大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
今天给大家展示基于R语言的聚类,在此之前呢,首先谈谈聚类分析,以及常见的聚类模型,说起聚类我们都知道,就是按照一定的相似性度量方式,把接近的一些个体聚在一起。这里主要是相似性度量,不同的数据类型,我们需要用不同的度量方式。除此之外,聚类的思想也很重要,要是按照聚类思想来说,主要有这么几大类,第一大类是基于分割的聚类,比如k-means,以及按照这个思路进行了简单扩展的几个聚类,如k-median等。第二大类呢,就是层次聚类,它其实是把个体之间的关系进行了一个层次展示,具体聚为几类,由人为进行设定。第三大类呢,就是基于密度的聚类,这里不要讲基于密度的聚类和基于概率密度分布的聚类相混淆,这其实是一样的,比如混合模型,就是基于概率分布的聚类,而DBSCAN就是基于密度的聚类,实际上,这里密度是指一指局部密度,而不是概率密度分布。那么第四大类呢,就是基于概率密度分布的聚类,这一类聚类方法主要是假设数据来自某个概率分布,或者是某几个概率分布的组合,进而进行参数估计,确定分布的样子,再反过来看看,样本点属于哪一类。那么第五大类呢,是矩阵的分解(Nonnegative Matrix Factorizations ),这一大类其实和之前的几类明显不同,比如SVD分解,或者其他的分解其实在文本挖掘或者推荐算法里边都属于聚类。最后一大类就是谱聚类了。下面我们用R语言进行一下计算。
#要是没有这个包的话,首先需要安装一下
#install.packages("factoextra")
#载入包
library(factoextra)
# 载入数据
data("USArrests")
# 数据进行标准化
df <- scale(USArrests)
# 查看数据的前五行
head(df, n = 5)
Murder Assault UrbanPop Rape
Alabama 1.24256408 0.7828393 -0.5209066 -0.003416473
Alaska 0.50786248 1.1068225 -1.2117642 2.484202941
Arizona 0.07163341 1.4788032 0.9989801 1.042878388
Arkansas 0.23234938 0.2308680 -1.0735927 -0.184916602
California 0.27826823 1.2628144 1.7589234 2.067820292
#确定最佳聚类数目
fviz_nbclust(df, kmeans, method = "wss") + geom_vline(xintercept = 4, linetype = 2)
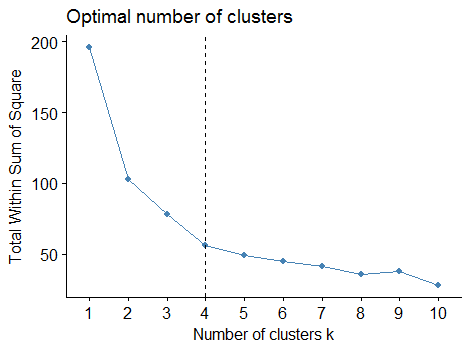
#可以发现聚为四类最合适,当然这个没有绝对的,从指标上看,选择坡度变化不明显的点最为最佳聚类数目。
#设置随机数种子,保证实验的可重复进行
set.seed(123)
#利用k-mean是进行聚类
km_result <- kmeans(df, 4, nstart = 24)
#查看聚类的一些结果
print(km_result)
#提取类标签并且与原始数据进行合并
dd <- cbind(USArrests, cluster = km.res$cluster)
head(dd)
Murder Assault UrbanPop Rape cluster
Alabama 13.2 236 58 21.2 4
Alaska 10.0 263 48 44.5 3
Arizona 8.1 294 80 31.0 3
Arkansas 8.8 190 50 19.5 4
California 9.0 276 91 40.6 3
Colorado 7.9 204 78 38.7 3
#查看每一类的数目
table(dd$cluster)
1 2 3 4
13 16 13 8
#进行可视化展示
fviz_cluster(km_result, data = df,
palette = c("#2E9FDF", "#00AFBB", "#E7B800", "#FC4E07"),
ellipse.type = "euclid",
star.plot = TRUE,
repel = TRUE,
ggtheme = theme_minimal()
)结果如下:
一般来说,能够对数据聚类后进行可视化展示的也就是二维,三维数据,如果维度很高的话,一种方法是t-SNE方法,这种方法是按照流型的方法进行可视化,用的比较多。另一种的话,就是利用降维方法,比如主成分分析等,进行降维后可视化展示。
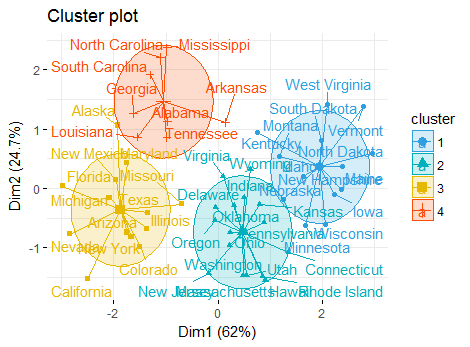
下面我们进行层次聚类
#先求样本之间两两相似性
result <- dist(df, method = "euclidean") #产生层次结构 result_hc <- hclust(d = result, method = "ward.D2") #进行初步展示 fviz_dend(result_hc, cex = 0.6)结果如下:
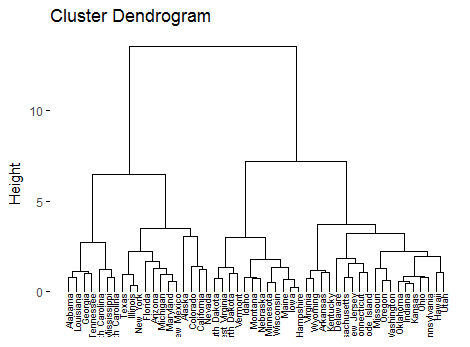
根据这个图,我们可以方便的确定聚为几类比较合适,比如我们聚为四类,并且进行可视化展示
fviz_dend(result_hc, k = 4,
cex = 0.5,
k_colors = c("#2E9FDF", "#00AFBB", "#E7B800", "#FC4E07"),
color_labels_by_k = TRUE,
rect = TRUE
)效果如下:

好,今天就到这,明天继续展示其它几类聚类方法,以及图的制作。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/213274.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
