大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
文章目录
总结:NDT是一种概率模型的点云配准方法。相对于icp而言:具有收敛域广,对初值不敏感。速度快等优点。但是精度没有icp高。
NDT预备知识
正态分布
n维正态随机过程中,其概率密度函数为:
p ( x ⃗ ) = 1 ( 2 π ) D / 2 ∣ Σ ∣ exp ( − ( x ⃗ − μ ⃗ ) T Σ − 1 ( x ⃗ − μ ⃗ ) 2 ) (1) p(\vec{x})=\frac{1}{(2 \pi)^{D / 2} \sqrt{|\boldsymbol{\Sigma}|}} \exp \left(-\frac{(\vec{x}-\vec{\mu})^{\mathrm{T}} \boldsymbol{\Sigma}^{-1}(\vec{x}-\vec{\mu})}{2}\right)\tag{1} p(x)=(2π)D/2∣Σ∣1exp(−2(x−μ)TΣ−1(x−μ))(1)
其中 μ ⃗ , Σ \vec{\mu},\Sigma μ,Σ表示平均值,和协方差矩阵,其计算如下:
μ ⃗ = 1 m ∑ k = 1 m y ⃗ k (2) \vec{\mu}=\frac{1}{m} \sum_{k=1}^{m} \vec{y}_{k}\tag{2} μ=m1k=1∑myk(2)
Σ = 1 m − 1 ∑ k = 1 m ( y ⃗ k − μ ⃗ ) ( y ⃗ k − μ ⃗ ) T (3) \Sigma =\frac{1}{m-1} \sum_{k=1}^{m}\left(\vec{y}_{k}-\vec{\mu}\right)\left(\vec{y}_{k}-\vec{\mu}\right)^{\mathrm{T}}\tag{3} Σ=m−11k=1∑m(yk−μ)(yk−μ)T(3)
高斯牛顿法求解非线性最小二乘
后续专门写一篇博客
NDT原理
(1)目标函数
NDT全称: normal distributions transform,即正常分布变换,可以描述为一种紧密(简洁)表示表面的方法。
该变换将点云映射到平滑曲面表示,描述为一组局部概率密度函数(PDF),其中每个函数描述部分曲面的形状。即利用局部概率密度函数表示局部点云。
当使用NDT进行扫描配准时,通过最大化当前待配准点位于参考(基准)扫描表面的可能性,从而找到当前待配准点云的姿态。即最大化下面似然函数:
Ψ = ∏ k = 1 n p ( T ( p ⃗ , x ⃗ k ) ) (4) \Psi=\prod_{k=1}^{n} p\left(T\left(\vec{p}, \vec{x}_{k}\right)\right)\tag{4} Ψ=k=1∏np(T(p,xk))(4)
p ⃗ , x ⃗ k , p ( x ⃗ ) \vec{p},\vec{x}_{k},p(\vec{x}) p,xk,p(x)分别是:姿态对应的变换矩阵,待配准点云,待配准点云对应基准点云的概率密度函数。PDF概率密度函数不一定非得的正态分布,能够描述局部表面,并且对异常值具有稳健性的概率密度函数都是可以的。
最大化公式(4)等价于最小化公式(5):
− log Ψ = − ∑ k = 1 n log ( p ( T ( p ⃗ , x ⃗ k ) ) ) (5) -\log \Psi=-\sum_{k=1}^{n} \log \left(p\left(T\left(\vec{p}, \vec{x}_{k}\right)\right)\right)\tag{5} −logΨ=−k=1∑nlog(p(T(p,xk)))(5)
(2)简化目标函数
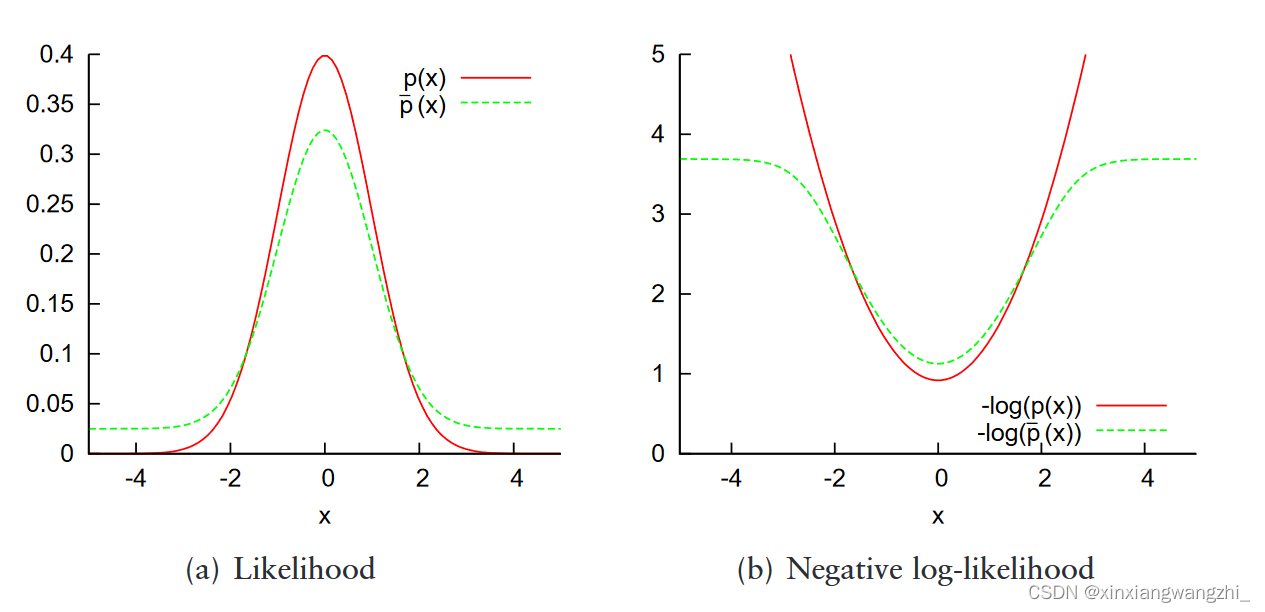

左侧(a)为正态分布(红色)与混合分布 p ˉ ( x ⃗ ) \bar{p}(\vec{x}) pˉ(x)(正态、均匀分布,绿色)的图像,右侧(b)为两者相应的-log对数。由(b)中可知,原始的正态分布相对于x没有约束,在x的值变大时函数值也会受到很大影响,而混合模型则会对x的值进行约束,具有更好的鲁棒性。(受噪声点的影响更小)
观察上图(b)的红色曲线 − l o g ( p ( x ) ) -log(p(x)) −log(p(x)),发现其极值为正无穷。为了避免极端x值导致y值无穷大或者无穷小,以及避免异常值的影响,将正态概率密度函数公式(1)更改为正态分布和均匀分布的混合分布公式(6):
p ˉ ( x ⃗ ) = c 1 exp ( − ( x ⃗ − μ ⃗ ) T Σ − 1 ( x ⃗ − μ ⃗ ) 2 ) + c 2 p o (6) \bar{p}(\vec{x})=c_{1} \exp \left(-\frac{(\vec{x}-\vec{\mu})^{\mathrm{T}} \Sigma^{-1}(\vec{x}-\vec{\mu})}{2}\right)+c_{2} p_{o}\tag{6} pˉ(x)=c1exp(−2(x−μ)TΣ−1(x−μ))+c2po(6)
p o p_{o} po为异常值比例,常数c1和c2可以通过要概率密度函数积分等于1来确定。
将概率密度函数公式(1)近似为公式(6)之后,即目标函数 − log ( p ˉ ( x ⃗ ) ) -\log({\bar{p}(\vec{x})}) −log(pˉ(x))的一阶二阶导数是复杂的,因此,再将公式(6)转换为高斯形式进行近似:
p ~ ( x ⃗ k ) = − d 1 exp ( − d 2 2 ( x ⃗ k − μ ⃗ k ) T Σ k − 1 ( x ⃗ k − μ ⃗ k ) ) (7) \tilde{p}\left(\vec{x}_{k}\right)=-d_{1} \exp \left(-\frac{d_{2}}{2}\left(\vec{x}_{k}-\vec{\mu}_{k}\right)^{\mathrm{T}} \boldsymbol{\Sigma}_{k}^{-1}\left(\vec{x}_{k}-\vec{\mu}_{k}\right)\right)\tag{7} p~(xk)=−d1exp(−2d2(xk−μk)TΣk−1(xk−μk))(7)
其中:
d 3 = − log ( c 2 ) d 1 = − log ( c 1 + c 2 ) − d 3 d 2 = − 2 log ( ( − log ( c 1 exp ( − 1 / 2 ) + c 2 ) − d 3 ) / d 1 ) (8) \begin{aligned} &d_{3}=-\log \left(c_{2}\right) \\ &d_{1}=-\log \left(c_{1}+c_{2}\right)-d_{3} \\ &d_{2}=-2 \log \left(\left(-\log \left(c_{1} \exp (-1 / 2)+c_{2}\right)-d_{3}\right) / d_{1}\right)\tag{8} \end{aligned} d3=−log(c2)d1=−log(c1+c2)−d3d2=−2log((−log(c1exp(−1/2)+c2)−d3)/d1)(8)
公式(7)省略了d3,因为它是常数偏移,不会更改其概率密度函数形状或优化的参数。
综上,给定一系列点云 X = { x ⃗ 1 , … , x ⃗ n } \mathcal{X}=\left\{\vec{x}_{1}, \ldots, \vec{x}_{n}\right\} X={
x1,…,xn}, 姿态 p ⃗ \vec{p} p, 变换矩阵 T ( p ⃗ , x ⃗ ) T(\vec{p}, \vec{x}) T(p,x), the NDT score function s ( p ⃗ ) s(\vec{p}) s(p) 可以表示为:
s ( p ⃗ ) = − ∑ k = 1 n p ~ ( T ( p ⃗ , x ⃗ k ) ) (9) s(\vec{p})=-\sum_{k=1}^{n} \tilde{p}\left(T\left(\vec{p}, \vec{x}_{k}\right)\right) \tag{9} s(p)=−k=1∑np~(T(p,xk))(9)
score function定义为log likelihood的一阶求导见知乎。即公式9是公式5的一阶导数。
(3)数值求解
概率密度函数要求协方差的逆,由于对于线状、平面点云而言,协方差是奇异的,并且不可逆。另外在3D空间中,当点云数量小于3,矩阵同样是奇异的,协方差阵不可逆。因此假设最大特征值,次大特征值,最小特征值分别为: λ 3 λ 2 λ 1 \lambda_{3}\lambda_{2}\lambda_{1} λ3λ2λ1,当 λ 3 \lambda_{3} λ3大于100倍的 λ 2 或 者 λ 1 \lambda_{2}或者\lambda_{1} λ2或者λ1时,令 λ 1 , 2 ′ = λ 3 / 100 \lambda_{1,2}^{\prime}=\lambda_{3} / 100 λ1,2′=λ3/100。新的协方差阵 Σ ′ = V Λ ′ V \boldsymbol{\Sigma}^{\prime}=\mathbf{V} \Lambda^{\prime} \mathbf{V} Σ′=VΛ′V 替代原始协方差阵 Σ \boldsymbol{\Sigma} Σ, V \mathbf{V} V 是特征向量对应的矩阵 Σ \boldsymbol{\Sigma} Σ :
Λ ′ = [ λ 1 ′ 0 0 0 λ 2 ′ 0 0 0 λ 3 ] (11) \Lambda^{\prime}=\left[\begin{array}{ccc} \lambda_{1}^{\prime} & 0 & 0 \\ 0 & \lambda_{2}^{\prime} & 0 \\ 0 & 0 & \lambda_{3} \end{array}\right]\tag{11} Λ′=⎣⎡λ1′000λ2′000λ3⎦⎤(11)
利用牛顿法,通过优化 s ( p ⃗ ) s(\vec{p}) s(p),可以找到 姿态参数 p ⃗ \vec{p} p 。
Newton’s method iteratively solves the equation H Δ p ⃗ = − g ⃗ \mathrm{H} \Delta \vec{p}=-\vec{g} HΔp=−g, where H \mathrm{H} H and g ⃗ \vec{g} gare the Hessian matrix and gradient vector of s ( p ⃗ ) s(\vec{p}) s(p)。梯度可以表示为:
g i = δ s δ p i = ∑ k = 1 n d 1 d 2 x ⃗ k ′ T Σ k − 1 δ x ⃗ k ′ δ p i exp ( − d 2 2 x ⃗ k ′ T Σ k − 1 x ⃗ k ′ ) (11) g_{i}=\frac{\delta s}{\delta p_{i}}=\sum_{k=1}^{n} d_{1} d_{2} \vec{x}_{k}^{\prime \mathrm{T}} \Sigma_{k}^{-1} \frac{\delta \vec{x}_{k}^{\prime}}{\delta p_{i}} \exp \left(\frac{-d_{2}}{2} \vec{x}_{k}^{\prime \mathrm{T}} \Sigma_{k}^{-1} \vec{x}_{k}^{\prime}\right)\tag{11} gi=δpiδs=k=1∑nd1d2xk′TΣk−1δpiδxk′exp(2−d2xk′TΣk−1xk′)(11)
黑森矩阵为:
H i j = δ 2 s δ p i δ p j = ∑ k = 1 n d 1 d 2 exp ( − d 2 2 x ⃗ k ′ T Σ k − 1 x ⃗ k ′ ) ( − d 2 ( x ⃗ k ′ T Σ k − 1 δ x ⃗ k ′ δ p i ) ( x ⃗ k ′ T Σ k − 1 δ x ⃗ k ′ δ p j ) + x ⃗ k T Σ k − 1 δ 2 x ⃗ k ′ δ p i δ p j + δ x ⃗ k ′ δ p j Σ k − 1 δ x ⃗ k ′ δ p i ) (12) H_{i j}=\frac{\delta^{2} s}{\delta p_{i} \delta p_{j}}= \sum_{k=1}^{n} d_{1} d_{2} \exp \left(\frac{-d_{2}}{2} \vec{x}_{k}^{\prime}{ }^{\mathrm{T}} \boldsymbol{\Sigma}_{k}^{-1} \vec{x}_{k}^{\prime}\right)\left(-d_{2}\left(\vec{x}_{k}^{\prime}{ }^{\mathrm{T}} \boldsymbol{\Sigma}_{k}^{-1} \frac{\delta \vec{x}_{k}^{\prime}}{\delta p_{i}}\right)\left(\vec{x}_{k}^{\prime}{ }^{\mathrm{T}} \boldsymbol{\Sigma}_{k}^{-1} \frac{\delta \vec{x}_{k}^{\prime}}{\delta p_{j}}\right)+\\ \vec{x}_{k}^{\mathrm{T}} \boldsymbol{\Sigma}_{k}^{-1} \frac{\delta^{2} \vec{x}_{k}^{\prime}}{\delta p_{i} \delta p_{j}}+\frac{\delta \vec{x}_{k}^{\prime}}{\delta p_{j}} \boldsymbol{\Sigma}_{k}^{-1} \frac{\delta \vec{x}_{k}^{\prime}}{\delta p_{i}}\right)\tag{12} Hij=δpiδpjδ2s=k=1∑nd1d2exp(2−d2xk′TΣk−1xk′)(−d2(xk′TΣk−1δpiδxk′)(xk′TΣk−1δpjδxk′)+xkTΣk−1δpiδpjδ2xk′+δpjδxk′Σk−1δpiδxk′)(12)
2D,3D NDT的梯度和Heissian矩阵形式是相同的,差别在于转换矩阵T(公式详见原文,这里不贴公式了)。2D 3D NDT之间的差别主要在于变换矩阵不同,以及变换矩阵一阶二阶矩阵不同.
(4)算法流程:
其算法流程如下:(注意Register scan :待配准点云(source), reference scan:基准点云(target))
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-51cSItJc-1653804976551)(./%E7%AE%97%E6%B3%95%E6%B5%81%E7%A8%8B.png)]](https://img-blog.csdnimg.cn/a41aeb1392aa40c49c0ddcc3bea5f81c.png)
(5)相比ICP的优势
NDT类方法比ICP类算法有更高的效率和更广的收敛域,对于2D和3D应用已有较为成熟的解决方案,但在缺乏良好初值的情况下,也会陷入局部最优。
- 对初值不敏感(也需要初值)
- 不需要最近邻搜索,速度快
NDT在PCL应用
#pragma once
/* * @Description: 使用正态分布变换进行配准 * https://www.cnblogs.com/li-yao7758258/p/6554582.html * http://robot.czxy.com/docs/pcl/chapter03/registration/#ndt * @Author: HCQ * @Company(School): UCAS * @Email: 1756260160@qq.com * @Date: 2020-10-22 19:20:43 * @LastEditTime: 2020-10-22 19:26:04 * @FilePath: /pcl-learning/14registration配准/4正态分布变换配准(NDT)/normal_distributions_transform.cpp */
/* 使用正态分布变换进行配准的实验 。其中room_scan1.pcd room_scan2.pcd这些点云包含同一房间360不同视角的扫描数据 */
#include <iostream>
#include <pcl/point_types.h>
#include <pcl/registration/ndt.h> //NDT(正态分布)配准类头文件
int ndt(const pcl::PointCloud<pcl::PointXYZ>::Ptr cloud_source,
const pcl::PointCloud<pcl::PointXYZ>::Ptr cloud_target,
pcl::PointCloud<pcl::PointXYZ>::Ptr transformed_source)
{
// 初始化正态分布(NDT)对象
pcl::NormalDistributionsTransform<pcl::PointXYZ, pcl::PointXYZ> ndt;
// 根据输入数据的尺度设置NDT相关参数
ndt.setTransformationEpsilon(0.03); //为终止条件设置最小转换差异
ndt.setStepSize(0.1); //为more-thuente线搜索设置最大步长
ndt.setResolution(2.0); //设置NDT网格网格结构的分辨率(voxelgridcovariance)
//添加最大迭代次数限制能够增加程序的鲁棒性阻止了它在错误的方向上运行时间过长
//ndt.setMaximumIterations(50);
ndt.setInputSource(cloud_source); //源点云
// Setting point cloud to be aligned to.
ndt.setInputTarget(cloud_target); //目标点云
//使用单位阵作为矩阵初始值
ndt.align( *transformed_source);
//这个地方的output_cloud不能作为最终的源点云变换,因为上面对点云进行了滤波处理
std::cout << "Normal Distributions Transform has converged:" << ndt.hasConverged()
<< " score: " << ndt.getFitnessScore() << std::endl;
std::cout << "tf matrix:\n" << ndt.getFinalTransformation() << std::endl;
// 使用创建的变换对为过滤的输入点云进行变换
pcl::transformPointCloud(*cloud_source, *transformed_source, ndt.getFinalTransformation());
// 保存转换后的源点云作为最终的变换输出
//pcl::io::savePCDFileASCII(transformed_source_name, *output_cloud);
return 0;
}
NDT源码解析
待更
参考资料
3d ndt原始论文《Scan registration for autonomous mining vehicles using 3D-NDT》
3d ndt 博士论文(更详细)《The Three-Dimensional Normal-Distributions Transform — an Efficient Representation for Registration, Surface Analysis, and Loop Detection》
ndt与icp比较《激光扫描匹配方法研究综述》
https://zhuanlan.zhihu.com/p/96908474
https://www.modb.pro/db/101593
https://www.codetd.com/en/article/13213393
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/215545.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
