大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
决策树原理及其应用
##决策树的原理
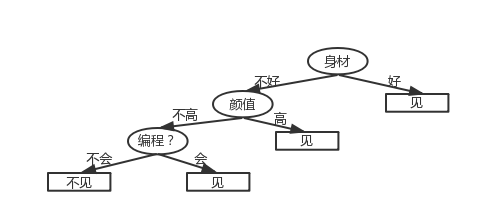
我们先构造一颗简单的决策树来玩一玩。举一个不恰当的例子:小明过年回家,老妈催着他结婚,帮着张罗相亲对象。有三个女孩的资料(简称A、B、C)。
关于A:
小明问:“身材好吗?”,妈妈说:“好!”,小明说:“见一面”
关于B:
小明问:“身材好吗?” , 妈妈说:“不好!”,小明又问:“漂亮吗?”,
妈妈说:“漂亮!”,小明说:“见一面”
关于C:
小明问:“身材好吗?” , 妈妈说:“不好!”,小明又问:“漂亮吗?”,妈妈说:“不漂亮”,小明又问:“会写代码吗?”,妈妈说:“会”,小明说:“见一面”。
我们构造出小明相亲的决策树如下:

在这里 优先级顺序是 身材 > 颜值 > 编程能力。这个时候就会疑惑,这个“优先级”是怎么决定的呢?在决定是否去相亲的因素有很多,工作地点的距离(我编不出来了)etc…,我们是否要每一个因素都去考虑?如果你有这方面的疑惑,恭喜你!如果在1984,提出CART算法的人可能不是Breiman了。这三个问题涉及到决策树中的特征选择,决策树的生成,决策树的修剪,一堆扯淡的引入到此为止。
下面是某相亲网上约会成功的数据:
| ID | 年龄 | 工作 | 有房 | 颜值 | 类别 |
|---|---|---|---|---|---|
| 1 | 青年 | 否 | 否 | 一般 | 否 |
| 2 | 青年 | 否 | 否 | 好 | 否 |
| 3 | 青年 | 是 | 否 | 好 | 是 |
| 4 | 青年 | 是 | 是 | 一般 | 是 |
| 5 | 青年 | 否 | 否 | 一般 | 否 |
| 6 | 中年 | 否 | 否 | 一般 | 否 |
| 7 | 中年 | 否 | 否 | 好 | 否 |
| 8 | 中年 | 是 | 是 | 好 | 是 |
| 9 | 中年 | 否 | 是 | 非常好 | 是 |
| 10 | 中年 | 否 | 是 | 非常好 | 是 |
| 11 | 老年 | 否 | 是 | 非常好 | 是 |
| 12 | 老年 | 否 | 是 | 好 | 是 |
| 13 | 老年 | 是 | 否 | 好 | 是 |
| 14 | 老年 | 是 | 否 | 非常好 | 是 |
| 15 | 老年 | 否 | 否 | 一般 | 否 |
以上数据改编自 李航《统计学习方法》
- 特征选择
特征选择是根据所给数据来决定用哪个特征来对数据进行分类,当然是按特征的分类能力强弱来对数据进行分类,下面我们来讲一讲如何评判特征的分类能力。
先看一看是否有房这一栏和类别的关系,在有房的情况下,类别为是的一共有6组数据;在没有房的情况下,类别为否的一共有6组数据,是否有房和是否约会成功一致的一共有12组数据。再看一看是否有工作和是否约会成功一致的数据,发现一共有11组数据。“12>11”感觉上“是否有房子”比“是否有工作”的分类能力要强一些,到底是不是这样呢?下面我们用精确的数学语言来解释一下。
我们这里引入三个信息论的概念熵、条件熵、信息增益、信息增益比。
熵 表示随机变量不确定性的度量。设 X X X是一个取有限个值的随机变量,其分布为: P ( X = x i ) = p i , i = 1 , 2 , . . . , n P(X = x_i) = p_i , i=1,2,…,n P(X=xi)=pi,i=1,2,...,n
则随机变量 X X X的熵定义为:
H ( X ) = − ∑ i = 1 n p i l o g p i H(X)=-\sum_{i=1}^{n}p_ilogp_i H(X)=−∑i=1npilogpi
例子: 随机变量是年龄
$P(x_1= 青年) = \frac{5}{15}; P(x_2 = 中年) = \frac{5}{15};P(x_3 = 老年) = \frac{5}{15} $
H ( X ) = − ( 5 15 l o g 5 15 + 5 15 l o g 5 15 + 5 15 l o g 5 15 ) H(X) = -(\frac{5}{15}log\frac{5}{15}+\frac{5}{15}log\frac{5}{15}+\frac{5}{15}log\frac{5}{15}) H(X)=−(155log155+155log155+155log155)
**条件熵 ** H ( Y ∣ X ) H(Y|X) H(Y∣X)表示在已知随机变量 X X X的条件下随机变量 Y Y Y的不确定性,定义为:
H ( Y ∣ X ) = ∑ i = 1 n p i H ( Y ∣ X = x i ) H(Y|X) = \sum_{i=1}^np_i H(Y|X=x_i) H(Y∣X)=∑i=1npiH(Y∣X=xi) ,这里$ p_i=P(X = x_i) , i=1,2,…,n$
例子:随机变量 Y Y Y为类别,随机变量 X X X为年龄
H ( Y ∣ X ) = 5 15 H ( Y ∣ x 1 = 青 年 ) + 5 15 H ( Y ∣ x 2 = 中 年 ) + 5 15 H ( Y ∣ x 3 = 老 年 ) H(Y|X)=\frac{5}{15}H(Y|x_1=青年)+\frac{5}{15}H(Y|x_2=中年)+\frac{5}{15}H(Y|x_3=老年) H(Y∣X)=155H(Y∣x1=青年)+155H(Y∣x2=中年)+155H(Y∣x3=老年)
H ( Y ∣ x 1 = 青 年 ) = − ∑ i = 1 n p ( x = 青 年 , y i ) l o g p ( y i ∣ x = 青 年 ) H(Y|x_1=青年) =- \sum _{i=1}^{n}p(x=青年,y_i)logp(y_i|x=青年) H(Y∣x1=青年)=−∑i=1np(x=青年,yi)logp(yi∣x=青年)
H ( Y ∣ x 1 = 中 年 ) = − ∑ i = 1 n p ( x = 中 年 , y i ) l o g p ( y i ∣ x = 中 年 ) H(Y|x_1=中年) =- \sum _{i=1}^{n}p(x=中年,y_i)logp(y_i|x=中年) H(Y∣x1=中年)=−∑i=1np(x=中年,yi)logp(yi∣x=中年)
H ( Y ∣ x 1 = 老 年 ) = − ∑ i = 1 n p ( x = 老 年 , y i ) l o g p ( y i ∣ x = 老 年 ) H(Y|x_1=老年) = -\sum _{i=1}^{n}p(x=老年,y_i)logp(y_i|x=老年) H(Y∣x1=老年)=−∑i=1np(x=老年,yi)logp(yi∣x=老年)
H ( Y ∣ x 1 = 青 年 ) = − 3 5 l o g 3 5 − 2 5 l o g 2 5 H(Y|x_1=青年)=-\frac{3}{5}log\frac{3}{5}-\frac{2}{5}log\frac{2}{5} H(Y∣x1=青年)=−53log53−52log52
H ( Y ∣ x 2 = 中 年 ) = − 2 5 l o g 2 5 − 3 5 l o g 3 5 H(Y|x_2=中年)=-\frac{2}{5}log\frac{2}{5}-\frac{3}{5}log\frac{3}{5} H(Y∣x2=中年)=−52log52−53log53
H ( Y ∣ x 3 = 老 年 ) = − 1 5 l o g 1 5 − 4 5 l o g 4 5 H(Y|x_3=老年)=-\frac{1}{5}log\frac{1}{5}-\frac{4}{5}log\frac{4}{5} H(Y∣x3=老年)=−51log51−54log54
H ( Y ∣ X ) = 5 15 H ( Y ∣ x 1 = 青 年 ) + 5 15 H ( Y ∣ x 2 = 中 年 ) + 5 15 H ( Y ∣ x 3 = 老 年 ) ≈ 0.888 H(Y|X)=\frac{5}{15}H(Y|x_1=青年)+\frac{5}{15}H(Y|x_2=中年)+\frac{5}{15}H(Y|x_3=老年) \approx0.888 H(Y∣X)=155H(Y∣x1=青年)+155H(Y∣x2=中年)+155H(Y∣x3=老年)≈0.888
信息增益 即 是 g ( Y , X ) = H ( Y ) − H ( Y ∣ X ) , g ( Y , X ) 为 特 征 X 的 信 息 增 益 即是 g(Y,X)=H(Y)-H(Y|X),g(Y,X)为特征X的信息增益 即是g(Y,X)=H(Y)−H(Y∣X),g(Y,X)为特征X的信息增益
终于讲完了这三个概念,我们一起来算一算 g ( Y , X 1 ) , g ( Y , X 2 ) g(Y,X_1),g(Y,X_2) g(Y,X1),g(Y,X2),其中 X 1 是 特 征 是 否 有 房 子 , X 2 是 特 征 是 否 有 工 作 X_1是特征是否有房子,X_2是特征是否有工作 X1是特征是否有房子,X2是特征是否有工作。
g ( Y , X 1 ) = H ( Y ) − H ( Y ∣ X 1 ) g(Y,X_1)=H(Y)-H(Y|X_1) g(Y,X1)=H(Y)−H(Y∣X1)
H ( Y ) = − 9 15 l o g 9 15 − 6 15 l o g 6 15 = 0.971 H(Y)=-\frac{9}{15}log\frac{9}{15}-\frac{6}{15}log\frac{6}{15}=0.971 H(Y)=−159log159−156log156=0.971
H ( Y ∣ X 1 ) = 10 15 H ( Y ∣ x 1 = 否 ) + 5 15 H ( Y ∣ x 2 = 是 ) H(Y|X_1)=\frac{10}{15}H(Y|x_1=否)+\frac{5}{15}H(Y|x_2=是) H(Y∣X1)=1510H(Y∣x1=否)+155H(Y∣x2=是)
H ( Y ∣ x 1 = 否 ) = − 6 10 l o g 6 10 − 4 10 l o g 4 10 H(Y|x_1=否)=-\frac{6}{10}log\frac{6}{10}-\frac{4}{10}log\frac{4}{10} H(Y∣x1=否)=−106log106−104log104
H ( Y ∣ x 2 = 是 ) = − 5 5 l o g 5 5 H(Y|x_2=是)=-\frac{5}{5}log\frac{5}{5} H(Y∣x2=是)=−55log55
H ( Y ∣ X 1 ) = 10 15 ( − 6 10 l o g 6 10 − 4 10 l o g 4 10 ) + 5 15 × 0 H(Y|X_1)=\frac{10}{15}(-\frac{6}{10}log\frac{6}{10}-\frac{4}{10}log\frac{4}{10})+\frac{5}{15}×0 H(Y∣X1)=1510(−106log106−104log104)+155×0
g ( Y ∣ X 1 ) = 0.971 − [ 10 15 ( − 6 10 l o g 6 10 − 4 10 l o g 4 10 ) + 5 15 × 0 ] = 0.324 g(Y|X_1)=0.971-[\frac{10}{15}(-\frac{6}{10}log\frac{6}{10}-\frac{4}{10}log\frac{4}{10})+\frac{5}{15}×0]=0.324 g(Y∣X1)=0.971−[1510(−106log106−104log104)+155×0]=0.324
g ( Y , X 2 ) = H ( Y ) − H ( Y ∣ X 2 ) g(Y,X_2)=H(Y)-H(Y|X_2) g(Y,X2)=H(Y)−H(Y∣X2)
H ( Y ∣ X 2 ) = 9 15 H ( Y ∣ x 1 = 否 ) + 6 15 H ( Y ∣ x 2 = 是 ) H(Y|X_2)=\frac{9}{15}H(Y|x_1=否)+\frac{6}{15}H(Y|x_2=是) H(Y∣X2)=159H(Y∣x1=否)+156H(Y∣x2=是)
H ( Y ∣ x 1 = 否 ) = − 6 9 l o g 6 9 − 3 9 l o g 3 9 H(Y|x_1=否)=-\frac{6}{9}log\frac{6}{9}-\frac{3}{9}log\frac{3}{9} H(Y∣x1=否)=−96log96−93log93
H ( Y ∣ x 2 = 是 ) = − 6 6 l o g 6 6 H(Y|x_2=是)=-\frac{6}{6}log\frac{6}{6} H(Y∣x2=是)=−66log66
H ( Y ∣ X 2 ) = 9 15 ( − 6 9 l o g 6 9 − 3 9 l o g 3 9 ) + 6 15 ( − 6 6 l o g 6 6 ) H(Y|X_2)=\frac{9}{15}(-\frac{6}{9}log\frac{6}{9}-\frac{3}{9}log\frac{3}{9})+\frac{6}{15}(-\frac{6}{6}log\frac{6}{6}) H(Y∣X2)=159(−96log96−93log93)+156(−66log66)
g ( Y ∣ X 2 ) = 0.971 − [ 9 15 ( − 6 9 l o g 6 9 − 3 9 l o g 3 9 ) + 6 15 ( − 6 6 l o g 6 6 ) ] = 0.420 g(Y|X_2)=0.971-[\frac{9}{15}(-\frac{6}{9}log\frac{6}{9}-\frac{3}{9}log\frac{3}{9})+\frac{6}{15}(-\frac{6}{6}log\frac{6}{6})]=0.420 g(Y∣X2)=0.971−[159(−96log96−93log93)+156(−66log66)]=0.420
这里 g ( Y ∣ X 1 ) < g ( Y ∣ X 2 ) g(Y|X_1)<g(Y|X_2) g(Y∣X1)<g(Y∣X2)所以特征“是否有房子”的分类能力强于“是否有工作”,然后按给出的方法计算出每一个特征的增益值,就可以进行下一步啦。
信息增益比
特征 A A A对训练数据集 D D D的信息增益比 g R ( D , A ) g_R(D,A) gR(D,A)定义为其信息增益 g ( D , A ) g(D,A) g(D,A)与训练数据集 D D D关于特征 A A A的值的熵 H A ( D ) H_A(D) HA(D)之比,即
g R ( D , A ) = g ( D , A ) H A ( D ) g_R(D,A)=\frac{g(D,A)}{H_A(D)} gR(D,A)=HA(D)g(D,A)
其中 H A ( D ) = − ∑ i = 1 n ∣ D i ∣ ∣ D ∣ l o g 2 ∣ D i ∣ ∣ D ∣ H_A(D)=-\sum_{i=1}^n\frac{|D_i|}{|D|}log_2\frac{|D_i|}{|D|} HA(D)=−∑i=1n∣D∣∣Di∣log2∣D∣∣Di∣,其中 n 是 特 征 A 取 值 的 个 数 n是特征A取值的个数 n是特征A取值的个数
2. 决策树生成
在sklearn中介绍了三种决策树生成算法ID3、C4.5、C5.0、CART,我们简单介绍一下这几中算法的原理。
输入:训练数据集 D D D,特征集 A A A,阈值 ϵ \epsilon ϵ
输出:决策树T
ID3:
(1)如果数据集中所有实例都属于同一类 C k C_k Ck( y i , i = 1 , 2 , . . , n y_i,i=1,2,..,n yi,i=1,2,..,n, y i = C k y_i=C_k yi=Ck),则 T T T为单节点树,并将类 C k C_k Ck作为该节点的标记,返回 T T T;
(2)如果 A = ∅ A= \varnothing A=∅,则 T T T为单节点树,并将 D D D中实例数的最大类 C k C_k Ck作为该节点的标记,返回 T T T;
(3)否则,计算 A A A中各特征对 D D D的信息增益,选择信息增益最大的特征 A g A_g Ag;
(4)如果 A g A_g Ag的信息增益小于阈值 ϵ \epsilon ϵ,则 T T T为单节点树,并将 D D D中实例数的最大类 C k C_k Ck作为该节点的标记,返回 T T T;
(5)否则,对 A g A_g Ag的每一可能值 a i a_i ai,依 A g = a i A_g=a_i Ag=ai将 D D D分割为若干非空子集 D i D_i Di,将 D i D_i Di中实例数最大的类作为标记,构建子节点,由节点及其子节点构成树 T T T,返回 T T T.
(6)对第 i i i个子节点,以 D i D_i Di为训练集,以 A − A g A-{A_g} A−Ag为特征集,递归地调用(1)~(5),得到子树 T i T_i Ti,返回 T i T_i Ti。
C4.5
C4.5和ID3类似,只在特征选择上不同,其他都是一样的,ID3用信息增益来选择特征,而C4.5用信息增益比来选择特征。C4.5是ID3的改进,既然是改进,说明信息增益比作为特征选择的比信息增益更合理。大概是因为信息增益趋向于选择取值比较多的特征。具体原因在这里
C5.0
在C4.5的基础上有所改进,它不是开源的。这里说它的运行速度比C4.5更快,所需要的内存比C4.5更小,和C4.5很相似,不过C5.0会建立更多的深度较小的决策树,在同样的数据集下的准确率和C4.5类似,等等。
CART
建议先看完决策树剪枝,在来看CART算法
3.决策树剪枝
不想写了。。。。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/196133.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
