大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
深度学习CNN算法原理
一 卷积神经网络
卷积神经网络(CNN)是一种前馈神经网络,通常包含数据输入层、卷积计算层、ReLU激活层、池化层、全连接层(INPUT-CONV-RELU-POOL-FC),是由卷积运算来代替传统矩阵乘法运算的神经网络。CNN常用于图像的数据处理,常用的LenNet-5神经网络模型如下图所示:
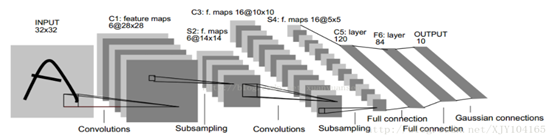

该模型由2个卷积层、2个抽样层(池化层)、3个全连接层组成。
1.1 卷积层
用途:进行特征提取
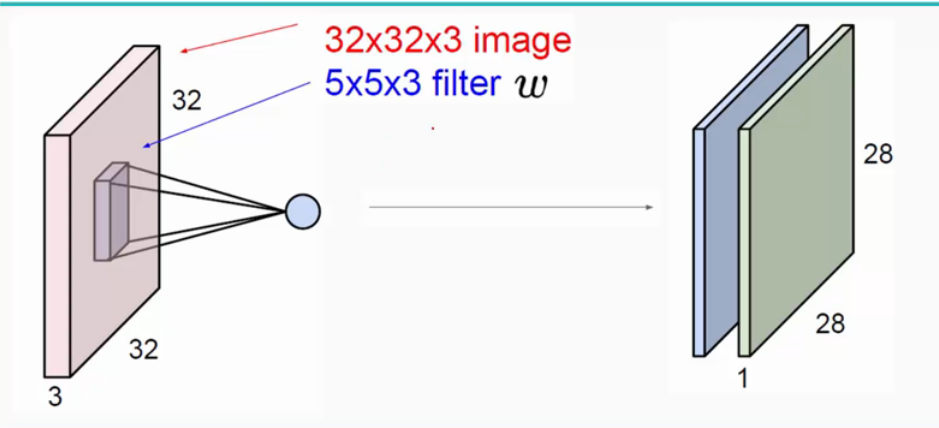
如上图所示:若输入图像是32*32*3(3是它的深度(即R、G、B),卷积层是一个5*5*3的filter(感受野)。注意感受野的深度必须和输入图像的深度相同。通过一个filter与输入图像的卷积可以得到一个28*28*1的特征图,上图是用了两个filter得到了两个特征图;在实际的运用过程中,通常会使用多层卷积层来得到更深层次的特征图。
卷积层是通过一个可调参数的卷积核与上一层特征图进行滑动卷积运算,再加上一个偏置量得到一个净输出,然后调用激活函数得出卷积结果,通过对全图的滑动卷积运算输出新的特征图,
ujl=i∈Mixijl-1*kijl+bjl
xjl=f(ujl)
式中xijl-1是l-1层特征图被第j个卷积所覆盖的元素;kijl为l层卷积核中的元素;bjl为第j个卷积结果的偏置量;Mi为第i个卷积核所覆盖的区域;ujl为l层卷积的净输入;fujl为激活函数;xjl为l层第j个卷积的输入。
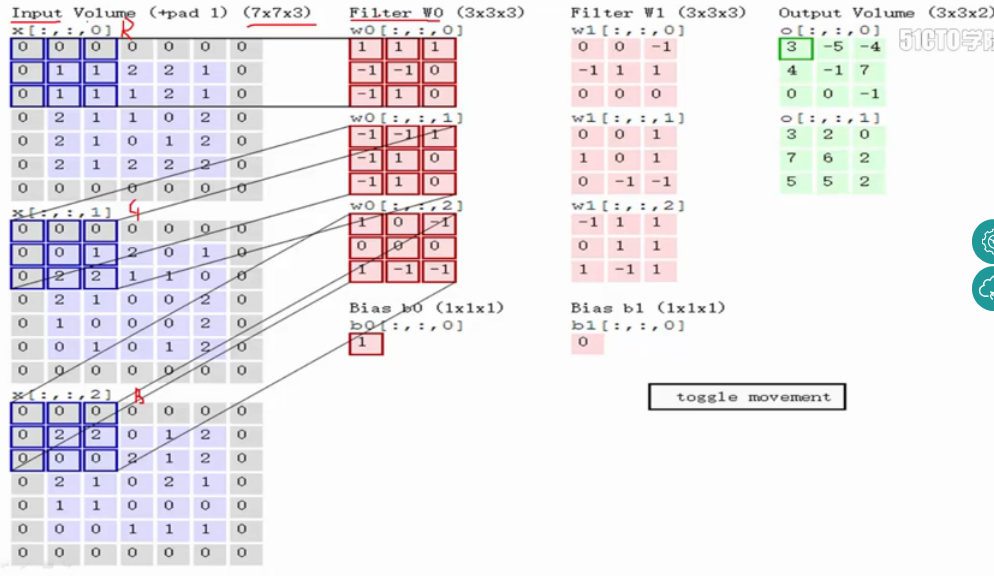
如图中所示,filter w0的第一层深度和输入图像的蓝色方框中对应元素相乘再求和得到0,其他两个深度得到2,0,则有0+2+0+1=3即图中右边特征图的第一个元素3.,卷积过后输入图像的蓝色方框再滑动,stride=2,如下图。
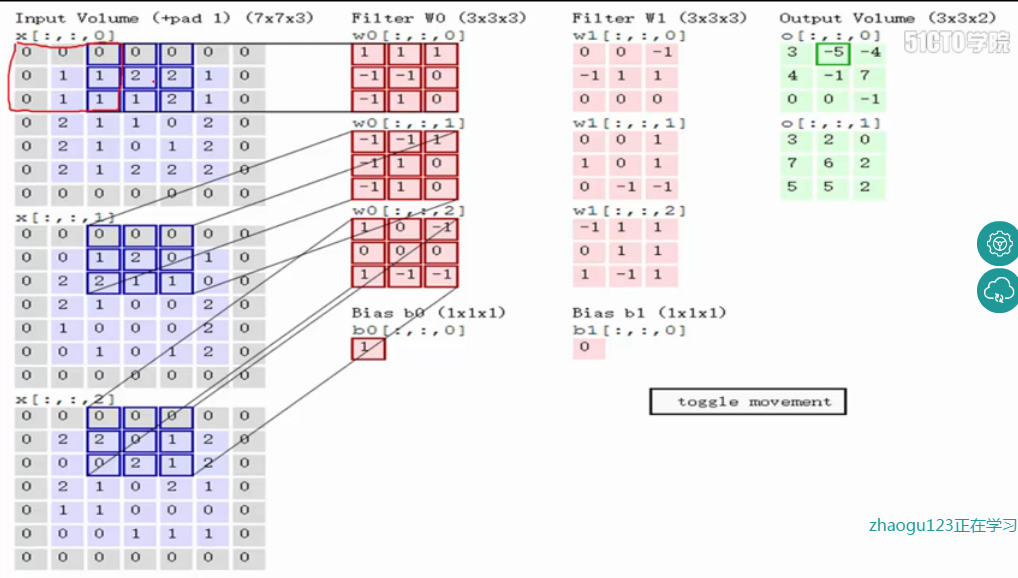
卷积层还有一个特性就是“权值共享”原则。如没有这个原则,则特征图由10个32*32*1的特征图组成,即每个特征图上有1024个神经元,每个神经元对应输入图像上一块5*5*3的区域,即一个神经元和输入图像的这块区域有75个连接,即75个权值参数,则共有75*1024*10=768000个权值参数,这是非常复杂的,因此卷积神经网络引入“权值”共享原则,即一个特征图上每个神经元对应的75个权值参数被每个神经元共享,这样则只需75*10=750个权值参数,而每个特征图的阈值也共享,即需要10个阈值,则总共需要750+10=760个参数。
补充:
(1)对于多通道图像做1*1卷积,其实就是将输入图像的每个通道乘以系数后加在一起,即相当于将原图中本来各个独立的通道“联通”在了一起;
(2)权值共享时,只是在每一个filter上的每一个channel中是共享的;
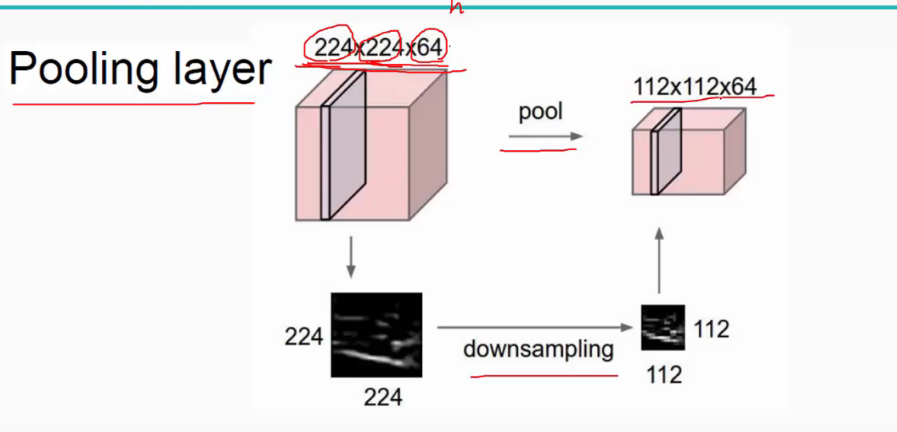
1.2 抽样层(池化层)
抽样层是将输入的特征图用nxn的窗口划分成多个不重叠的区域,然后对每个区域计算出最大值或者均值,使图像缩小了n倍,最后加上偏置量通过激活函数得到抽样数据。
用途:对输入的特征图进行压缩,一方面使特征图变小,简化网络计算复杂度;一方面进行特征压缩,提取主要特征。
池化操作一般有两种,一种是Avy Pooling,一种是max Pooling,如下:
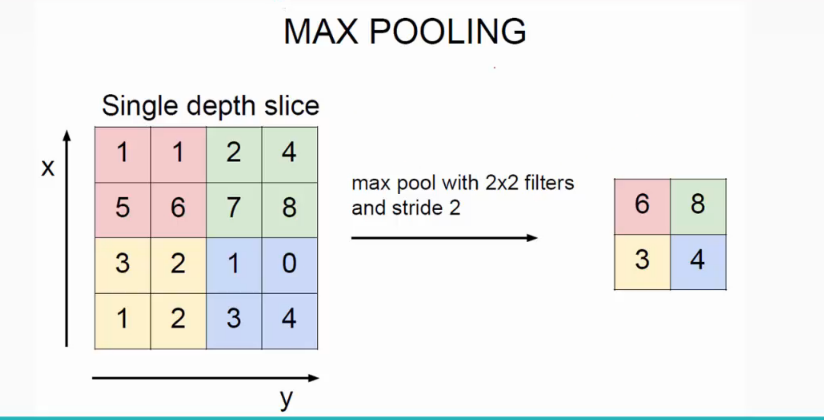
同样地采用一个2*2的filter,max pooling是在每一个区域中寻找最大值,这里的stride=2,最终在原特征图中提取主要特征得到右图。
(Avy pooling现在不怎么用了(其实就是平均池化层),方法是对每一个2*2的区域元素求和,再除以4,得到主要特征),而一般的filter取2*2,最大取3*3,stride取2,压缩为原来的1/4.
注意:这里的pooling操作是特征图缩小,有可能影响网络的准确度,因此可以通过增加特征图的深度来弥补(这里的深度变为原来的2倍)。
1.3 全连接输出层
全连接层则是通过提取的特征参数对原始图像进行分类。常用的分类方法如下式
yl=f(wlxl-1+bl)
式中xl-1为前一层的特征图,通过卷积核抽样提取出来的特征参数;wl为全连接层的权重系数;bl为l层的偏置量。
用途:连接所有的特征,将输出值送给分类器(如softmax分类器)。
1.4 总结
CNN网络中前几层的卷积层参数量占比小,计算量占比大;而后面的全连接层正好相反,大部分CNN网络都具有这个特点。因此我们在进行计算加速优化时,重点放在卷积层;进行参数优化、权值裁剪时,重点放在全连接层。
二 Backpropagation Pass反向传播
反向传播回来的误差可以看做是每个神经元的基的灵敏度sensitivities(灵敏度的意思就是我们的基b变化多少,误差会变化多少,也就是误差对基的变化率,也就是导数了),定义如下:(第二个等号是根据求导的链式法则得到的)
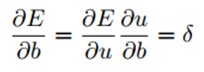
因为∂u/∂b=1,所以∂E/∂b=∂E/∂u=δ,也就是说bias基的灵敏度∂E/∂b=δ和误差E对一个节点全部输入u的导数∂E/∂u是相等的。这个导数就是让高层误差反向传播到底层的神来之笔。反向传播就是用下面这条关系式:(下面这条式子表达的就是第l层的灵敏度,就是)
公式(1)
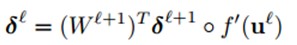
这里的“◦”表示每个元素相乘。输出层的神经元的灵敏度是不一样的:
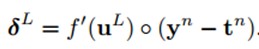
最后,对每个神经元运用delta(即δ)规则进行权值更新。具体来说就是,对一个给定的神经元,得到它的输入,然后用这个神经元的delta(即δ)来进行缩放。用向量的形式表述就是,对于第l层,误差对于该层每一个权值(组合为矩阵)的导数是该层的输入(等于上一层的输出)与该层的灵敏度(该层每个神经元的δ组合成一个向量的形式)的叉乘。然后得到的偏导数乘以一个负学习率就是该层的神经元的权值的更新了:
公式(2)
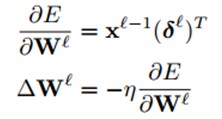
对于bias基的更新表达式差不多。实际上,对于每一个权值(W)ij都有一个特定的学习率ηIj。
三 Computing the Gradients梯度计算
假定每个卷积层l都会接一个下采样层l+1 。对于BP来说,我们知道,要想求得层l的每个神经元对应的权值的权值更新,就需要先求层l的每一个神经节点的灵敏度δ(也就是权值更新的公式(2))。为了求这个灵敏度我们就需要先对下一层的节点(连接到当前层l的感兴趣节点的第l+1层的节点)的灵敏度求和(得到δl+1),然后乘以这些连接对应的权值(连接第l层感兴趣节点和第l+1层节点的权值)W。再乘以当前层l的该神经元节点的输入u的激活函数f的导数值(也就是那个灵敏度反向传播的公式(1)的δl的求解),这样就可以得到当前层l每个神经节点对应的灵敏度δl了。
因为下采样的存在,采样层的一个像素(神经元节点)对应的灵敏度δ对应于卷积层(上一层)的输出map的一块像素(采样窗口大小)。因此,层l中的一个map的每个节点只与l+1层中相应map的一个节点连接。
为了有效计算层l的灵敏度,我们需要上采样upsample 这个下采样downsample层对应的灵敏度map(特征map中每个像素对应一个灵敏度,所以也组成一个map),这样才使得这个灵敏度map大小与卷积层的map大小一致,然后再将层l的map的激活值的偏导数与从第l+1层的上采样得到的灵敏度map逐元素相乘(也就是公式(1))。
在下采样层map的权值都取一个相同值β,而且是一个常数。所以我们只需要将上一个步骤得到的结果乘以一个β就可以完成第l层灵敏度δ的计算。
参考网址:https://blog.csdn.net/u010555688/article/details/38780767
二 实验分析
在本文中,实验结果和过程基于Tensorflow深度学习框架进行实现,数据源使用MNIST数据集,分别采用softmax回归算法和CNN深度学习进行模型训练。
2.1 CNN模型实现
结合LenNet-5神经网络模型,基于Tensorflow深度学习模型实现方式如下:
2.2 模型评价指标
采用常用的成本函数“交叉熵”,如下式所示:
Hy‘y=-iyi‘log(yi)
式中,y为预测的概率分布,y’为实际输入值。实现方法如下:(1)创建占位符输入正确值;(2)计算交叉熵
2.3 模型检验
预测结果检验方法:
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/195946.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
