一、前言
结合目前已存在的商品推荐设计(如淘宝、京东等),推荐系统主要包含系统推荐和个性化推荐两个模块。
系统推荐: 根据大众行为的推荐引擎,对每个用户都给出同样的推荐,这些推荐可以是静态的由系统管理员人工设定的,或者基于系统所有用户的反馈统计计算出的当下比较流行的物品。
个性化推荐:对不同的用户,根据他们的口味和喜好给出更加精确的推荐,这时,系统需要了解需推荐内容和用户的特质,或者基于社会化网络,通过找到与当前用户相同喜好的用户,实现推荐。
下面具体介绍系统推荐和个性化推荐的设计方案。
二、系统推荐
2.1、系统推荐目的
针对所有用户推荐,当前比较流行的商品(必选) 或 促销实惠商品(可选) 或 新上市商品(可选),以促进商品的销售量。
PS:根据我们的应用情况考虑是否 选择推荐 促销实惠商品 和 新上市商品。(TODO1)
2.2、实现方式
实现方式包含:系统自动化推荐 和 人工设置推荐。
(1)系统自动化推荐考虑因素有:商品发布时间、商品分类、库存余量、历史被购买数量、历史被加入购物车数量、历史被浏览数量、降价幅度等。根据我们当前可用数据,再进一步确定(TODO2)
(2)人工设置:提供运营页面供运营人员设置,设置包含排行位置、开始时间和结束时间、推荐介绍等等。
由于系统推荐实现相对简单,因此不作过多的文字说明,下面详细介绍个性化推荐的设计。
三、个性化推荐
3.1、个性化推荐目的
对不同的用户,根据他们的口味和喜好给出更加精确的推荐,系统需要了解需推荐内容和用户的特质,或者基于社会化网络,通过找到与当前用户相同喜好的用户,实现推荐,以促进商品的销售量。
3.2、三种推荐模式的介绍
据推荐引擎的数据源有三种模式:基于人口统计学的推荐、基于内容的推荐、基于协同过滤的推荐。
(1)基于人口统计学的推荐:针对用户的“性别、年龄范围、收入情况、学历、专业、职业”进行推荐。
(2)基于内容的推荐:如下图,这里没有考虑人对物品的态度,仅仅是因为电影A月电影C相似,因此将电影C推荐给用户A。这是与后面讲到的协同过滤推荐最大的不同。

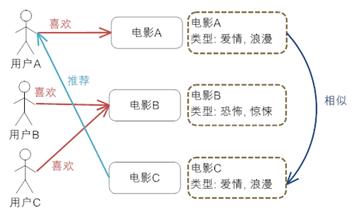
(3)基于协同过滤的推荐:如下图,这里我们并不知道物品A和物品D是否相似,仅仅考虑人对物品的喜好进行推荐。

模式采用:这三种模式可以单独使用,也可结合使用。结合我们实际情况,采用基于协同过滤的推荐更加合适,看后期情况是否结合另外两种模式实现推荐。但基于协同过滤的推荐这种模式,会引发“冷启动”问题。关于,冷启动问题,后续会讨论解决方案。
3.3、用户喜好设计
(1)判断用户喜好因素:历史购买、历史购物车、历史搜索、历史浏览等,待确定我们可用数据再进一步细化。
(2)用户对某个商品的喜好程度,通过不同行为对应不同分值权重,如:历史购买(10)、历史购物车(8)、历史搜索(5)、历史浏览(6),确定用户喜好因素后再进一步对各个因素评分权重进行 合理的设计。
(3)用户对商品的喜好程度最终体现:结合某个商品的不同行为 统计出 最终对该商品的喜好程度,即对商品的喜好程度,最终以一个数字体现。
3.4、Mahout介绍
目前选择采用协同过滤框架Mahout进行实现。
Mahout 是一个很强大的数据挖掘工具,是一个分布式机器学习算法的集合,包括:被称为Taste的分布式协同过滤的实现、分类、聚类等。Mahout最大的优点就是基于hadoop实现,把很多以前运行于单机上的算法,转化为了MapReduce模式,这样大大提升了算法可处理的数据量和处理性能。
Mahout 是一个布式机器学习算法的集合,但是这里我们只使用到它的推荐/协同过滤算法。
3.5、Mahout实现协同过滤实例
协同过滤在mahout里是由一个叫taste的引擎提供的, 它提供两种模式,一种是以jar包形式嵌入到程序里在进程内运行,另外一种是MapReduce Job形式在hadoop上运行。这两种方式使用的算法是一样的,配置也类似。
这里我们采用第一种引入jar包的单机模式。
3.5.1、依赖
<dependency>
<groupId>org.apache.mahout</groupId>
<artifactId>mahout-core</artifactId>
<version>0.9</version>
</dependency>
<dependency>
<groupId>org.apache.mahout</groupId>
<artifactId>mahout-math</artifactId>
<version>0.9</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.2.1</version>
</dependency>3.5.2、实现代码
public static void main(String[] args) {
try {
// 从文件加载数据
DataModel model = new FileDataModel(new File("D:\\mahout\\data.csv"));
// 指定用户相似度计算方法,这里采用皮尔森相关度
UserSimilarity similarity = new PearsonCorrelationSimilarity(model);
// 指定用户邻居数量,这里为2
UserNeighborhood neighborhood = new NearestNUserNeighborhood(2,
similarity, model);
// 构建基于用户的推荐系统
Recommender recommender = new GenericUserBasedRecommender(model,
neighborhood, similarity);
// 得到指定用户的推荐结果,这里是得到用户1的两个推荐
List<RecommendedItem> recommendations = recommender.recommend(1, 2);
// 打印推荐结果
for (RecommendedItem recommendation : recommendations) {
System.out.println(recommendation);
}
} catch (Exception e) {
System.out.println(e);
}
}3.5.3、data.csv内容(用户id、商品id,评分)
1,101,5
1,102,3
1,103,2.5
2,101,2
2,102,2.5
2,103,5
2,104,2
3,101,2.5
3,104,4
3,105,4.5
3,107,5
4,101,5
4,103,3
4,104,4.5
4,106,4
5,101,4
5,102,3
5,103,2
5,104,4
5,105,3.5
5,106,43.5.4、运行结果
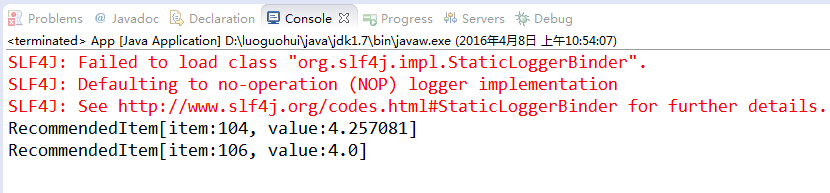
3.6、Mahout协同过滤算法选用
3.6.1、Mahout协同过滤自带算法介绍
Mahout算法框架自带的推荐器有下面这些:
GenericUserBasedRecommender:基于用户的推荐器,用户数量少时速度快;
GenericItemBasedRecommender:基于商品推荐器,商品数量少时速度快,尤其当外部提供了商品相似度数据后效率更好;
SlopeOneRecommender:基于slope-one算法的推荐器,在线推荐或更新较快,需要事先大量预处理运算,物品数量少时较好;
SVDRecommender:奇异值分解,推荐效果较好,但之前需要大量预处理运算;
KnnRecommender:基于k近邻算法(KNN),适合于物品数量较小时;
TreeClusteringRecommender:基于聚类的推荐器,在线推荐较快,之前需要大量预处理运算,用户数量较少时效果好;
Mahout最常用的三个推荐器是上述的前三个,本文主要讨论前两种的使用。
3.6.2、考虑使用算法
(1)GenericUserBasedRecommender(推荐)
一个很简单的user-based模式的推荐器实现类,根据传入的DataModel和UserNeighborhood进行推荐。其推荐流程分成三步:
第一步,使用UserNeighborhood获取跟指定用户Ui最相似的K个用户{U1…Uk};
第二步,{U1…Uk}喜欢的item集合中排除掉Ui喜欢的item, 得到一个item集合 {Item0…Itemm}
第三步,对{Item0…Itemm}每个itemj计算 Ui可能喜欢的程度值perf(Ui , Itemj) ,并把item按这个数值从高到低排序,把前N个item推荐给Ui。其中perf(Ui , Itemj)的计算公式如下:
其中 是用户Ul对Itemj的喜好值。
(2)GenericItemBasedRecommender
一个简单的item-based的推荐器,根据传入的DateModel和ItemSimilarity去推荐。基于Item的相似度计算比基于User的相似度计算有个好处是,item数量较少,计算量也就少了,另外item之间的相似度比较固定,所以相似度可以事先算好,这样可以大幅提高推荐的速度。
其推荐流程可以分成三步:
第一步,获取用户Ui喜好的item集合{It1…Itm}
第二步,使用MostSimilarItemsCandidateItemsStrategy(有多种策略, 功能类似UserNeighborhood) 获取跟用户喜好集合里每个item最相似的其他Item构成集合 {Item1…Itemk};
第三步,对{Item1…Itemk}里的每个itemj计算 Ui可能喜欢的程度值perf(Ui , Itemj) ,并把item按这个数值从高到低排序,把前N个Item推荐给Ui。其中perf(Ui , Itemj)的计算公式如下:
其中 是用户Ul对Iteml的喜好值。
(3)SlopeOneRecommender
基于Slopeone算法的推荐器,Slopeone算法适用于用户对item的打分是具体数值的情况。Slopeone算法不同于前面提到的基于相似度的算法,他计算简单快速,对新用户推荐效果不错,数据更新和扩展性都很不错,预测能达到和基于相似度的算法差不多的效果,很适合在实际项目中使用。
综合考虑,我们使用GenericUserBasedRecommender(基于用户的推荐器)比较合适。3.5、Mahout实现协同过滤实例 就是采用这种算法实现的。
3.7、Mahout数据源获取方式
DataModel 是用户喜好信息的抽象接口,它的具体实现支持从任意类型的数据源抽取用户喜好信息。Taste 默认提供 JDBCDataModel 和 FileDataModel,分别支持从数据库和文件中读取用户的喜好信息。
目前,Mahout为DataModel提供了以下几种实现:
org.apache.mahout.cf.taste.impl.model.GenericDataModel
org.apache.mahout.cf.taste.impl.model.GenericBooleanPrefDataModel
org.apache.mahout.cf.taste.impl.model.PlusAnonymousUserDataModel
org.apache.mahout.cf.taste.impl.model.file.FileDataModel
org.apache.mahout.cf.taste.impl.model.hbase.HBaseDataModel
org.apache.mahout.cf.taste.impl.model.cassandra.CassandraDataModel
org.apache.mahout.cf.taste.impl.model.mongodb.MongoDBDataModel
org.apache.mahout.cf.taste.impl.model.jdbc.SQL92JDBCDataModel
org.apache.mahout.cf.taste.impl.model.jdbc.MySQLJDBCDataModel
org.apache.mahout.cf.taste.impl.model.jdbc.PostgreSQLJDBCDataModel
org.apache.mahout.cf.taste.impl.model.jdbc.GenericJDBCDataModel
org.apache.mahout.cf.taste.impl.model.jdbc.SQL92BooleanPrefJDBCDataModel
org.apache.mahout.cf.taste.impl.model.jdbc.MySQLBooleanPrefJDBCDataModel
org.apache.mahout.cf.taste.impl.model.jdbc.PostgreBooleanPrefSQLJDBCDataModel
org.apache.mahout.cf.taste.impl.model.jdbc.ReloadFromJDBCDataModel
从类名上就可以大概猜出来每个DataModel的用途,但是竟然没有HDFS的DataModel,有人实现了一个,请参考MAHOUT-1579(https://issues.apache.org/jira/browse/MAHOUT-1579)。
3.8、协同过滤实现采用技术
采用如下技术:Mahout(推荐算法) + Spark(并行计算) + Hadoop + Elasticsearch
Mahout 是一个很强大的数据挖掘工具,是一个分布式机器学习算法的集合,包括:被称为Taste的分布式协同过滤的实现、分类、聚类等。Mahout最大的优点就是基于hadoop实现,把很多以前运行于单机上的算法,转化为了MapReduce模式,这样大大提升了算法可处理的数据量和处理性能。
Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于map reduce算法实现的分布式计算,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的map reduce的算法。
但Spark没有提供文件管理系统,所以,它必须和其他的分布式文件系统进行集成才能运作。这里我们可以选择Hadoop的HDFS,也可以选择其他的基于云的数据系统平台。但Spark默认来说还是被用在Hadoop上面的,毕竟,大家都认为它们的结合是最好的。
PS:Mahout(推荐算法) + Spark(并行计算) + Hadoop + Elasticsearch搭配的实现方式并没有尝试,网上有一些解决方案,但是并不详细,而且英文居多,因此需要进一步学习研究。
可参考文献:https://mahout.apache.org/users/algorithms/intro-cooccurrence-spark.html
3.9、冷启动问题
所谓冷启动,是指对于很多推荐引擎的开始阶段,当一个新用户进入推荐系统或者系统添加一个新的物品后,由于还没有大量的用户数据,系统无法计算出推荐模型,从而导致系统的推荐功能失效的问题。
可考虑的解决方案有:
(1)利用用户注册信息进行初步推荐,主要包括人口统计学信息、用户描述的个人兴趣内容,预先设定好用户的偏好信息。
(2)在用户第一次访问系统时,给用户提供一些物品,让用户反馈对这些物品的评分,然后根据用户的反馈形成初始的个性化推荐。
(3)邀请行业的专家对新的用户或者新的物品
进行分类、评注。
(4)随机推荐的方法。对于冷启动问题,实际应用中最简单最直观的方法是采用随机推荐的 方式。这种方法是比较冒险。
(5)平均值法。所有项目的均值,作为用户对未评价过项目的预测值,将原始评分矩阵进行 填充,然后在填充后的评分矩阵上寻找目标用户的最近邻居,应用协同过滤的方法产生推荐。但是均值的方法只能说是一种被动应付的方式,新用户对项目的喜好值正好等于其他用户对此项目的平均值的概率是非常小的。
根据我们实际情况,建议使用第(1)种解决方案比较合适。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/2277.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
