大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
目录
一、哈希表是什么
哈希表(Hash table)又称散列表,是一种存储结构,通常用来存储多个元素。
和其它存储结构(线性表、树等)相比,哈希表查找目标元素的效率非常高。每个存储到哈希表中的元素,都配有一个唯一的标识(又称“索引”或者“键”),用户想查找哪个元素,凭借该元素对应的标识就可以直接找到它,无需遍历整个哈希表。
二、哈希表存储结构
多数场景中,哈希表是在数组的基础上构建的,下图给大家展示了一个普通的数组:
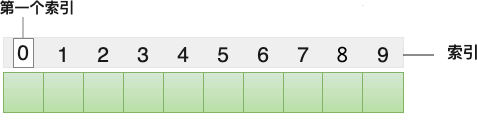

使用数组构建哈希表,最大的好处在于:可以直接将数组下标当作已存储元素的索引,不再需要为每个元素手动配置索引,极大得简化了构建哈希表的难度。
我们知道,在数组中查找一个元素,除非提前知晓它存储位置处的下标,否则只能遍历整个数组。哈希表的解决方案是:各个元素并不从数组的起始位置依次存储,它们的存储位置由专门设计的函数计算得出,我们通常将这样的函数称为哈希函数。
哈希函数类似于数学中的一次函数,我们给它传递一个元素,它反馈给我们一个结果值,这个值就是该元素对应的索引,也就是存储到哈希表中的位置。
举个例子,将 {20, 30, 50, 70, 80} 存储到哈希表中,我们设计的哈希函数为 y=x/10,最终各个元素的存储位置如下图所示:
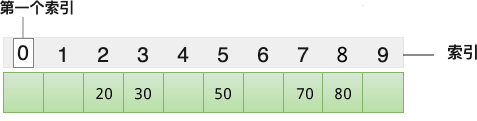
从上图我们可以看出,假设我们想查找元素 50,只需将它带入 y=x/10 这个哈希函数中,计算出它对应的索引值为 5,直接可以在数组中找到它。借助哈希函数,我们提高了数组中数据的查找效率,这就是哈希表存储结构。
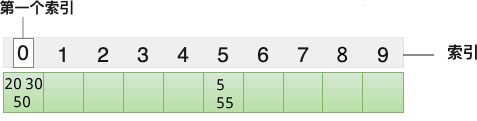
构建哈希表时,哈希函数的设计至关重要。假设将 {5, 20, 30, 50, 55} 存储到哈希表中,哈希函数是 y=x%10,各个元素在数组中的存储位置如下图所示:
三、哈希冲突
从上图可以看到,5 和 55 以及 20、30 和 50 对应的索引值是相同的,它们的存储位置发生了冲突,我们习惯称为哈希冲突或者哈希碰撞。设计一个好的哈希函数,可以降低哈希冲突的出现次数。哈希表提供了很多解决哈希冲突的方案,比如线性探测法、再哈希法、链地址法
?线性探测法
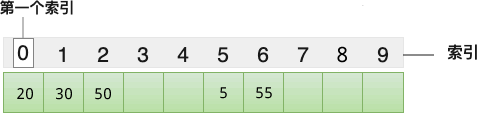
当使用线性探测法解决哈希冲突,解决方法是:当元素的索引值(存储位置)发生冲突时,从当前位置向后查找,直至找到一个空闲位置,作为冲突元素的存储位置。仍以图 3 中的哈希表为例,使用线性探测法解决哈希冲突的过程是:
- 元素 5 最先存储到数组中下标为 5 的位置;
- 元素 20 最先存储到数组中下标为 0 的位置;
- 元素 30 的存储位置为 0,和 20 冲突,根据线性探测法,从下标为 0 的位置向后查找,下标为 1 的存储位置空闲,用来存储 30;
- 元素 50 的存储位置为 0,和 20 冲突,根据线性探测法,从下标为 0 的位置向后查找,下标为 2 的存储位置空闲,用来存储 50;
- 元素 55 的存储位置为 5,和 5 冲突,根据线性探测法,从下标为 5 的位置向后查找,下标为 6 的存储位置空闲,用来存储 55。
借助线性探测法,最终 {5, 20, 30, 50, 55} 存储到哈希表中的状态为:
假设我们从图 4 所示的哈希表中查找元素 50,查找过程需要经过以下几步:
- 根据哈希函数 y=x%10,目标元素的存储位置为 0,但经过和下标为 0 处的元素 20 比较,该位置存储的并非目标元素;
- 根据线性探测法,比较下标位置为 1 处的元素 30,也不是目标元素;
- 继续比较下标位置为 2 的元素 50,成功找到目标元素。
对于发生哈希冲突的哈希表,尽管查找效率会下降,但仍比一些普通存储结构(比如数组)的查找效率高。
?二次探测法

?哈希桶(开散列法)
哈希桶法又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。
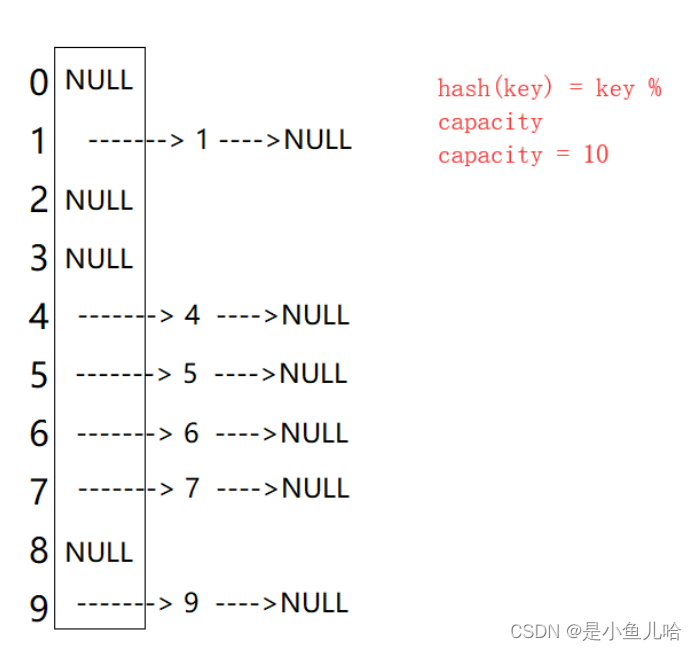
从上图可以看出,开散列中每个桶中放的都是发生哈希冲突的元素。
开散列,可以认为是把一个在大集合中的搜索问题转化为在小集合中做搜索了
刚才我们提到了,哈希桶其实可以看作将大集合的搜索问题转化为小集合的搜索问题了,那如果冲突严重,就意味着小集合的搜索性能其实也时不佳的,这个时候我们就可以将这个所谓的小集合搜索问题继续进行转化,例如:
- 每个桶的背后是另一个哈希表
- 每个桶的背后是一棵搜索树
四、哈希桶的手动代码实现
/**
* 哈希桶解决hash冲突(哈希桶的模拟实现)(同时实现了哈希查找)
*/
public class HashBuck {
class Node {
int key;
int value;
Node next;
public Node(int key, int value) {
this.key = key;
this.value = value;
}
}
private Node[] array; //该数字中的每一个下标元素都对应一个链表
private int UsedSize;
private static final double DEFULT_LOAD_FACTOR = 0.75;
public HashBuck(int size) {
array = new Node[size];
}
/**
* 插入元素
* @param key
* @param value
*/
public void put(int key, int value) {
Node node = new Node(key, value);
int index = key % array.length;
Node cur = array[index];
while (cur != null) {
if (cur.key == key) {
cur.value = value; // 如果冲突就替换该结点的值
return;
}
cur = cur.next;
}
// 如果程序走到这里,说明该array[index]所对应的那一列上的key没有和要插入结点的key相冲突的
// 进行第二步——头插(在JDK1.8中采用的是尾插)
node.next = array[index];
array[index] = node;
++UsedSize;
// 检查当前哈希表是否超过了负载因子
if (LoadFactor() >= DEFULT_LOAD_FACTOR) {
// 扩容——遍历数组每个链表的每个结点,重新哈希到新的哈希表当中(面试题)
resize();
}
}
// 扩容 && 对哈希表重新哈希
private void resize() {
Node[] temp = new Node[array.length * 2];
// 遍历原来的数组
for (int i = 0; i < array.length; i++) {
// 获取到当前下标的链表的头结点
Node cur = array[i];
// 遍历这个链表的每个结点
while (cur != null) {
Node curNext = cur.next; // 保存下当前链表的下一个结点
int index = cur.key % temp.length;// 获取到当前的key在新的数组中的下标
cur.next = temp[index];
temp[index] = cur;
cur = curNext; // 如果不提前保存cur.next,经过cur.next = temp[index],cur.next已经变了
}
}
array = temp; // 将原来数组的引用重新引用新的数组
}
private double LoadFactor() {
return UsedSize * 1 / array.length;
}
/**
* 通过key来获取value
*/
public int get(int key) {
int index = key % array.length;
Node cur = array[index];
// 遍历当前数组下标所对应的链表,在该链表中找key
while (cur != null) {
if (cur.key == key) {
return cur.value;
}
else {
cur = cur.next;
}
}
return -1;
}
}
测试代码:
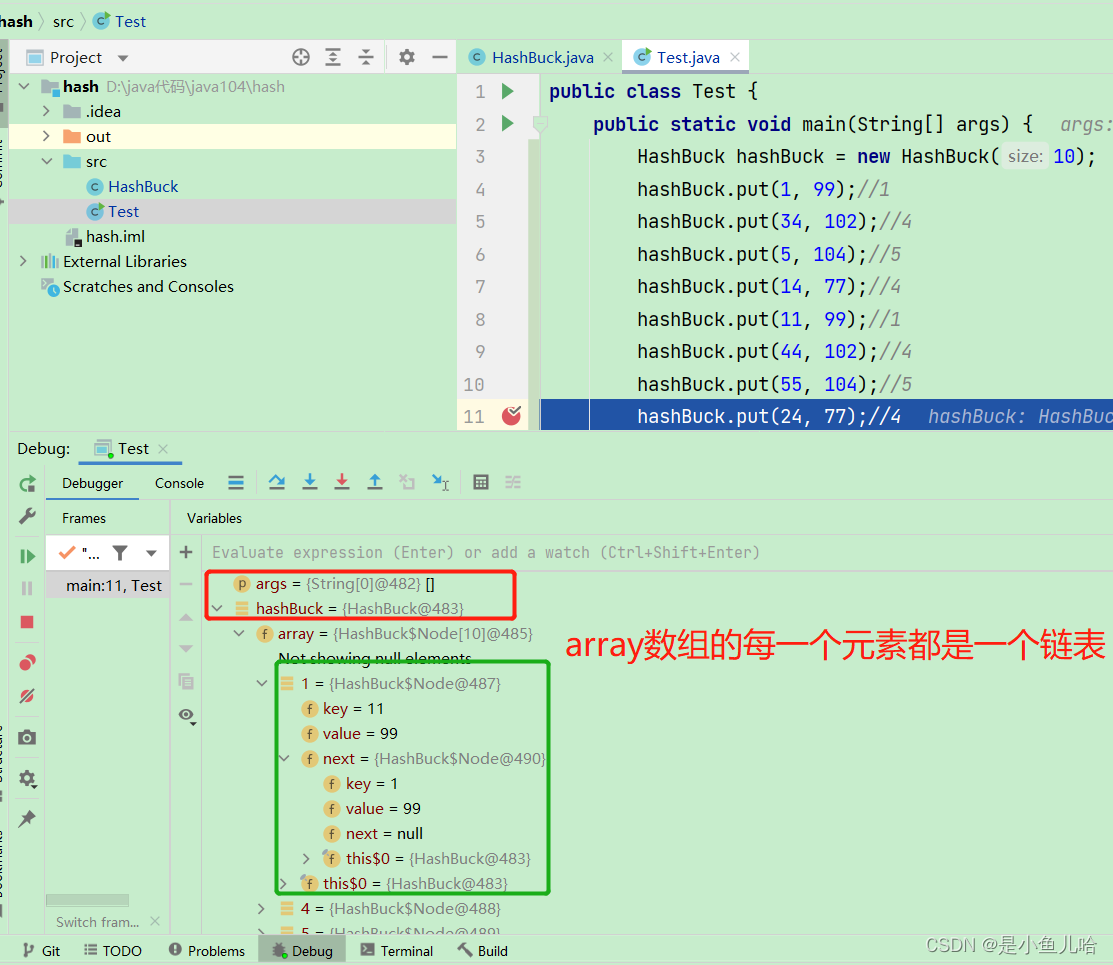
public class Test { public static void main(String[] args) { HashBuck hashBuck = new HashBuck(10); hashBuck.put(1, 99);//1 hashBuck.put(34, 102);//4 hashBuck.put(5, 104);//5 hashBuck.put(14, 77);//4 hashBuck.put(11, 99);//1 hashBuck.put(44, 102);//4 hashBuck.put(55, 104);//5 hashBuck.put(24, 77);//4 hashBuck.put(32, 234);//2 hashBuck.put(23, 378);//3 hashBuck.put(45, 5555);//5 hashBuck.put(13, 77777);//13 System.out.println("djfk"); } }
五、哈希查找算法(基于线性探测法的实现)
哈希查找算法就是利用哈希表查找目标元素的算法。对于给定的序列,该算法会先将整个序列存储到哈希表中,然后再查找目标元素。
如下是使用哈希查找算法在 {5, 20, 30, 50, 55} 序列中查找 50 的 Java 程序:
public class Demo {
//哈希函数
public static int hash(int value) {
return value % 10;
}
//创建哈希表
public static void creatHash(int [] arr,int [] hashArr) {
int i,index;
//将序列中每个元素存储到哈希表
for (i = 0; i < 5; i++) {
index = hash(arr[i]);
while(hashArr[index % 10] != 0) {
index++;
}
hashArr[index] = arr[i];
}
}
//实现哈希查找算法
public static int hash_serach(int [] hashArr,int value) {
//查找目标元素对应的索引值
int hashAdd = hash(value);
while (hashArr[hashAdd] != value) { // 如果索引位置不是目标元素,则发生了碰撞
hashAdd = (hashAdd + 1) % 10; // 根据线性探测法,从索引位置依次向后探测
//如果探测位置为空,或者重新回到了探测开始的位置(即探测了一圈),则查找失败
if (hashArr[hashAdd] == 0 || hashAdd == hash(value)) {
return -1;
}
}
//返回目标元素所在的数组下标
return hashAdd;
}
public static void main(String[] args) {
int [] arr = new int[] {5, 20, 30, 50, 55};
int[] hashArr = new int[10];
//创建哈希表
creatHash(arr,hashArr);
// 查找目标元素 50 位于哈希表中的位置
int hashAdd = hash_serach(hashArr,50);
if(hashAdd == -1) {
System.out.print("查找失败");
}else {
System.out.print("查找成功,目标元素所在哈希表中的下标为:" + hashAdd);
}
}
}当然在我们上面的哈希桶的手动实现代码中也同时实现了哈希查找,自己下去试试看吧!
练习题
题目一、


题目二、


题目三、


发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/213284.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
