大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
文章目录
一、为什么要用分布式ID
在说分布式ID的具体实现之前,我们来简单分析一下为什么用分布式ID?分布式ID应该满足哪些特征?
1、什么是分布式ID
拿MySQL数据库举个栗子:
在我们业务数据量不大的时候,单库单表完全可以支撑现有业务,数据再大一点搞个MySQL主从同步读写分离也能对付。
但随着数据日渐增长,主从同步也扛不住了,就需要对数据库进行分库分表,但分库分表后需要有一个唯一ID来标识一条数据,数据库的自增ID显然不能满足需求;特别一点的如订单、优惠券也都需要有唯一ID做标识。此时一个能够生成全局唯一ID的系统是非常必要的。那么这个全局唯一ID就叫分布式ID
2、那么分布式ID需要满足哪些条件
- 全局唯一:必须保证ID是全局性唯一的,基本要求
- 高性能:高可用低延时,ID生成响应要块,否则反倒会成为业务瓶颈
- 高可用:对ID号生成系统的可用性要求极高,所以不能有单点故障
- 好接入:要秉着拿来即用的设计原则,在系统设计和实现上要尽可能的简单
- 趋势递增:在MySQL InnoDB引擎中使用的是聚集索引,由于多数RDBMS使用B-tree的数据结构来存储索引数据,在主键的选择上面我们应该尽量使用有序的主键保证写入性能
- 单调递增:保证下一个ID一定大于上一个ID,例如事务版本号、IM增量消息、排序等特殊需求
- 信息安全:如果ID是连续的,恶意用户的扒取工作就非常容易做了,直接按照顺序下载指定URL即可;如果是订单号就更危险了,竞争对手可以直接知道我们一天的单量。所以在一些应用场景下,会需要ID无规则、不规则
- 分片支持:可以控制ShardingId。比如某一个用户的文章要放在同一个分片内,这样查询效率高,修改也容易
二、 分布式ID有哪些生成方式
今天主要分析一下以下9种,分布式ID生成器方式以及优缺点:
- 基于UUID
- 基于数据库自增ID
- 基于数据库集群模式
- 基于数据库的号段模式
- 基于Redis模式
- 基于雪花算法(SnowFlake)
- 百度 (Uidgenerator)
- 美团(Leaf)
- 滴滴出品(TinyID)
那么它们都是如何实现?以及各自有什么优缺点?我们往下看

1、基于UUID
UUID (Universally Unique Identifier),通用唯一识别码的缩写。UUID是由一组32位数的16进制数字所构成,所以UUID理论上的总数为 1632=2128,约等于 3.4 x 10^38。也就是说若每纳秒产生1兆个UUID,要花100亿年才会将所有UUID用完。
生成的UUID是由 8-4-4-4-12格式的数据组成,其中32个字符和4个连字符’ – ‘,一般我们使用的时候会将连字符删除 uuid.toString().replaceAll("-","")。
目前UUID的产生方式有5种版本,每个版本的算法不同,应用范围也不同。
-
基于时间的UUID – 版本1:这个一般是通过当前时间,随机数,和本地Mac地址来计算出来,可以通过
org.apache.logging.log4j.core.util包中的UuidUtil.getTimeBasedUuid()来使用或者其他包中工具。由于使用了MAC地址,因此能够确保唯一性,但是同时也暴露了MAC地址,私密性不够好。 -
DCE安全的UUID – 版本2:DCE(Distributed Computing Environment)安全的UUID和基于时间的UUID算法相同,但会把时间戳的前4位置换为POSIX的UID或GID。这个版本的UUID在实际中较少用到。
-
基于名字的UUID(MD5)- 版本3:基于名字的UUID通过计算名字和名字空间的MD5散列值得到。这个版本的UUID保证了:相同名字空间中不同名字生成的UUID的唯一性;不同名字空间中的UUID的唯一性;相同名字空间中相同名字的UUID重复生成是相同的。
-
随机UUID – 版本4:根据随机数,或者伪随机数生成UUID。这种UUID产生重复的概率是可以计算出来的,但是重复的可能性可以忽略不计,因此该版本也是被经常使用的版本。JDK中使用的就是这个版本。
-
基于名字的UUID(SHA1) – 版本5:和基于名字的UUID算法类似,只是散列值计算使用SHA1(Secure Hash Algorithm 1)算法。
我们 Java中 JDK自带的 UUID产生方式就是版本4根据随机数生成的 UUID 和版本3基于名字的 UUID,有兴趣的可以去看看它的源码
public static void main(String[] args) {
//获取一个版本4根据随机字节数组的UUID。
UUID uuid = UUID.randomUUID();
System.out.println(uuid.toString().replaceAll("-", ""));
//获取一个版本3(基于名称)根据指定的字节数组的UUID。
byte[] nbyte = {
10, 20, 30};
UUID uuidFromBytes = UUID.nameUUIDFromBytes(nbyte);
System.out.println(uuidFromBytes.toString().replaceAll("-", ""));
}
优点
- 生成简单,本地生成无网络消耗,性能非常高,具有唯一性
缺点
- 没有具体的业务含义:无序的字符串,没有具体的业务含义,且不具备趋势自增特性
- 信息不安全:基于MAC地址生成UUID的算法可能会造成MAC地址泄露,暴露使用者的位置。
- 存储性能差查询耗时:如果作为MySQL数据库主键,在InnoDB引擎下,UUID的无序性可能会引起数据位置频繁变动,严重影响性能,可以查阅 Mysql 索引原理 B+树的知识。
- 传输数据量大,且不可读
2、基于数据库自增ID
基于数据库的auto_increment自增ID完全可以充当分布式ID,具体实现:需要一个单独的MySQL实例用来生成ID,建表结构如下:
CREATE DATABASE `SEQ_ID`;
CREATE TABLE SEQID.SEQUENCE_ID (
id bigint(20) unsigned NOT NULL auto_increment,
value char(10) NOT NULL default '',
PRIMARY KEY (id),
);
insert into SEQUENCE_ID(value) VALUES ('values');
优点
- 实现简单,ID单调自增,数值类型查询速度快
缺点
- 强依赖DB,DB单点存在宕机风险,无法扛住高并发场景
3、基于数据库集群模式
前边说了单点数据库方式不可取,那对上边的方式做一些高可用优化,换成主从模式集群。害怕一个主节点挂掉没法用,那就做双主模式集群,也就是两个Mysql实例都能单独的生产自增ID
那这样还会有个问题,两个MySQL实例的自增ID都从1开始,会生成重复的ID怎么办?
解决方案:设置起始值和自增步长
MySQL_1 配置:
set @@auto_increment_offset = 1; -- 起始值
set @@auto_increment_increment = 2; -- 步长
MySQL_2 配置:
set @@auto_increment_offset = 2; -- 起始值
set @@auto_increment_increment = 2; -- 步长
这样两个MySQL实例的自增ID分别就是:
1、3、5、7、9
2、4、6、8、10
那如果集群后的性能还是扛不住高并发咋办?就要进行MySQL扩容增加节点,这是一个比较麻烦的事。
水平扩展的数据库集群,有利于解决数据库单点压力的问题,同时为了ID生成特性,将自增步长按照机器数量来设置。
增加第三台MySQL实例需要人工修改一、二两台MySQL实例的起始值和步长,把第三台机器的ID起始生成位置设定在比现有最大自增ID的位置远一些,但必须在一、二两台MySQL实例ID还没有增长到第三台MySQL实例的起始ID值的时候,否则自增ID就要出现重复了,必要时可能还需要停机修改。
优点
- 解决DB单点问题
缺点
- 不利于后续扩容,而且实际上单个数据库自身压力还是大,依旧无法满足高并发场景
4、基于数据库的号段模式
号段模式是当下分布式ID生成器的主流实现方式之一,号段模式可以理解为从数据库批量的获取自增ID,每次从数据库取出一个号段范围,例如 (1,1000] 代表1000个ID,具体的业务服务将本号段,生成1~1000的自增ID并加载到内存。表结构如下:
CREATE TABLE id_generator (
id int(10) NOT NULL,
max_id bigint(20) NOT NULL COMMENT '当前最大id',
step int(20) NOT NULL COMMENT '号段的布长',
biz_type int(20) NOT NULL COMMENT '业务类型',
version int(20) NOT NULL COMMENT '版本号',
PRIMARY KEY (`id`)
);
biz_type :代表不同业务类型
max_id :当前最大的可用id
step :代表号段的长度
version :是一个乐观锁,每次都更新version版本,保证并发时数据的正确性
| id | biz_type | max_id | step | version |
|---|---|---|---|---|
| 1 | 101 | 1000 | 2000 | 0 |
等这批号段ID用完,再次向数据库申请新号段,对max_id字段做一次update操作,update max_id= max_id + step,update成功则说明新号段获取成功,新的号段范围是(max_id ,max_id +step]
update id_generator set max_id = #{max_id+step}, version = version + 1 where version = # {version} and biz_type = XXX
由于多业务端可能同时操作,所以采用版本号version乐观锁方式更新,这种分布式ID生成方式不强依赖于数据库,不会频繁的访问数据库,对数据库的压力小很多。
优点
- 不会频繁的访问数据库,对数据库的压力小
缺点
- 需要将一个号段的自增ID保存到内存,增加实现难度
5、基于Redis模式
Redis实现分布式唯一ID主要是通过提供像 INCR 和 INCRBY 这样的自增原子命令,由于Redis自身的单线程的特点所以能保证生成的 ID 肯定是唯一有序的。
127.0.0.1:6379> set seq_id 1 // 初始化自增ID为1
OK
127.0.0.1:6379> incr seq_id // 增加1,并返回递增后的数值
(integer) 2
但是单机存在性能瓶颈,无法满足高并发的业务需求,所以可以采用集群的方式来实现。集群的方式又会涉及到和数据库集群同样的问题,所以也需要设置分段和步长来实现。
为了避免长期自增后数字过大可以通过与当前时间戳组合起来使用,另外为了保证并发和业务多线程的问题可以采用 Redis + Lua的方式进行编码,保证安全。
优点
- Redis 实现分布式全局唯一ID,它的性能比较高,生成的数据是有序的,对排序业务有利
缺点
-
需要系统引进redis组件,增加了系统的配置复杂性
-
需要编码和配置的工作量比较大
-
Redis单点故障,影响服务可用性
-
用
redis实现需要注意一点,要考虑到redis持久化的问题。redis有两种持久化方式RDB和AOF-
RDB会定时打一个快照进行持久化,假如连续自增但redis没及时持久化,而这会Redis挂掉了,重启Redis后会出现ID重复的情况。 -
AOF会对每条写命令进行持久化,即使Redis挂掉了也不会出现ID重复的情况,但由于incr命令的特殊性,会导致Redis重启恢复的数据时间过长。
-
6、基于雪花算法(Snowflake)模式
雪花算法(Snowflake)是twitter公司内部分布式项目采用的ID生成算法,开源后广受国内大厂的好评,在该算法影响下各大公司相继开发出各具特色的分布式ID生成器。
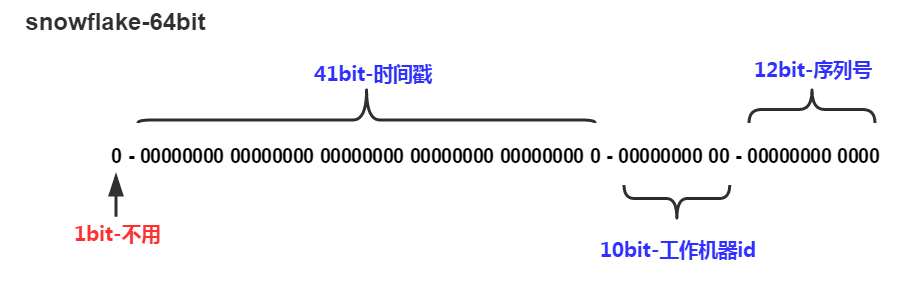
Snowflake生成的是Long类型的ID,一个Long类型占8个字节,每个字节占8比特,也就是说一个Long类型占64个比特。
Snowflake ID组成结构:正数位(占1比特)+ 时间戳(占41比特)+ 机器ID(占5比特)+ 数据中心(占5比特)+ 自增值(占12比特),总共64比特组成的一个Long类型。
- 第一个bit位(1bit):Java中long的最高位是符号位代表正负,正数是0,负数是1,一般生成ID都为正数,所以默认为0。
- 时间戳部分(41bit):毫秒级的时间,不建议存当前时间戳,而是用(当前时间戳 – 固定开始时间戳)的差值,可以使产生的ID从更小的值开始;41位的时间戳可以使用69年,(1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69年
- 工作机器id(10bit):也被叫做
workId,这个可以灵活配置,机房或者机器号组合都可以。 - 序列号部分(12bit),自增值支持同一毫秒内同一个节点可以生成4096个ID
根据这个算法的逻辑,只需要将这个算法用Java语言实现出来,封装为一个工具方法,那么各个业务应用可以直接使用该工具方法来获取分布式ID,只需保证每个业务应用有自己的工作机器id即可,而不需要单独去搭建一个获取分布式ID的应用。
Java版本的Snowflake算法实现
public class SnowflakeIdWorker {
/** * 起始的时间戳,2020-01-01 00:00:00 */
private final static long START_TIMESTAMP = 1577808000000L;
/** * 数据中心占用的位数 */
private final static long DATACENTER_ID_BIT = 5;
/** * 工作机器标识占用的位数 */
private final static long WORKER_ID_BIT = 5;
/** * 序列号占用的位数 */
private final static long SEQUENCE_BIT = 12;
/** * 支持的数据中心最大值 */
private final static long MAX_DATACENTER_ID = ~(-1L << DATACENTER_ID_BIT);
/** * 支持的工作机器标识最大值 */
private final static long MAX_WORKER_ID = ~(-1L << WORKER_ID_BIT);
/** * 支持的序列号最大值 */
private final static long MAX_SEQUENCE = ~(-1L << SEQUENCE_BIT);
/** * 工作机器标识向左移12位 */
private final static long WORKER_ID_LEFT = SEQUENCE_BIT;
/** * 数据中心向左移(12+5)位 */
private final static long DATACENTER_ID_LEFT = SEQUENCE_BIT + WORKER_ID_BIT;
/** * 时间戳向左移(12+5+5)位 */
private final static long TIMESTAMP_LEFT = DATACENTER_ID_LEFT + DATACENTER_ID_BIT;
/** * 数据中心 */
private final long datacenterId;
/** * 工作机器标识 */
private final long workerId;
/** * 序列号 */
private long sequence = 0L;
/** * 上一次时间戳 */
private long lastTimestamp = -1L;
/** * 构造函数 * * @param datacenterId 数据中心 (0~31) * @param workerId 工作机器标识 (0~31) */
public SnowflakeIdWorker(long datacenterId, long workerId) {
if (datacenterId > MAX_DATACENTER_ID || datacenterId < 0) {
throw new IllegalArgumentException("datacenterId can't be greater than MAX_DATACENTER_ID or less than 0");
}
if (workerId > MAX_WORKER_ID || workerId < 0) {
throw new IllegalArgumentException("workerId can't be greater than MAX_WORKER_ID or less than 0");
}
this.datacenterId = datacenterId;
this.workerId = workerId;
}
/** * 获取下一个ID (该方法是线程安全的) * * @return long SnowflakeId */
public synchronized long nextId() {
long currentTimestamp = currentTimeMillis();
//如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常
if (currentTimestamp < lastTimestamp) {
throw new RuntimeException("Clock moved backwards. Refusing to generate id");
}
//如果是同一时间生成的,则进行毫秒内序列
if (currentTimestamp == lastTimestamp) {
//相同毫秒内,序列号自增
sequence = (sequence + 1) & MAX_SEQUENCE;
//同一毫秒的序列数已经达到最大
if (sequence == 0L) {
currentTimestamp = nextTimeMillis();
}
} else {
//不同毫秒内,序列号置为0
sequence = 0L;
}
//上次生成ID的时间戳
lastTimestamp = currentTimestamp;
//移位并通过或运算拼到一起组成64位的ID
//时间戳部分
return (currentTimestamp - START_TIMESTAMP) << TIMESTAMP_LEFT
//数据中心部分
| datacenterId << DATACENTER_ID_LEFT
//工作机器标识部分
| workerId << WORKER_ID_LEFT
//序列号部分
| sequence;
}
/** * 阻塞到下一个毫秒,直到获得新的时间戳 * * @return 当前时间戳 */
private long nextTimeMillis() {
long mill = currentTimeMillis();
while (mill <= lastTimestamp) {
mill = currentTimeMillis();
}
return mill;
}
/** * 返回以毫秒为单位的当前时间 * * @return 当前时间(毫秒) */
private long currentTimeMillis() {
return System.currentTimeMillis();
}
public static void main(String[] args) {
SnowflakeIdWorker snowflake = new SnowflakeIdWorker(2, 3);
for (int i = 0; i < (1 << 10); i++) {
System.out.println(snowflake.nextId());
}
}
}
雪花算法提供了一个很好的设计思想,雪花算法生成的ID是趋势递增,不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的,而且可以根据自身业务特性分配bit位,非常灵活。
但是雪花算法强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。如果恰巧回退前生成过一些ID,而时间回退后,生成的ID就有可能重复。官方对于此并没有给出解决方案,而是简单的抛错处理,这样会造成在时间被追回之前的这段时间服务不可用。
很多其他类雪花算法也是在此思想上的设计然后改进规避它的缺陷,后面介绍的百度 UidGenerator 和 美团分布式ID生成系统 Leaf 中snowflake模式都是在 snowflake 的基础上演进出来的。
优点
- 不依赖外部组件,稳定性高
- 灵活方便,可以根据自身业务特性分配bit位
- 单机上ID单调自增,毫秒数在高位,自增序列在低位,整个ID都是趋势递增的
缺点
- 强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态
- ID可能不是全局递增。在单机上是递增的,但是由于涉及到分布式环境,每台机器上的时钟不可能完全同步,也许有时候也会出现不是全局递增的情况
7、百度(uid-generator)
uid-generator是由百度技术部开发,项目GitHub地址 https://github.com/baidu/uid-generator
uid-generator是基于Snowflake算法实现的,与原始的snowflake算法不同在于,uid-generator支持自定义时间戳、工作机器ID和 序列号 等各部分的位数,而且uid-generator中采用用户自定义workId的生成策略。
uid-generator需要与数据库配合使用,需要新增一个WORKER_NODE表。当应用启动时会向数据库表中去插入一条数据,插入成功后返回的自增ID就是该机器的workId数据,由host,port组成。
对于uid-generator ID组成结构:
workId,占用了22个bit位,时间占用了28个bit位,序列化占用了13个bit位,需要注意的是,和原始的snowflake不太一样,时间的单位是秒,而不是毫秒,workId也不一样,而且同一应用每次重启就会消费一个workId。
参考文献
https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md
8、美团(Leaf)
Leaf由美团开发,github地址:https://github.com/Meituan-Dianping/Leaf
Leaf同时支持号段模式和snowflake算法模式,可以切换使用。
号段模式
先导入源码 https://github.com/Meituan-Dianping/Leaf ,再建一张表leaf_alloc
DROP TABLE IF EXISTS `leaf_alloc`;
CREATE TABLE `leaf_alloc` (
`biz_tag` varchar(128) NOT NULL DEFAULT '' COMMENT '业务key',
`max_id` bigint(20) NOT NULL DEFAULT '1' COMMENT '当前已经分配了的最大id',
`step` int(11) NOT NULL COMMENT '初始步长,也是动态调整的最小步长',
`description` varchar(256) DEFAULT NULL COMMENT '业务key的描述',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '数据库维护的更新时间',
PRIMARY KEY (`biz_tag`)
) ENGINE=InnoDB;
然后在项目中开启号段模式,配置对应的数据库信息,并关闭snowflake模式
leaf.name=com.sankuai.leaf.opensource.test
leaf.segment.enable=true
leaf.jdbc.url=jdbc:mysql://localhost:3306/leaf_test?useUnicode=true&characterEncoding=utf8&characterSetResults=utf8
leaf.jdbc.username=root
leaf.jdbc.password=root
leaf.snowflake.enable=false
#leaf.snowflake.zk.address=
#leaf.snowflake.port=
启动leaf-server 模块的 LeafServerApplication项目就跑起来了
号段模式获取分布式自增ID的测试url:http://localhost:8080/api/segment/get/leaf-segment-test
监控号段模式:http://localhost:8080/cache
snowflake模式
Leaf的snowflake模式依赖于ZooKeeper,不同于原始snowflake算法,主要是在workId的生成上,Leaf中workId是基于ZooKeeper的顺序Id来生成的,每个应用在使用Leaf-snowflake时,启动时都会都在Zookeeper中生成一个顺序Id,相当于一台机器对应一个顺序节点,也就是一个workId。
leaf.snowflake.enable=true
leaf.snowflake.zk.address=127.0.0.1
leaf.snowflake.port=2181
snowflake模式获取分布式自增ID的测试url:http://localhost:8080/api/snowflake/get/test
9、滴滴(Tinyid)
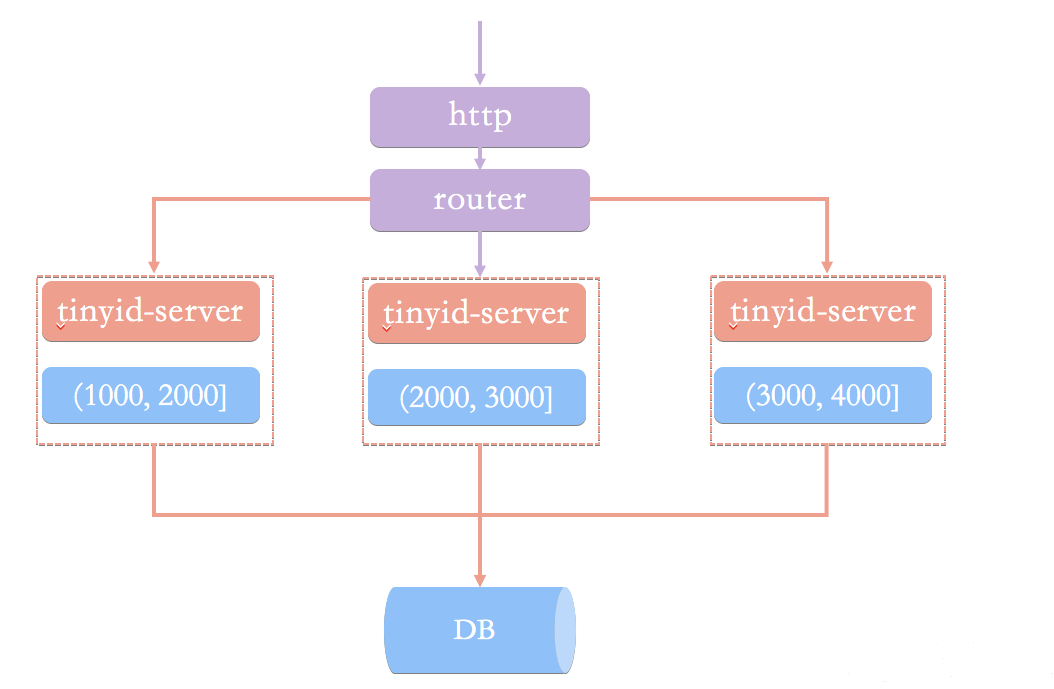
Tinyid由滴滴开发,Github地址:https://github.com/didi/tinyid。
Tinyid是基于号段模式原理实现的与Leaf如出一辙,每个服务获取一个号段(1000,2000]、(2000,3000]、(3000,4000]
Tinyid提供http和tinyid-client两种方式接入
Http方式接入
(1)导入Tinyid源码:
git clone https://github.com/didi/tinyid.git
(2)创建数据表:
CREATE TABLE `tiny_id_info` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`biz_type` varchar(63) NOT NULL DEFAULT '' COMMENT '业务类型,唯一',
`begin_id` bigint(20) NOT NULL DEFAULT '0' COMMENT '开始id,仅记录初始值,无其他含义。初始化时begin_id和max_id应相同',
`max_id` bigint(20) NOT NULL DEFAULT '0' COMMENT '当前最大id',
`step` int(11) DEFAULT '0' COMMENT '步长',
`delta` int(11) NOT NULL DEFAULT '1' COMMENT '每次id增量',
`remainder` int(11) NOT NULL DEFAULT '0' COMMENT '余数',
`create_time` timestamp NOT NULL DEFAULT '2010-01-01 00:00:00' COMMENT '创建时间',
`update_time` timestamp NOT NULL DEFAULT '2010-01-01 00:00:00' COMMENT '更新时间',
`version` bigint(20) NOT NULL DEFAULT '0' COMMENT '版本号',
PRIMARY KEY (`id`),
UNIQUE KEY `uniq_biz_type` (`biz_type`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT 'id信息表';
CREATE TABLE `tiny_id_token` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
`token` varchar(255) NOT NULL DEFAULT '' COMMENT 'token',
`biz_type` varchar(63) NOT NULL DEFAULT '' COMMENT '此token可访问的业务类型标识',
`remark` varchar(255) NOT NULL DEFAULT '' COMMENT '备注',
`create_time` timestamp NOT NULL DEFAULT '2010-01-01 00:00:00' COMMENT '创建时间',
`update_time` timestamp NOT NULL DEFAULT '2010-01-01 00:00:00' COMMENT '更新时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT 'token信息表';
INSERT INTO `tiny_id_info` (`id`, `biz_type`, `begin_id`, `max_id`, `step`, `delta`, `remainder`, `create_time`, `update_time`, `version`)
VALUES
(1, 'test', 1, 1, 100000, 1, 0, '2018-07-21 23:52:58', '2018-07-22 23:19:27', 1);
INSERT INTO `tiny_id_info` (`id`, `biz_type`, `begin_id`, `max_id`, `step`, `delta`, `remainder`, `create_time`, `update_time`, `version`)
VALUES
(2, 'test_odd', 1, 1, 100000, 2, 1, '2018-07-21 23:52:58', '2018-07-23 00:39:24', 3);
INSERT INTO `tiny_id_token` (`id`, `token`, `biz_type`, `remark`, `create_time`, `update_time`)
VALUES
(1, '0f673adf80504e2eaa552f5d791b644c', 'test', '1', '2017-12-14 16:36:46', '2017-12-14 16:36:48');
INSERT INTO `tiny_id_token` (`id`, `token`, `biz_type`, `remark`, `create_time`, `update_time`)
VALUES
(2, '0f673adf80504e2eaa552f5d791b644c', 'test_odd', '1', '2017-12-14 16:36:46', '2017-12-14 16:36:48');
(3)配置数据库:
datasource.tinyid.names=primary
datasource.tinyid.primary.driver-class-name=com.mysql.jdbc.Driver
datasource.tinyid.primary.url=jdbc:mysql://ip:port/databaseName?autoReconnect=true&useUnicode=true&characterEncoding=UTF-8
datasource.tinyid.primary.username=root
datasource.tinyid.primary.password=123456
(4)启动tinyid-server后测试
获取分布式自增ID: http://localhost:9999/tinyid/id/nextIdSimple?bizType=test&token=0f673adf80504e2eaa552f5d791b644c'
返回结果: 3
批量获取分布式自增ID: http://localhost:9999/tinyid/id/nextIdSimple?bizType=test&token=0f673adf80504e2eaa552f5d791b644c&batchSize=10'
返回结果: 4,5,6,7,8,9,10,11,12,13
Java客户端方式接入
重复Http方式的(2)(3)操作
引入依赖
<dependency>
<groupId>com.xiaoju.uemc.tinyid</groupId>
<artifactId>tinyid-client</artifactId>
<version>${tinyid.version}</version>
</dependency>
配置文件
tinyid.server =localhost:9999
tinyid.token =0f673adf80504e2eaa552f5d791b644c
test 、tinyid.token是在数据库表中预先插入的数据,test 是具体业务类型,tinyid.token表示可访问的业务类型
// 获取单个分布式自增ID
Long id = TinyId.nextId("test");
// 按需批量分布式自增ID
List< Long > ids = TinyId.nextId("test" , 10);
三、总结
本文只是简单介绍一下每种分布式ID生成器,旨在给大家一个详细学习的方向,每种生成方式都有它自己的优缺点,具体如何使用还要看具体的业务需求。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/210085.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
