大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定

本文主要讲“变量选择”“模型开发”“评分卡创建和刻度”
变量分析
首先,需要确定变量之间是否存在共线性,若存在高度相关性,只需保存最稳定、预测能力最高的那个。需要通过 VIF(variance inflation factor)也就是 方差膨胀因子进行检验。
变量分为连续变量和分类变量。在评分卡建模中,变量分箱(binning)是对连续变量离散化(discretization)的一种称呼。要将logistic模型转换为标准评分卡的形式,这一环节是必须完成的。信用评分卡开发中一般有常用的等距分段、等深分段、最优分段。
单因子分析,用来检测各变量的预测强度,方法为WOE、IV;
WOE
WOE(weight of Evidence)字面意思证据权重,对分箱后的每组进行。假设good为好客户(未违约),bad为坏客户(违约)。
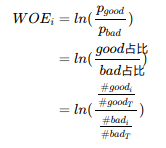

#good(i)表示每组中标签为good的数量,#good(T)为good的总数量;bad相同。
这里说一下,有的地方计算WOE时使用的是 b a d 占 比 g o o d 占 比 \frac{bad占比}{good占比} good占比bad占比的,其实是没有影响的,因为我们计算WOE的目的其实是通过WOE去计算IV,从而达到预测的目的。后面IV计算中,会通过相减后相乘的方式把负号给抵消掉。所以不管谁做分子,谁做分母,最终的IV预测结果是不变的。
IV
IV(information value)衡量的是某一个变量的信息量,公式如下:
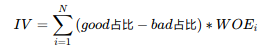
![]()
N为分组的组数;
IV可用来表示一个变量的预测能力。
| IV | 预测能力 |
|---|---|
| <0.03 | 无预测能力 |
| 0.03~0.09 | 低 |
| 0.1~0.29 | 中 |
| 0.3~0.49 | 高 |
| >=0.5 | 极高 |
根据IV值来调整分箱结构并重新计算WOE和IV,直到IV达到最大值,此时的分箱效果最好。
分组一般原则
- 组间差异大
- 组内差异小
- 每组占比不低于5%
- 必须有好、坏两种分类
举例说明
例如按年龄分组,一般进行分箱,我们都喜欢按照少年、青年、中年、老年几大类进行分组,但效果真的不一定好:
| Age | good | bad | WOE |
|---|---|---|---|
| <18 | 50 | 40 | l n ( 50 / 330 40 / 220 ) = − 0.182321556793955 ln(\frac{50/330}{40/220}) = -0.182321556793955 ln(40/22050/330)=−0.182321556793955 |
| 18~30 | 100 | 60 | l n ( 100 / 330 60 / 220 ) = 0.105360515657826 ln(\frac{100/330}{60/220}) = 0.105360515657826 ln(60/220100/330)=0.105360515657826 |
| 30~60 | 100 | 80 | l n ( 100 / 330 80 / 220 ) = − 0.182321556793955 ln(\frac{100/330}{80/220}) = -0.182321556793955 ln(80/220100/330)=−0.182321556793955 |
| >60 | 80 | 40 | l n ( 80 / 330 40 / 220 ) = 0.287682072451781 ln(\frac{80/330}{40/220}) = 0.287682072451781 ln(40/22080/330)=0.287682072451781 |
| ALL | 330 | 220 |
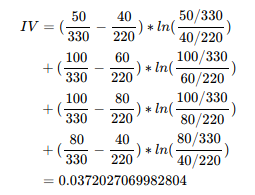
![]()
根据IV值可以看出,预测能力低,建议重新调整分箱。
建立模型
先进行数据划分,一般70%训练集、30%测试集。训练集用于训练模型,测试集用于检测训练后的模型。
一般采用Logistic Regression建立模型,训练模型。将建好的模型对待测样本进行预测。
评分卡
评分卡计算方法
odds为good用户概率(p)与bad用户概率(1-p)的比值。
o d d s = 好 客 户 概 率 坏 客 户 概 率 = p 1 − p odds=\frac{好客户概率}{坏客户概率}=\frac{p}{1-p} odds=坏客户概率好客户概率=1−pp
评分卡设定的分值刻度可以通过将分值表示为比率对数的线性表达式来定义。公式如下:
s c o r e 总 = A + B ∗ l n ( o d d s ) score_总=A+B*ln(odds) score总=A+B∗ln(odds)
注:若odds是 好 客 户 概 率 坏 客 户 概 率 \frac{好客户概率}{坏客户概率} 坏客户概率好客户概率,odds应取倒数,再经过 l n ln ln转换则B前面是减号。所以有的地方此公式B前为负号。
设置比率为 θ 0 \theta_0 θ0(也就是odds)的特定点分值为 P 0 P_0 P0,比率为 2 θ 0 2\theta_0 2θ0的点的分值为 P 0 + P D O P_0+PDO P0+PDO。带入上面公式可得到:
{ P 0 = A + B l n ( θ 0 ) P 0 + P D O = A + B l n ( 2 θ 0 ) \begin{cases} P_0 &= A+Bln(\theta_0) \\ P_0+PDO &= A+Bln(2\theta_0) \end{cases} {
P0P0+PDO=A+Bln(θ0)=A+Bln(2θ0)
求解上述公式,可以得到A、B值:
{ B = P D O l n 2 A = P 0 − B l n ( θ 0 ) \begin{cases} B &= \frac{PDO}{ln2} \\ A &= P_0-Bln(\theta_0) \end{cases} {
BA=ln2PDO=P0−Bln(θ0)
P 0 P_0 P0 和 P D O PDO PDO 的值都是已知常数,可以设置 P 0 = 600 P_0 = 600 P0=600 和 P D O = 20 PDO = 20 PDO=20,
可以计算出A、B值。
这里 P 0 P_0 P0 和 P D O PDO PDO 主要是根据你想要分数落在一个什么范围内,然后进行人为设定,不用太纠结取值的意义。
分值分配
在实际的应用中,我们会计算出每个变量的各分箱对应的分值。新用户产生时,对应到每个分箱的值,将这些值相加,最后加上初始基础分,得到最终的结果。
如果用户某个变量发生改变,由一个分箱变成另一个,只需将更新后所在分箱的值做替换,再重新相加即可得到新的总分。
我们都知道,假设模型结果为p,根据Logistic Regression计算公式有:
p = 1 1 + e − θ T x p = \frac{1}{1+e^{-\theta^Tx}} p=1+e−θTx1
经过转换得到
l n ( p 1 − p ) = θ T x ln(\frac{p}{1-p})=\theta^Tx ln(1−pp)=θTx
由于上面提到的公式
l n ( p 1 − p ) = l n ( o d d s ) ln(\frac{p}{1-p})=ln(odds) ln(1−pp)=ln(odds)
所以
l n ( o d d s ) = θ T x = w 0 + w 1 x 1 + ⋅ ⋅ ⋅ + w n x n ln(odds)=\theta^Tx =w_0+w_1x_1+···+w_nx_n ln(odds)=θTx=w0+w1x1+⋅⋅⋅+wnxn
这里带入评分卡公式,
s c o r e 总 = A + B ∗ ( θ T x ) = A + B ∗ ( w 0 + w 1 x 1 + ⋅ ⋅ ⋅ + w n x n ) score_总 = A+B*(\theta^Tx)=A+B*(w_0+w_1x_1+···+w_nx_n) score总=A+B∗(θTx)=A+B∗(w0+w1x1+⋅⋅⋅+wnxn)
= ( A + B ∗ w 0 ) + B ∗ w 1 x 1 + ⋅ ⋅ ⋅ + B ∗ w n x n =(A+B*w_0)+B*w_1x_1+···+B*w_nx_n =(A+B∗w0)+B∗w1x1+⋅⋅⋅+B∗wnxn
这里 w 1 , w 2 , . . . , w n w_1,w_2,…,w_n w1,w2,...,wn是Logistic Regression中不同变量 x 1 , x 2 , . . . , x n x_1,x_2,…,x_n x1,x2,...,xn的系数。 w 0 w_0 w0是截距。
( A + B ∗ w 0 ) (A+B*w_0) (A+B∗w0)为基础分数, B ∗ w 1 x 1 , ⋅ ⋅ ⋅ , B ∗ w n x n B*w_1x_1,···,B*w_nx_n B∗w1x1,⋅⋅⋅,B∗wnxn为每个变量对应分配到的分数。
之前步骤中每个变量都有进行分箱操作,分为若干类。所以下一步的话,把每个变量对应的分数,分别乘以变量中每个分箱的WOE,得到每个分箱的评分结果。
| 变量 | 分箱类别 | 分值 |
|---|---|---|
| 基础分数 | – | ( A + B ∗ w 0 ) (A+B*w_0) (A+B∗w0) |
| x 1 x_1 x1 | 1 2 … i i i |
( B ∗ w 1 ) ∗ W O E 11 (B*w_1)*WOE_{11} (B∗w1)∗WOE11 ( B ∗ w 1 ) ∗ W O E 12 (B*w_1)*WOE_{12} (B∗w1)∗WOE12 ··· ( B ∗ w 1 ) ∗ W O E 1 i (B*w_1)*WOE_{1i} (B∗w1)∗WOE1i |
| x 2 x_2 x2 | 1 2 … j j j |
( B ∗ w 2 ) ∗ W O E 21 (B*w_2)*WOE_{21} (B∗w2)∗WOE21 ( B ∗ w 2 ) ∗ W O E 22 (B*w_2)*WOE_{22} (B∗w2)∗WOE22 ··· ( B ∗ w 2 ) ∗ W O E 2 j (B*w_2)*WOE_{2j} (B∗w2)∗WOE2j |
| ··· | ··· | ··· |
| x n x_n xn | 1 2 … k k k |
( B ∗ w n ) ∗ W O E n 1 (B*w_n)*WOE_{n1} (B∗wn)∗WOEn1 ( B ∗ w n ) ∗ W O E n 2 (B*w_n)*WOE_{n2} (B∗wn)∗WOEn2 ··· ( B ∗ w n ) ∗ W O E n k (B*w_n)*WOE_{nk} (B∗wn)∗WOEnk |
以上步骤都完成后,假如新产生一个用户,我们只需将此用户每个变量对应到各分箱中得到其对应的WOE值,再根据上面的公式计算出这个样本在每个变量下的分数。最后将所有变量对应的分数相加,即为最终评分结果。
最后说一下,特征选择方面,并不是维度越多越好。一个评分卡中,一般不超过15个维度。可根据Logistic Regression模型系数来确定每个变量的权重,保留权重高的变量。通过协方差计算的相关性大于0.7的变量一般只保留IV值最高的那一个。
引用
《信用风险评分卡研究》Mamdouh Refaat著
《互联网金融时代消费信贷评分建模与应用》单良著
手把手教你用R语言建立信用评分模型
《统计学习方法》李航著
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/200763.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...