大家好,又见面了,我是你们的朋友全栈君。
造成雪崩的真实场景
1.4.1 服务提供者不可用
-
硬件故障:如网络故障、硬盘损坏等。 -
程序的 bug:如算法需要占用大量 CPU 的计算时间导致 CPU 使用率过高。 -
缓存击穿:比如应用刚重启,短时间内缓存是失效的,导致大量请求直接访问到了数据库,数据库不堪重负,服务不可用。 -
秒杀和大促:服务短时间承载不了那么多请求量。
1.4.2 重试加大流量
-
用户连续重试:比如用户看到界面上没有响应,所以又操作了一遍,结果又增加了一倍请求量。 -
程序重试机制:比如代码中有多次重试的逻辑,一次失败后,过几秒后再重试,重试个三次就取消重试,走异常处理分支了。也是增加了请求量。
五、如何防止雪崩
方案
出问题前预防:限流、主动降级、隔离
出问题后修复:熔断、被动降级
「本篇主要来讲解熔断机制。」 后续几篇会讲解其他方案。
六、熔断原理和算法
1.6.1 熔断概念


熔断这个概念来源于电路系统中的保险丝熔断。当电流过大时,保险丝熔断,防止因电流过大损坏电器元器件,或因电流过大,导致元器件热度过高,发生火灾。

「物理公式」 电功率 P = I^2 * R,I 代表电流,元器件的电阻 R 不变的情况下,电流越大,电功率约大,电阻做的电功大部分都用来发热了,所以电功率越大,发热越严重。(还好高中物理没忘。)
放到我们系统中,怎么理解熔断?
如果在某段时间内,调用某个服务非常慢甚至超时,就可以将这个服务熔断,后续其他服务再调用这个服务就直接返回,告诉其他服务:「“已经熔断了,你别调用我了,过段时间再来试下吧。”」
1.6.2 如何熔断
「熔断有个原则」 一段时间内,统计失败的次数或者失败请求的占比超过一定阈值,就进行熔断。
详细的原理如下图所示:
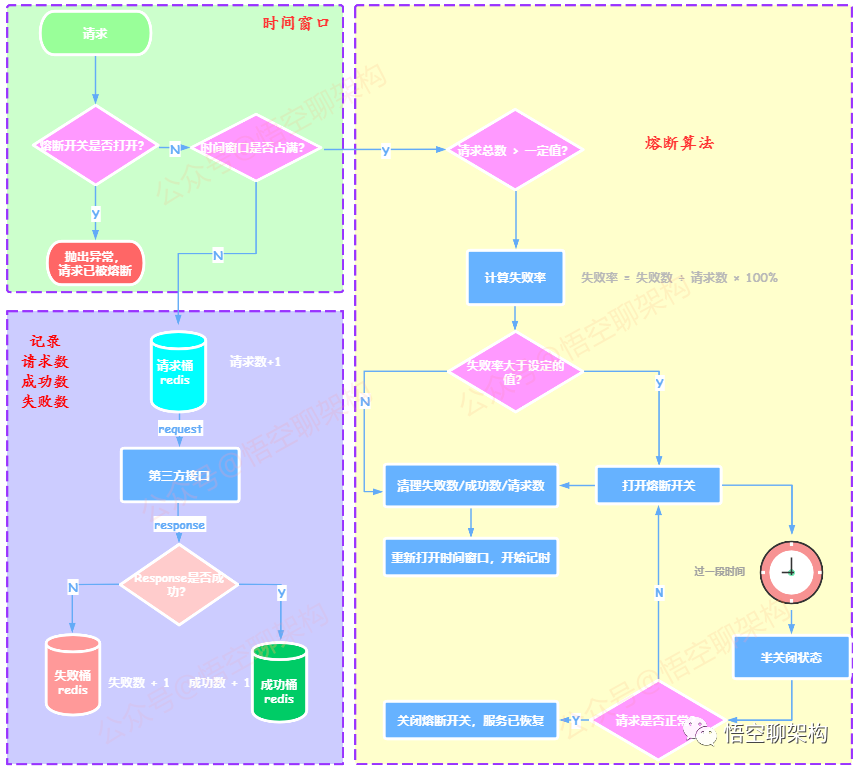
1.6.3 统计请求的算法
-
请求访问到后台服务后,首先判断熔断开关是否打开。
-
如果熔断开关
已打开,则表明当前请求不能被处理。 -
如果熔断开关
未打开,则判断时间窗口是否已满。 -
如果时间窗口
未满,则请求桶中的请求数加 1。 -
如果返回的响应有异常,则失败桶的
失败数加 1,如果返回的响应没有异常,则成功桶的成功数加 1。 -
如果时间窗口
已满,则开始判断是否需要熔断。
1.6.4 熔断的恢复算法
-
当熔断后,开关切换到
断开状态。 -
过一段时间后,开关切换为
半断开状态(Half-Open)。半断开状态下,允许对应用程序的一定数量的请求可以去调用服务,如果调用成功,则认为服务可以正常访问了,于是将开关切换为闭合状态。 -
如果半断开状态下,还是有调用失败的情况,则认为服务还没有恢复,开关从半断开状态切换到
断开状态。
1.6.5 统计失败率的时间窗口
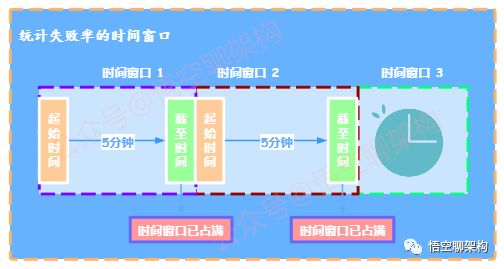
-
时间窗口可以比喻为人坐在窗户边,看外面来往的车辆,一定时间内从窗户外经过的车辆。 -
每次请求,都会判断时间窗口是否已满(如5分钟),如果时间窗口已满,则重新开始计时,且清理请求数/成功数/失败数。
-
注意:第一次开始的起始时间默认为当前时间。
1.6.6 尝试恢复服务的时间窗口
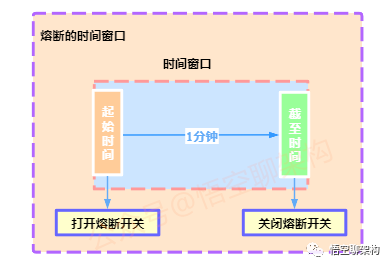
-
开关为断开的状态,经过一定时间后,比如 1 分钟,设置为
半断开的状态,尝试发送请求检测服务是否恢复。 -
如果已恢复,则切换状态为关闭状态。如果未恢复,则切换状态为
断开的状态,经过 1 分钟后,重复上面的步骤。 -
这里的时间窗口可以根据环境的运行状态进行动态调整,比如第一次是 1 分钟,第二次是 3 分钟,第三次是 10 分钟。
七、熔断中间件
肯定有人会问了,你这上面讲的原理,难道还真的自己去写这套算法?
「答案:是的,项目中我们自己造了一个轮子:熔断器。」
但这里我不推荐大家这么做。市面上还有更优秀的开源组件供大家使用,比如阿里系的 Sentinel(推荐),Netflix 的 Hystrix(已停止更新)。
当然 Sentinel 就不在这篇讲了,后续奉上~
最后
对于很多Java工程师而言,想要提升技能,往往是自己摸索成长,不成体系的学习效果低效漫长且无助。
整理的这些资料希望对Java开发的朋友们有所参考以及少走弯路,本文的重点是你有没有收获与成长,其余的都不重要,希望读者们能谨记这一点。
再免费分享一波我的Java面试真题+视频学习详解+技能进阶书籍
这一点。**
再免费分享一波我的Java面试真题+视频学习详解+技能进阶书籍

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/137439.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
