大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
每每以为攀得众山小,可、每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~

———————————————————————————
线性混合模型与普通的线性模型不同的地方是除了有固定效应外还有随机效应。
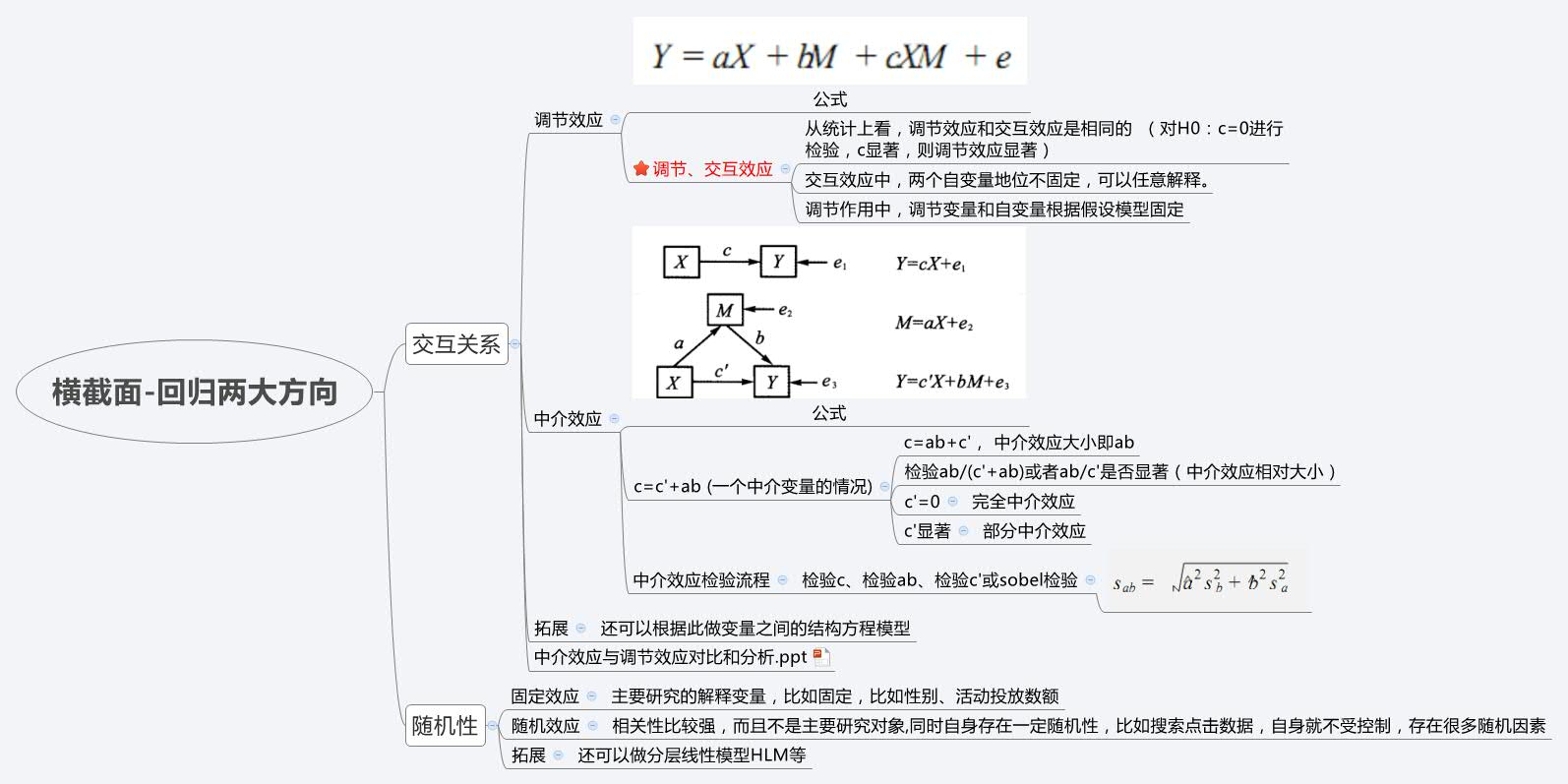
笔者认为一般统计模型中的横截面回归模型中大致可以分为两个方向:一个是交互效应方向(调节、中介效应)、一个是随机性方向(固定效应、随机效应)。
两个方向的选择需要根据业务需求:
交互效应较多探究的是变量之间的网络关系,可能会有很多变量,多变量之间的关系;
而随机性探究的是变量自身的关联,当需要着重顾及某变量存在太大的随机因素时(这样的变量就想是在寻在内生变量一样,比如点击量、不同人所在地区等)才会使用。具体见:
笔记︱横截面回归模型中的两大方向(交互效应+随机性)
___________________________________________________________________________________
一、线性混合模型理论
普通的线性回归只包含两项影响因素,即固定效应(fixed-effect)和噪声(noise)。噪声是我们模型中没有考虑的随机因素。而固定效应是那些可预测因素,而且能完整的划分总体。例如模型中的性别变量,我们清楚只有两种性别,而且理解这种变量的变化对结果的影响。
a0: 固定截距
a1: 固定斜率
b: 随机效应(只影响截距)
X: 固定效应
e: 噪声
混合线性模型有时又称为多水平线性模型或层次结构线性模型由两个部分来决定,固定效应部分+随机效应部分.
(以上内容来源于数据挖掘入门与实战公众号)
1、模型简述
混合线性模型有时又称为多水平线性模型或层次结构线性模型由两个部分来决定,固定效应部分+随机效应部分。
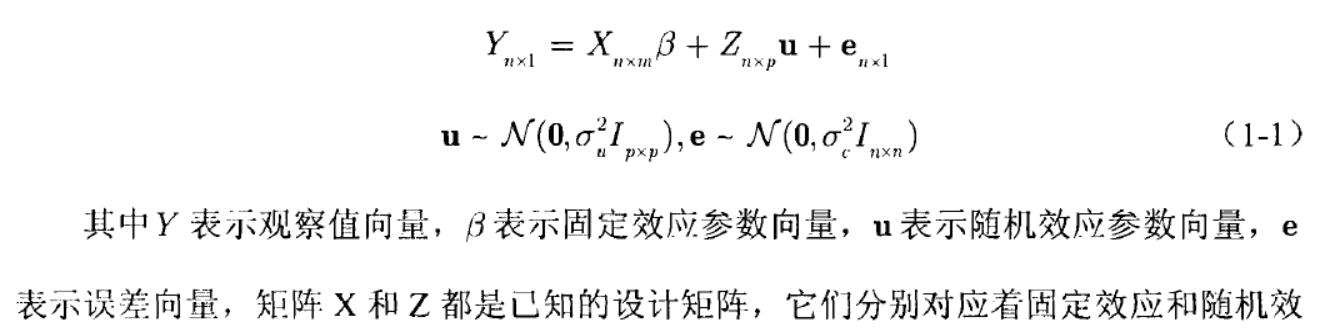
2、协方差结构
来源于论文混合线性模型的应用(该论文涉及到两个案例),为了减少混合线性模型中方差协方差矩阵中参数的个数,统计学家提供了一些方差协方差矩阵(Y)的系统结构模式供实际工作应用。
常见的协方差结构有:

3、与普通线性回归模型以及广义线性模型的区别(参考经管之家论坛帖子)
(1)线性回归模型,适用于自变量X和因变量Y为线性关系,具体来说,画出散点图可以用一条直线来近似拟合。一般线性模型要求观测值之间相互独立、残差(因变量)服从正态分布、残差(因变量)方差齐性
(2)线性混合模型,在线性模型中加入随机效应项,消了观测值之间相互独立和残差(因变量)方差齐性的要求。
(3)广义线性模型,是为了克服线性回归模型的缺点出现的,是线性回归模型的推广。首先自变量可以是离散的,也可以是连续的。离散的可以是0-1变量,也可以是多种取值的变量。广义线性模型又取消了对残差(因变量)服从正态分布的要求。残差不一定要服从正态分布,可以服从二项、泊松、负二项、正态、伽马、逆高斯等分布,这些分布被统称为指数分布族。
关于分布:因变量的分布有放宽,但是自变量没有分布的要求
与线性回归模型相比较,有以下推广:
a、随机误差项不一定服从正态分布,可以服从二项、泊松、负二项、正态、伽马、逆高斯等分布,这些分布被统称为指数分布族。
b、引入联接函数$g(\cdot )$。因变量和自变量通过联接函数产生影响。根据不同的数据,可以自由选择不同的模型。大家比较熟悉的Logit模型就是使用Logit联接、随机误差项服从二项分布得到模型。
(4)与分层线性模型(HLM)的区别。
介于线性模型与分层线性模型之间,线性混合模型平行地以加入解释变量的形式加入了随机效应,分层线性模型是以系数项为二层回归引入了随机效应。分层线性模型较之线性混合模型更具随机性。
___________________________________________________________________________________
二、R语言中的线性混合模型
来自博客R中的线性混合模型介绍(翻译博客)(来自科学网邓飞博客)原来来自:http://www.r-bloggers.com/linear-mixed-models-in-r/
1、nlme lme4 Asreml包
R中有很多软件包可以做混合线性模型,这里我只介绍nlme、lme4和ASreml(对!ASreml是商业版,但是还有对应的R包),这些都是基于Reml的算法,当然还有一些包是基于贝叶斯的算法,这部分在其他章节介绍。
几个包的介绍:
|
包 |
优点 |
缺点 |
|
nlme |
这是一个比较成熟的R包,是R语言安装时默认的包,它除了可以分析分层的线性混合模型,也可以处理非线性模型。在优势方面,个人认为它可以处理相对复杂的线性和非线性模型,可以定义方差协方差结构,可以在广义线性模型中定义几种分布函数和连接函数。 |
它的短板: |
|
lme4 |
lme4包是由Douglas Bates开发,他也是nlme包的作者之一,相对于nlme包而言,它的运行速度快一点,对于睡觉效应·随机效应的结构也可以更复杂一点,但是它的缺点也和nlme一样 |
1、不能处理协方差和相关系数结构 |
|
ASReml-R |
ASReml-R是ASReml的R版本,它的优点: |
主要的缺点: |
2、R语言案例
数据来源:一个传统的裂区数据来说明不同软件包的用法,这个数据oats是在MASS包中,是研究大麦品种和N肥处理的裂区试验,其中品种为主区,肥料为裂区。
library(MASS)
data(oats)
names(oats) = c('block', 'variety', 'nitrogen', 'yield')3、nlme包
用这个包很简单,y-变量写在左边,然后是固定因子,然后是随机因子,注意1|block/mainplot是裂区试验残差的写法,因为里面有两个残差。代码如下:
library(nlme)
m1.nlme = lme(yield ~ variety*nitrogen,
random = ~ 1|block/mainplot,
data = oats)
summary(m1.nlme)
方差分析结果为:
anova(m1.nlme)
numDF denDF F-value p-value
(Intercept) 1 45 245.14333 <.0001
variety 2 10 1.48534 0.2724
nitrogen 3 45 37.68561 <.0001
variety:nitrogen 6 45 0.30282 0.9322如果假设认为这些调查对象是同质的,也就是个体间没有差异性,那么可以将数据完全汇集(complete pooling)到一起,直接利用lm函数进行回归。但这个混合效应模型的同质假设往往不成立,数据汇集导致过度简化。另一种思路是假设研究的异质性,将不同的个体分别进行回归,从而得到针对特定个体的估计值,这称为不汇集(no pooling)。但这种方法导致每个回归所用到的样本减少,从而难以估计统计量的标准差。
4、lme4包
lme4包的语法也相似,随机效应有着和nlme相同的语法,不同的是lme4包它的结果给出了随机效应的标准差,而不是方差。
library(lme4)
m1.lme4 = lmer(yield ~ variety*nitrogen + (1|block/mainplot),
data = oats)
summary(m1.lme4)
anova(m1.lme4)
lmer函数使用和lm是类似的,一般变量表示固定效应,括号内竖线右侧的person表示它是一个随机效应,它与模型中其它变量相加,而且与年份cyear变量相乘,影响其斜率。这就是一个随机效应模型。如果认为随机效应只影响模型截距,那么固定效应回归模型可以用下面的公式
5、ASReml-R包
代码如下:
library(asreml)
m1.asreml = asreml(yield ~ variety*nitrogen,
random = ~ block/mainplot,
data = oats)
summary(m1.asreml)$varcomp
wald(m1.asreml)___________________________________________________________________________________
三、线性混合模型解读
1、难点
建模前提:数据服从正态分布的假设;
固定、随机效应变量选择:哪些变量归类到随机效应(相关性比较强,而且不是主要研究对象,同时自身存在一定随机性,比如搜索点击数据,自身就不受控制,存在很多随机因素);固定效应(主要研究的解释变量)。
协方差结构的选择:可以利用AIC、BIC指标来判断,常见的有8个协方差结构。
2、案例一:论文《混合线性模型的应用》的案例解读
模型为:成绩(被解释变量)=性别(固定效应)+地区(随机效应)
协方差结构的选择:将随机参数向量的方差协方差矩阵设置为无结构型。
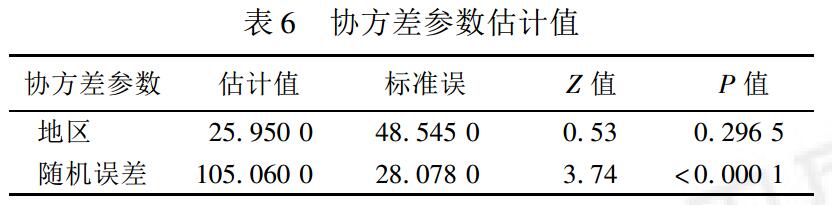
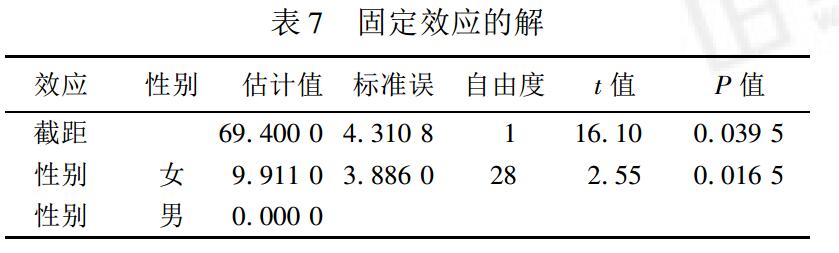
剩余误差ε的方差估计值为105.06,地区随机效应的方差估计值g=25.95,但无统计学意义,表示地区间的变异不大( 由于样本含量较小之故)。比较这 2 个值的大小反映考试成绩在同一地区内学生间的变异大于地区间的变异。为了更好地解释模型,仍将地区随机效应保留在模型中。
地区学生考试成绩的聚集性达到近,20%。
固定效应变量性别对学生考试影响的参数估计值为9.911,具有统计学意义。男生的平均成绩预报值为69.4分,女生的平均成绩预报值为69.4+9.91=79.31分。这一预报值是控制地区变异后的结果,不同于模型中的条件平均预报值。
3、案例二:分析不同手术方案病人的前蛋白含量在手术前后变化情况(论文《混合线性模型的应用》的案例解读)
协方差结构的选择:在分析协变量的效应前,先要选择一个合适的方差协方差矩阵。 在配合的8种协方差结构中, 综合考虑协方差参数个数及信息量指标值,特别是BIC以具有2个参数AR(1)的 ,AR(1)效果最好。 故选用AR(1)作为本例的方差协方差结构。
每每以为攀得众山小,可、每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~
———————————————————————————
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/224131.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...