大家好,又见面了,我是你们的朋友全栈君。
Exposing Deep Fakes Using Inconsistent Head Poses论文详记
原文链接:
https://ieeexplore.ieee.org/abstract/document/8683164.
一、论文简述
利用3D头部姿势误差检测DeepFake视频,属于基于帧内图像伪影的检测方法,使用低级语义层次特征+SVM分类器,属于浅层分类器方法。
二、论文内容
作者观察到,在DeepFake产生的过程中,会把生成的虚假人脸拼接到源视频图像中的人脸区域,在这个过程中,将不可避免地引入一种三维头部姿势误差,这种误差是基于深度神经网络人脸合成模型的内在局限性。具体来说,基于神经网络的额算法生成新的虚假人脸,同时在生成人脸中保持源人脸的面部表情,然而,这个过程中无法保证生成人脸和源人脸的面部LandMark(LandMark是人类面部一些重要结构的位置,比如眼镜、嘴角等)相一致。LandMark位置的误差可能不能直接通过肉眼察觉,但可以通过面部中真实部分和伪造部分(中心区域)的二维LandMark估计的头部姿势(即头部方向和位置)的差距来揭示。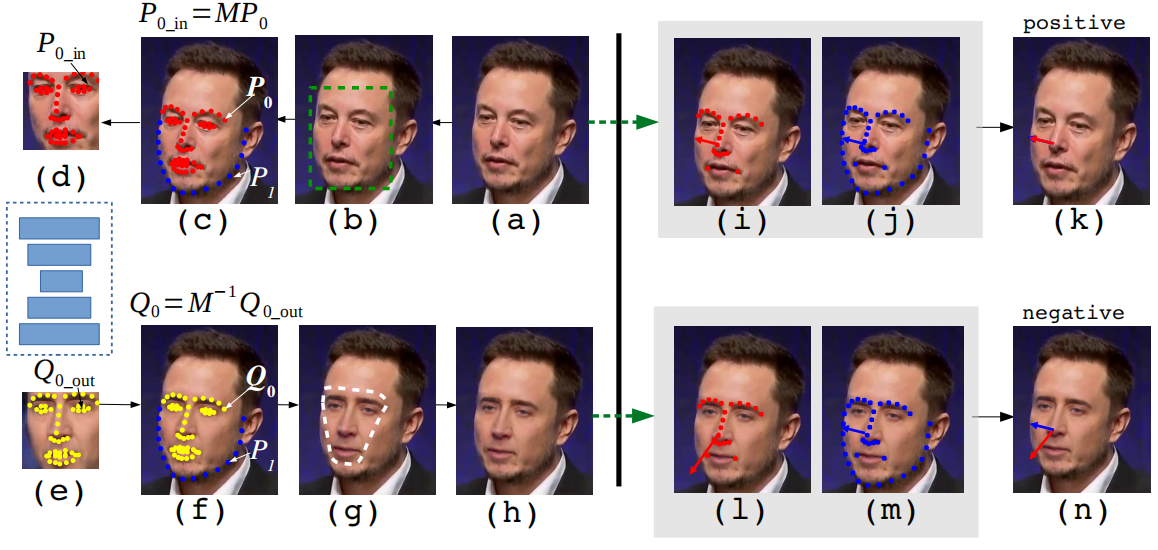

如上图所示,图左边是DeepFake的生成流,其中(a)是原始图像,(b)是图像中的人脸区域,(c)是检测出来的2D人脸LandMark,(d)对(a)中的人脸区域做仿射变换(旋转、缩放等),转化成标准化的脸部区域,(e)是深度神经网络合成的脸部区域,并保有(d)中的面部表情,(f)利用(d)中的逆仿射变换,将合成的面部区域匹配回源视频中的面部形状,(g)将合成的脸部融合进源图片中,得到(h)为虚假图片。图右边为本文方法的overview,其中上面一行对应于真实图片,下面一行对应于虚假图片。作者比较了使用整个脸部的LandMark(j和m)以及仅使用脸部中心区域的LandMark(i和l)估计的头部姿势,发现真实图片中两者差距不大,而虚假图片中两者在图像平面的投影方向不一致,由此,作者利用整个脸部的LandMark与中心区域的LandMark估计头部姿态的差异作为特征向量,训练了一个简单的基于SVM的分类器来区分真实视频和DeepFake视频。
A、三维头部姿势估计
三维头部姿势对应于真实坐标到相应相机坐标的旋转和平移。具体地,将[U,V,W]T表示为一个面部LandMark的真实坐标,[X,Y,Z]T表示为其相机坐标,(x,y)T表示为其图像坐标。真实坐标系和相机坐标系之间的转换可以表示为:
[ X Y Z ] = R [ U V W ] + t → (1) {\left[ \begin{array}{ccc} X \\ Y \\ Z \end{array} \right ]} = R { \left[ \begin{array}{ccc} U \\ V \\ W \end{array} \right ]} + \mathop{t}\limits ^{\rightarrow} \tag{1} ⎣⎡XYZ⎦⎤=R⎣⎡UVW⎦⎤+t→(1)
其中R是3×3的旋转矩阵, t → \mathop{t}\limits ^{\rightarrow} t→是3×1的偏移矩阵,则摄像机和图像坐标系之间的转化定义为:
s [ x y 1 ] = R [ f x 0 c x 0 f y c y 0 0 1 ] [ X Y Z ] (2) {s\left[ \begin{array}{ccc} x \\ y \\ 1 \end{array} \right ]} = R { \left[ \begin{array}{ccc} f_x & 0 & c_x\\ 0 & f_y & c_y\\ 0 & 0 & 1 \end{array} \right ]} { \left[ \begin{array}{ccc} X\\ Y \\ Z \end{array} \right ]} \tag{2} s⎣⎡xy1⎦⎤=R⎣⎡fx000fy0cxcy1⎦⎤⎣⎡XYZ⎦⎤(2)
其中 f x f_x fx和 f y f_y fy是X、Y方向上的焦距, ( c x , c y ) (c_x,c_y) (cx,cy)是光学中心, s s s是一个未知的缩放因子。
在三维头部姿势估计中,我们需要解决的是反向的问题,即使用从标准模型获取的同一组面部LandMark的二维图像坐标 ( x i , y i ) (x_i,y_i) (xi,yi)和三维真实坐标 ( U i , V i , W i ) (U_i,V_i,W_i) (Ui,Vi,Wi)来估计 s s s、 R R R和 t → \mathop{t}\limits ^{\rightarrow} t→。例如:假设相机参数已知(即 f x f_x fx、 f y f_y fy、 ( c x , c y ) (c_x,c_y) (cx,cy)已知),针对一个3D人脸模型,对于1组共n个面部LandMark,可以表述为以下一个优化问题:
m i n s , R , t → ∑ i = 1 n ∣ ∣ s [ x i y i 1 ] − [ f x 0 c x 0 f y c y 0 0 1 ] ( R [ U i V i W i ] + t → ) ∣ ∣ 2 \underset{s,R,\mathop{t}\limits ^{\rightarrow}}{min} \sum_{i=1}^n|| {s\left[ \begin{array}{ccc} x_i \\ y_i \\ 1 \end{array} \right ]} – { \left[ \begin{array}{ccc} f_x & 0 & c_x\\ 0 & f_y & c_y\\ 0 & 0 & 1 \end{array} \right ]} ( {R\left[ \begin{array}{ccc} U_i \\ V_i \\ W_i \end{array} \right ]} + \mathop{t}\limits ^{\rightarrow} )||^2 s,R,t→mini=1∑n∣∣s⎣⎡xiyi1⎦⎤−⎣⎡fx000fy0cxcy1⎦⎤(R⎣⎡UiViWi⎦⎤+t→)∣∣2
上面这个优化公式可以利用Levenberg-Marquardt算法有效地解决,得到估计的R是摄像机姿态,它是摄像机相对于真实世界坐标的旋转,则头部姿态是通过将其反转为RT(因为R是一个正交矩阵)来获得的。
B、DeepFake中头部姿势的不一致性
如上图(c)所示,DeepFake处理会将面部中心区域P0中的LandMark仿射变换为P0_in=MP0,通过生成模型后,其对应的LandMark在合成面部上是Q0_out。由于DeepFake中的生成神经网络不能保证LandMark的匹配,而且不同人有不同的面部结构,这便导致了Q0_out与P0_in具有不同的位置。通过比较795张64×64图像的51个中心区域LandMark,得出生成性神经网络中LandMark从输入到输出的平均偏移量为1.540像素,偏移标准差为0.921像素。经过逆变换后得到Q0=M-1Q0_out,显然虚假人脸中的标志点位置Q0也会不同于原始人脸中的标志点位置P0。
然而由于DeepFake处理中一般只替换面部的中心区域,面部外轮廓上的标志点位置不会改变,这种合成面部中心点和外轮廓点之间的不匹配被进一步揭示为由中心位置LandMark和整个面部LandMark估计的三维头部姿势的不一致。在真实图像中,中心区域和整个人脸区域的头部姿态差异较小,而在虚假图像中,中心区域和整个人脸区域的头部姿态差异较大。
作者进行实验来证实假设,为简单起见,只考虑头部方向向量。设 R a T R_a^T RaT是由整个脸部LandMark(下图中的红点加蓝点)估计的旋转矩阵,设 R c T R_c^T RcT是仅由面部中心区域LandMark(下图中的红点)估计的旋转矩阵
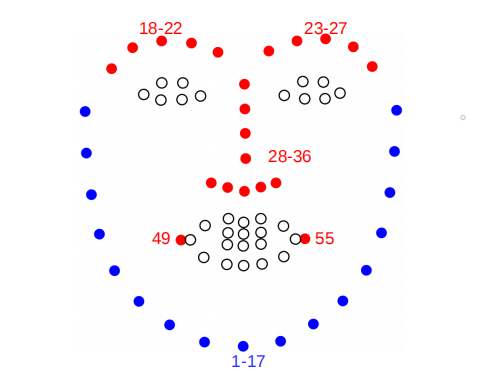
我们可以得到两种方法对应的头部方向的三维单位向量( w → = [ 0 , 0 , 1 ] T \mathop{w}\limits ^{\rightarrow}=[0,0,1]^T w→=[0,0,1]T,是真实坐标轴的W轴方向):
v a → = R a T w → , v c → = R c T w → \mathop{v_a}\limits ^{\rightarrow}=R_a^T\mathop{w}\limits ^{\rightarrow}, \mathop{v_c}\limits ^{\rightarrow}=R_c^T\mathop{w}\limits ^{\rightarrow} va→=RaTw→,vc→=RcTw→
之后我们比较 v a → \mathop{v_a}\limits ^{\rightarrow} va→和 v c → \mathop{v_c}\limits ^{\rightarrow} vc→之间的余弦距离,即: 1 − v a → ⋅ v c → / ( ∣ ∣ v a → ∣ ∣ ∣ ∣ v c ∣ ∣ ) 1-\mathop{v_a}\limits ^{\rightarrow}·\mathop{v_c}\limits ^{\rightarrow}/(||\mathop{v_a}\limits ^{\rightarrow}||||\mathop{v_c}\limits||) 1−va→⋅vc→/(∣∣va→∣∣∣∣vc∣∣),易知式子取值[0,2],当为0时, c o s θ = 1 cos{\theta}=1 cosθ=1,即 θ = 0 {\theta}=0 θ=0,此时 v a → \mathop{v_a}\limits ^{\rightarrow} va→与 v c → \mathop{v_c}\limits ^{\rightarrow} vc→方向一致。下图所示是一组原始图片和DeepFake图片中 v a → \mathop{v_a}\limits ^{\rightarrow} va→与 v c → \mathop{v_c}\limits ^{\rightarrow} vc→之间的余弦距离的统计直方图比较。
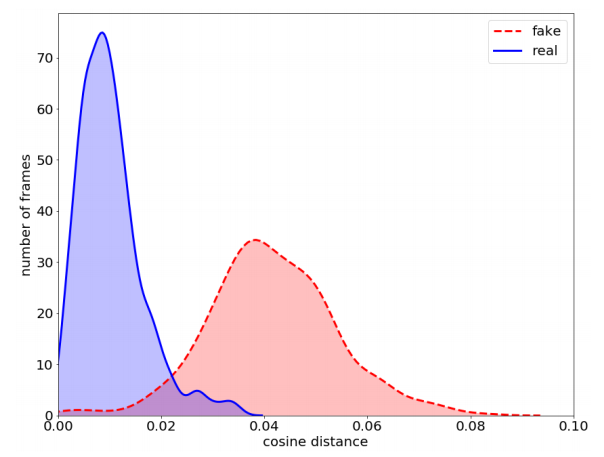
显而易见,真实图像估计的两个头部姿态向量的余弦距离集中在一个显著较小的范围内,最大值可达0.02,而对于DeepFakes,大多数值在0.02到0.08之间。 两个头部姿势向量的余弦距离分布的差异表明,它们可以根据这个线索进行区分。
C、基于头部姿势的分类
作者进一步利用上述分析训练了一个SVM分类。首先使用DLib工具包在每帧的图像中检测人脸并提取68个脸部LandMark,然后借助OpenFace2工具包,分别利用全脸特征点(蓝加红)和中心区域特征点(红)估计出头部姿势(作者将相机焦距近似为图像的宽度和高度,将光学中心近似为图像中心,即忽略了镜头畸变带来的影响),最后将获得的旋转矩阵之间的差距 ( R a − R c ) (R_a-R_c) (Ra−Rc)和平移矩阵之间的差距 ( t a → − t c → ) (\mathop{t_a}\limits ^{\rightarrow}-\mathop{t_c}\limits ^{\rightarrow}) (ta→−tc→)展平成向量,并减去均值,除以标准差达到归一化的效果,最终用于分类。
三、论文实验及结果
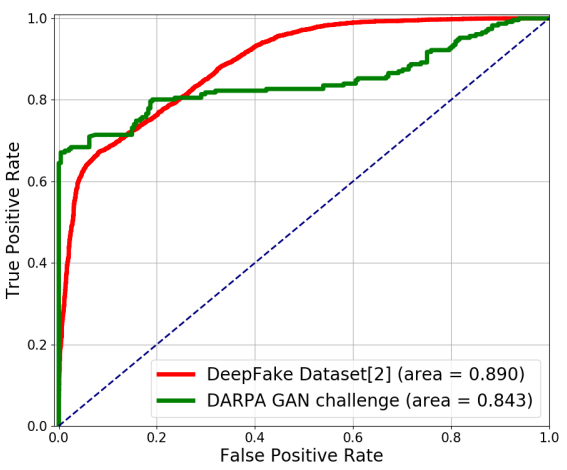
实验数据集:①UADFV;② DARPA MediFor GAN Image/Video Challenge
实验效果:以AUROC作为性能度量,分类特征为 ( R a − R c ) & ( t a → − t c → ) (R_a-R_c)\&(\mathop{t_a}\limits ^{\rightarrow}-\mathop{t_c}\limits ^{\rightarrow}) (Ra−Rc)&(ta→−tc→),效果如下图所示:
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/141502.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
