大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
1. LSTM模型 输入参数理解
(Long Short-Term Memory)
lstm是RNN模型的一种变种模式,增加了输入门,遗忘门,输出门。
LSTM也是在时间序列预测中的常用模型。
小白我也是从这个模型入门来开始机器学习的坑。
LSTM的基本概念与各个门的解释已经有博文写的非常详细:推荐博文:【译】理解LSTM(通俗易懂版)
这篇文章写的非常详细,生动,概念解释的非常清楚。我也是从这个博文里开始理解的。
2. 模型参数
- 模型的调参是模型训练中非常重要的一部分,调整参数前的重要一步就是要理解参数是什么意思,才能帮助更好的调整参数。
- 但是发现在一些实战模型将代码直接放在那里,但是基本参数只是把定义写在哪里,没有生动的解释,我一开始看的时候也是一脸懵逼。
- 在我寻找着写参数的额定义的时候,往往看不到让小白一眼就能明白的解释。
- 希望从一个小白的角度来讲解我眼中的这些参数是什么意思,如果有不对,还请指出交流。
3. LSTM 的参数输入格式
1. 一般表示为[batch_size, time_step, input_size]
2. 中文解释为[每一次feed数据的行数,时间步长,输入变量个数]
3.1 分开讲解,input_size
- 如果你使用7个自变量来预测1个因变量,那么input_size=7,output_size=1
- 如果你使用8个自变量来预测3个因变量,那么input_size=8,output_size=3
这个还是比较好理解的,你的输入数据,想要通过什么变量预测什么变量应该是比较清楚的。
难点是另外两个参数的区别。
3.2 分开讲解,batch_size
- 如果你的数据有10000行,训练100次把所有数据训练完,那么你的batch_size=10000/100=100
- 如果你的数据有20000行,同样训练100次把所有数据训练完,那么你的batch_size=20000/100=200
- 如果你的数据有20000行,训练50次把所有数据训练完,那么你的batch_size=20000/50=400
- 以此类推
- 不过只是举个例子,实际的情况要看你的数据样本,一般的batch_size小于100,来使你的训练结果更好,一次feed太多行数据,模型容易吃撑,消化不良,可能需要健胃消食片,哈哈哈哈
3.3 分开讲解, time_step
最最最最难理解的就是这个time_step了,我也是琢磨了好久。
- 首先要知道,time_step是指的哪个过程?
是不是看到的图都是在画,输入了什么,遗忘了什么,输出了什么,以为每个细胞状态都是1个time_step?
如果这样的话,那么恭喜你,你和我一样,都是想错了,其实那些一串的流程细胞状态图都是在1个time_step!都是在1个time_step!都是在1个time_step! - 是不是很惊讶,很奇怪?
- 那讲的是time_step的内部进行的,而不是在time_step之间。
- 换句话说,所谓的t-1的遗留状态也是在一个time_step里面的事情,t多少取决于time_step的取值。
此时,再来看看time_step的本身含义,时间步长,时间步长,那么一定是是和时间有关系啊!!!
4. 重点
4.1 batch_size与time_step
- 之前的batch_size中只是规定了一个每次feed多少行数据进去,并没有涵盖一个时间的概念进去,
- 而这个参数刚好就是对于时间的限制,毕竟你是做时间序列预测,所以才多了这个参数。
- 换句话说,就是在一个batch_size中,你要定义一下每次数据的时间序列是多少?
- 如果你的数据都是按照时间排列的,batch_size是100的话,time_step=10
- 在第1次训练的时候,是用前100行数据进行训练,而在这其中每次给模型10个连续时间序列的数据。
- 那你是不是以为应该是1-10,11-20,21-30,这样把数据给模型?还是不对,请看下图。
4.2 [batch_size, time_step, input_size]=[30,5,7]
time_step=n, 就意味着我们认为每一个值都和它前n个值有关系


- 如果 [batch_size, time_step, input_size]=[30,5,7]
- 那么,上图中,黑色框代表的就是一个batch_size中所含有的数据的量。
- 那么,从上到下的3个红色框就为 time_step为5的时候,每次细胞输入门所输入的数据量。
- 那么,列B~列H,一共7列,就为 input_size
4.3 举例
再看下图
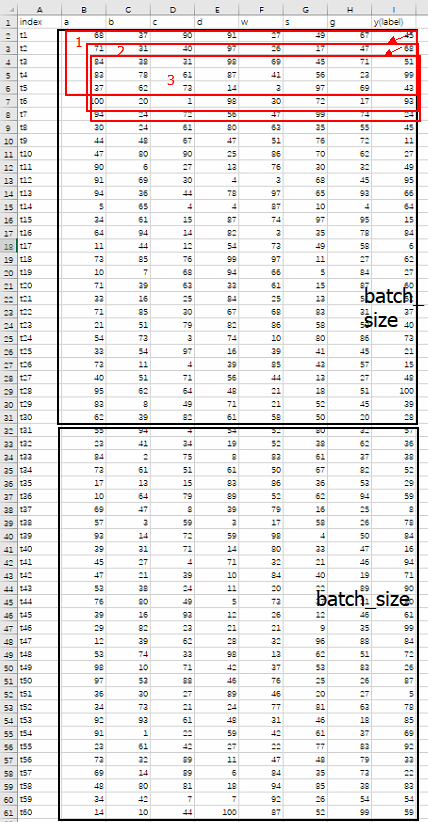
time_step=n, 就意味着我们认为每一个值都和它前n个值有关系
- 假如没有time_step这个参数, [input_size=7,batch_size=30],一共只需要1次就能训练完所有数据。
- 如果有,那么变成了 [input_size=7,batch_size=30, time_step=5],需要30-5+1=26,需要26次数据连续喂给模型,中间不能停。
- 在26次中每一次都要把上一次产生的y,与这一次的5行连续时间序列数据一起feed进去,再产生新的y
- 以此往复,直到此个batch_size 结束。
结语
1. input_size 是根据你的训练问题而确定的。
2. time_step是LSTM神经网络中的重要参数,time_step在神经网络模型建好后一般就不会改变了。
3. 与time_step不同的是,batch_size是模型训练时的训练参数,在模型训练时可根据模型训练的结果以及loss随时进行调整,达到最优。
非常感谢以下作者,让我慢慢理解了参数意义,才有了以上学习笔记!
参考资料:
菜鸡的自我拯救,RNN 参数理解
视觉弘毅,RNN之多层LSTM理解
MichaelLiu_dev,理解LSTM(通俗易懂版)
Andrej Karpathy,The Unreasonable Effectiveness of Recurrent Neural Networks
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/197633.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
