享给大家,就好比说:“老婆,出来看上帝”……
随着信息爆炸时代的来临,互联网上充斥着着大量的近重复信息,有效地识别它们是一个很有意义的课题。例如,对于搜索引擎的爬虫系统来说,收录重复的网页是毫无意义的,只会造成存储和计算资源的浪费;同时,展示重复的信息对于用户来说也并不是最好的体验。造成网页近重复的可能原因主要包括:
- 镜像网站
- 内容复制
- 嵌入广告
- 计数改变
- 少量修改
一个简化的爬虫系统架构如下图所示: 

事实上,传统比较两个文本相似性的方法,大多是将文本分词之后,转化为特征向量距离的度量,比如常见的欧氏距离、海明距离或者余弦角度等等。两两比较固然能很好地适应,但这种方法的一个最大的缺点就是,无法将其扩展到海量数据。例如,试想像Google那种收录了数以几十亿互联网信息的大型搜索引擎,每天都会通过爬虫的方式为自己的索引库新增的数百万网页,如果待收录每一条数据都去和网页库里面的每条记录算一下余弦角度,其计算量是相当恐怖的。
我们考虑采用为每一个web文档通过hash的方式生成一个指纹(fingerprint)。传统的加密式hash,比如md5,其设计的目的是为了让整个分布尽可能地均匀,输入内容哪怕只有轻微变化,hash就会发生很大地变化。我们理想当中的哈希函数,需要对几乎相同的输入内容,产生相同或者相近的hashcode,换句话说,hashcode的相似程度要能直接反映输入内容的相似程度。很明显,前面所说的md5等传统hash无法满足我们的需求。
simhash是locality sensitive hash(局部敏感哈希)的一种,最早由Moses Charikar在《similarity estimation techniques from rounding algorithms》一文中提出。Google就是基于此算法实现网页文件查重的。我们假设有以下三段文本:
- the cat sat on the mat
- the cat sat on a mat
- we all scream for ice cream
使用传统hash可能会产生如下的结果:
使用simhash会应该产生类似如下的结果:
海明距离的定义,为两个二进制串中不同位的数量。上述三个文本的simhash结果,其两两之间的海明距离为(p1,p2)=4,(p1,p3)=16以及(p2,p3)=12。事实上,这正好符合文本之间的相似度,p1和p2间的相似度要远大于与p3的。
如何实现这种hash算法呢?以上述三个文本为例,整个过程可以分为以下六步:
1、选择simhash的位数,请综合考虑存储成本以及数据集的大小,比如说32位
2、将simhash的各位初始化为0
3、提取原始文本中的特征,一般采用各种分词的方式。比如对于”the cat sat on the mat”,采用两两分词的方式得到如下结果:{“th”, “he”, “e “, ” c”, “ca”, “at”, “t “, ” s”, “sa”, ” o”, “on”, “n “, ” t”, ” m”, “ma”}
4、使用传统的32位hash函数计算各个word的hashcode,比如:”th”.hash = -502157718
,”he”.hash = -369049682,……
5、对各word的hashcode的每一位,如果该位为1,则simhash相应位的值加1;否则减1
6、对最后得到的32位的simhash,如果该位大于1,则设为1;否则设为0
整个过程可以参考下图: 
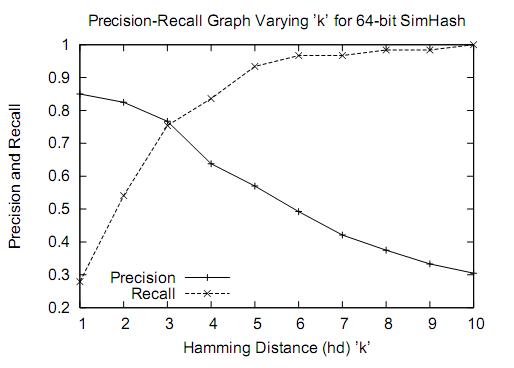
按照Charikar在论文中阐述的,64位simhash,海明距离在3以内的文本都可以认为是近重复文本。当然,具体数值需要结合具体业务以及经验值来确定。
使用上述方法产生的simhash可以用来比较两个文本之间的相似度。问题是,如何将其扩展到海量数据的近重复检测中去呢?譬如说对于64位的待查询文本的simhash code来说,如何在海量的样本库(>1M)中查询与其海明距离在3以内的记录呢?下面在引入simhash的索引结构之前,先提供两种常规的思路。第一种是方案是查找待查询文本的64位simhash code的所有3位以内变化的组合,大约需要四万多次的查询,参考下图: 
另一种方案是预生成库中所有样本simhash code的3位变化以内的组合,大约需要占据4万多倍的原始空间,参考下图: 
显然,上述两种方法,或者时间复杂度,或者空间复杂度,其一无法满足实际的需求。我们需要一种方法,其时间复杂度优于前者,空间复杂度优于后者。
假设我们要寻找海明距离3以内的数值,根据抽屉原理,只要我们将整个64位的二进制串划分为4块,无论如何,匹配的两个simhash code之间至少有一块区域是完全相同的,如下图所示: 
由于我们无法事先得知完全相同的是哪一块区域,因此我们必须采用存储多份table的方式。在本例的情况下,我们需要存储4份table,并将64位的simhash code等分成4份;对于每一个输入的code,我们通过精确匹配的方式,查找前16位相同的记录作为候选记录,如下图所示: 
让我们来总结一下上述算法的实质:
1、将64位的二进制串等分成四块
2、调整上述64位二进制,将任意一块作为前16位,总共有四种组合,生成四份table
3、采用精确匹配的方式查找前16位
4、如果样本库中存有2^34(差不多10亿)的哈希指纹,则每个table返回2^(34-16)=262144个候选结果,大大减少了海明距离的计算成本
我们可以将这种方法拓展成多种配置,不过,请记住,table的数量与每个table返回的结果呈此消彼长的关系,也就是说,时间效率与空间效率不可兼得,参看下图: 
事实上,这就是Google每天所做的,用来识别获取的网页是否与它庞大的、数以十亿计的网页库是否重复。另外,simhash还可以用于信息聚类、文件压缩等。
也许,读到这里,你已经感受到数学的魅力了。
simhash与Google的网页去重
来源:http://leoncom.org/?p=650607
前几天去吃葫芦头的路上,大飞哥给详细的讲解了他在比较文本相似度实验时对Google的simhash方法高效的惊叹,回来特意去找了原文去拜读。
Simhash
传统IR领域内文本相似度比较所采用的经典方法是文本相似度的向量夹角余弦,其主要思想是根据一个文章中出现词的词频构成一个向量,然后计算两篇文章对应向量的向量夹角。但由于有可能一个文章的特征向量词特别多导致整个向量维度很高,使得计算的代价太大,对于Google这种处理万亿级别的网页的搜索引擎而言是不可接受的,simhash算法的主要思想是降维,将高维的特征向量映射成一个f-bit的指纹(fingerprint),通过比较两篇文章的f-bit指纹的Hamming Distance来确定文章是否重复或者高度近似。
simhash算法很精巧,但却十分容易理解和实现,具体的simhash过程如下:
1. 首先基于传统的IR方法,将文章转换为一组加权的特征值构成的向量。
2.初始化一个f维的向量V,其中每一个元素初始值为0。
3.对于文章的特征向量集中的每一个特征,做如下计算:
利用传统的hash算法映射到一个f-bit的签名。对于这个f- bit的签名,如果签名的第i位上为1,则对向量V中第i维加上这个特征的权值,否则对向量的第i维减去该特征的权值。
4.对整个特征向量集合迭代上述运算后,根据V中每一维向量的符号来确定生成的f-bit指纹的值,如果V的第i维为正数,则生成f-bit指纹的第i维为1,否则为0。

simhash和普通hash最大的不同在于传统的hash函数虽然也可以用于映射来比较文本的重复,但是对于可能差距只有一个字节的文档也会映射成两个完全不同的哈希结果,而simhash对相似的文本的哈希映射结果也相似。Google的论文中取了f=64,即将整个网页的加权特征集合映射到一个64-bit的fingerprint上。
比起simhash,整片文章中Google所采用的查找与给定f-bit的fingerprint的海明距离(Hamming Distance)小于k的算法相对还稍微难理解点。
fingerprint的Hamming Distance
问题:一个80亿的64-bit指纹组成的集合Q,对于一个给定64-bit的指纹F,如何在a few millionseconds中找到Q中和f至多只有k(k=3)位差别的指纹。
思想:1. 对于一个具有2^d个记录的集合,只需要考虑d-bit hash。2. 选取一个d’使得|d’-d|十分小,因此如果两fingerprint在d’-bits上都相同,那么在d-bits也很可能相同。然后在这些d-bit match的结果中寻找整个f-bit的Hamming Distance小于k的fingerprint。 简单的说,就是利用fingerprint少量特征位数比较从而首先缩小范围,然后再去确定是否差异小于k个bit。
算法:
1. 首先对于集合Q构建多个表T1,T2…Tt,每一个表都是采用对应的置换函数π(i)将64-bit的fingerprint中的某p(i)位序列置换换到整个序列的最前面。即每个表存储都是整个Q的fingerprint的复制置换。
2.对于给定的F,在每个Ti中进行匹配,寻找所有前pi位与F经过π(i)置换后的前pi位相同的fingerprint。
3.对于所有在上一步中匹配到的置换后的fingerprint,计算其是否与π(i)(F)至多有k-bit不同。
算法的重点在于对于集合Q的分表以及每个表所对应的置换函数,假设对于64-bit的fingerprint,k=3,存储16个table,划分参考下图:

将64-bit按照16位划分为4个区间,每个区间剩余的48-bit再按照每个12-bit划分为4个区间,因此总共16个table并行查找,即使三个不同的k-bit落在A、B、C、D中三个不同的区块,此划分方法也不会导致遗漏。
以上方法是对于online的query,即一个给定的F在集合中查找相似的fingerprint。如果爬虫每天爬取了100w个网页,快速的查找这些新抓取的网页是否在原集合中有Near-duplication,对于这种batch-query的情况,Map-Reduce就发挥它的威力了。

不同的是,在batch-query的处理中,是对待查集合B(1M个fingerprint)进行复制置换构建Table而非8B的目标集合,而在每一个chunkserver上对Fi(F为整个8B的fingerprint)在整个Table(B)中进行探测,每一个chunkserver上的的该Map过程输出该Fi中与整个B的near-duplicates,Reduces过程则将所有的结果收集、去重、然后输出为一个sorted file。
Haffman编码压缩
上述的查询过程,特别是针对online-version的算法,可以看出需要对8B的fingerprint进行多表复制和构建,其占据的容量是非常大的,不过由于构建的每一个置换Table都是sorted的,因此可以利用每一个fingerprint与其前一个的开始不同的bit-position h(h∈[0,f-1]) 来进行数据压缩,即如果前一个编码是11011011,而自身是11011001,则后一个可以编码为(6)1,即h=6,其中6表示从第6位(从0开始编号)开始和上一个fingerprint不相同(上一个为1,这个必然为0),然后再保存不相同位置右侧的编码,依次生成整个table。
Google首先计算整个排序的fingerprint表中h的分布情况,即不同的h出现次数,依据此对[0,f-1]上出现的h建立Haffman code,再根据上述规则生成table(例如上面的6就表示成对应的Haffman code)。其中table分为多个block,每一个block中的第一个fingerprint保存原数据,后面的依次按照编码生成。
将每一个block中所对应的最后一个fingerprint保存在内存中,因此在比对的时候就可以直接根据内存中的fingerprint来确定是哪一个block需要被decompress进行比较。
8B个64-bit的fingerprint原占据空间大约为64GB,利用上述Haffman code压缩后几乎会减少一般,而内存中又只对每一个block保存了一个fingerprint。
每次看Google的论文都会让人眼前一亮,而且与很多(特别是国内)的论文是对未来进行设想不同,Google的东西都是已经运行了2,3年了再到WWW,OSDI这种顶级会议上灌个水。再次各种羡慕能去这个Dream Company工作的人,你们懂得。
参考:
Detecting Near-Duplicates for Web Crawling(Paper)
Detecting Near–Duplicates for Web Crawling(PPT)
来源:http://blog.csdn.net/lgnlgn/article/details/6008498
有1亿个不重复的64位的01字符串,任意给出一个64位的01字符串f,如何快速从中找出与f汉明距离小于3的字符串?
大规模网页的近似查重
主要翻译自WWW07的Detecting Near–Duplicates for Web Crawling
WWW上存在大量内容近似相同的网页,对搜索引擎而言,去除近似相同的网页可以提高检索效率、降低存储开销。
当爬虫在抓取网页时必须很快能在海量文本集中快速找出是否有重复的网页。
论文主要2个贡献:
1. 展示了simhash可以用以海量文本查重
2. 提出了一个在实际应用中可行的算法。
两篇文本相似度普遍的定义是比较向量化之后两个词袋中词的交集程度,有cosine,jaccard等等
如果直接使用这种计算方式,时间空间复杂度都太高,因此有了simhash这种降维技术,
但是如何从传统的向量相似度能用simhash来近似,论文没提,应该是有很长一段推导要走的。
Simhash算法
一篇文本提取出内容以后,经过基本的预处理,比如去除停词,词根还原,甚至chunking,最后可以得到一个向量。
对每一个term进行hash算法转换,得到长度f位的hash码,每一位上1-0值进行正负权值转换,例如f1位是1时,权值设为 +weight, fk位为0时,权值设为-weight。
讲文本中所有的term转换出的weight向量按f对应位累加最后得到一个f位的权值数组,位为正的置1,位为负的置0,那么文本就转变成一个f位的新1-0数组,也就是一个新的hash码。

Simhash具有两个“冲突的性质”:
1. 它是一个hash方法
2. 相似的文本具有相似的hash值,如果两个文本的simhash越接近,也就是汉明距离越小,文本就越相似。
因此海量文本中查重的任务转换位如何在海量simhash中快速确定是否存在汉明距离小的指纹。
也就是:在n个f-bit的指纹中,查询汉明距离小于k的指纹。
在文章的实验中(见最后),simhash采用64位的哈希函数。在80亿网页规模下汉明距离=3刚好合适。
因此任务的f-bit=64 , k=3 , n= 8*10^11
任务清晰,首先看一下两种很直观的方法:
1. 对输入指纹,枚举出所有汉明距离小于3的simhash指纹,对每个指纹在80亿排序指纹中查询。
(这种方法需要进行C(64,3)=41664次的simhash指纹,再为每个进行一次查询)
2. 输入指纹不变,对应集合相应位置变。也就是集合上任意3位组合的位置进行变化,实际上就是提前准备41664个排序可能,需要庞大的空间。输入在这群集合并行去搜….
提出的方法介于两者之间,合理的空间和时间的折中。
• 假设我们有一个已经排序的容量为2d,f-bit指纹集。看每个指纹的高d位。该高低位具有以下性质:尽管有很多的2d位组合存在,但高d位中有只有少量重复的。
• 现在找一个接近于d的数字d’,由于整个表是排好序的,所以一趟搜索就能找出高d’位与目标指纹F相同的指纹集合f’。因为d’和d很接近,所以找出的集合f’也不会很大。
• 最后在集合f’中查找和F之间海明距离为k的指纹也就很快了。
• 总的思想:先要把检索的集合缩小,然后在小集合中检索f-d’位的海明距离
要是一时半会看不懂,那就从新回顾一下那两种极端的办法:
方法2,前61位上精确匹配,后面就不需要比较了
方法1,前0位上精确匹配,那就要在后面,也就是所有,上比较
那么折中的想法是 前d- bits相同,留下3bit在(64-d)bit小范围搜索,可行否?
d-bits的表示范围有2^d,总量N个指纹,平均 每个表示后面只有N/(2^d)个快速定位到前缀是d的位置以后,直接比较N/(2^k)个指纹。
如此只能保证前d位精确的那部分N/(2^d)指纹没有遗漏汉明距离>3的因此要保证64bits上所有部分都安全,全部才没有遗漏。方法2其实就是把所有的d=61 部分(也就是64选61)都包含了。
按照例子,80亿网页有2^34个,那么理论上34位就能表示完80亿不重复的指纹。
我们假设最前的34位的表示完了80亿指纹,假设指纹在前30位是一样的,那么后面4位还可以表示24个,只需要逐一比较这16个指纹是否于待测指纹汉明距离小于3。
假设:对任意34位中的30位都可以这么做。
因此在一次完整的查找中,限定前q位精确匹配(假设这些指纹已经是q位有序的,可以采用二分查找,如果指纹量非常大,且分布均匀,甚至可以采用内插搜索),之后的2d-q个指纹剩下64-q位需要比较汉明距离小于3。
于是问题就转变为如何切割64位的q。
将64位平分成若干份,例如4份ABCD,每份16位。
假设这些指纹已经按A部分排序好了,我们先按A的16位精确匹配到一个区间,这个区间的后BCD位检查汉明距离是否小于3。
同样的假设,其次我们按B的16位精确匹配到另一个区间,这个区间的所有指纹需要在ACD位上比较汉明距离是否小于3。
同理还有C和D
所以这里我们需要将全部的指纹T复制4份,T1 T2 T3 T4, T1按A排序,T2按B排序… 4份可以并行进行查询,最后把结果合并。这样即使最坏的情况:3个位分别落在其中3个区域ABC,ACD,BCD,ABD…都不会被漏掉。
只精确匹配16位,还需要逐一比较的指纹量依然庞大,可能达到2d-16个,我们也可以精确匹配更多的。
例如:将64位平分成4份ABCD,每份16位,在BCD的48位上,我们再分成4份,WXZY,每份12位,汉明距离的3位可以散落在任意三块,那么A与WXZY任意一份合起来做精确的28位…剩下3份用来检查汉明距离。同理B,C,D也可以这样,那么T需要复制16次,ABCD与WXYZ的组合做精确匹配,每次精确匹配后还需要逐一比较的个数降低到2d-28个。不同的组合方式也就是时间和空间上的权衡。
最坏情况是其中3份可能有1位汉明距离差异为1。
算法的描述如下:
1)先复制原表T为Tt份:T1,T2,….Tt
2)每个Ti都关联一个pi和一个πi,其中pi是一个整数,πi是一个置换函数,负责把pi个bit位换到高位上。
3)应用置换函数πi到相应的Ti表上,然后对Ti进行排序
4)然后对每一个Ti和要匹配的指纹F、海明距离k做如下运算:
a) 然后使用F’的高pi位检索,找出Ti中高pi位相同的集合
b) 在检索出的集合中比较f-pi位,找出海明距离小于等于k的指纹
5)最后合并所有Ti中检索出的结果
由于文本已经压缩成8个字节了,因此其实Simhash近似查重精度并不高:
simhash算法原理及实现
simhash是google用来处理海量文本去重的算法。 google出品,你懂的。 simhash最牛逼的一点就是将一个文档,最后转换成一个64位的字节,暂且称之为特征字,然后判断重复只需要判断他们的特征字的距离是不是<n(根据经验这个n一般取值为3),就可以判断两个文档是否相似。
原理
simhash值的生成图解如下:

大概花三分钟看懂这个图就差不多怎么实现这个simhash算法了。特别简单。谷歌出品嘛,简单实用。
算法过程大概如下:
- 将Doc进行关键词抽取(其中包括分词和计算权重),抽取出n个(关键词,权重)对, 即图中的
(feature, weight)们。 记为feature_weight_pairs = [fw1, fw2 ... fwn],其中fwn = (feature_n, weight_n)。 hash_weight_pairs = [ (hash(feature), weight) for feature, weight in feature_weight_pairs ]生成图中的(hash,weight)们, 此时假设hash生成的位数bits_count = 6(如图);- 然后对
hash_weight_pairs进行位的纵向累加,如果该位是1,则+weight,如果是0,则-weight,最后生成bits_count个数字,如图所示是[13, 108, -22, -5, -32, 55], 这里产生的值和hash函数所用的算法相关。 [13,108,-22,-5,-32,55] -> 110001这个就很简单啦,正1负0。
到此,如何从一个doc到一个simhash值的过程已经讲明白了。 但是还有一个重要的部分没讲,
simhash值的海明距离计算
二进制串A 和 二进制串B 的海明距离 就是 A xor B 后二进制中1的个数。
举例如下:
A = 100111;
B = 101010;
hamming_distance(A, B) = count_1(A xor B) = count_1(001101) = 3;
当我们算出所有doc的simhash值之后,需要计算doc A和doc B之间是否相似的条件是:
A和B的海明距离是否小于等于n,这个n值根据经验一般取值为3,
simhash本质上是局部敏感性的hash,和md5之类的不一样。 正因为它的局部敏感性,所以我们可以使用海明距离来衡量simhash值的相似度。
高效计算二进制序列中1的个数
/* src/Simhasher.hpp */
bool isEqual(uint64_t lhs, uint64_t rhs, unsigned short n = 3)
{
unsigned short cnt = 0;
lhs ^= rhs;
while(lhs && cnt <= n)
{
lhs &= lhs - 1;
cnt++;
}
if(cnt <= n)
{
return true;
}
return false;
}
由上式这个函数来计算的话,时间复杂度是 O(n); 这里的n默认取值为3。由此可见还是蛮高效的。
simhash实现的工程项目
主要是针对中文文档,也就是此项目进行simhash之前同时还进行了分词和关键词的抽取。
对比其他算法
百度的去重算法
百度的去重算法最简单,就是直接找出此文章的最长的n句话,做一遍hash签名。n一般取3。 工程实现巨简单,据说准确率和召回率都能到达80%以上。
shingle算法
shingle原理略复杂,不细说。 shingle算法我认为过于学院派,对于工程实现不够友好,速度太慢,基本上无法处理海量数据。
其他算法
具体看微博上的讨论
参考
- Similarity estimation techniques from rounding algorithms
- simhash与Google的网页去重
- 海量数据相似度计算之simhash和海明距离
simhash算法实现
来源:http://blog.sina.com.cn/s/blog_81e6c30b0101cpvu.html
代码如下:
一、Python版


二、Java版:
结论:
python的计算能力确实很强,float可以表示任意长度的数字,而对应java、c++只能用其他办法来实现了,比如java的BigIneteger,对应的位操作也只能利用类方法。。。汗。。。
另外说明,位运算只适合整数哦。。。因为浮点的存储方案决定不能位运算,如果非要位运算,就需要Float.floatToIntBits,运算完,再通过Float.intBitsToFloat转化回去。(java默认的float,double的hashcode其实就是对应的floatToIntBits的int值)
java左移、右移: 移位运算符和气压的位运算符一样都是用来操作二进制位。
1)<< ,左移位:将操作符左侧的操作数向左移动操作数右侧指定的位数。移动的规则是在二进制的低位补0.
2)>> ,有符号右移位,将操作符左侧的操作数向右移动操作数右侧指定的位数。移动的规则是,如果被操作数的符号为正,则在二进制的高位补0;如果被操作数的符号为负,则在二进制的高位补1
3)>>> ,无符号右移位:将操作符左侧的操作数向右移动操作数右侧指定的位数。移动的对则是,无论被操作数的符号是正是负,都在二进制的高位补0.
中文文档simhash值计算:https://github.com/yanyiwu/simhash
参考文章:
http://www.cnblogs.com/linecong/archive/2010/08/28/simhash.html
http://blog.csdn.NET/liema2000/article/details/6149561
http://blog.csdn.Net/lgnlgn/article/details/6008498
http://www.cnpetweb.com/a/xinxizhongxin/lanmu9/2011/0913/13538.html
http://2588084.blog.51cto.com/2578084/558873
http://leoncom.org/?tag=simhash
来源:http://my.oschina.net/pathenon/blog/65210
1.概述
Jaccard index是用来计算相似性,也就是距离的一种度量标准。假如有集合A、B,那么,
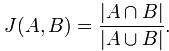
那么对集合A、B,hmin(A) = hmin(B)成立的条件是A ∪ B 中具有最小哈希值的元素也在 ∩ B中。这里
有一个假设,h(x)是一个良好的哈希函数,它具有很好的均匀性,能够把不同元素映射成不同的整数。
所以有,Pr[hmin(A) = hmin(B)] = J(A,B),即集合A和B的相似度为集合A、B经过hash后最小哈希值相
等的概率。
对,如果仅仅对两篇文档计算相似度而言,MinHash没有什么优势,反而把问题复杂化了。但是如果有海量的文档需要求相似度,比如在推荐系统
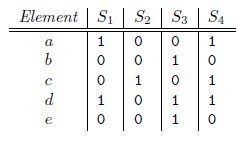
元素集合{a,b,c,d,e},其中s1={a,d},s2={c},s3={b,d,e},s4={a,c,d}
那么这四个集合的矩阵表示为:
beadc,那么对应的矩阵为
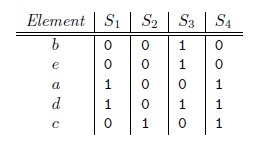
h(S1) = a,同样可以得到h(S2) = c, h(S3) = b, h(S4) = a。
来计算相似度。但是求排列本身的复杂度比较高,特别是针对很大的矩阵来说。因此,我们可以设计一个随机哈希函数去模拟排列,能够把行号0~n随机映射到0~n上。比如
H(0)=100,H(1)=3…。当然,冲突是不可避免的,冲突后可以二次散列。并且如果选取的随机哈希函数够均匀,并且当n较大时,冲突发生的概率还是比较低的。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/230851.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
