大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
上一篇关于TransUnet的GitHub复现,大家反映效果不好,调参也不好调,我把模型单独拿出来,放到另外一个框架,供大家参考学习(上一篇链接:https://blog.csdn.net/qq_20373723/article/details/115548900)
我这里训练了20个epoch,下面先给出效果正常的情况:
原图


预测结果

整体代码结构:
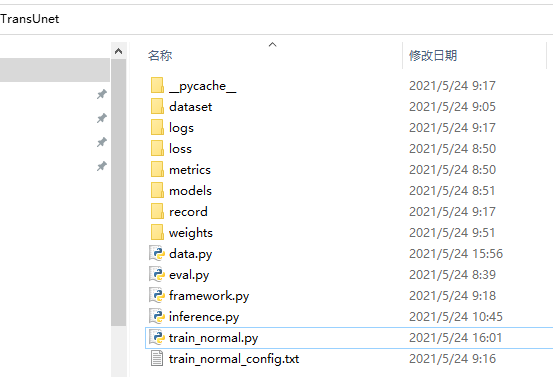
注意一下代码结构和文件名字记得保持一样,没有的文件手动新建一下
1.数据准备,文件名字请务必保持一致,不过你也可以去代码里改
一级目录,红线的三个,其它不用管

二级目录
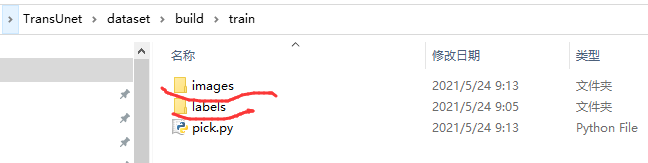
三级目录就分别是图像、标签了,二者名字保持一致,标签值为0和255,代码里改也行
2.数据加载代码data.py
""" Based on https://github.com/asanakoy/kaggle_carvana_segmentation """
import torch
import torch.utils.data as data
from torch.autograd import Variable as V
from PIL import Image
import cv2
import numpy as np
import os
import scipy.misc as misc
def randomHueSaturationValue(image, hue_shift_limit=(-180, 180),
sat_shift_limit=(-255, 255),
val_shift_limit=(-255, 255), u=0.5):
if np.random.random() < u:
image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
h, s, v = cv2.split(image)
hue_shift = np.random.randint(hue_shift_limit[0], hue_shift_limit[1]+1)
hue_shift = np.uint8(hue_shift)
h += hue_shift
sat_shift = np.random.uniform(sat_shift_limit[0], sat_shift_limit[1])
s = cv2.add(s, sat_shift)
val_shift = np.random.uniform(val_shift_limit[0], val_shift_limit[1])
v = cv2.add(v, val_shift)
image = cv2.merge((h, s, v))
#image = cv2.merge((s, v))
image = cv2.cvtColor(image, cv2.COLOR_HSV2BGR)
return image
def randomShiftScaleRotate(image, mask,
shift_limit=(-0.0, 0.0),
scale_limit=(-0.0, 0.0),
rotate_limit=(-0.0, 0.0),
aspect_limit=(-0.0, 0.0),
borderMode=cv2.BORDER_CONSTANT, u=0.5):
if np.random.random() < u:
height, width, channel = image.shape
angle = np.random.uniform(rotate_limit[0], rotate_limit[1])
scale = np.random.uniform(1 + scale_limit[0], 1 + scale_limit[1])
aspect = np.random.uniform(1 + aspect_limit[0], 1 + aspect_limit[1])
sx = scale * aspect / (aspect ** 0.5)
sy = scale / (aspect ** 0.5)
dx = round(np.random.uniform(shift_limit[0], shift_limit[1]) * width)
dy = round(np.random.uniform(shift_limit[0], shift_limit[1]) * height)
cc = np.math.cos(angle / 180 * np.math.pi) * sx
ss = np.math.sin(angle / 180 * np.math.pi) * sy
rotate_matrix = np.array([[cc, -ss], [ss, cc]])
box0 = np.array([[0, 0], [width, 0], [width, height], [0, height], ])
box1 = box0 - np.array([width / 2, height / 2])
box1 = np.dot(box1, rotate_matrix.T) + np.array([width / 2 + dx, height / 2 + dy])
box0 = box0.astype(np.float32)
box1 = box1.astype(np.float32)
mat = cv2.getPerspectiveTransform(box0, box1)
image = cv2.warpPerspective(image, mat, (width, height), flags=cv2.INTER_LINEAR, borderMode=borderMode,
borderValue=(
0, 0,
0,))
mask = cv2.warpPerspective(mask, mat, (width, height), flags=cv2.INTER_LINEAR, borderMode=borderMode,
borderValue=(
0, 0,
0,))
return image, mask
def randomHorizontalFlip(image, mask, u=0.5):
if np.random.random() < u:
image = cv2.flip(image, 1)
mask = cv2.flip(mask, 1)
return image, mask
def randomVerticleFlip(image, mask, u=0.5):
if np.random.random() < u:
image = cv2.flip(image, 0)
mask = cv2.flip(mask, 0)
return image, mask
def randomRotate90(image, mask, u=0.5):
if np.random.random() < u:
image=np.rot90(image)
mask=np.rot90(mask)
return image, mask
def default_loader(img_path, mask_path):
img = cv2.imread(img_path)
# print("img:{}".format(np.shape(img)))
img = cv2.resize(img, (448, 448))
mask = cv2.imread(mask_path, cv2.IMREAD_GRAYSCALE)
mask = 255. - cv2.resize(mask, (448, 448))
img = randomHueSaturationValue(img,
hue_shift_limit=(-30, 30),
sat_shift_limit=(-5, 5),
val_shift_limit=(-15, 15))
img, mask = randomShiftScaleRotate(img, mask,
shift_limit=(-0.1, 0.1),
scale_limit=(-0.1, 0.1),
aspect_limit=(-0.1, 0.1),
rotate_limit=(-0, 0))
img, mask = randomHorizontalFlip(img, mask)
img, mask = randomVerticleFlip(img, mask)
img, mask = randomRotate90(img, mask)
mask = np.expand_dims(mask, axis=2)
#
# print(np.shape(img))
# print(np.shape(mask))
img = np.array(img, np.float32).transpose(2,0,1)/255.0 * 3.2 - 1.6
mask = np.array(mask, np.float32).transpose(2,0,1)/255.0
mask[mask >= 0.5] = 1
mask[mask <= 0.5] = 0
#mask = abs(mask-1)
return img, mask
def read_own_data(root_path, mode = 'train'):
images = []
masks = []
image_root = os.path.join(root_path, mode + '/images')
gt_root = os.path.join(root_path, mode + '/labels')
for image_name in os.listdir(gt_root):
image_path = os.path.join(image_root, image_name)
label_path = os.path.join(gt_root, image_name)
images.append(image_path)
masks.append(label_path)
return images, masks
def own_data_loader(img_path, mask_path):
img = cv2.imread(img_path)
mask = cv2.imread(mask_path, 0)
img = randomHueSaturationValue(img,
hue_shift_limit=(-30, 30),
sat_shift_limit=(-5, 5),
val_shift_limit=(-15, 15))
img, mask = randomShiftScaleRotate(img, mask,
shift_limit=(-0.1, 0.1),
scale_limit=(-0.1, 0.1),
aspect_limit=(-0.1, 0.1),
rotate_limit=(-0, 0))
img, mask = randomHorizontalFlip(img, mask)
img, mask = randomVerticleFlip(img, mask)
img, mask = randomRotate90(img, mask)
mask = np.expand_dims(mask, axis=2)
img = np.array(img, np.float32) / 255.0 * 3.2 - 1.6
mask = np.array(mask, np.float32) / 255.0
mask[mask >= 0.5] = 1
mask[mask < 0.5] = 0
img = np.array(img, np.float32).transpose(2, 0, 1)
mask = np.array(mask, np.float32).transpose(2, 0, 1)
return img, mask
def own_data_test_loader(img_path, mask_path):
img = cv2.imread(img_path)
mask = cv2.imread(mask_path, 0)
return img, mask
class ImageFolder(data.Dataset):
def __init__(self,root_path,mode='train'):
self.root = root_path
self.mode = mode
self.images, self.labels = read_own_data(self.root, self.mode)
def __getitem__(self, index):
# img, mask = default_DRIVE_loader(self.images[index], self.labels[index])
if self.mode == 'test':
img, mask = own_data_test_loader(self.images[index], self.labels[index])
else:
img, mask = own_data_loader(self.images[index], self.labels[index])
img = torch.Tensor(img)
mask = torch.Tensor(mask)
return img, mask
def __len__(self):
assert len(self.images) == len(self.labels), 'The number of images must be equal to labels'
return len(self.images)
3.训练代码train_normal.py
import torch
import torch.optim as optim
from torch.optim import lr_scheduler
import torch.nn as nn
import torch.utils.data as data
import torch.nn.functional as F
from torch.autograd import Variable as V
import cv2
import os
import math
import warnings
from tqdm import tqdm
import numpy as np
from time import time
from shutil import copyfile, move
from models.networks.TransUnet import get_transNet
from framework import MyFrame
from loss.dice_bce_loss import Dice_bce_loss
from loss.diceloss import DiceLoss
from metrics.iou import iou_pytorch
from eval import eval_func, eval_new
from data import ImageFolder
from inference import TTAFrame
from tensorboardX import SummaryWriter
# os.environ["CUDA_VISIBLE_DEVICES"] = "0"
os.environ["KMP_DUPLICATE_LIB_OK"]='True'
def train(Model = None):
config_file='train_normal_config.txt'
dirs=[]
for line in open(config_file):
dirs.append(line.split()[0])
data_root = dirs[0]
data_root = data_root.replace('\\','/')
pre_model = dirs[1]
pre_model= pre_model.replace('\\','/')
bs_p_card = dirs[2]
bs_p_card = bs_p_card.replace('\\','/')
lr = dirs[3]
epoch_num = dirs[4]
epoch_num = epoch_num.replace('\\','/')
model_name = dirs[5]
model_name = model_name.replace('\\','/')
warnings.filterwarnings("ignore")
BATCHSIZE_PER_CARD = int(bs_p_card)
solver = MyFrame(Model, Dice_bce_loss, float(lr))
if pre_model.endswith('.th'):
solver.load(pre_model)
else:
pass
train_batchsize = BATCHSIZE_PER_CARD
val_batchsize = BATCHSIZE_PER_CARD
train_dataset = ImageFolder(data_root, mode='train')
val_dataset = ImageFolder(data_root, mode='val')
test_dataset = ImageFolder(data_root, mode='test')
data_loader = torch.utils.data.DataLoader(
train_dataset,
batch_size = train_batchsize,
shuffle=True,
num_workers=0)
val_data_loader = torch.utils.data.DataLoader(
val_dataset,
batch_size = val_batchsize,
shuffle=True,
num_workers=0)
test_data_loader = torch.utils.data.DataLoader(
test_dataset,
batch_size = 1,
shuffle=True,
num_workers=0)
writer = SummaryWriter('./record')
mylog = open('logs/'+ model_name + '.log','w')
tic = time()
device = torch.device('cuda:0')
no_optim = 0
total_epoch = int(epoch_num)
train_epoch_best_loss = 100.
val_epoch_best_loss = 100.
val_best_iou = 0.3
# criteon = nn.CrossEntropyLoss().to(device)
criteon = DiceLoss()
# iou_criteon = SoftIoULoss(2)
scheduler = solver.lr_strategy()
for epoch in range(1, total_epoch + 1):
print('---------- Epoch:'+str(epoch)+ ' ----------')
# data_loader_iter = iter(data_loader)
data_loader_iter = data_loader
train_epoch_loss = 0
print('Train:')
for img, mask in tqdm(data_loader_iter,ncols=20,total=len(data_loader_iter)):
solver.set_input(img, mask)
train_loss = solver.optimize()
train_epoch_loss += train_loss
train_epoch_loss /= len(data_loader_iter)
val_data_loader_num = iter(val_data_loader)
test_epoch_loss = 0
test_mean_iou = 0
val_pre_list = []
val_mask_list = []
print('Validation:')
for val_img, val_mask in tqdm(val_data_loader_num,ncols=20,total=len(val_data_loader_num)):
val_img, val_mask = val_img.to(device), val_mask.cpu()
val_mask[np.where(val_mask > 0)] = 1
val_mask = val_mask.squeeze(0)
predict = solver.test_one_img(val_img)
predict_temp = torch.from_numpy(predict).unsqueeze(0)
predict_use = V(predict_temp.type(torch.FloatTensor),volatile=True)
val_use = V(val_mask.type(torch.FloatTensor),volatile=True)
test_epoch_loss += criteon.forward(predict_use,val_use)
predict_use = predict_use.squeeze(0)
predict_use = predict_use.unsqueeze(1)
predict_use[predict_use >= 0.5] = 1
predict_use[predict_use < 0.5] = 0
predict_use = predict_use.type(torch.LongTensor)
val_use = val_use.squeeze(1).type(torch.LongTensor)
test_mean_iou += iou_pytorch(predict_use, val_use)
batch_iou = test_mean_iou / len(val_data_loader_num)
val_loss = test_epoch_loss / len(val_data_loader_num)
writer.add_scalar('lr', scheduler.get_lr()[0], epoch)
writer.add_scalar('train_loss', train_epoch_loss, epoch)
writer.add_scalar('val_loss', val_loss, epoch)
writer.add_scalar('iou', batch_iou, epoch)
mylog.write('********** ' + 'lr={:.10f}'.format(scheduler.get_lr()[0]) + ' **********' + '\n')
mylog.write('--epoch:'+ str(epoch) + ' --time:' + str(int(time()-tic)) + ' --train_loss:' + str(train_epoch_loss) + ' --val_loss:' + str(val_loss.item()) + ' --val_iou:' + str(batch_iou.item()) +'\n')
print('--epoch:', epoch, ' --time:', int(time()-tic), ' --train_loss:', train_epoch_loss, ' --val_loss:',val_loss.item(), ' --val_iou:',batch_iou.item())
if train_epoch_loss >= train_epoch_best_loss:
no_optim += 1
else:
no_optim = 0
train_epoch_best_loss = train_epoch_loss
solver.save('weights/'+ model_name + '_train_loss_best.th')
if batch_iou >= val_best_iou:
val_best_iou = batch_iou
solver.save('weights/'+model_name + '_iou_best.th')
if val_loss <= val_epoch_best_loss:
val_epoch_best_loss = val_loss
solver.save('weights/' + model_name + '_val_loss_best.th')
if no_optim > 10:
if solver.old_lr < 5e-8:
break
solver.load('weights/'+ model_name + '_train_loss_best.th')
no_optim = 0
scheduler.step()
print('lr={:.10f}'.format(scheduler.get_lr()[0]))
mylog.flush()
# writer.add_graph(Model(), img)
print('Train Finish !')
mylog.close()
# evaluation
# model_path = './weights/'+model_name + '_iou_best.th'
model_path = './weights/'+ model_name + '_train_loss_best.th'
solver = TTAFrame(Model)
solver.load(model_path)
label_list = []
pre_list = []
for img, mask in tqdm(test_data_loader,ncols=20,total=len(test_data_loader)):
mask[mask>0] = 1
mask = torch.squeeze(mask)
mask = mask.numpy()
mask = mask.astype(np.int)
label_list.append(mask)
img = torch.squeeze(img)
img = img.numpy()
pre = solver.test_one_img_from_path_8(img)
pre[pre>=4.0] = 255
pre[pre<4.0] = 0
pre = pre.astype(np.int)
pre[pre>0] = 1
pre_list.append(pre)
eval_new(label_list, pre_list)
if __name__ == '__main__':
net = get_transNet(1)
# img = torch.randn((2, 3, 256, 256))
# new = net(img)
# print(new)
train(net)
配置文件内容
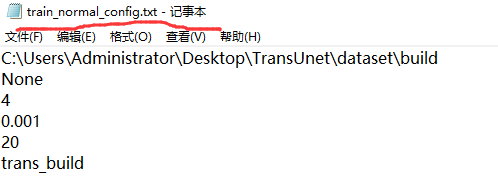
参数1:数据路径;参数2:预模型路径,没有就是None;参数3:batchsize;参数4:学习率;参数5:epoch;参数6:模型名字
4.模型加载、训练策略等相关代码framework.py
import cv2
import math
import numpy as np
import torch
import torch.nn as nn
from torch.autograd import Variable as V
from torch.optim import lr_scheduler
class MyFrame():
def __init__(self, net, loss, lr=2e-4, evalmode = False):
# self.net = net().cuda()
self.net = net.cuda()
self.net = torch.nn.DataParallel(self.net, device_ids=range(torch.cuda.device_count()))
# self.net = torch.nn.DataParallel(self.net, device_ids=[0])
# self.optimizer = torch.optim.Adam(params=self.net.parameters(), lr=lr)
self.optimizer = torch.optim.RMSprop(params=self.net.parameters(), lr=lr)
# self.optimizer = torch.optim.SGD(params=self.net.parameters(), lr=lr)
self.loss = loss()
self.old_lr = lr
if evalmode:
for i in self.net.modules():
if isinstance(i, nn.BatchNorm2d):
i.eval()
def set_input(self, img_batch, mask_batch=None, img_id=None):
self.img = img_batch
self.mask = mask_batch
self.img_id = img_id
def test_one_img(self, img):
pred = self.net.forward(img)
# pred[pred>0.5] = 1
# pred[pred<=0.5] = 0
# mask = pred.squeeze().cpu().data.numpy()
mask = pred.squeeze().cpu().data.numpy()
return mask
def test_batch(self):
self.forward(volatile=True)
mask = self.net.forward(self.img).cpu().data.numpy().squeeze(1)
mask[mask>0.5] = 1
mask[mask<=0.5] = 0
return mask, self.img_id
def test_one_img_from_path(self, path):
img = cv2.imread(path)
img = np.array(img, np.float32)/255.0 * 3.2 - 1.6
img = V(torch.Tensor(img).cuda())
mask = self.net.forward(img).squeeze().cpu().data.numpy()#.squeeze(1)
mask[mask>0.5] = 1
mask[mask<=0.5] = 0
return mask
def val_pre(self, img):
img90 = np.array(np.rot90(img))
img1 = np.concatenate([img[None],img90[None]])
img2 = np.array(img1)[:,::-1]
img3 = np.concatenate([img1,img2])
img4 = np.array(img3)[:,:,::-1]
img5 = np.concatenate([img3,img4]).transpose(0,3,1,2)
img5 = np.array(img5, np.float32)/255.0 * 3.2 -1.6
img5 = V(torch.Tensor(img5).cuda())
mask = self.net.forward(img5).squeeze().cpu().data.numpy()#.squeeze(1)
mask1 = mask[:4] + mask[4:,:,::-1]
mask2 = mask1[:2] + mask1[2:,::-1]
mask3 = mask2[0] + np.rot90(mask2[1])[::-1,::-1]
return mask3
def forward(self, volatile=False):
self.img = V(self.img.cuda(), volatile=volatile)
if self.mask is not None:
self.mask = V(self.mask.cuda(), volatile=volatile)
def optimize(self):
self.forward()
self.optimizer.zero_grad()
pred = self.net.forward(self.img)
loss = self.loss(self.mask, pred)
loss.backward()
self.optimizer.step()
# return loss.data[0]
return loss.item()
def save(self, path):
torch.save(self.net.state_dict(), path)
def load(self, path):
self.net.load_state_dict(torch.load(path))
def update_lr(self, new_lr, mylog, factor=False):
if factor:
new_lr = self.old_lr / new_lr
for param_group in self.optimizer.param_groups:
param_group['lr'] = new_lr
print(mylog, 'update learning rate: %f -> %f' % (self.old_lr, new_lr))
print('update learning rate: %f -> %f' % (self.old_lr, new_lr))
self.old_lr = new_lr
def lr_strategy(self):
# scheduler = lr_scheduler.StepLR(self.optimizer, step_size=100, gamma=0.1)
# scheduler = lr_scheduler.MultiStepLR(self.optimizer, [30, 80], 0.1)
scheduler = lr_scheduler.ExponentialLR(self.optimizer, gamma=0.9)
return scheduler
5.训练时的iou计算代码iou.py
import torch
import numpy as np
def iou_pytorch(outputs: torch.Tensor, labels: torch.Tensor, SMOOTH = 1e-6):
# You can comment out this line if you are passing tensors of equal shape
# But if you are passing output from UNet or something it will most probably
# be with the BATCH x 1 x H x W shape
outputs = outputs.squeeze(1) # BATCH x 1 x H x W => BATCH x H x W
intersection = (outputs & labels).float().sum((1, 2)) # Will be zero if Truth=0 or Prediction=0
union = (outputs | labels).float().sum((1, 2)) # Will be zzero if both are 0
iou = (intersection + SMOOTH) / (union + SMOOTH) # We smooth our devision to avoid 0/0
thresholded = torch.clamp(20 * (iou - 0.5), 0, 10).ceil() / 10 # This is equal to comparing with thresolds
return thresholded.mean() # Or thresholded.mean() if you are interested in average across the batch
# Numpy version
# Well, it's the same function, so I'm going to omit the comments
def iou_numpy(outputs: np.array, labels: np.array):
outputs = outputs.squeeze(1)
intersection = (outputs & labels).sum((1, 2))
union = (outputs | labels).sum((1, 2))
iou = (intersection + SMOOTH) / (union + SMOOTH)
thresholded = np.ceil(np.clip(20 * (iou - 0.5), 0, 10)) / 10
return thresholded # Or thresholded.mean()
位置
6.损失函数代码dice_bce_loss.py和diceloss.py
dice_bce_loss.py
import torch
import torch.nn as nn
from torch.autograd import Variable as V
import cv2
import numpy as np
import torch.nn.functional as F
try:
from itertools import ifilterfalse
except ImportError: # py3k
from itertools import filterfalse as ifilterfalse
class Dice_bce_loss(nn.Module):
def __init__(self, batch=True):
super(Dice_bce_loss, self).__init__()
self.batch = batch
self.bce_loss = nn.BCELoss()
def soft_dice_coeff(self, y_true, y_pred):
smooth = 1.0 # may change
if self.batch:
i = torch.sum(y_true)
j = torch.sum(y_pred)
intersection = torch.sum(y_true * y_pred)
else:
i = y_true.sum(1).sum(1).sum(1)
j = y_pred.sum(1).sum(1).sum(1)
intersection = (y_true * y_pred).sum(1).sum(1).sum(1)
score = (2. * intersection + smooth) / (i + j + smooth)
#score = (intersection + smooth) / (i + j - intersection + smooth)#iou
return score.mean()
def soft_dice_loss(self, y_true, y_pred):
loss = 1 - self.soft_dice_coeff(y_true, y_pred)
return loss
def __call__(self, y_true, y_pred):
a = self.bce_loss(y_pred, y_true)
b = self.soft_dice_loss(y_true, y_pred)
return a + b
class lovasz(nn.Module):
def __init__(self, batch=True):
super(lovasz, self).__init__()
self.bce_loss = nn.BCELoss()
# self.cross_entropy = nn.CrossEntropyLoss()
def isnan(self, x):
return x != x
def mean(self, l, ignore_nan=False, empty=0):
""" nanmean compatible with generators. """
l = iter(l)
if ignore_nan:
l = ifilterfalse(self.isnan, l)
try:
n = 1
acc = next(l)
except StopIteration:
if empty == 'raise':
raise ValueError('Empty mean')
return empty
for n, v in enumerate(l, 2):
acc += v
if n == 1:
return acc
return acc / n
def flatten_binary_scores(self, scores, labels, ignore=None):
""" Flattens predictions in the batch (binary case) Remove labels equal to 'ignore' """
scores = scores.view(-1)
labels = labels.view(-1)
if ignore is None:
return scores, labels
valid = (labels != ignore)
vscores = scores[valid]
vlabels = labels[valid]
return vscores, vlabels
def lovasz_grad(self, gt_sorted):
""" Computes gradient of the Lovasz extension w.r.t sorted errors See Alg. 1 in paper """
p = len(gt_sorted)
gts = gt_sorted.sum()
intersection = gts - gt_sorted.float().cumsum(0)
union = gts + (1 - gt_sorted).float().cumsum(0)
jaccard = 1. - intersection / union
if p > 1: # cover 1-pixel case
jaccard[1:p] = jaccard[1:p] - jaccard[0:-1]
return jaccard
def lovasz_hinge_flat(self, logits, labels):
""" Binary Lovasz hinge loss logits: [P] Variable, logits at each prediction (between -\infty and +\infty) labels: [P] Tensor, binary ground truth labels (0 or 1) ignore: label to ignore """
if len(labels) == 0:
# only void pixels, the gradients should be 0
return logits.sum() * 0.
signs = 2. * labels.float() - 1.
errors = (1. - logits * V(signs))
errors_sorted, perm = torch.sort(errors, dim=0, descending=True)
perm = perm.data
gt_sorted = labels[perm]
grad = self.lovasz_grad(gt_sorted)
loss = torch.dot(F.relu(errors_sorted), V(grad))
return loss
def lovasz_hinge(self, logits, labels, per_image=False, ignore=None):
""" Binary Lovasz hinge loss logits: [B, H, W] Variable, logits at each pixel (between -\infty and +\infty) labels: [B, H, W] Tensor, binary ground truth masks (0 or 1) per_image: compute the loss per image instead of per batch ignore: void class id """
if per_image:
loss = self.mean(self.lovasz_hinge_flat(*self.flatten_binary_scores(log.unsqueeze(0), lab.unsqueeze(0), ignore))
for log, lab in zip(logits, labels))
else:
loss = self.lovasz_hinge_flat(*self.flatten_binary_scores(logits, labels, ignore))
return loss
def __call__(self, y_true, y_pred):
a = (self.lovasz_hinge(y_pred, y_true) + self.lovasz_hinge(-y_pred, 1 - y_true)) / 2
b = self.bce_loss(y_pred, y_true)
c = self.lovasz_hinge(y_pred, y_true)
return a + b
class multi_loss(nn.Module):
def __init__(self, batch=True):
super(multi_loss, self).__init__()
self.batch = batch
self.multi_loss = nn.NLLLoss()
def __call__(self, y_true, y_pred):
a = self.multi_loss(y_true, y_pred)
return a
diceloss.py
import torch
import torch.nn as nn
class DiceLoss(nn.Module):
def __init__(self):
super(DiceLoss, self).__init__()
def forward(self, input, target):
N = target.size(0)
smooth = 1
input_flat = input.view(N, -1)
target_flat = target.view(N, -1)
intersection = input_flat * target_flat
loss = 2 * (intersection.sum(1) + smooth) / (input_flat.sum(1) + target_flat.sum(1) + smooth)
loss = 1 - loss.sum() / N
return loss
class MulticlassDiceLoss(nn.Module):
""" requires one hot encoded target. Applies DiceLoss on each class iteratively. requires input.shape[0:1] and target.shape[0:1] to be (N, C) where N is batch size and C is number of classes """
def __init__(self):
super(MulticlassDiceLoss, self).__init__()
def forward(self, input, target, weights=None):
C = target.shape[1]
# if weights is None:
# weights = torch.ones(C) #uniform weights for all classes
dice = DiceLoss()
totalLoss = 0
for i in range(C):
diceLoss = dice(input[:,i], target[:,i])
if weights is not None:
diceLoss *= weights[i]
totalLoss += diceLoss
return totalLoss
位置
7.模型调用文件,TransUnet.py
import torch
import torch.nn as nn
import functools
import torch.nn.functional as F
from .vit_seg_modeling import VisionTransformer as ViT_seg
from .vit_seg_modeling import CONFIGS as CONFIGS_ViT_seg
def get_transNet(n_classes):
img_size = 256
vit_patches_size = 16
vit_name = 'R50-ViT-B_16'
config_vit = CONFIGS_ViT_seg[vit_name]
config_vit.n_classes = n_classes
config_vit.n_skip = 3
if vit_name.find('R50') != -1:
config_vit.patches.grid = (int(img_size / vit_patches_size), int(img_size / vit_patches_size))
net = ViT_seg(config_vit, img_size=img_size, num_classes=n_classes)
return net
if __name__ == '__main__':
net = get_transNet(2)
img = torch.randn((2, 3, 512, 512))
segments = net(img)
print(segments.size())
# for edge in edges:
# print(edge.size())
位置,红框里的三个文件在原作者那里下载,链接https://github.com/Beckschen/TransUNet/tree/main/networks
8.预测代码inference.py
import torch
import torch.optim as optim
from torch.optim import lr_scheduler
import torch.nn as nn
import torch.utils.data as data
import torch.nn.functional as F
from torch.autograd import Variable as V
import cv2
import os
import math
import warnings
from tqdm import tqdm
import numpy as np
from data import ImageFolder
from models.networks.TransUnet import get_transNet
BATCHSIZE_PER_CARD = 8
class TTAFrame():
def __init__(self, net):
# self.net = net(out_planes=1).cuda()
self.net = net.cuda()
# self.net = net().cuda()
self.net = torch.nn.DataParallel(self.net, device_ids=range(torch.cuda.device_count()))
# self.net = torch.nn.DataParallel(self.net, device_ids=[0])
def test_one_img_from_path(self, path, evalmode = True):
if evalmode:
self.net.eval()
batchsize = torch.cuda.device_count() * BATCHSIZE_PER_CARD
if batchsize >= 8:
return self.test_one_img_from_path_1(path)
elif batchsize >= 4:
return self.test_one_img_from_path_2(path)
elif batchsize >= 2:
return self.test_one_img_from_path_4(path)
def test_one_img_from_path_8(self, img):
# img = cv2.imread(path)#.transpose(2,0,1)[None]
img90 = np.array(np.rot90(img))
img1 = np.concatenate([img[None],img90[None]])
img2 = np.array(img1)[:,::-1]
img3 = np.array(img1)[:,:,::-1]
img4 = np.array(img2)[:,:,::-1]
img1 = img1.transpose(0,3,1,2)
img2 = img2.transpose(0,3,1,2)
img3 = img3.transpose(0,3,1,2)
img4 = img4.transpose(0,3,1,2)
img1 = V(torch.Tensor(np.array(img1, np.float32)/255.0 * 3.2 - 1.6).cuda())
img2 = V(torch.Tensor(np.array(img2, np.float32)/255.0 * 3.2 - 1.6).cuda())
img3 = V(torch.Tensor(np.array(img3, np.float32)/255.0 * 3.2 - 1.6).cuda())
img4 = V(torch.Tensor(np.array(img4, np.float32)/255.0 * 3.2 - 1.6).cuda())
maska = self.net.forward(img1).squeeze().cpu().data.numpy()
maskb = self.net.forward(img2).squeeze().cpu().data.numpy()
maskc = self.net.forward(img3).squeeze().cpu().data.numpy()
maskd = self.net.forward(img4).squeeze().cpu().data.numpy()
mask1 = maska + maskb[:,::-1] + maskc[:,:,::-1] + maskd[:,::-1,::-1]
mask2 = mask1[0] + np.rot90(mask1[1])[::-1,::-1]
return mask2
def test_one_img_from_path_4(self, path):
img = cv2.imread(path)#.transpose(2,0,1)[None]
img90 = np.array(np.rot90(img))
img1 = np.concatenate([img[None],img90[None]])
img2 = np.array(img1)[:,::-1]
img3 = np.array(img1)[:,:,::-1]
img4 = np.array(img2)[:,:,::-1]
img1 = img1.transpose(0,3,1,2)
img2 = img2.transpose(0,3,1,2)
img3 = img3.transpose(0,3,1,2)
img4 = img4.transpose(0,3,1,2)
img1 = V(torch.Tensor(np.array(img1, np.float32)/255.0 * 3.2 -1.6).cuda())
img2 = V(torch.Tensor(np.array(img2, np.float32)/255.0 * 3.2 -1.6).cuda())
img3 = V(torch.Tensor(np.array(img3, np.float32)/255.0 * 3.2 -1.6).cuda())
img4 = V(torch.Tensor(np.array(img4, np.float32)/255.0 * 3.2 -1.6).cuda())
maska = self.net.forward(img1).squeeze().cpu().data.numpy()
maskb = self.net.forward(img2).squeeze().cpu().data.numpy()
maskc = self.net.forward(img3).squeeze().cpu().data.numpy()
maskd = self.net.forward(img4).squeeze().cpu().data.numpy()
mask1 = maska + maskb[:,::-1] + maskc[:,:,::-1] + maskd[:,::-1,::-1]
mask2 = mask1[0] + np.rot90(mask1[1])[::-1,::-1]
return mask2
def test_one_img_from_path_2(self, path):
img = cv2.imread(path)#.transpose(2,0,1)[None]
img90 = np.array(np.rot90(img))
img1 = np.concatenate([img[None],img90[None]])
img2 = np.array(img1)[:,::-1]
img3 = np.concatenate([img1,img2])
img4 = np.array(img3)[:,:,::-1]
img5 = img3.transpose(0,3,1,2)
img5 = np.array(img5, np.float32)/255.0 * 3.2 -1.6
img5 = V(torch.Tensor(img5).cuda())
img6 = img4.transpose(0,3,1,2)
img6 = np.array(img6, np.float32)/255.0 * 3.2 -1.6
img6 = V(torch.Tensor(img6).cuda())
maska = self.net.forward(img5).squeeze().cpu().data.numpy()#.squeeze(1)
maskb = self.net.forward(img6).squeeze().cpu().data.numpy()
mask1 = maska + maskb[:,:,::-1]
mask2 = mask1[:2] + mask1[2:,::-1]
mask3 = mask2[0] + np.rot90(mask2[1])[::-1,::-1]
return mask3
def test_one_img_from_path_1(self, img):
# img = cv2.imread(path)#.transpose(2,0,1)[None]
img90 = np.array(np.rot90(img))
img1 = np.concatenate([img[None],img90[None]])
img2 = np.array(img1)[:,::-1]
img3 = np.concatenate([img1,img2])
img4 = np.array(img3)[:,:,::-1]
img5 = np.concatenate([img3,img4]).transpose(0,3,1,2)
img5 = np.array(img5, np.float32)/255.0 * 3.2 -1.6
img5 = V(torch.Tensor(img5).cuda())
mask = self.net.forward(img5).squeeze().cpu().data.numpy()#.squeeze(1)
mask1 = mask[:4] + mask[4:,:,::-1]
mask2 = mask1[:2] + mask1[2:,::-1]
mask3 = mask2[0] + np.rot90(mask2[1])[::-1,::-1]
return mask3
def load(self, path):
self.net.load_state_dict(torch.load(path))
# self.net.load_state_dict(torch.load(path,map_location={'cuda:4':'cuda:0'}))
def tta_use(self,img):
#1
tta_model = tta.SegmentationTTAWrapper(self.net, tta.aliases.flip_transform(), merge_mode='mean')
img = img.transpose(2,1,0)
img = np.array(img, np.float32)/255.0 * 3.2 -1.6
img = V(torch.Tensor(img).cuda())
# print(img.shape)
mask = tta_model.forward(img.unsqueeze(0)).squeeze().cpu().data.numpy()
return mask
if __name__ == "__main__":
test_path = './TransUnet/dataset/build/test2/'
save_path = './TransUnet/dataset/build/result/'
imgs = os.listdir(test_path)
model_path = './weights/trans_build_iou_best.th'
net = get_transNet(1)
solver = TTAFrame(net)
solver.load(model_path)
for img in tqdm(imgs,ncols=20,total=len(imgs)):
img_path = os.path.join(test_path, img)
im = cv2.imread(img_path)
pre = solver.test_one_img_from_path_8(im)
pre[pre>=4.0] = 255
pre[pre<4.0] = 0
save_out = os.path.join(save_path, img)
cv2.imwrite(save_out, pre)
9.精度评价eval.py
# -*- coding: utf-8 -*-
import os
import cv2
import numpy as np
from osgeo import gdal
from sklearn.metrics import confusion_matrix
class IOUMetric:
""" Class to calculate mean-iou using fast_hist method """
def __init__(self, num_classes):
self.num_classes = num_classes
self.hist = np.zeros((num_classes, num_classes))
def _fast_hist(self, label_pred, label_true):
mask = (label_true >= 0) & (label_true < self.num_classes)
hist = np.bincount(
self.num_classes * label_true[mask].astype(int) +
label_pred[mask], minlength=self.num_classes ** 2).reshape(self.num_classes, self.num_classes)
return hist
def evaluate(self, predictions, gts):
for lp, lt in zip(predictions, gts):
assert len(lp.flatten()) == len(lt.flatten())
self.hist += self._fast_hist(lp.flatten(), lt.flatten())
# miou
iou = np.diag(self.hist) / (self.hist.sum(axis=1) + self.hist.sum(axis=0) - np.diag(self.hist))
miou = np.nanmean(iou)
# mean acc
acc = np.diag(self.hist).sum() / self.hist.sum()
acc_cls = np.nanmean(np.diag(self.hist) / self.hist.sum(axis=1))
freq = self.hist.sum(axis=1) / self.hist.sum()
fwavacc = (freq[freq > 0] * iou[freq > 0]).sum()
return acc, acc_cls, iou, miou, fwavacc
def read_img(filename):
dataset=gdal.Open(filename)
im_width = dataset.RasterXSize
im_height = dataset.RasterYSize
im_geotrans = dataset.GetGeoTransform()
im_proj = dataset.GetProjection()
im_data = dataset.ReadAsArray(0,0,im_width,im_height)
del dataset
return im_proj,im_geotrans,im_width, im_height,im_data
def write_img(filename, im_proj, im_geotrans, im_data):
if 'int8' in im_data.dtype.name:
datatype = gdal.GDT_Byte
elif 'int16' in im_data.dtype.name:
datatype = gdal.GDT_UInt16
else:
datatype = gdal.GDT_Float32
if len(im_data.shape) == 3:
im_bands, im_height, im_width = im_data.shape
else:
im_bands, (im_height, im_width) = 1,im_data.shape
driver = gdal.GetDriverByName("GTiff")
dataset = driver.Create(filename, im_width, im_height, im_bands, datatype)
dataset.SetGeoTransform(im_geotrans)
dataset.SetProjection(im_proj)
if im_bands == 1:
dataset.GetRasterBand(1).WriteArray(im_data)
else:
for i in range(im_bands):
dataset.GetRasterBand(i+1).WriteArray(im_data[i])
del dataset
def eval_re(label_path, predict_path, eval_path):
pres = os.listdir(predict_path)
labels = []
predicts = []
for im in pres:
if im[-4:] == '.tif':
label_name = im.split('.')[0] + '.tif'
lab_path = os.path.join(label_path, label_name)
pre_path = os.path.join(predict_path, im)
im_proj,im_geotrans,im_width, im_height, label = read_img(lab_path)
im_proj,im_geotrans,im_width, im_height, pre = read_img(pre_path)
# label = cv2.imread(lab_path,0)
# pre = cv2.imread(pre_path,0)
label[label>0] = 1
pre[pre>0] = 1
label = np.uint8(label)
pre = np.uint8(pre)
labels.append(label)
predicts.append(pre)
el = IOUMetric(2)
acc, acc_cls, iou, miou, fwavacc = el.evaluate(predicts, labels)
pres = os.listdir(predict_path)
init = np.zeros((2,2))
for im in pres:
lb_path = os.path.join(label_path, im)
pre_path = os.path.join(predict_path, im)
# lb = cv2.imread(lb_path,0)
# pre = cv2.imread(pre_path,0)
im_proj,im_geotrans,im_width, im_height, lb = read_img(lb_path)
im_proj,im_geotrans,im_width, im_height, pre = read_img(pre_path)
lb[lb>0] = 1
pre[pre>0] = 1
lb = np.uint8(lb)
pre = np.uint8(pre)
lb = lb.flatten()
pre = pre.flatten()
confuse = confusion_matrix(lb, pre)
init += confuse
precision = init[1][1]/(init[0][1] + init[1][1])
recall = init[1][1]/(init[1][0] + init[1][1])
accuracy = (init[0][0] + init[1][1])/init.sum()
f1_score = 2*precision*recall/(precision + recall)
with open(eval_path, 'a') as f:
f.write('accuracy: ' + str(accuracy) + '\n')
f.write('recal: ' + str(recall) + '\n')
f.write('miou: ' + str(miou))
def eval_func(label_path, predict_path):
pres = os.listdir(predict_path)
labels = []
predicts = []
for im in pres:
if im[-4:] == '.png':
label_name = im.split('.')[0] + '.png'
lab_path = os.path.join(label_path, label_name)
pre_path = os.path.join(predict_path, im)
label = cv2.imread(lab_path,0)
pre = cv2.imread(pre_path,0)
label[label>0] = 1
pre[pre>0] = 1
label = np.uint8(label)
pre = np.uint8(pre)
labels.append(label)
predicts.append(pre)
el = IOUMetric(2)
acc, acc_cls, iou, miou, fwavacc = el.evaluate(predicts,labels)
print('acc: ',acc)
print('acc_cls: ',acc_cls)
print('iou: ',iou)
print('miou: ',miou)
print('fwavacc: ',fwavacc)
pres = os.listdir(predict_path)
init = np.zeros((2,2))
for im in pres:
lb_path = os.path.join(label_path, im)
pre_path = os.path.join(predict_path, im)
lb = cv2.imread(lb_path,0)
pre = cv2.imread(pre_path,0)
lb[lb>0] = 1
pre[pre>0] = 1
lb = np.uint8(lb)
pre = np.uint8(pre)
lb = lb.flatten()
pre = pre.flatten()
confuse = confusion_matrix(lb, pre)
init += confuse
precision = init[1][1]/(init[0][1] + init[1][1])
recall = init[1][1]/(init[1][0] + init[1][1])
accuracy = (init[0][0] + init[1][1])/init.sum()
f1_score = 2*precision*recall/(precision + recall)
print('class_accuracy: ', precision)
print('class_recall: ', recall)
print('accuracy: ', accuracy)
print('f1_score: ', f1_score)
def eval_new(label_list, pre_list):
el = IOUMetric(2)
acc, acc_cls, iou, miou, fwavacc = el.evaluate(pre_list, label_list)
print('acc: ',acc)
# print('acc_cls: ',acc_cls)
print('iou: ',iou)
print('miou: ',miou)
print('fwavacc: ',fwavacc)
init = np.zeros((2,2))
for i in range(len(label_list)):
lab = label_list[i].flatten()
pre = pre_list[i].flatten()
confuse = confusion_matrix(lab, pre)
init += confuse
precision = init[1][1]/(init[0][1] + init[1][1])
recall = init[1][1]/(init[1][0] + init[1][1])
accuracy = (init[0][0] + init[1][1])/init.sum()
f1_score = 2*precision*recall/(precision + recall)
print('class_accuracy: ', precision)
print('class_recall: ', recall)
# print('accuracy: ', accuracy)
print('f1_score: ', f1_score)
if __name__ == "__main__":
label_path = './data/build/test/labels/'
predict_path = './data/build/test/re/'
eval_func(label_path, predict_path)
我用的训练数据:
链接:https://pan.baidu.com/s/1487wODEn5bpTbmBw91Oavw
提取码:zow5
–来自百度网盘超级会员V5的分享
清理电脑文件发现原始的预模型我居然有下载,链接
链接:https://pan.baidu.com/s/1Og9eTorM6saM95uWITVqhg
提取码:29zz
–来自百度网盘超级会员V5的分享
以上二分类源码:
https://download.csdn.net/download/qq_20373723/85035195
多分类说明:改多分类只需要找到网络最后一层,把sigmoid 改成softmax就好了,数据加载的地方也要改下,别忘了训练的时候把类别改了
实在不想改了或者想要参考的话:
https://download.csdn.net/download/qq_20373723/83024925
测试数据链接:
https://download.csdn.net/download/qq_20373723/83018556
有什么问题评论区或者私信都可以找我,看到了会回复的,另外,付费的资源尽量还是不下载吧,我觉得稍微懂一点的应该能独自完成的,参考博客肯定可以跑出来的
题外话:有什么新的比较好的网络可以评论推荐给我,我来复现贴出来大家一起用一用
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/196798.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
