大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
目录
一、概念
1.1、算法效率
如何衡量一个算法的好坏?比如对于以下斐波那契数列:
long long Fib(int N) { if (N < 3) return 1; return Fib(N - 1) + Fib(N - 2); }斐波那契数列用递归实现方式非常简洁,但简洁一定好吗?那该如何衡量其好与坏呢?在学完时间复杂度会为您揭晓。
算法效率分析分为两种:第一种是时间效率,第二种是空间效率。时间效率被称为时间复杂度,而空间效率被称作空间复杂度。 时间复杂度主要衡量的是一个算法的运行速度,而空间复杂度主要衡量一个算法所需要的额外空间,在计算机发展的早期,计算机的存储容量很小。所以对空间复杂度很是在乎。但是经过计算机行业的迅速发展,计算机的存储容量已经达到了很高的程度。所以我们如今已经不需要再特别关注一个算法的空间复杂度
1.2、时间复杂度
一个算法所花费的时间与其中语句的执行次数成正比例,算法中的基本操作的执行次数,为算法的时间复杂度。
1.3、空间复杂度
空间复杂度是对一个算法在运行过程中临时占用存储空间大小的量度 。空间复杂度不是程序占用了多少bytes的空间,因为这个也没太大意义,所以空间复杂度算的是变量的个数。空间复杂度计算规则基本跟实践复杂度类似,也使用大O渐进表示法。
二、计算
2.1、大O的渐进表示法
先看一串代码:
// 请计算一下Func1基本操作执行了多少次? void Func1(int N) { int count = 0; for (int i = 0; i < N; ++i) { for (int j = 0; j < N; ++j) { ++count; } } for (int k = 0; k < 2 * N; ++k) { ++count; } int M = 10; while (M--) { ++count; } printf("%d\n", count); }算法中的基本操作的执行次数,为算法的时间复杂度。显而易见,这里Func1 执行的最准确操作次数 :F(N)=N*N+2*N+10
例如F(10)=130、F(100)=10210、F(1000)=1002010
按理来说此题的时间复杂度就是上述的公式,其实不然。时间复杂度是一个估算,是去看表达式中影响最大的那一项。此题随着N的增大,这个表达式中N^2对结果的影响是最大的
实际中我们计算时间复杂度时,我们其实并不一定要计算精确的执行次数,而只需要大概执行次
数,那么这里我们使用大O的渐进表示法。,因而上题的时间复杂度为O(N^2)大O符号(Big O notation):是用于描述函数渐进行为的数学符号。
- 推导大O阶方法:
- 用常数1取代运行时间中的所有加法常数。
- 在修改后的运行次数函数中,只保留最高阶项。
- 如果最高阶项存在且不是1,则去除与这个项目相乘的常数。得到的结果就是大O阶。
通过上面我们会发现大O的渐进表示法去掉了那些对结果影响不大的项,简洁明了的表示出了执行次数。另外有些算法的时间复杂度存在最好、平均和最坏情况:
- 最坏情况:任意输入规模的最大运行次数(上界)
- 平均情况:任意输入规模的期望运行次数
- 最好情况:任意输入规模的最小运行次数(下界)
- 例如:在一个长度为N数组中搜索一个数据x
- 最好情况:1次找到
- 最坏情况:N次找到
- 平均情况:N/2次找到
在实际中一般情况关注的是算法的最坏运行情况,所以数组中搜索数据时间复杂度为O(N)
注意:递归算法时间复杂度计算
- 每次函数调用是O(1),那么就看他的递归次数
- 每次函数调用不是O(1),那么就看他的递归调用中次数的累加
2.2、时间复杂度计算
例题:
- 例一:
// 计算Func2的时间复杂度? void Func2(int N) { int count = 0; for (int k = 0; k < 2 * N; ++k) { ++count; } int M = 10; while (M--) { ++count; } printf("%d\n", count); }
- 答案:O(N)
解析:此题中最准确的次数为2*N+10,而其中影响最大的是N,可能有人觉着是2*N,但随着N的不断增大,2对结果的影响不是很大,况且要符合上述第三条规则:如果最高阶项存在且不是1,则去除与这个项目相乘的常数。得到的结果就是大O阶。所以把2去除掉,因而时间复杂度为O(N)
- 例二:
// 计算Func3的时间复杂度? void Func3(int N, int M) { int count = 0; for (int k = 0; k < M; ++k) { ++count; } for (int k = 0; k < N; ++k) { ++count; } printf("%d\n", count); }
- 答案:O(M+N)
解析:因为M和N都是未知数,所以N和M都要带着,但是如果题目明确M远大于N,那么时间复杂度就是O(M),如果M和N差不多大,那么时间复杂度就是O(M)或O(N)
- 例三:
// 计算Func4的时间复杂度? void Func4(int N) { int count = 0; for (int k = 0; k < 100; ++k) { ++count; } printf("%d\n", count); }
- 答案:O(1)
解析:这里最准确的次数是100,但是要符合大O的渐进表示法的规则,用常数1取代运行时间中的所有加法常数。所以时间复杂度就是O(1)
- 例四:
// 计算strchr的时间复杂度? const char* strchr(const char* str, char character) { while (*str != '\0') { if (*str == character) return str; ++str; } return NULL; }
- 答案:O(N)
解析:此题就要分情况了,这里假设字符串为abcdefghijklmn,如果目标字符找的是g,则需要执行N/2次,如果找到是a,则需要执行1次,如果找n,则N次,所以要分情况,这里就出现了有些算法的时间复杂度存在最好O(1)、平均O(N/2)和最坏O(N)情况,但是在实际中一般情况关注的是算法的最坏运行情况,所以此题时间复杂度为O(N)
- 例五:
// 计算BubbleSort的时间复杂度? void BubbleSort(int* a, int n) { assert(a); for (size_t end = n; end > 0; --end) { int exchange = 0; for (size_t i = 1; i < end; ++i) { if (a[i - 1] > a[i]) { Swap(&a[i - 1], &a[i]); exchange = 1; } } if (exchange == 0) break; } }
- 答案:O(N^2)
解析:此段代码考到的是冒泡排序。第一趟的冒泡排序走了N次,第二趟走了N-1次,第三趟N-2,……最后就是1,次规律正合等差数列,求和即为(N+1)*N/2,当然这个是最准确的,这里还要找对结果影响最大的那一项,即N^2,所以时间复杂度是O(N^2)
- 例六:
// 计算BinarySearch的时间复杂度? int BinarySearch(int* a, int n, int x) { assert(a); int begin = 0; int end = n; while (begin < end) { int mid = begin + ((end - begin) >> 1); if (a[mid] < x) begin = mid + 1; else if (a[mid] > x) end = mid; else return mid; } return -1; }
- 答案:O(logN)
解析:此题很明显考到的是二分查找。假设数组长度为N,且找了X次,则1*2*2*2*2*……*2=N,即为2^X=N,则X等于log以2为底N的对数,而算法的复杂度计算,喜欢省略简写成logN,因为很多地方不好写底数,所以此题时间复杂度为O(logN)
- 例七:
// 计算阶乘递归Factorial的时间复杂度? long long Factorial(size_t N) { return N < 2 ? N : Factorial(N-1)*N; }
- 答案:O(N)
解析:如果N为10
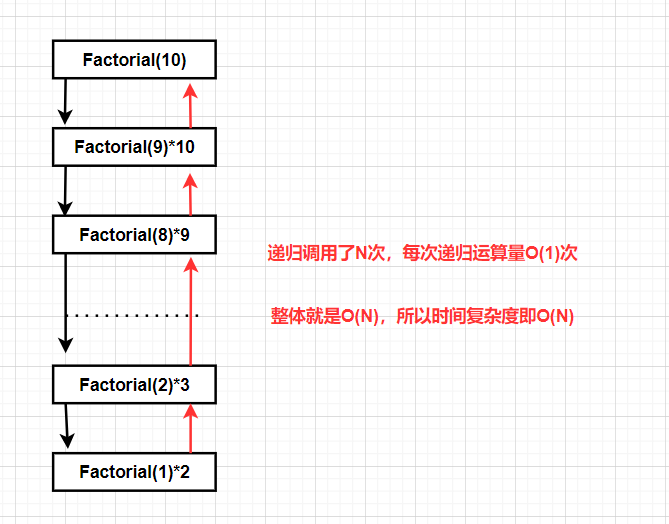

- 例八:
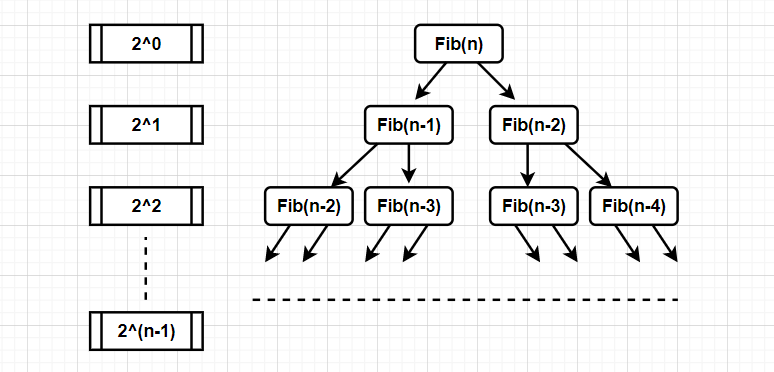
long long Fib(int N) { if (N < 3) return 1; return Fib(N - 1) + Fib(N - 2); }这串代码是上文最开始呈现的代码,代码风格十分简单,短短几行便可完成斐波那契数列的计算,可看似这么简洁的代码真的“好”吗?先来计算一下时间复杂度:
- 答案:O(2^N)
解析:
有上图可以得知,第一行执行1次,第二行执行2^1次,第三行执行2^2次,以此类推,是个等比数列,累计算下来再根据大O阶表示法的规则得知,此斐波那契数列的时间复杂度为O(2^N)。
但是,根据2^N这个时间复杂度是个非常大的数字,当n=10时,在VS环境下很快容易得到答案,但是当n稍微再大一点比如说是50,就要等上很长一段时间才能将结果算出来,由此可见,简洁的代码不一定是最优的代码。
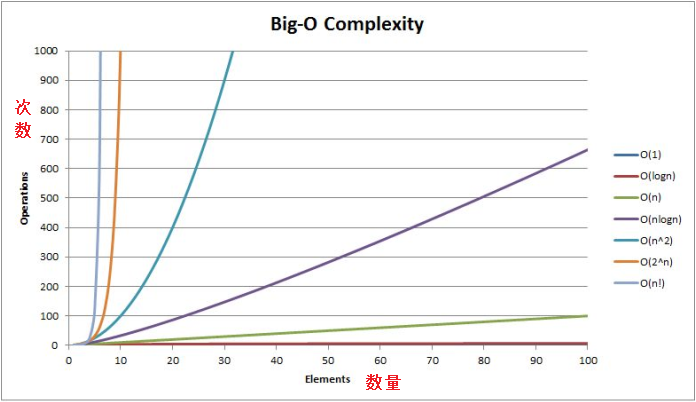
常见时间复杂度:O(N^2)、O(N)、O(logN)、O(1)
- 复杂度对比:
2.3、空间复杂度计算
- 空间复杂度也是一个数学表达式,是对一个算法在运行过程中临时占用存储空间大小的量度 。空间复杂度不是程序占用了多少bytes的空间,因为这个也没太大意义,所以空间复杂度算的是变量的个数。
- 空间复杂度计算规则基本跟实践复杂度类似,也使用大O渐进表示法。
- 注意:函数运行时所需要的栈空间(存储参数、局部变量、一些寄存器信息等)在编译期间已经确定好了,因此空间复杂度主要通过函数在运行时候显式申请的额外空间来确定。
例题
- 例一:
// 计算BubbleSort的空间复杂度? void BubbleSort(int* a, int n) { assert(a); for (size_t end = n; end > 0; --end) { int exchange = 0; for (size_t i = 1; i < end; ++i) { if (a[i - 1] > a[i]) { Swap(&a[i - 1], &a[i]); exchange = 1; } } if (exchange == 0) break; } }
- 答案:O(1)
解析:这里其实总共开辟了三个空间,分别为end、exchange、i,既然是常数个变量,那么空间复杂度就是O(1),空间复杂度算的是申请的额外空间,所以跟上面的int*a和int n没有关系。可能有人觉着这是个for循环,exchange应该开辟n次,其实每次循环进来,exchange都会重新开辟,结束一次循环exchange销毁,以此类推,exchange始终是同一个空间。
而什么时候会出现O(n)呢?
- 1、malloc一个数组
int *a = (int*)malloc(sizeof(int)*numsSize); //O(N)此情况的前提是numsSize必须是个未知的数字,如果是具体数字,那么空间复杂度依旧是O(1)
- 2、变长数组
int a[numsSize]; //numsSize未知,O(N)
- 例二:
// 计算Fibonacci的空间复杂度? // 返回斐波那契数列的前n项 long long* Fibonacci(size_t n) { if (n == 0) return NULL; long long* fibArray = (long long*)malloc((n + 1) * sizeof(long long)); fibArray[0] = 0; fibArray[1] = 1; for (int i = 2; i <= n; ++i) { fibArray[i] = fibArray[i - 1] + fibArray[i - 2]; } return fibArray; }
- 答案:O(N+1)
解析:这里看到了malloc开辟了n+1个大小为long long类型的数组,看到这就不需要再过多计较后续创建了几个变量,因为空间复杂度是估算,所以直接就是O(N)
- 例三:
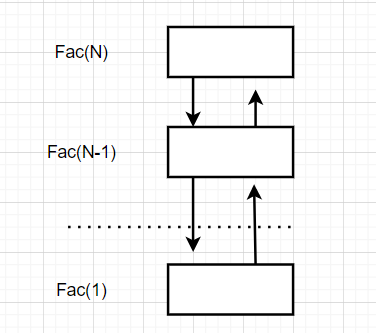
// 计算阶乘递归Fac的空间复杂度? long long Fac(size_t N) { if (N == 0) return 1; return Fac(N - 1) * N; }
- 答案:O(1)
解析: 这里递归函数是要建立栈帧的,而建立栈帧的个数为N个,每个栈帧的变量都是常数个,N个即空间复杂度为O(N)
- 例四:
// 计算斐波那契递归Fib的空间复杂度? long long Fib(size_t N) { if (N < 3) return 1; return Fib(N - 1) + Fib(N - 2); }
- 答案:O(N)
解析:时间一去不复返,是累积的,空间回收以后是可以重复利用的。当递归到Fib(3)的时候,此时调用Fib(2)和Fib(1),调到Fib(2)就可以返回了,此时Fib(2)的栈帧就销毁了,此时再调用的Fib(1)和Fib(2)用的就是同一块空间,同理Fib(N-1)总共建立了N-1个栈帧,同理再调用Fib(N-2)和刚才Fib(N-1)使用的是同一块空间,充分说明了时间一去不复返,是累积的,空间回收以后是可以重复利用的。
三、有复杂度要求的习题
- 题一:(消失的数字)
链接:https://leetcode-cn.com/problems/missing-number-lcci/
此题就明确了一个要求:想办法在O(n)的时间内完成,本题将提供两种有效且可行的方法,正文开始:
法一:相加 – 相加
- 思想:
此题是在一串连续的整数中缺了一个数,那我们就把理应有的整数个数依次相加再减去原数组中缺一个数字的所有元素和即为我们想要的数字。
代码如下:
int missingNumber(int* nums, int numsSize){ int sum1=0; int sum2=0; for(int i=0;i<numsSize+1;i++) { sum1+=i; } for(int i=0;i<numsSize;i++) { sum2+=nums[i]; } return sum1-sum2; }法二:异或
- 思想:
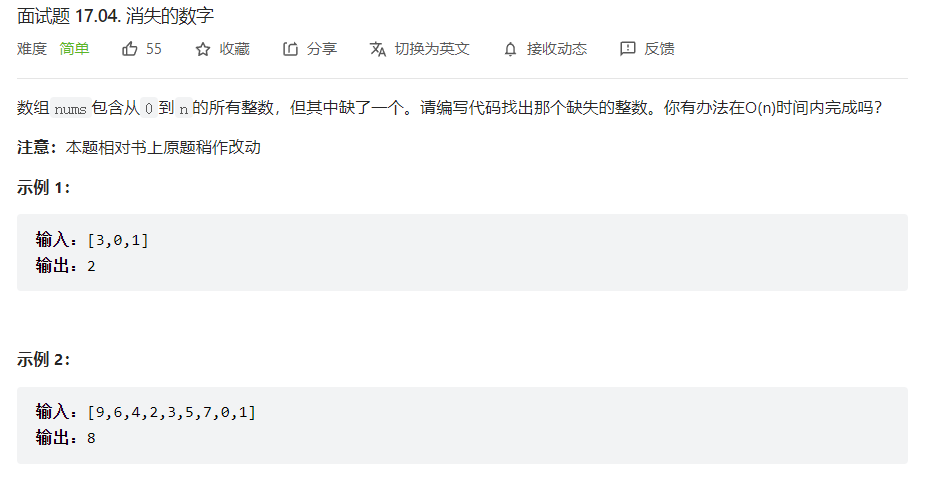
正如示例2,这里假设一共有10个数字,那么这里nums数组就是 [ 0 – 9 ],不过其中缺了一个数字,我们已经深知异或的运算规则(相同为0,相异为1)以及两个重要结论:1、两个相同的数字异或等于0。2、0与任何数字异或等于该任意数字。因此,我们完全可以先把原数组的所有元素异或起来,再把理论上0-n依次递增的所有元素都异或起来,然后两块再次异或得到的就是缺少的数字。
- 画图展示:
代码如下:
int missingNumber(int* nums, int numsSize){ int n=0; for(int i=0;i<numsSize;i++) { n^=nums[i]; } for(int i=0;i<numsSize+1;i++) { n^=i; } return n; }注意:第二个for循环中循环的次数要建立在numsSize的基础上再加1,因为是缺少了一个数字,所以理论上数组的长度是在原基础上加1的。

- 题二:(旋转数组)
链接:https://leetcode-cn.com/problems/rotate-array/
此题的进阶思想中就明确了使用空间复杂度为O(1)的算法来解决此问题,正文开始
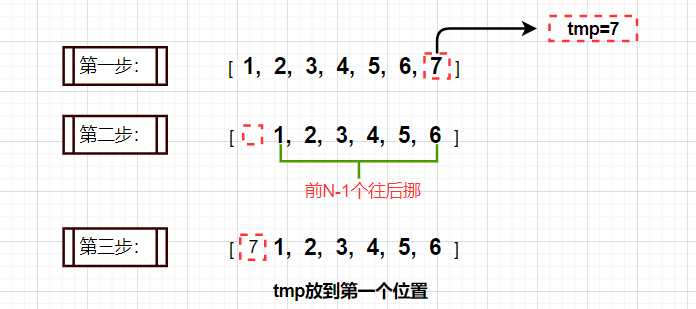
法一:右旋K次,一次移动一个
- 思想:
首先,定义一个变量tmp把数组的最后一个元素保存起来。其次,把前N-1个值往后挪。最后,把tmp的值放到第一个位置。如图所示:
此法时间复杂度为:O(N*K),空间复杂度O(1),此法的空间复杂度满足题意了,但有个风险,就是当K%N=N-1时时间复杂度过大,为O(N^2),所以再看看有无更好方法:
法二: 额外开数组
- 思想:
额外开辟一个新数组,把后K个元素放到新数组前面,再把原数组N-K个元素拷贝到新数组后面。但是此法的时间复杂度是O(N),空间复杂度也是O(N),不符合题意,再换:
法三:三趟逆置
- 思想:
第一趟对它的前N-K个元素逆置,第二趟对它的后K个元素逆置,最后整体逆置。如图所示:
此法非常巧妙,时间复杂度O(N),空间复杂度O(N),符合题意
代码如下:
void reverse(int*nums,int left,int right) { while(left<right) { int tmp=nums[left]; nums[left]=nums[right]; nums[right]=tmp; left++; right--; } } void rotate(int* nums, int numsSize, int k){ k%=numsSize; reverse(nums,0,numsSize-k-1); reverse(nums,numsSize-k,numsSize-1); reverse(nums,0,numsSize-1); }注意:这里当k=7时,相当于全部逆置完了一遍,也就是又回到了原来的样子,是有规律可循的,所以真正逆置的次数为k%=numsSize;


发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/207174.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
