大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
一、前言
现在说数仓,更多的会和数据平台或者基础架构搭上,已经融合到整个基础设施的搭建上。这里呢,我们不说Hadoop各种组件之间的配合,我们就简单说下数仓分层的意义价值和该如何设计分层。
二、数仓建模
说到数仓建模,就得提下经典的2套理论:
-
范式建模
Inmon提出的集线器的自上而下(EDW-DM)的数据仓库架构。 -
维度建模
Kimball提出的总线式的自下而上(DM-DW)的数据仓库架构。
数仓的建模或者分层,其实都是为了更好的去组织、管理、维护数据,实际开发时会整合2种方式去使用,当然,还有些其他的,像Data Vault模型、Anchor模型,暂时还没有应用过,就不说了。
维度建模,一般都会提到星型模型、雪花模型,星型模型做OLAP分析很方便。
三、数仓分层
简单点儿,直接ODS+DM就可以了,将所有数据同步过来,然后直接开发些应用层的报表,这是最简单的了;当DM层的内容多了以后,想要重用,就会再拆分一个公共层出来,变成三层架构,最近看了本阿里的书,《大数据之路》,里面有很多数仓相关的内容,很不错,参考后,目前使用的分层模式如下:
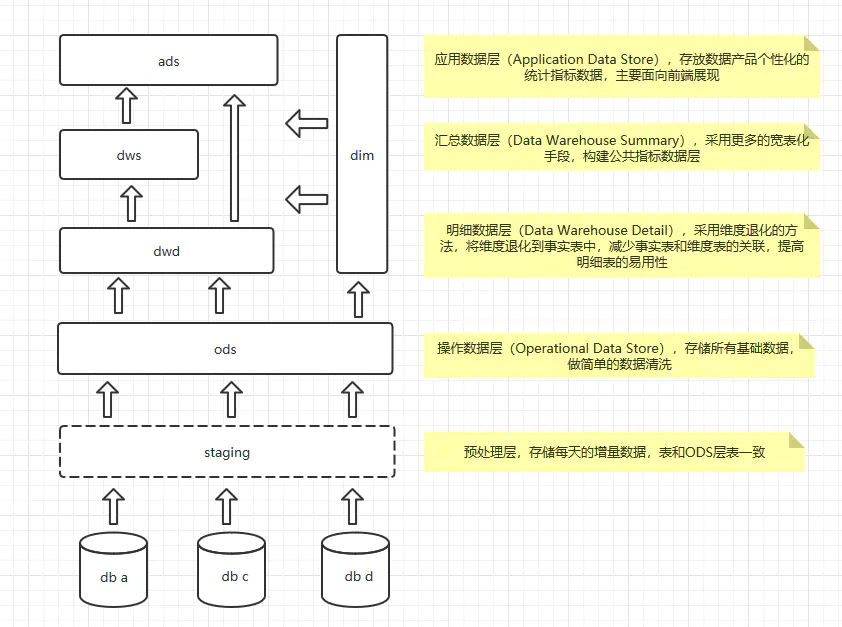

按照这种分层方式,我们的开发重心就在 DWD 层,就是明细数据层,这里主要是一些宽表,存储的还是明细数据;到了 DWS 层,我们就会针对不同的维度,对数据进行聚合了。按道理说,DWS层算是集市层,这里一般按照主题进行划分,属于维度建模的范畴;ADS就是偏应用层,各种报表的输出。
四、数仓的基本特征
数据仓库有4个基本特征:面向主题的、集成的、相对稳定的、记录历史的,而数据仓库的价值正是基于这4个特征体现的。
1、高效的数据组织和管理
面向主题的特性决定了数据仓库拥有业务数据库所无法拥有的高效的数据组织形式,更加完整的数据体系,清晰的数据分类和分层机制。因为所有数据在进入数据仓库之前都经过清洗和过滤,使原始数据不再杂乱无章,基于优化查询的组织形式,有效提高数据获取、统计和分析的效率。
2、时间价值
数据仓库的构建将大大缩短获取信息的时间,数据仓库作为数据的集合,所有的信息都可以从数据仓库直接获取,数据仓库的最大优势在于一旦底层从各类数据源到数据仓库的ETL流程构建成型,那么每天就会有来自各方面的信息通过自动任务调度的形式流入数据仓库,从而使一切基于这些底层信息的数据获取的效率达到迅速提升。
从应用来看,使用数据仓库可以大大提高数据的查询效率,尤其对于海量数据的关联查询和复杂查询,所以数据仓库有利于实现复杂的统计需求,提高数据统计的效率。
3、集成价值
数据仓库是所有数据的集合,包括日志信息、数据库数据、文本数据、外部数据等都集成在数据仓库中,对于应用来说,实现各种不同数据的关联并使多维分析更加方便,为从多角度多层次地数据分析和决策制定提供的可能。
4、历史累积价值
记历史是数据仓库的特性之一,数据仓库能够还原历史时间点上的产品状态、用户状态、用户行为等,以便于能更好的回溯历史,分析历史,跟踪用户的历史行为,更好地比较历史和总结历史,同时根据历史预测未来。
五、数据仓库用途
- 整合公司所有业务数据,建立统一的数据中心
- 产生业务报表,用于作出决策
- 为网站运营提供运营上的数据支持
- 可以作为各个业务的数据源,形成业务数据互相反馈的良性循环
- 分析用户行为数据,通过数据挖掘来降低投入成本,提高投入效果
- 开发数据产品,直接或间接地为公司盈利
六、数仓分层的好处
对数据进行分层的一个主要原因就是希望在管理数据的时候,能对数据有一个更加清晰的掌控,详细来讲,主要有下面几个原因:
- 清晰数据结构:每一个数据分层都有它的作用域,这样我们在使用表的时候能更方便地定位和理解。
- 数据血缘追踪:简单来讲可以这样理解,我们最终给业务呈现的是一张能直接使用的张业务表,但是它的来源有很多,如果有一张来源表出问题了,我们希望能够快速准确地定位到问题,并清楚它的危害范围。
- 减少重复开发:规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算。
- 把复杂问题简单化:将一个复杂的任务分解成多个步骤来完成,每一层只处理单一的步骤,比较简单和容易理解。而且便于维护数据的准确性,当数据出现问题之后,可以不用修复所有的数据,只需要从有问题的步骤开始修复。
- 屏蔽原始数据的异常:屏蔽业务的影响,不必改一次业务就需要重新接入数据。
数据体系中的各个表的依赖就像是电线的流向一样,我们都希望它是规整、流向清晰、便于管理的,如下图。
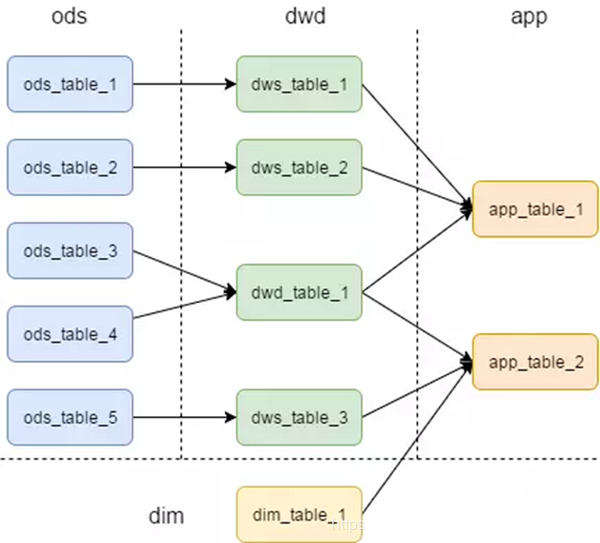
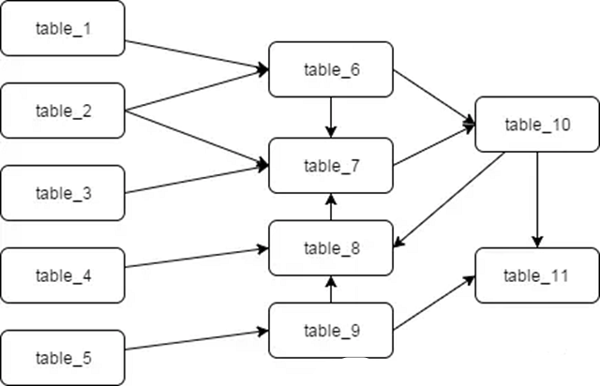
但是,最终的结果大多却是依赖复杂、层级混乱,想梳理清楚一张表的生成途径会比较困难,如下图:
七、如何分层
理论抽象
我们可以从理论上对数仓来做一个抽象,可以把数据仓库分为下面三个层,即:数据运营层、数据仓库层和数据产品层。
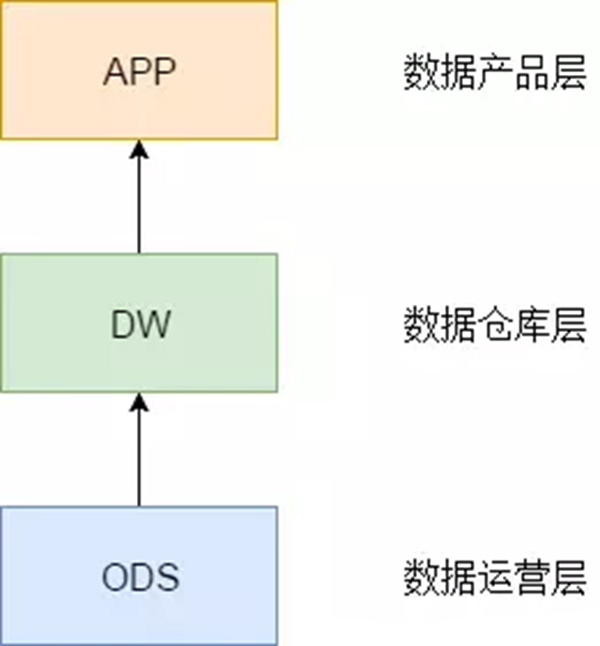
1. 操作数据层(ODS)
“面向主题的”,数据运营层,也叫ODS层,是最接近数据源中数据的一层,数据源中的数据,经过抽取、洗净、传输,也就说传说中的 ETL 之后,装入本层。
本层的数据,总体上大多是按照源头业务系统的分类方式而分类的。但是,这一层面的数据却不等同于原始数据。在源数据装入这一层时,要进行诸如去噪(例如有一条数据中人的年龄是 300 岁,这种属于异常数据,就需要提前做一些处理)、去重(例如在个人资料表中,同一 ID 却有两条重复数据,在接入的时候需要做一步去重)、字段命名规范等一系列操作。
2. 数据仓库层(DW/CDM)
这是数据仓库的主体。在这里,从 ODS 层中获得的数据按照主题建立各种数据模型,在这一层和维度建模会有比较深的联系。
3. 数据产品/集市层(APP/ADS)
这一层是提供为数据产品使用的结果数据。在这里,主要是提供给数据产品和数据分析使用的数据,一般会存放在 ES、MySQL等系统中供线上系统使用,也可能会存在 Hive 或者 Druid 中供数据分析和数据挖掘使用。如我们经常说的报表数据,或者说那种大宽表,一般就放在这里。
另外,我们在实际分层过程中,也可以根据我们的实际数据处理的流程进行分层。
八、举个例子
网上的例子很多,以下是某位大牛早期参与设计的数据分层例子。
我们分析一下当初的想法,以及这种设计的缺陷。
大佬当初的设计总共分了 6 层,其中去掉元数据后,还有5层。下面分析一下当初的一个设计思路。
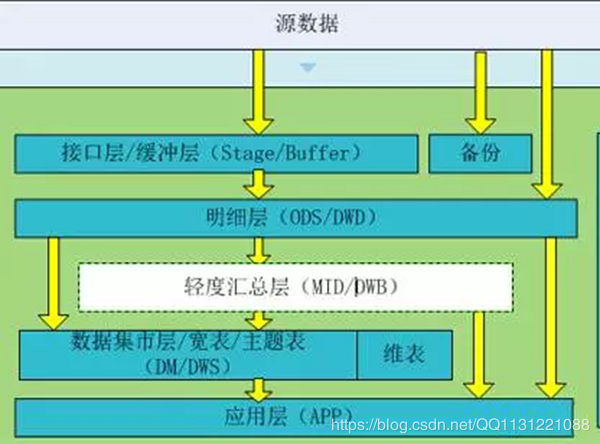
缓冲层(buffer)
概念:又称为接口层(stage),用于存储每天的增量数据和变更数据,如Canal接收的业务变更日志。
数据生成方式:直接从kafka接收源数据,需要业务表每天生成update、delete、inseret数据,只生成insert数据的业务表,数据直接入明细层。
讨论方案:只把canal日志直接入缓冲层,如果其它有拉链数据的业务,也入缓冲层。
日志存储方式:使用Impala外表,parquet文件格式,方便需要MR处理的数据读取。
日志删除方式:长久存储,可只存储最近几天的数据。讨论方案:直接长久存储
表schema:一般按天创建分区库与表命名。库名:buffer、表名:初步考虑格式为:buffer日期业务表名,待定。
明细层(ODS, Operational Data Store,DWD: data warehouse detail)
概念:是数据仓库的细节数据层,是对STAGE层数据进行沉淀,减少了抽取的复杂性,同时ODS/DWD的信息模型组织主要遵循企业业务事务处理的形式,将各个专业数据进行集中,明细层跟stage层的粒度一致,属于分析的公共资源
数据生成方式:部分数据直接来自kafka,部分数据为接口层数据与历史数据合成。
canal日志合成数据的方式待研究。
讨论方案:canal数据的合成方式为:每天把明细层的前天全量数据和昨天新数据合成一个新的数据表,覆盖旧表。同时使用历史镜像,按周/按月/按年 存储一个历史镜像到新表。
日志存储方式:直接数据使用impala外表,parquet文件格式,canal合成数据为二次生成数据,建议使用内表,下面几层都是从impala生成的数据,建议都用内表+静态/动态分区。
日志删除方式:长久存储。
表schema:一般按天创建分区,没有时间概念的按具体业务选择分区字段。
库与表命名:库名:ods、表名:初步考虑格式为ods日期业务表名,待定。
旧数据更新方式:直接覆盖
轻度汇总层(MID或DWB, data warehouse basis)
概念:轻度汇总层数据仓库中DWD层和DM层之间的一个过渡层次,是对DWD层的生产数据进行轻度综合和汇总统计(可以把复杂的清洗,处理包含,如根据PV日志生成的会话数据)。轻度综合层与DWD的主要区别在于二者的应用领域不同,DWD的数据来源于生产型系统,并未满意一些不可预见的需求而进行沉淀;轻度综合层则面向分析型应用进行细粒度的统计和沉淀。
数据生成方式:由明细层按照一定的业务需求生成轻度汇总表。明细层需要复杂清洗的数据和需要MR处理的数据也经过处理后接入到轻度汇总层。
日志存储方式:内表,parquet文件格式。
日志删除方式:长久存储。
表schema:一般按天创建分区,没有时间概念的按具体业务选择分区字段。
库与表命名:库名:dwb,表名:初步考虑格式为:dwb日期业务表名,待定。
旧数据更新方式:直接覆盖。
主题层(DM,data market或DWS, data warehouse service)
概念:又称数据集市或宽表。按照业务划分,如流量、订单、用户等,生成字段比较多的宽表,用于提供后续的业务查询,OLAP分析,数据分发等。
数据生成方式:由轻度汇总层和明细层数据计算生成。
日志存储方式:使用impala内表,parquet文件格式。
日志删除方式:长久存储。
表schema:一般按天创建分区,没有时间概念的按具体业务选择分区字段。
库与表命名:库名:dm、表名:初步考虑格式为:dm日期业务表名,待定。
旧数据更新方式:直接覆盖。
应用层(App)
概念:应用层是根据业务需要,由前面三层数据统计而出的结果,可以直接提供查询展现,或导入至Mysql中使用。
数据生成方式:由明细层、轻度汇总层,数据集市层生成,一般要求数据主要来源于集市层。
日志存储方式:使用impala内表,parquet文件格式。
日志删除方式:长久存储。
表schema:一般按天创建分区,没有时间概念的按具体业务选择分区字段。
库与表命名:库名:暂定apl,另外根据业务不同,不限定一定要一个库。
旧数据更新方式:直接覆盖。
九、如何更优雅一些
前面提到的一种设计其实相对来讲已经很详细了,但是可能层次会有一点多,而且在区分一张表到底该存放在什么位置的时候可能还有不小的疑惑。我们可以再设计一套数据仓库的分层,同时在前面的基础上加上维表和一些临时表的考虑,来让我们的方案更优雅一些。
下图,做了一些小的改动,我们去掉了上一节的Buffer层,把数据集市层和轻度汇总层放在同一个层级上,同时独立出来了维表和临时表。
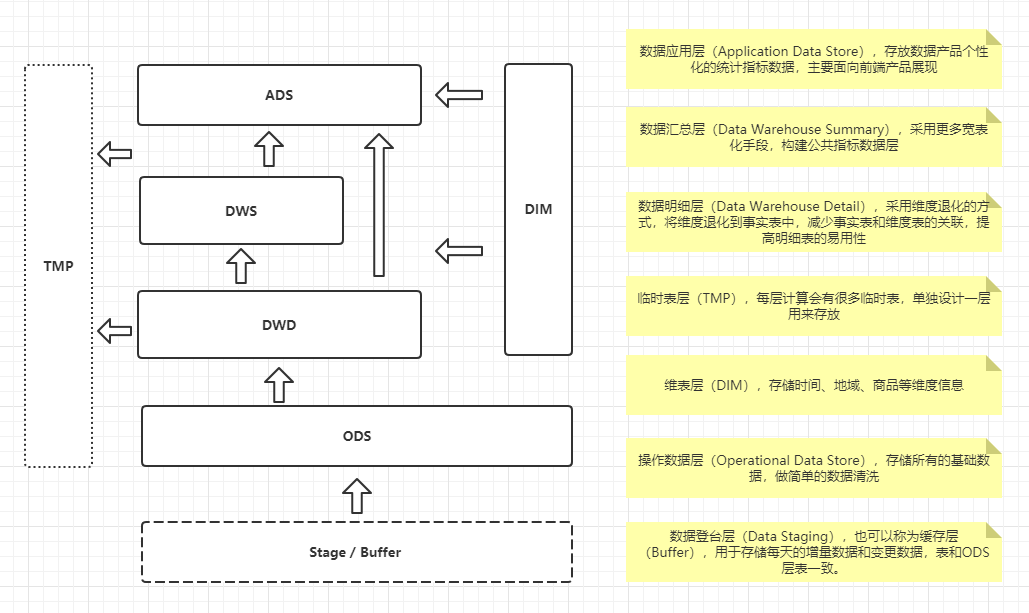
这里解释一下DWS、DWD、DIM和TMP的作用。
DWS:轻度汇总层,从ODS层中对用户的行为做一个初步的汇总,抽象出来一些通用的维度:时间、ip、id,并根据这些维度做一些统计值,比如用户每个时间段在不同登录ip购买的商品数等。这里做一层轻度的汇总会让计算更加的高效,在此基础上如果计算仅7天、30天、90天的行为的话会快很多。我们希望80%的业务都能通过我们的DWS层计算,而不是ODS。
DWD:这一层主要解决一些数据质量问题和数据的完整度问题。比如用户的资料信息来自于很多不同表,而且经常出现延迟丢数据等问题,为了方便各个使用方更好的使用数据,我们可以在这一层做一个屏蔽。
DIM:这一层比较单纯,举个例子就明白,比如国家代码和国家名、地理位置、中文名、国旗图片等信息就存在DIM层中。
TMP:每一层的计算都会有很多临时表,专设一个DWTMP层来存储我们数据仓库的临时表。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/203710.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
