大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
原文链接::https://arxiv.org/abs/1707.01083
Abstract
论文提出了一种计算效率极高的卷积神经网络结构——ShuffleNet,它是专门为计算能力有限的移动平台设计的。这个新结构用来两个新操作——逐渐群卷积(pointwise group convulution)和通道混洗(channel shuffle)在保障精确率损失不大的同时大大减少了计算成本。基于ImageNet数据集的分类任务和MS COCO的目标检测任务上ShuffleNet都表现出了优于其他结构的性能,如 top-1 error 仅为7.8%,超越了之前MobileNet在ImageNet分类为任务的表现。
1. Introduction
为了解决主要的视觉识别任务,构建更深更大的卷积神经网络是一个基本的趋势,大多数准确率高的卷积神经网络通常都有上百层和上千个通道,需要数十亿的 FLOPS。这篇报告走的是另一个极端,在只有几十或者几百 FLOPS 的计算资源预算下,追求最佳的精度,目前的研究主要集中在剪枝、压缩和量化上。在这里我们要探索的是根据我们的计算资源设计一种高效的基本网络架构。
我们注意到最先进的网络结构(比如Xception和ResNeXt)中由于大量 1 x 1 卷积核耗费了过多计算资源,使得这种结构在小型网络中会变得效率很低。我们的目的是使用逐点群卷积来减小 1×1 卷积的计算复杂度,同时为了克服群卷积带来的副作用,我们提出了通道清洗来帮助信息流通。基于这两种技术,我们构建了一种叫做ShuffleNet的高效架构,在给定计算复杂度预算下,相比于其他流行的架构,我们的ShuffleNet允许使用更多的特征通道,这有助于编码更多的信息,尤其是对小型网络的表现这一点至关重要。
我们在ImageNet分类任务和MS COCO目标检测任务上评估了我们的模型,一系列可控制的实验都证明我们设计模型的优越性。我们也在一块基于ARM的计算核心上做了真实的硬件加速,ShuffleNet模型于AlexNet相比,在精度降低不大的同时实现了13倍的实际加速。
2. Related Work
2.1 高效模型设计
在过去的很多年里我们已经看到了深度神经网络在计算机视觉领域的巨大成功,其中模型设计扮演了重要的角色。在嵌入式设备上运行高品质模型的需求如日剧增,这也促进了高效模型设计方面的研究。 例如,与单纯的堆叠卷积层相比,GoogleNet在增加了网络深度的同时极大地降低了复杂度;SqueezeNet在保持精度的同时大大减少参数和计算量;ResNet利用高效的bottleneck结构实现惊人的效果;SENet介绍了一种结构单元降低了网络的计算成本。于我们的工作同时进行的一项工作是使用强化学习和模型研究来探索高效的模型设计。
2.2 群卷积
群卷积这个概念第一次是出现在用两个GPU运行AlexNet网络时,现在它已经在ResNetXt中展示了其高效性。Xception中提出的深度可分离卷积概括了Inception序列,最近的MobileNet使用深度可分离卷积实现了最先进的结果。我们的工作概括了群卷积和新形式的深度可分离卷积。
2.3 通道清洗操作
据我们所知,在高效模型设计上,先前的工作中很少提到通道清洗操作,尽管CNN cuda-convnet 支持 随机稀疏卷积层,这个等价于在随机通道清洗后面跟一组卷积层。这样的随机清洗操作有不同的目的,并且之后很少使用了。直到最近,另一个同时展开的工作也采用了这个想法用于一个两阶段的卷积层,然而它们没有调查通道清洗的有效性和其在小型网络设计上的通途。
2.4 模型加速
这个方向旨在保证预训练模型精确度的同时加速推理。常见的措施有修剪网络连接或通道数减少预训练模型中的冗余连接;量化或因式分解减少计算冗余加速推理;在不修改参数的前提下,通过FFT或者其他方法来优化卷积计算减少时间消耗;知识蒸馏是将在大模型中学到的知识迁移到小模型中使得小模型训练更加容易。
关于这部分的内容我在之前的博客中也有提到:https://blog.csdn.net/h__ang/article/details/88238734
三. Approach
3.1 针对群卷积做通道清洗
现代神经网络经常由多个相同结构的重复块组成。在它们之中,最先进的网络如Xception和ResNeXt在构建块时引入了高效的深度分离卷积和组卷积,使得其在性能和计算成本之间取得了平衡。然而我们注意到两个设计中都未完全采用 1 x 1 的卷积核,因为这需要考虑复杂度的问题。举个例子,在ResNeXt中仅仅对 3×3 的卷积核采用组卷积,因此在ResNeXt中对于每一个残差单元来讲逐点卷积占据了93.4%的计算量。在小型网络中,昂贵的逐点卷积导致有限的通道数满足计算的约束,这往往会损坏模型的精确度。
为了解决这个问题,一个最直接的方法就是应用通道稀疏连接,比如在 1×1 的卷积层上做组卷积,通过确保每个卷积操作仅作用在相应的输入通道上来减少计算成本。然而,如果多个组卷积堆叠在一起,就会产生一个副作用:一个确定通道的输出仅仅取决于输入通道的一部分,下图的(a)展示了两个堆叠组卷积层的情况,很明显一个确定组的输出仅与组内的输入有关,这样的性质阻止了不同通道组之间的信息流通,弱化了信息表达能力。
如果我们允许组卷积获得不同组的输入数据(正如下图(b)所示),这样的话输入和输出通道将会完全相关了。具体来讲,对于由上个组卷积层产生的feature map,我们将每个组的通道拆分为几个子组,然后将不同子组重新组合送入下一层。
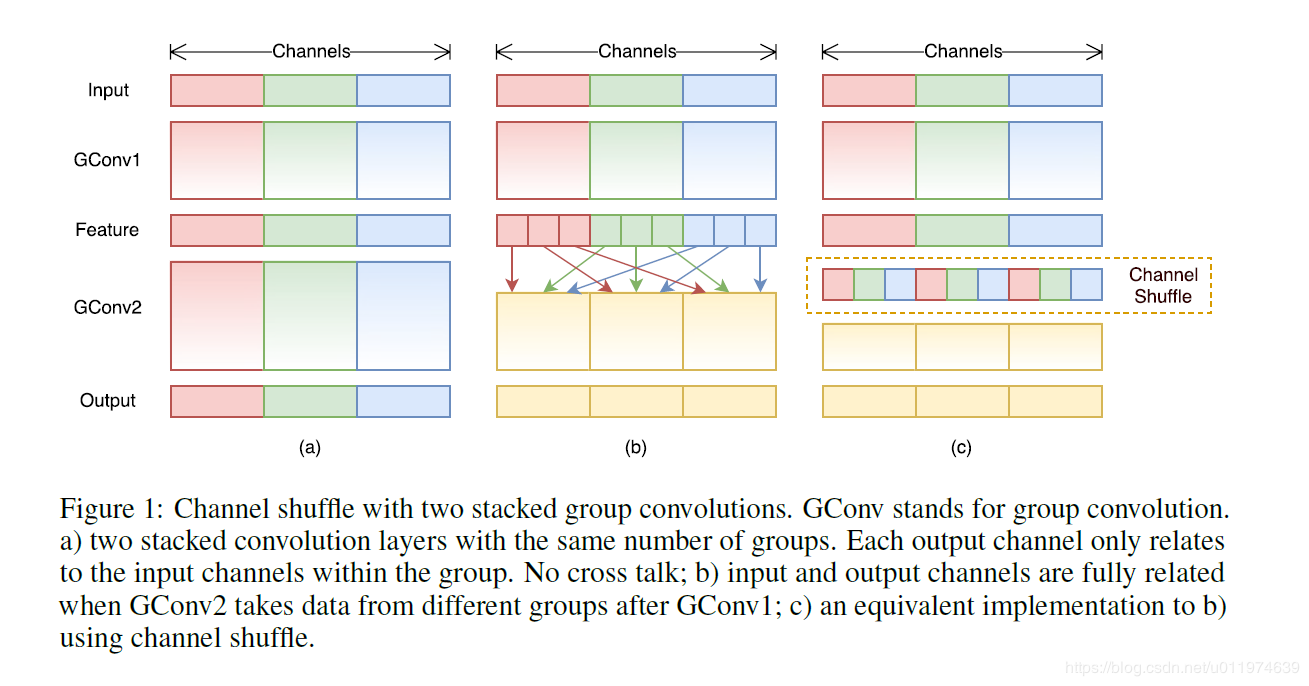

这个过程由一个叫做通道清洗的操作高效而优雅的实现(正如上图©)所示,步骤如下:
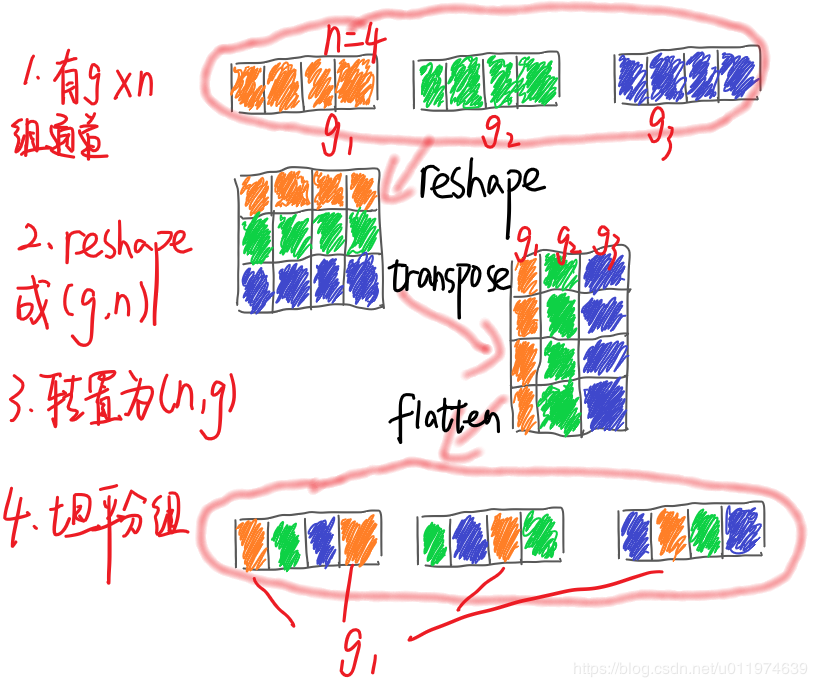
- 有g个组的卷积层进行划分使得输出有 gxn 个通道;(划分为g个组,每个组有n个通道)
- feature map reshape为(g, n);
- 将维度为(g, n)的feature map转置为(n, g);
- 平坦化之后分组送入下一层;(这时到底划分为几个组就取决于下一个组卷积的组数了)
用一组图来更加贴切的说明一下(还是盗别人的图,捂脸):
而且,通道清洗是可微分的,这意味着模型可以进行 end-to-end 的训练;通道清洗操作使得使用多个组卷积层构建更强大的结构成为可能,下一节中我们将会介绍一种带有通道清洗和组卷积的有效网络单元。
现在换一种思路来理解组卷积,假定输入的维度为 Hin x Win x Din,卷积核的维度为 h x w x Din x Dout,标准卷积的结果就是输出维度为 Hin x Win x Dout,它的每一个元素包含了所有输入通道的信息,因为它使用 h x w x Din 对 Hin x Win x Din 做卷积来得到每一个元素的;在做组卷积时,它是先把 h x w x Din x Dout 的卷积核分为 g 个组,那么每个组的维度为 h x w x (Din / g) x (Dout / g),这时每个组对应输入的一部分,比如第一个组对应的输入为 Hin x Win x [0: (Din / g)],第二组对应的输入为 Hin x Win x [(Din / g) : (2Din / g)],以此类推…,用每个组的卷积核和对应的输入做卷积得到 g 个 维度 Hin x Win x (Dout / g) 的输出,拼接在一起得到一个 Hin x Win x Dout 的输出。
其优点:
- 可以高效地进行训练,卷积倍分成多个路径,每个路径可由不同的GPU分开处理,所以模型可以并行方式在多个GPU上进行训练;
- 模型更加高效,即模型参数会随着分组数的增大而减少。举个例子,在上面的陈述中标准卷积有 h x w x Din x Dout 个参数。具有 g个分组的组卷积的参数量为 h x w x (Din / g) x (Dout / g) x g = h x w x (Din / g) x Dout,减少了g倍;
- 分组卷积也许能提供比标准完整 2D 卷积更好的模型,原因和稀疏过滤器的关系有关。
参考文献:https://zhuanlan.zhihu.com/p/57575810
3.2 ShuffleNet单元
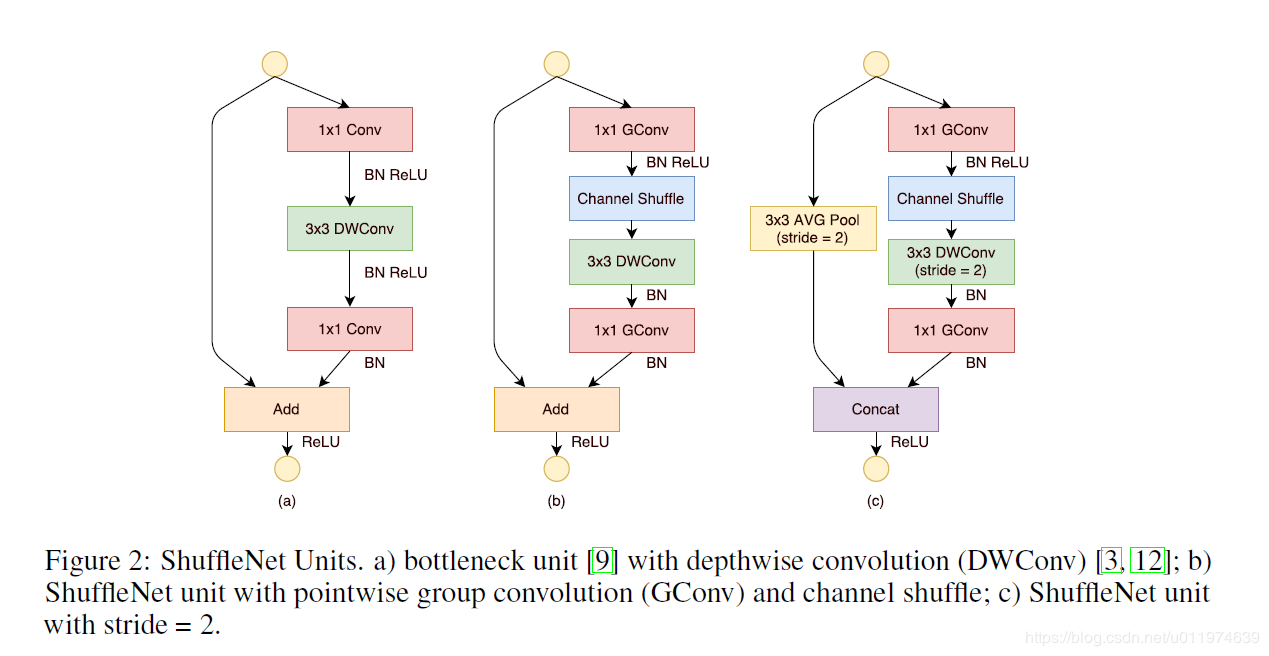 我们专门为小型网络提出了一种新颖的ShuffleNet单元,我们从上图(a)开始,这是一个残差块,在主分支的 3×3 卷积层我们使用了深度卷积,接着,我们用 1×1 的 组逐点卷积 和通道清洗取代第一个1×1卷积层得到图(b),第二个组逐点卷积的目的是恢复通道维度让其和shortcut匹配上,第二个组卷积后面没有加上通道清洗,除此之外,3×3 深度卷积层后面也没有过ReLU函数了;至于ShuffleNet中应用步长的情况,我们简单地做了两点修正:
我们专门为小型网络提出了一种新颖的ShuffleNet单元,我们从上图(a)开始,这是一个残差块,在主分支的 3×3 卷积层我们使用了深度卷积,接着,我们用 1×1 的 组逐点卷积 和通道清洗取代第一个1×1卷积层得到图(b),第二个组逐点卷积的目的是恢复通道维度让其和shortcut匹配上,第二个组卷积后面没有加上通道清洗,除此之外,3×3 深度卷积层后面也没有过ReLU函数了;至于ShuffleNet中应用步长的情况,我们简单地做了两点修正:
- 在shortcut路径上添加了一个 3×3 的平均池化层;
- 使用通道拼接代替(b)中的元素相加,在扩大通道的同时增加的计算成本却很少;
多亏了通道清洗和群逐点卷积,在ShuffleNet单元中的所有元素才可以高效地计算。与ResNet和ResNeXt相比,我们的结构在相同的配置下计算复杂度更低。举个例子,给定维度为 c x h x w 的输入,c为输入层的通道数,bottleneck的通道为m:
- ResNet单元需要的计算量为 hw(2cm + 9m**2)
- ResNeXt单元需要 hw(2cm + 9m**2/g) FLOPS,
- ShuffleNet单元仅仅需要 hw(2cm/g + 9m) FLOPS,这里的g是卷积层的分组数。
换句话来讲,在给定计算预算的限制下,ShuffleNet可以使用更宽的特征映射。我们发现这对小型网络很重要,因为小型网络没有足够的通道传递信息。
另外我们还发现了一个问题,ShuffleNet的深度卷积仅仅作用在bottlenet上,这是由于深度卷积虽然理论上的计算复杂度很低,但是与其他密集型卷积相比其计算/存储访问的效率很差。其原因在于两点:
- depthwise的卷积核复用率比普通卷积要小很多,内存中的置换率也比普通卷积高;
- depthwise的卷积是per channel的,每个卷积的操作矩阵都很小,这麽小的矩阵不容易得到充分并行。
3.3 Network Architexture
基于上面的ShuffleNet单元,我们提出了ShuffleNet的整体结构如下表一:
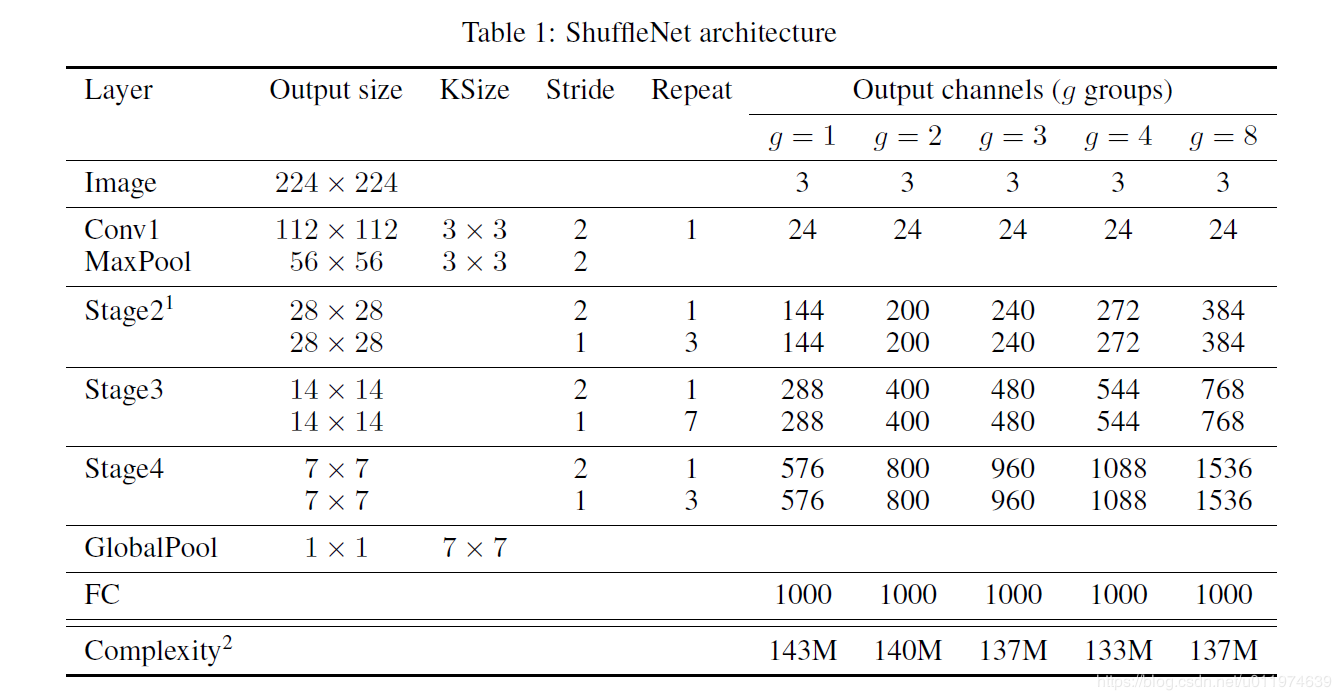 网络主要由三个阶段的ShuffleNet单元堆叠组成,在每个阶段的第一个组成层的步长都是2,同一个阶段内的其它超参数是保持相同的,下一个阶段的输出通道数相对于上一个阶段翻倍,特征尺寸相对于上一个阶段减半。
网络主要由三个阶段的ShuffleNet单元堆叠组成,在每个阶段的第一个组成层的步长都是2,同一个阶段内的其它超参数是保持相同的,下一个阶段的输出通道数相对于上一个阶段翻倍,特征尺寸相对于上一个阶段减半。
在ShuffleNet单元中,组数g控制着逐点卷积连接的稀疏性,表1探索了不同组数的影响,在实验中我们对不同组数采用不同的输出通道数保证整体的计算复杂度基本不变(大约140MFLOPS)。很明显,在给定的计算复杂度约束下较大的组数可以有更多的输出通道数,着帮助我们可以编码很多的信息,然而太多的组数也有可能导致组内信息过少,丢失精度。
为了将网络定制到所需要的复杂度,我们简单地在通道数上应用一个比例因子s,举个例子,我们将表1中的网络定义为”ShuffleNet 1x”,那么”ShuffleNet sx”就是将ShuffleNet 1x中的卷积核的通道数缩减s倍,这将会导致网络的计算复杂度整体缩减s**2倍。
四. Experiments
我们在ImageNet 2012分类数据集上对模型进行了评估,我们遵循了ResNet的大多数训练参数设置,除了两点:
- 我们将权重衰减率由1e-4改为4e-5;
- 在数据预处理时使用较少的aggressive scale增强;
这是由于在小模型往往会欠拟合而不是过拟合,我们在4块GPU上花了1-2天对模型进行了 3 x 10**5迭代,batchsize为1024。为了进行基准测试,我们在ImageNet验证集上比较了top-1 的表现,将原来 的图片尺寸裁剪为 224 x 224。
4.1 Ablation Study
ShuffleNet的核心观点就在于逐点组卷积和通道清洗,在这个子部分我们对其进行评估。
4.1.1 逐点组卷积
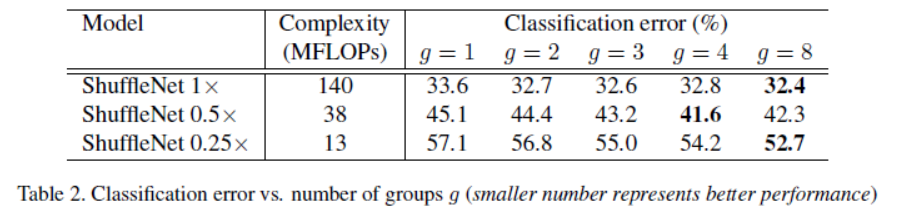 同一行表示的是相同的计算复杂度下,不同组数下的分类错误率,可以看到随着组数g的增大,一般情况下错误率会下降,因为分组越多,意味着可以从更多的通道数中获取信息。但是同时也有例外,当g增大到一定程度时错误率会上升,这是因为组数太多时组内信息过少,丢失精度,总的而言,越小的模型更倾向于需要更大的分组数。
同一行表示的是相同的计算复杂度下,不同组数下的分类错误率,可以看到随着组数g的增大,一般情况下错误率会下降,因为分组越多,意味着可以从更多的通道数中获取信息。但是同时也有例外,当g增大到一定程度时错误率会上升,这是因为组数太多时组内信息过少,丢失精度,总的而言,越小的模型更倾向于需要更大的分组数。
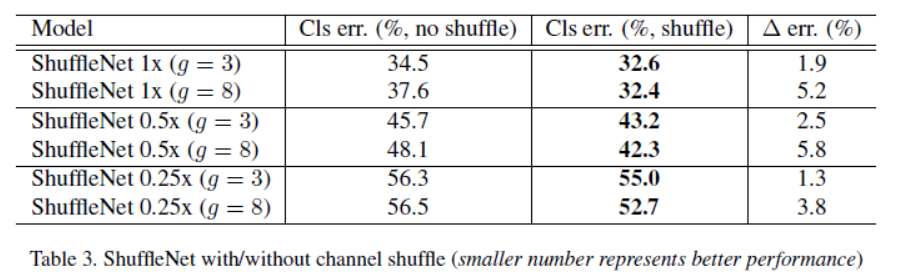
4.1.2 Channel Shuffle vs. No Shuffle
通道清洗的目的是对于多组卷积层进行跨层的信息流动,下表展示了不同ShuffleNet结构下的模型准确率:
4.2 Comparison with Other Structure Units

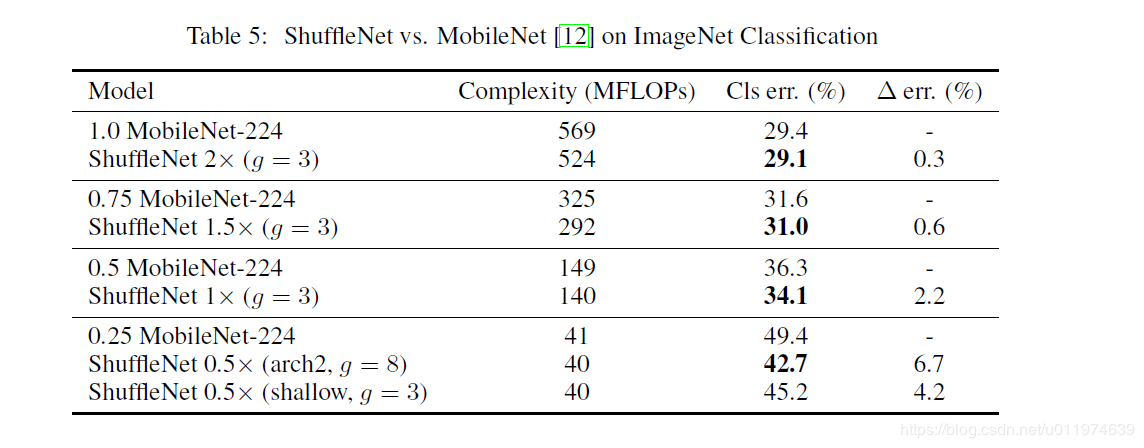
4.3 Comparison with MobileNets and Other Frameworks
与MobileNets相比:
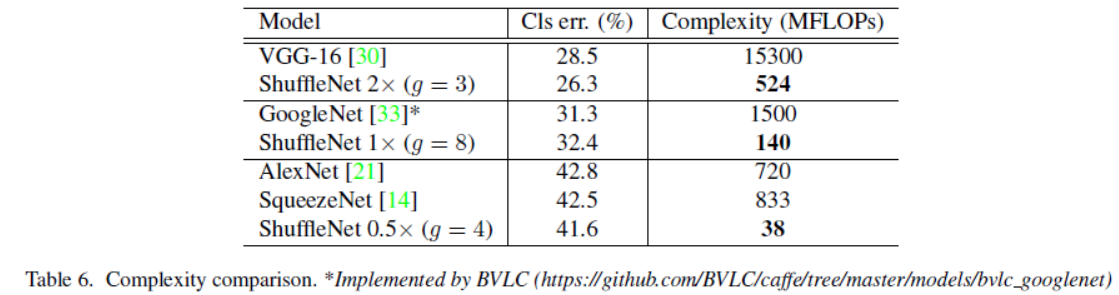
 与其他一些流行架构相比:
与其他一些流行架构相比:
4.4 Generalization Ability
table7展示了两种分辨率不同的输入下不同结构的表现:

4.5 Actual Speedup Evaluation
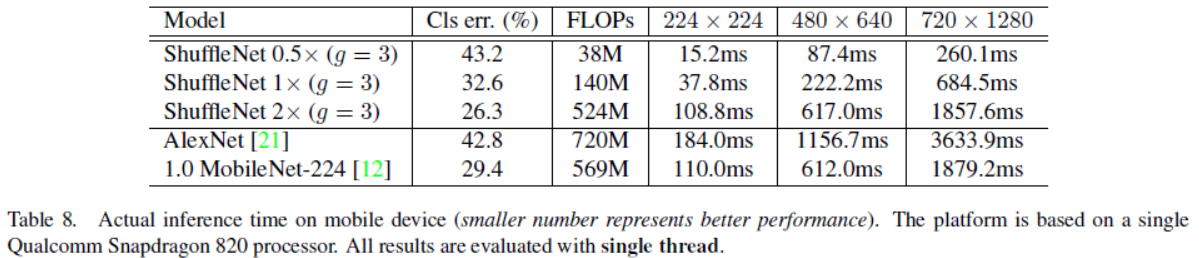
最后,我们在ARM的平台上评估了真实的推理速度,尽管越大的分组数理论上会有更好的表现,但是在实际实施时却没有想象中的效率高,经验认为g=3通常会在准确率和实际推理时间之间取得平衡。由于内存访问和其他的一些开销,理论上4倍的计算复杂度的减少经常只会带来 2.6倍的实际速度的提升。尽管如此,与AlexNet相比,我们的ShuffleNet 0.5x 模型在同一个计算复杂度下依然有13x的速度提升。
参考文章:
[1] https://blog.csdn.net/u011974639/article/details/79200559
[2] Diagonalwise Refactorization: An Efficient Training Method for Depthwise Convolutions
源码链接:https://github.com/MG2033/ShuffleNet
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/195554.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
