大家好,又见面了,我是你们的朋友全栈君。
目录
5.dropout(0.5*0.5*0.5)+BN(without biases):
关于snapshot(ckpt)的优化——ensemble:
概要:
问题来源:
kaggle的一个表情识别的训练集。
题目的发起者也是用三个竞赛发起了一篇论文。ICML的表示学习专题
https://arxiv.org/abs/1307.0414
论文对此比赛的说明:
在本次比赛中,我们想比较一个研究得很好但使用全新数据集的任务的方法。这避免了过度拟合重复使用的基准数据集的测试集的问题。举办这种竞赛的一个原因是,它允许我们以尽可能公平的方式将特征学习方法与手工设计的特征进行比较。这个数据集是一个大型项目的一部分,是用谷歌的人脸识别API获得的,进行了各种边界处理、去重和裁剪的48*48灰度图(所以其实自己能做的数据增强选项不多)。fer2013有采集错误,人类也只有65%+-5%的准确度。
JamesBergstra还确定了“空”模型的最佳性能,该模型由一个卷积网络组成,除了最后的分类器层之外,没有任何学习。通过使用TPE超参数优化算法,他发现这种最佳卷积网络的精度达到60%。使用这样的组合模型,他获得了65.5%的准确率。详见[13]。
前三个团队都使用卷积神经网络[14]对图像转换进行歧视性训练。胜利者Yichuan Tang,他将SVM的primal objective作为loss去训练,然后加了一个L2-SVM的loss。这是一种在竞赛数据集等方面取得了巨大成果的新发展。
选择原因:
选这个fer2013数据集的主要原因,主要是觉得适合拿来练手。
fer2013的图形比MNIST复杂一些,MNIST随便用一个简单模型,全连接层强行记忆就几乎完全拟合,做一些额外的改进可能根本看不到区别。
fer2013比ImageNet比,又简单的多,不至于因为显卡危机而把时间都浪费在等待上,调两个参数,估计什么都凉了。
实际测下来,fer2013训练集与测试集有一定差距,难以达到理想的泛化效果,所以用各种优化都能明显、或者比较明显的看到实际的改进,反馈好,很适合学习。(至少在我接触的数据集中,算是比较合适的一个)
实现与优化思路:
第一的模型能达到71%,但是结构特殊;
其他有cliquenet,不是典型DenseNet;
还有VGG,不过VGG用的数据集不同,还有1000类,感觉微调应该不够用,而且训练也会很慢;
我打算先用普通卷积网络加交叉熵来做,看能到多少,再考虑后续优化。。

前置:
数据处理:
这套fer2013数据本身问题还是比较多的。各种水印、卡通、抽象加遮挡。根据官方说法,训练数据和测试数据差距也较大。

全流程的数据操作,三部分。
原csv数据的读取与分割:
csv读取解析存储等。
csv数据转图片和tfrecord的存取:
csv的字符串数据,经过处理,以图片文件和文件名-标签列表的形式存在。
最后将图片和标签一起存入tfrecord。
这块细节比较多,好好调一下。
tfrecord接生产队列供模型训练:
线程协调器,生产者队列,生产者直接从文件读取数据,存入队列,模型直接从队列拿数据
神经网络定义:
根据lenet5和alexnet进行变形:
因为fer2013的图形是48*48*1的,比mnist大的多,lenet-5是针对mnist的24*24的,本文围绕Lenet5进行改造,增加卷积层数和全连接层数(),加入dropout、Regularization、BN、data augmentation等。
卷积核大小,5*5,三层。三层通道数64,64,128,conv配套ReLU、pooling和BN。FC层大小512.
网络结构如下
| layer | k_size | stride | padding | k_num | output_size |
| input | b,48,48,1 | ||||
| conv_1 | 5*5 | 1*1 | SAME | 64 | b,48,48,64 |
| poolling_1 | 3*3 | 2*2 | SAME | b,24,24,64 | |
| conv_2 | 5*5 | 1*1 | SAME | 64 | b,24,24,64 |
| poolling_2 | 3*3 | 2*2 | SAME | b,12,12,64 | |
| conv_3 | 5*5 | 1*1 | SAME | 128 | b,12,12,128 |
| poolling_3 | 3*3 | 2*2 | SAME | b,6,6,128 | |
| flatten | b,4608 | ||||
| FC_1 | 512 | b,512 | |||
| FC_2 | 512 | b,512 | |||
| output | 7 | b,7 |
卷积核5*5,stride1*1,stride小为了更好更细的提取特征。
池化层3*3,stride2*2,池化本来就是要降采样缩小特征图,所以stride=2,池化核3*3重叠是为了边缘平滑。
关于感受野的计算:
一个3*3的卷积核,感受野3*3,两层3*3的卷积核组合起来,感受野就是5*5,间接等效于一个5*5的卷积核,而且因为多了一次非线性转换,其实拟合效果还要更好一些。(三层3*3的感受野是7*7)
一个5*5的卷积核,感受域是5*5,两层5*5的感受野就是9*9,三层是13*13,每多一层就+k_size-1,其实如果中间组合了pooling,感受野还是会进一步扩大的,经过一层pooling,感受野类似double的效果。下面计算一下:
第一层卷积:1+(5-1)=5
第一层池化:5+(3-1)=7
基本特征跨度double
第二层卷积:7+(5-1)*2=15
第二层池化:15+(3-1)*2=19
基本特征跨度double
第三层卷积:19+(5-1)*4=35
第三层池化:35+(3-1)*4=43,
输出pool3,一个点的感受野是43,移动一位跨度8,2*2的特征图即可覆盖51*51的原图,足够覆盖fer2013的48*48,实际pool3输出是6*6,留有余量,这里是可以适当缩减卷积核的,只是没太大必要,时间关系,就不实验了(也有好处,比如减少了参数数量,增加了训练速度)。
损失函数:
交叉熵+(全连接层)L2正则化
滑动平均(EMA):
加“惯性”,让weights和biases变动更平缓,避免个别batch造成的过大波动,加速收敛,也能保证测试结果比较稳定。
EMA又叫影子变量,影子之所以叫影子,是因为他会跟在变量的后边变化。
注意事项:如果想用影子变量做预测,注意你恢复的变量是不是影子变量。ema.variables_to_restore()是用来干这个的,指定一个映射,用影子变量替代原变量。
EMA笔记和示例:
https://blog.csdn.net/huqinweI987/article/details/88241776
训练与优化过程:
基本设置:
学习率:
如果算力有限,初期学习率可以适当高一点,方便观察,及时调整。
后期学习率当然可以低一点,个人觉得分界线在过拟合吧,如果一个模型能学到过拟合的水平(本例是准确率70+),学习率就不用往高去调了,有算力的话,还可以再低一些。
学习率的decay,如果不监控,可能导致后期学习率过低,跟踪一下,然后可以加入一个保底。
如果中途想调整模型,也不想重新训练,断点续训,需要重新调整基础学习率来中和一下,不然学习率低到见不到任何改变。
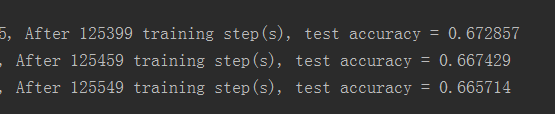
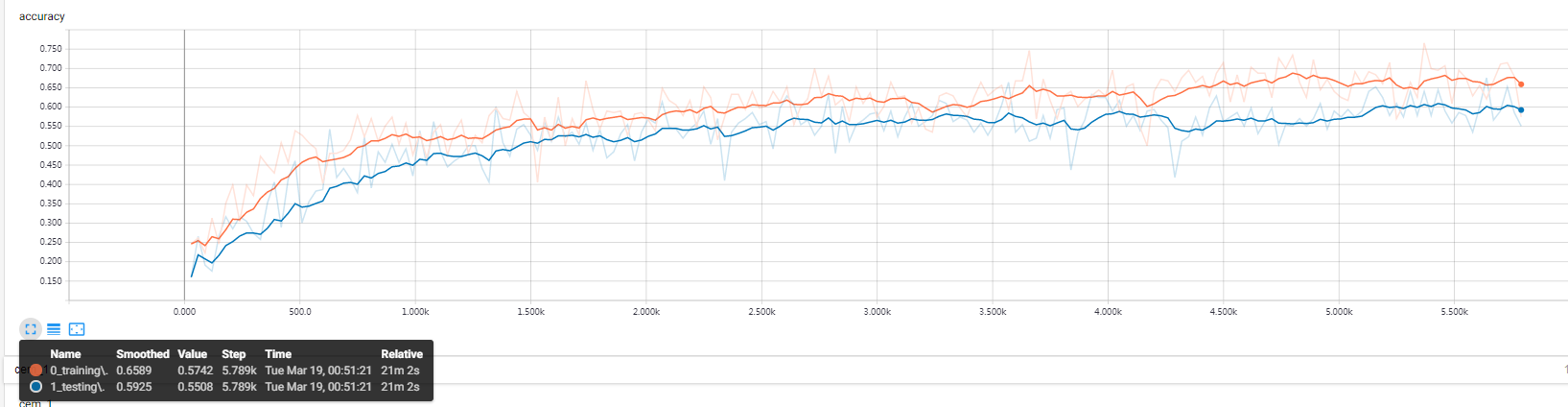
2019-03-16 15:39:46 : After 244799 training step(s),lr is 1.49615e-13 loss,accuracy on training batch is 0.857955 , 0.746094.
After 244799 training step(s), test accuracy = 0.644531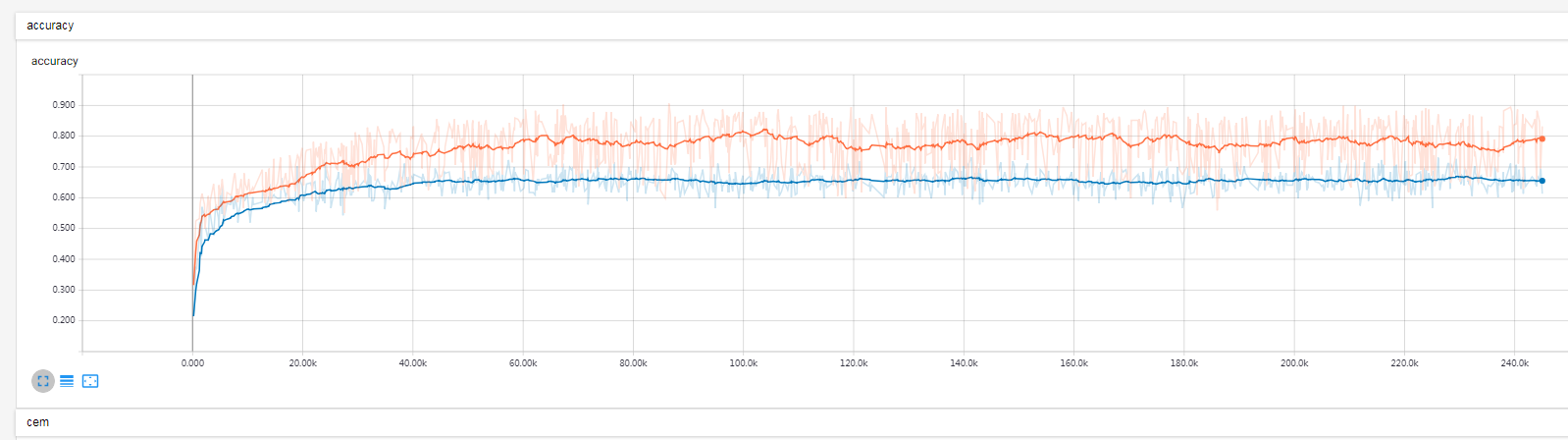
曲线已经不容易发生变化
LEARNING_RATE_BASE = 0.0005改为LEARNING_RATE_BASE = 0.052019-03-16 15:44:13 : After 244859 training step(s),lr is 1.48118e-11 loss,accuracy on training batch is 0.630326 , 0.839844.
After 244859 training step(s), test accuracy = 0.640625这样学习率就提升两个数量级,具体调整到多少,根据需求。
batch_size:
暂时用虚拟机,没法GPU,第一次BATCH小了,一直到结束,只有34(中间也跳了一次40,但是因为batch小,没说服力)

把batch改为128:
第一次就36了,训练1000次以后在五十上下:

补充:最后改到了双GTX1060 3G,不使用专门的并发逻辑,只触发单卡,能支持256,再翻倍到512就超了。
训练次数:
BATCH_SIZE = 128
train_num_examples=28709
225个step对应一个epoch。
前边设置1000次训练太少了,提升训练次数:
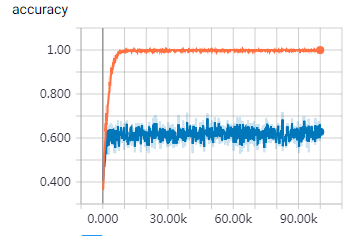
两万step的时候,已经接近1了,因为理论上达不到这么高,所以这是过拟合了,再用测试集对比一下

改了网络的变量命名,第二次训练又死机了,卡在6000次的时候,先以6000次为基准做个对照:
训练集的mini-batch准确率如下:

测试集的准确率如下:
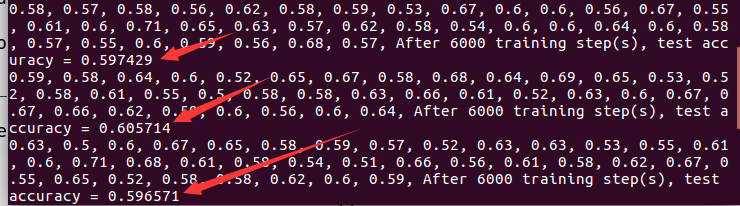
过拟合明显,所以打算先从dropout入手改善
Dropout:
消除过拟合的一种手段,每次通过不同神经元,使每个神经元都可能被训练到,避免路径依赖,有一种ensemble的作用。详细对比放在dropout和BN实验。
BN:
第一个版本用了一下lrn,lrn是激活和pooling之后使用,后边的版本我会替换成BN,BN在激活函数前使用。
实测替换BN后在同样的训练次数下准确率好于之前的lrn,虽然relu正轴斜率是1,相比sigmoid弱化了一部分预防梯度爆炸的效果,但是整体来说BN对于改善分布和提升训练效率还是很有效的。
实验对比(无LRN且无BN对比有BN,不是LRN对比BN):
使用BN前,可以看到三层卷积层的激活输出relu1、2、3,一个比一个萎缩,两层FC的输出也不太好。使用BN后(图二),conv层激活RELU3的输出分布明显好转,仔细看FC层y1、y2的数值分布,深色区域训练初期1.5+,训练后期1.5-,明显好于图一,而图一大多数深色区域小于1。
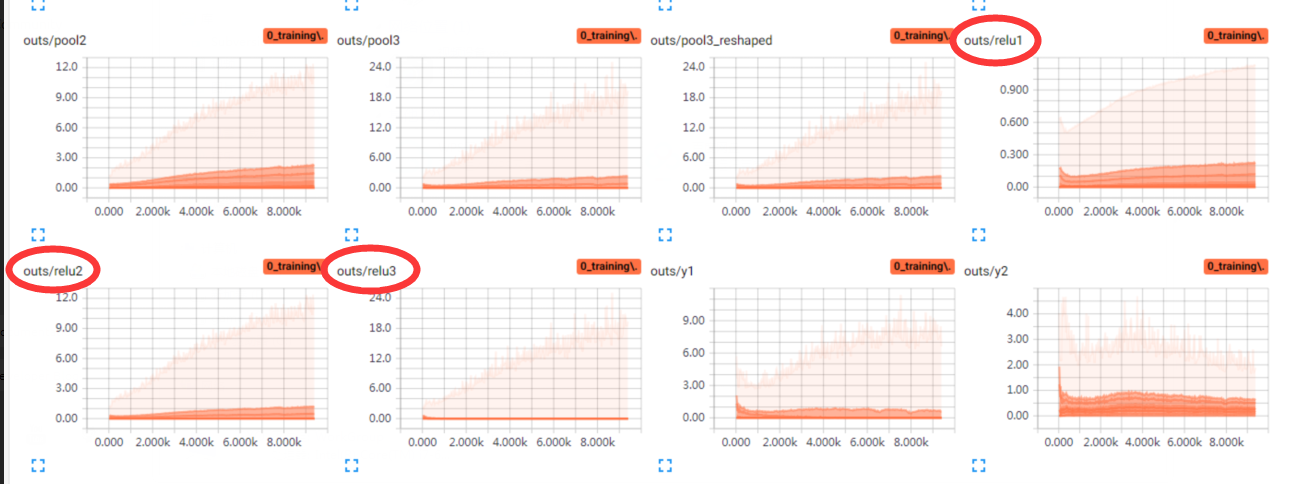
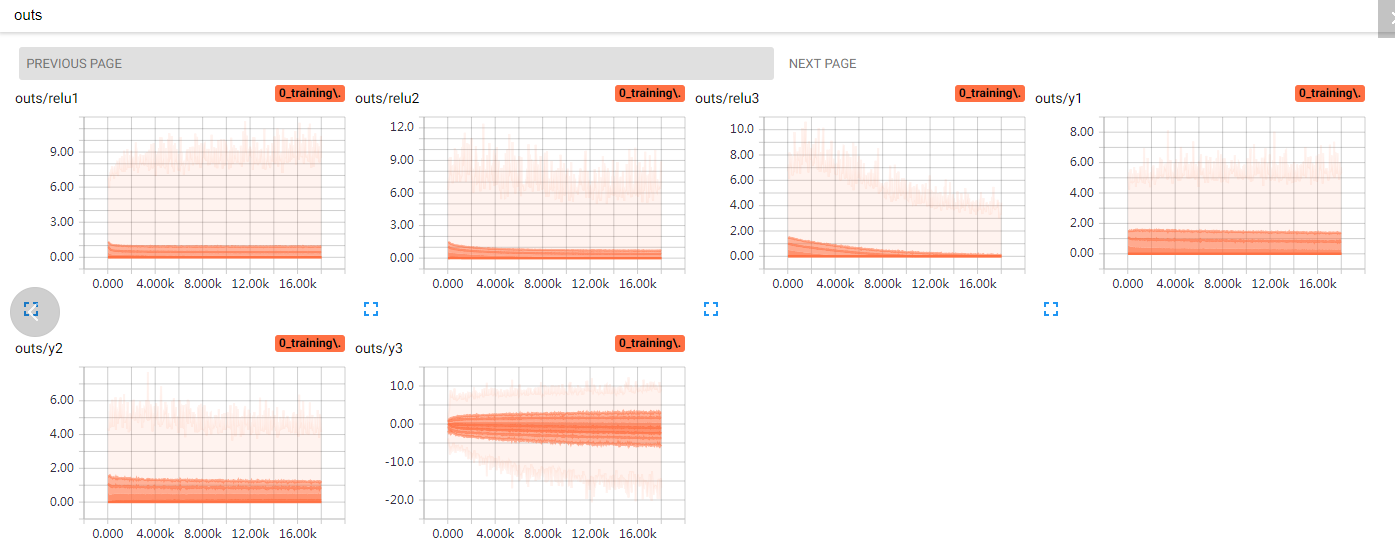
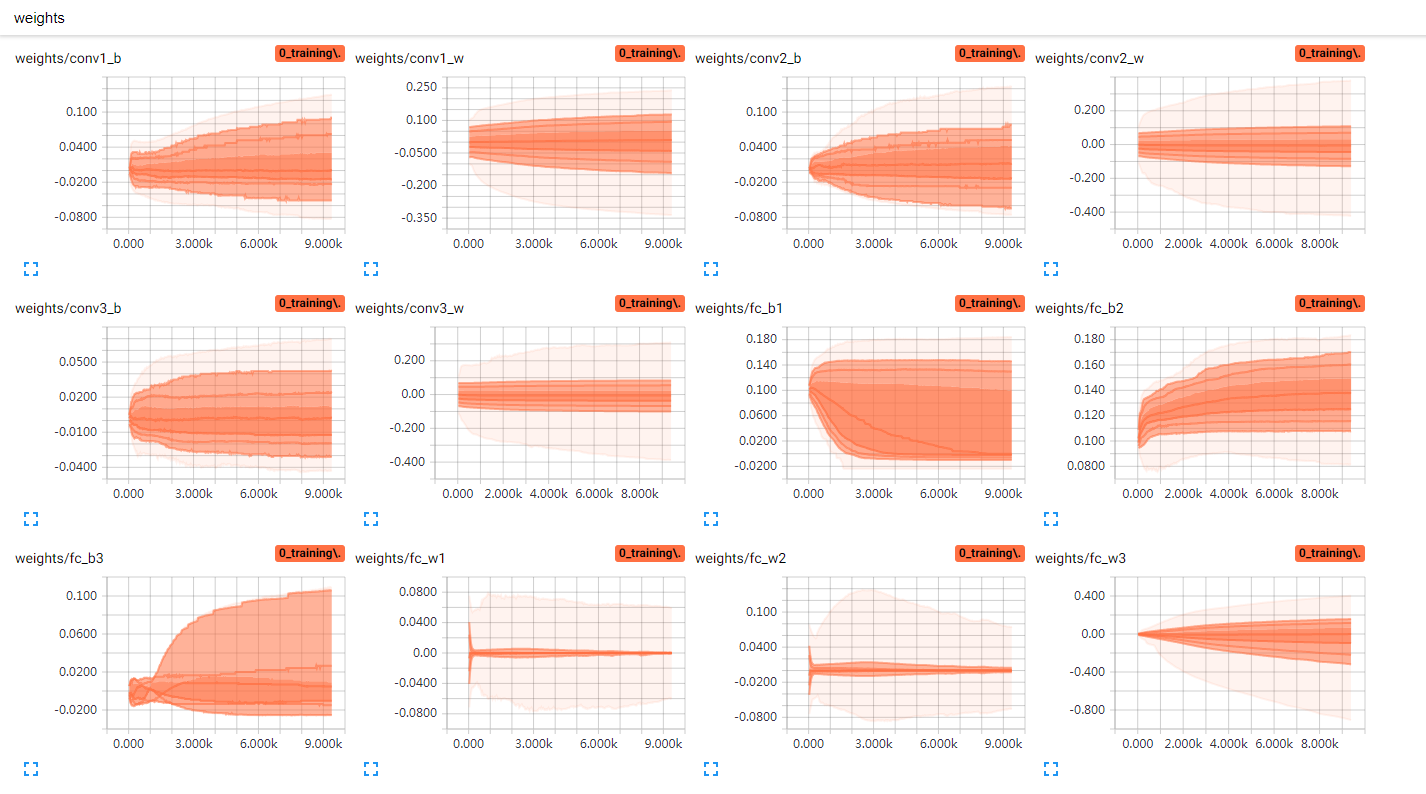
然后是变量的区别,使用BN前,训练过程中,变量weights范围变化大,biases有大范围的偏移,说明参数要迁就数据,使用BN后(图二),仔细观察刻度,无BN的模型,卷积层的模型w深色部分超过0.1,变化幅度也大,有BN模型不超过0.1,而且有BN的模型,weights范围也很早就平稳下来,说明weights需要的范围也更小,容易达到,收敛速度更快(图二biases皆为固定值0.1,因为在BN前取消掉了biases,短路闲置了,打印出来验证而已,只有fc_b3因为对应最终分类输出,没有做BN)
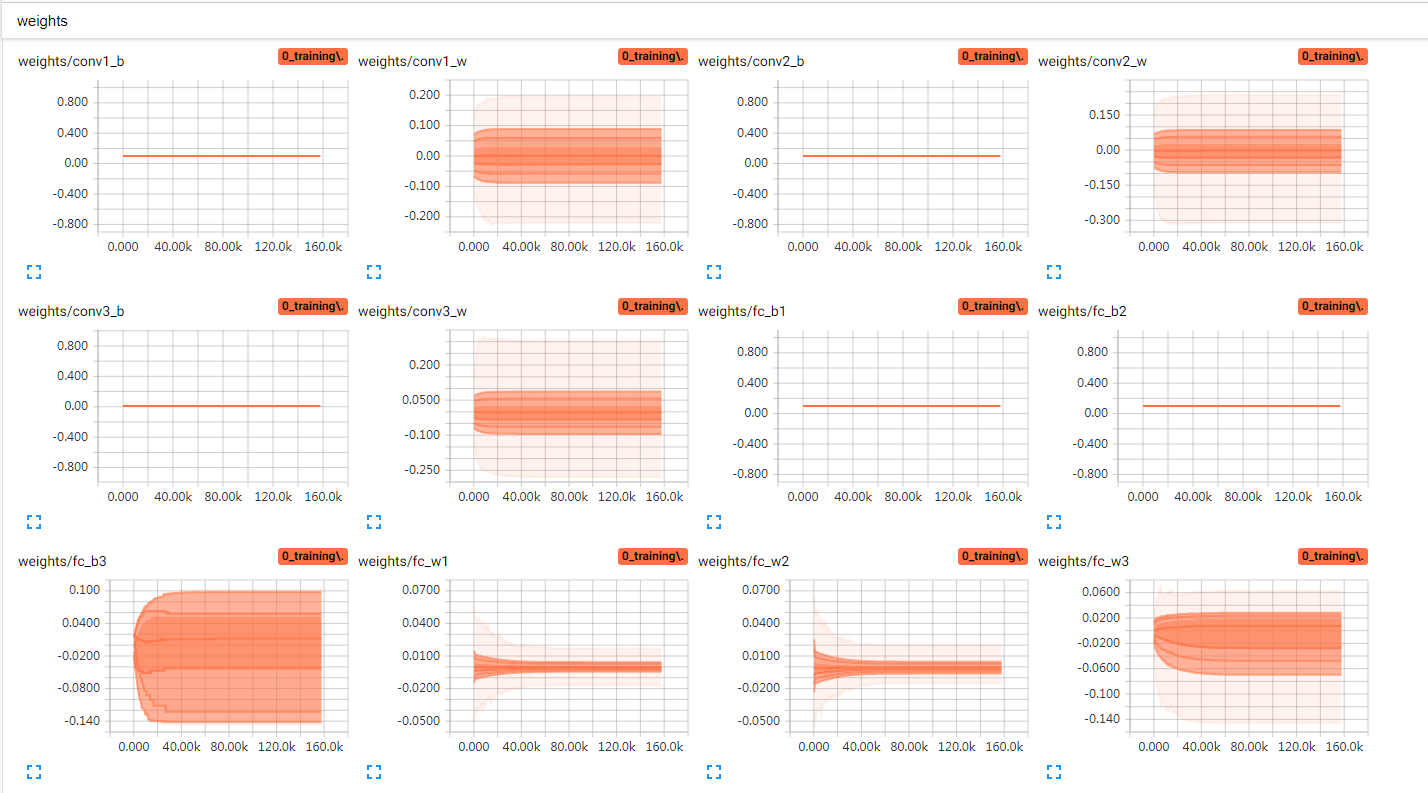
具体BN两种写法和详细计算过程以及原理和注意事项的笔记
Dropout和BN的组合、对比实验:
基础学习率0.0005,BATCH=256
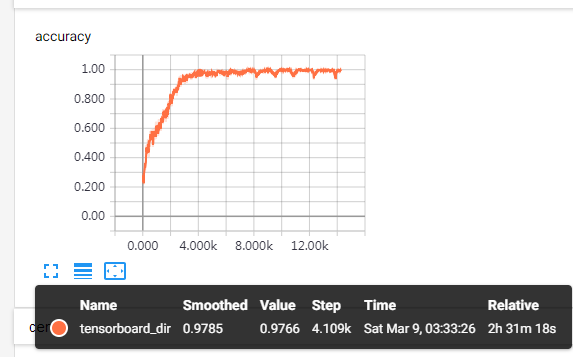
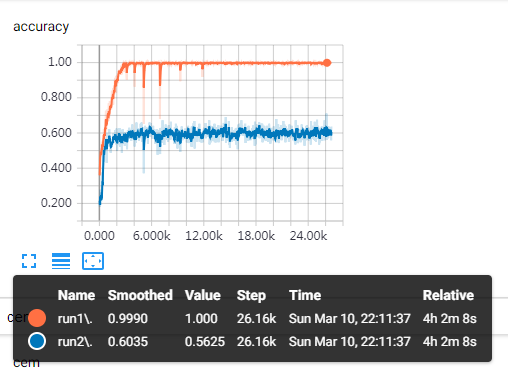
带dropout的模型,4k步以后趋于稳定,6k步准确率趋于1.0。
(这图不算完整模型了)loss有下降趋势,时间关系,就不看一万多步了。
接下来打算设计几个实验进行对比:
1.基准:动态学习率的素神经网络(其他都不带):
训练准确率接近1,测试准确率57%~59%。
2.单纯dropout(0.6*0.6*0.6):
测试准确率61+,感觉dropout还是不够多,还是充分的过拟合了。(误区,其实测试准确率上不去还有其他因素,比如数据集的不同)
3.(有biases的)BN:
图丢了(手动滑稽)(在本例,相对来说差距不算大,略过,以后直接使用无biases的)
4.去掉biases的BN:

加BN的话biases就不是很有用,留offsets就行了(论文),仔细想BN的流程,其实BN已经自带了offsets了,输入端也是做了归一化处理,对于想要的效果来说,输入之前bias就显得不是那么有用。因为relu就是线性的,和sigmoid不同,sigmoid要避开0点,所以ReLU也不一定就很需要scaling操作。(如果不要scale,接口可以传参scale=False)
现在网络保持同等条件下,去掉BN输入之前+bias操作,只留W*x。影响不大,后边的操作,BN之前就不用biases了。
5.dropout(0.5*0.5*0.5)+BN(without biases):
组合前边的用法,仍然是60上下
5.2.FC层追加BN(之前只有conv层加了BN):
FC的ReLU前也加BN层,最后一层输出层除外。同样的,在BN层之前去掉biases。
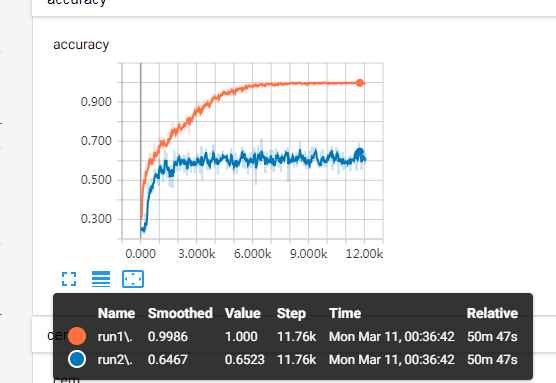
略有升高,图中65%的点是低平滑度下的单个batch的凸点,整体平滑在60%之上,之前只有60的水平,但是整体差别也不大。

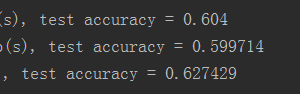
5.3.更低的dropout(0.3):
三层0.5,通过的只有0.125了,但是没办法,还是过拟合(“过拟合”不一定是训练的原因,至少,本例的测试集准确率上不去,多少有些数据集的关系)。
三层0.3,通过率0.027,FC层宽度512,还能平均通过13.824个特征,7分类的话,应该还算勉强够用。
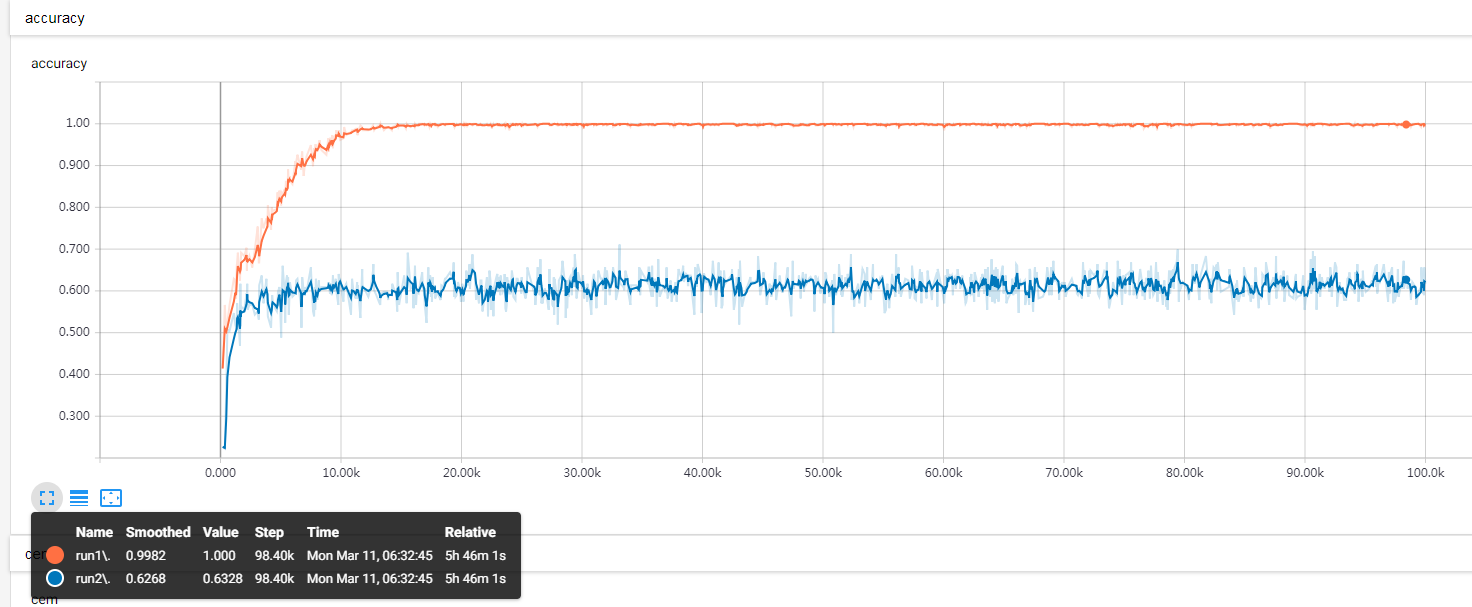
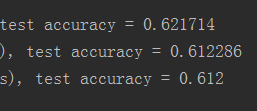
从曲线可知,测试集的准确率不是先上升后下降,也不完全算是过拟合或者过度训练的锅(否则随着训练的进展,测试集可能会有所下降),提前终止的手段用不上。
从dropout和BN看,估计只能到这个水平了。尝试其他出路。
目前已知的优化方向:数据增强、数据均衡和标签优化(fer2013_plus,不一定能用得上)。
数据增强:
flip_left_and_right:
通过观察数据集图片可知,第一个可行的方法应该就是左右翻转了。另外,如果不改网络的输入尺寸,可以考虑把图像resize放大一点,再crop,观察一下效果,不过看起来图片都很紧凑,这样做也可能会丢失面部特征。

最终方案,保持0.3*0.3*0.3的dropout以及标准BN操作,所有条件不变,以0.5的概率,对读取的数据进行批操作,左右翻转。(更新,将tf.cond换成了tf.where,从使用一个随机数控制一个batch改为使用batch_size个随机数分别控制每一个样本随机翻转)
结果对比:
蓝线是batch准确率,不是全部样本。使用相同平滑度0.946.
旧的曲线,最后一段,低点0.61,高点0.62。而数据增强的结果,低点0.625,高点0.646,提高一个百分比有余。
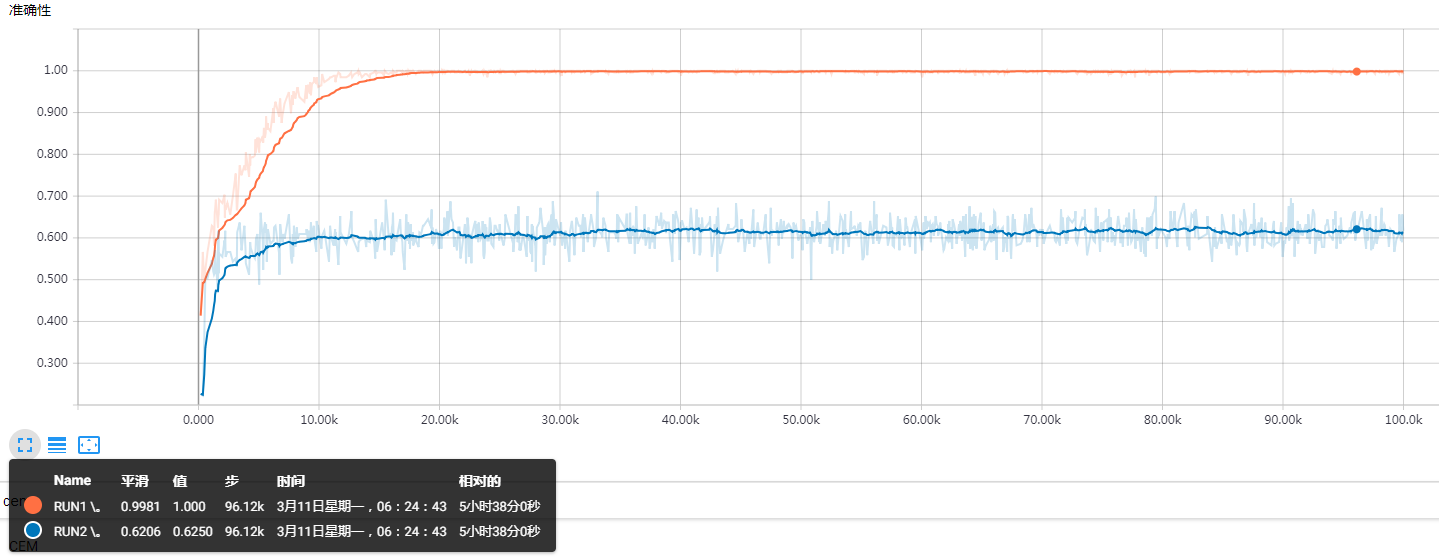
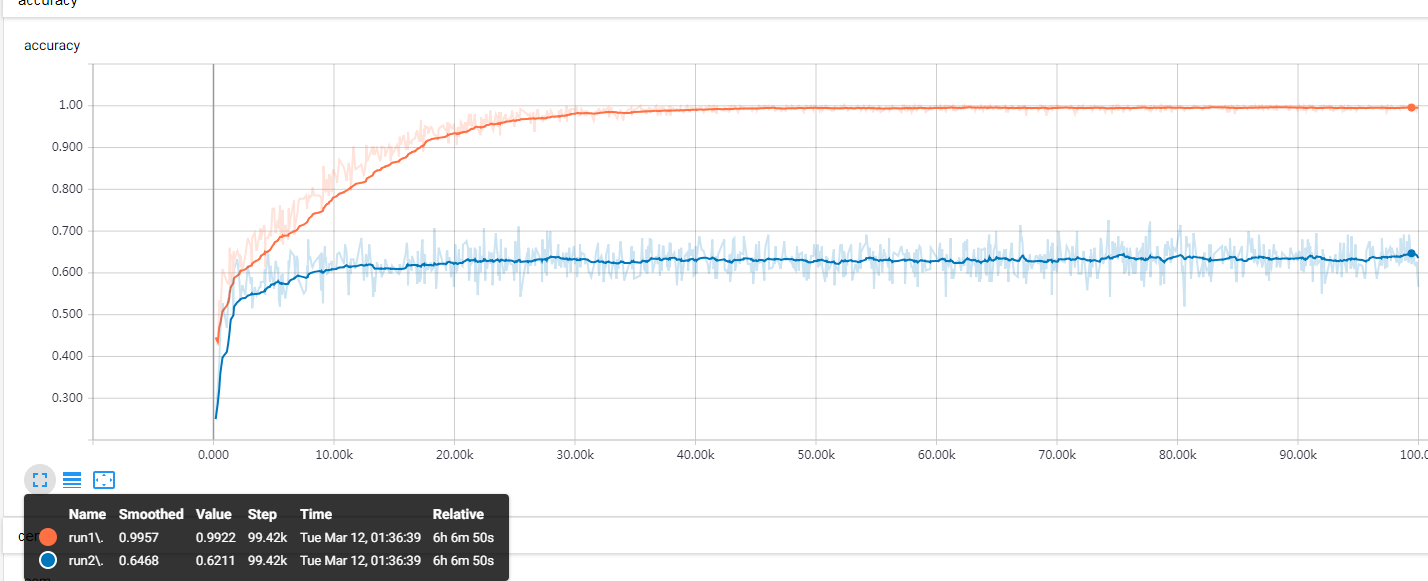
单独跑测试集,全体平均,明显高于之前。


轻度rotate:
通过观察图片,发现人脸本来就有一定的倾斜度,所以做rotate应该不会影响模型抽象特征,并且能增加数据量。
和flip同理,随机对数据进行批处理(更新,将tf.cond换成了tf.where,从使用一个随机数控制一个batch改为使用batch_size个随机数分别控制每一个样本随机旋转),随机rotate[-0.5,0.5],其他所有都保持不变,包括BN、dropout的keep率、随机的左右flip的操作。
tensorboard保持同样平滑度,后期的蓝线低点0.66,高点0.679,总体在66%~67%吧。

使用整个测试集测试,平均能保持在0.66~0.67!


验证了古人那句话“有时候不是赢在算法,而是赢在数据!”
更多的数据增强思路:对于fer2013,应该认识到,训练集和测试集的不同是预测准确率上不去的主要原因,所以数据增强应该围绕这两个集合的差距来研究,虽然也不能硬生观察两个集合区别强行改变,因为用测试集有作弊嫌疑。但是可以研究学习当做“行业经验”。
根据图片有各种字母和水印这个事实,也可以考虑自己加一些类似噪音进去。
(todo:如果能智能识别,给远景图crop,近景图保留原样就好了?也许可以考虑集成一个人脸识别进来专门做预处理,不过这已经是谷歌API针对人脸裁剪过的了,按理说已经不需要这种操作了,随意缩放也可能毁了图,提升空间可能不大,有空尝试做center_crop)
数据增强易犯错误:如果数据增强是对tensor操作,属于计算图,那么计算准确度的时候图像自身也发生偏转,这是不应该的,所以需要一个额外的placeholder控制,计算准确率的时候关闭数据增强。当然,这个主要是影响tensorboard的观测,不影响真实训练过程。更何况提取图片的过程和前向传播的过程不在同一张计算图上,所以,能确保测试集的数据流程没有数据增强就可以了。
关于颜色方面的增强,颜色的考量限于彩图数据集,fer2013本来就是单通道灰度图,所以颜色方面没有变更的必要。另一方面,可能不同颜色甚至代表了不同类别,比如蓝猫和橘猫,颜色也是特征的一部分,所以颜色的更改要慎重,但是人脸,也许能考虑,黑人白人,愤怒都是愤怒。但是!!!!!关键还是看输入网络时是什么样子,如果输入网络时有些特征已经被消除了,就没必要再动脑筋了,比如数值,如果已经归一化,都是0~1,就没必要改了!!还有图片,虽然我的网络搜集的测试图片是彩图,但是神经网络输入前已经被预处理了,所以可以认为颜色没起作用。
L2正则化系数:
因为仍然存在很大的“过拟合”现象,所以可以考虑加大L2正则化系数。
默认在FC1和FC2使用了0.004,改为0.4。
明显看到不同,对训练集的拟合约束力很强,训练两万多步,两条曲线还是齐头并进,
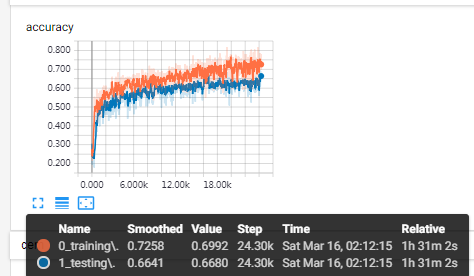
不过0.4可能过高了,过高可能导致拟合能力不足,训练集准确率降低,测试集准确率也没有因此而提升。最后反而达不到之前的效果,根据结果再调整一下。
平滑准确率64%开始平缓了,30k到35k时,正则化系数改成0.04。
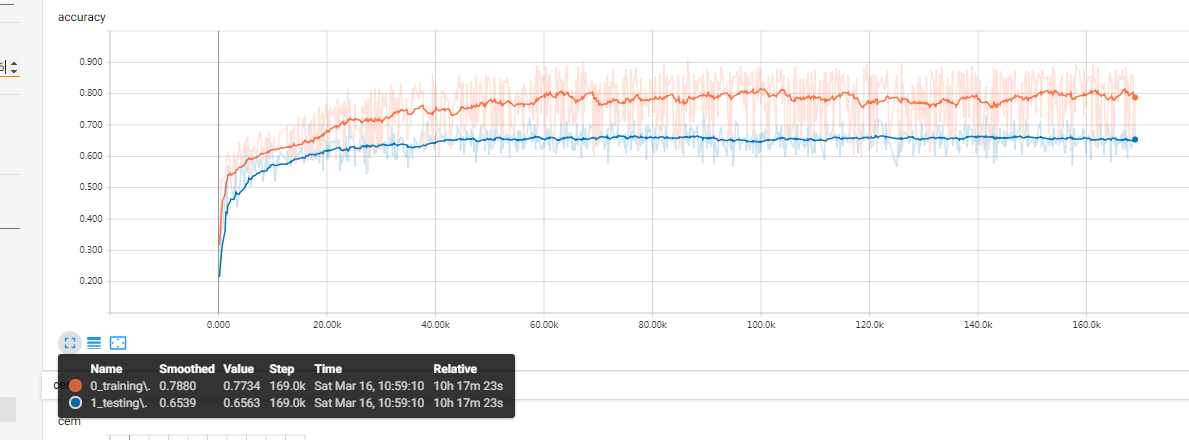
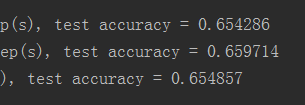
最终也就是65%+,可见,虽然训练集降低了很多,测试集也并不能获得很大的提升,这并不是真正的过拟合问题,一味增加对weights的惩罚并不能解决问题,至少不能达到“训练集准确率降低,测试集准确率就升高”这样的预期。
降低再调,改为0.01断点续训,改善不明显了,需要从头训练或者改变基准学习率(前边提到过学习率的监督和修改),时间有限,跑起来费时间,不测太细了。总的来说,相比初始的0.004,不能提升太多。
总之这个正则化的可调空间也不大,毕竟本例的核心问题不在过拟合上,正则化系数太高反而阻碍拟合!!
样本均衡问题:
实际打印,训练集七个分类的样本个数如下。不是很均衡,整体还可以,第二类有点少:
[3995, 436, 4097, 7215, 4830, 3171, 4965]
specified_class_idx = 1
specified_class_weight = 10
other_class_weight= 1 # 其他类
y = tf.nn.softmax(y)#手动的话,需要softmax
ce1 = -specified_class_weight*tf.reduce_sum((y_[:,specified_class_idx] * tf.log(y[:,specified_class_idx])))#tf.clip_by_value(,1e-10,1.0)
ce2 = -other_class_weight*tf.reduce_sum((y_[:,:specified_class_idx] * tf.log(y[:,:specified_class_idx])))
ce3 = -other_class_weight*tf.reduce_sum((y_[:,specified_class_idx+1:] * tf.log(y[:,specified_class_idx+1:])))
cem = tf.reduce_mean(ce1+ce2+ce3)可以考虑让这个分类的loss乘以10。但是如果这个权重太大,比如指定分类乘以10,其他乘以1,再加上tf.log输入的clip,整体的loss值,比以前大(其实不是很多)。具体数值可以适当调节,clip还是要用,方法可能要改,后边会提。
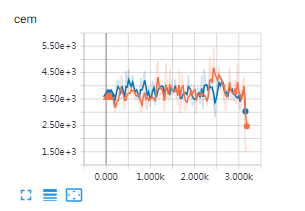
如图,使用了错误的y,cem丢了,给y加softmax(手动交叉熵要用softmax,而用接口直接softmax_cross_entropy_with_logits求的时候往往没有这层处理。(也有说不用softmax而用sigmoid的?至少softmax可行,先用softmax!!分析,softmax会让不同的输出平均分担1.0,而sigmoid是每一个单独的类的输出转换成0~1之间,如果这个交叉熵是多分类,针对的都是具体的对应的分类,其实sigmoid可行。))
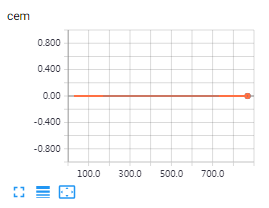
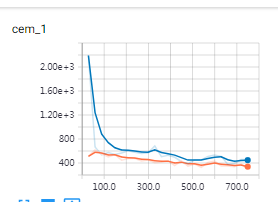
现在可以正常训练了
其他设置,基本保持不变,dropout从0.3*0.3*0.3调到0.5*0.5*0.5。正则化系数暂时用0.04,相比初始的0.004,是10倍,但是现在交叉熵也一定程度变大(436/28709 = 1/66的数据的交叉熵变成10倍,总的数据倒不至于变成10倍),总之,这种相互关联的东西,参数没有死的。但是以目前的样本情况,正则化系数改回0.004附近也许更好,感觉训练集准确率提升过早减缓(前边试验过了)。训练到一半,感觉过拟合了,适当降低一下dropout的keep率,适当提升L2正则化的系数就好了。
图一,一次性设置L2系数过高,训练过慢
图二,keep率高,L2系数低,开始过拟合了。
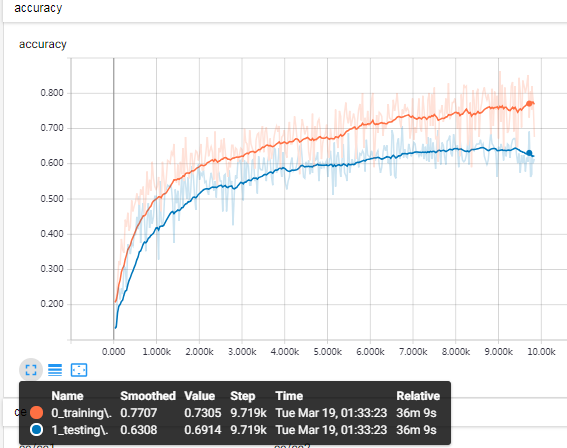
降低keep率,提升L2惩罚,继续训练。

最后又Nan了!!!先加clip,为了不影响训练,用tf.reduce_max(y)当上限,而不是1.0!!!
clip的弊端,强行限制数值的传递,可能会影响网络的训练(举例,a=100被砍成a=1,a=1和target=1的loss是0,则a=100永远不能变成a=1)。最好是把网络层的输出调好,让tensor处于一个比较好的区间,避免Nan的情况发生。(不行再把softmax换sigmoid,目前效果良好)
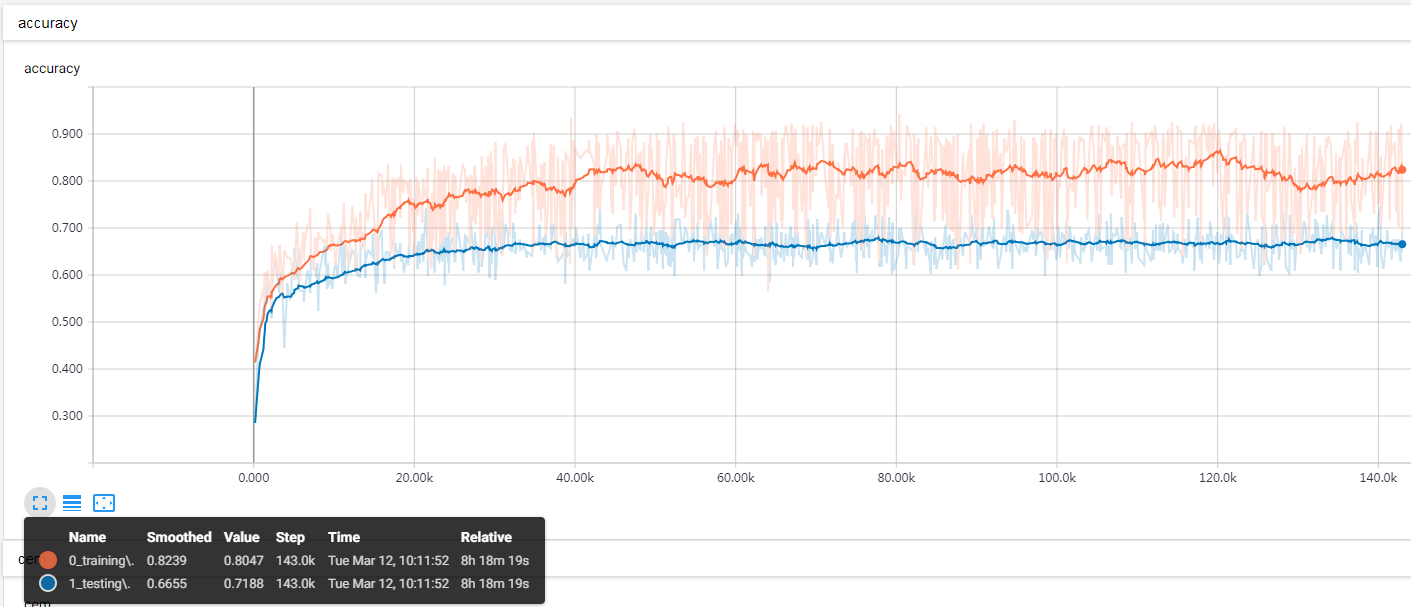
实验结果:batch峰值71%+,平滑测试准确率67%~68%+(如果在合适时机早停,可能会获得一个不错的效果,当然,选不好也可能泛化更差),较之前有一个百分比的提升:
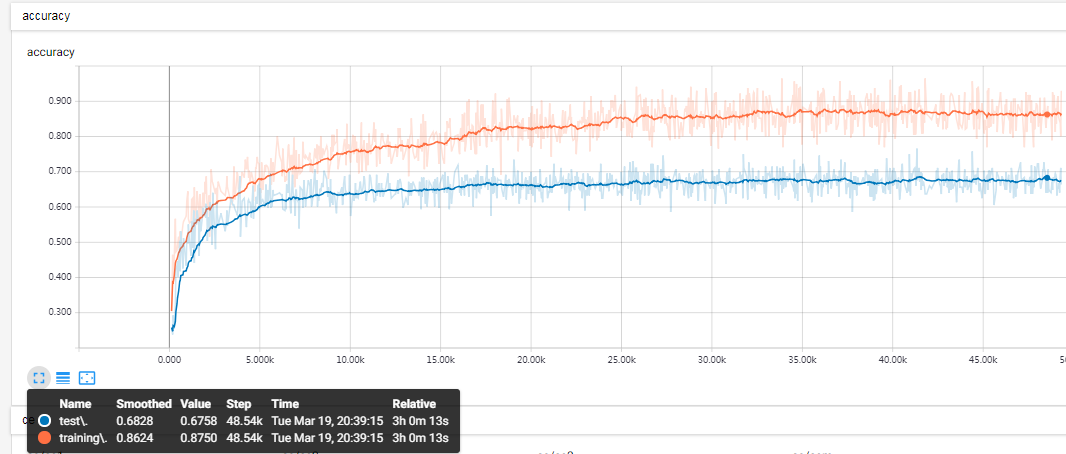
目前模型准确率:68%左右
验证集准确率



测试集准确率测试

其他可持续做的优化:
网络结构调整:可适当加深,宽度已经足够宽,看是否有必要收窄一些,因为太宽就容易过拟合,过拟合就要dropout。
激活函数,从ReLU改为Leaky ReLU,原则上能改善梯度消失和神经元死亡的问题,但是不一定有直观区别。
数据方面:网上还有一个fer2013 plus的git,数据不变,只是label改成了10类,原来是7类。这个号称能提升识别结果,乍一看简单,就是换个label数据,但是也有问题,我把这个数据集当10个label来看,进行训练,最终的预测呢?怎么转成7个?所以得研究一下那个git的说明,好好看一下。
私有和公有验证集的问题:训练集是自动训练调参用的,先不论。(公有)验证集是人工调参使用的集合,测试集(私有验证集)等于提交后的成绩,用来二次修正。目前两者区别不大,等到后期差别大的时候再做调整,减少过拟合,比如调整dropout。有时间的话,还可以使用交叉验证等方法。
网络结构:替换cliquenet等其他网络结构。
用共有验证集valid set训练:目前都是纯用train set,虽然加入valid set可能会过拟合导致test set性能下降,但是仍然可以做尝试,之后再做调节。
对比手动BN层(没区别按理说)
不用那个自动的BN,改一些参数。
学习率等优化
收窄全连接层(可考虑项):考虑网络很容易就“学”会了所有的特征,将训练集识别到100%,可以考虑收紧全连接层宽度。
估计效果不会太好,因为已经dropout到0.3*0.3*0.3了,直觉上提升空间不大,是数据集本身的差距。FC从512改到256,但是算了一下dropout的通过率,如果keep_prob用0.3,256的宽度估计不够用了。反过来想,如果FC层变窄,那么dropout也不用设置到畸形的0.3。
标签优化(可考虑项):有一个fer2013_plus。其实我也很好奇标签优化是怎么做的,原来7类,他优化到10类,用10类的训练,之后怎么回到7类?fine-tuning?好像也没必要,单纯从conv层提取特征来讲,7个标签和10个标签应该无差。如果按10类训练,再fine-tuning回去7类,FC层改变,好像绕一圈绕回来了,也多此一举。
SVM-LOSS:根据论文内容和对准确率71%的冠军模型的描述,应该是用了SVM-Loss和SVM-L2 Loss。这是最根本的区别。应该是余下的最大提升空间了,但是这是Hinton门徒专门设计的模型,不是简单改一个loss,暂时不想了。
预测与输出:
各层抽象结果:
三个conv层各打印了三个通道,第一层是人脸按不同形式的抽象进行图层剥离,第二层是结构抽象,但还有些人脸的关键特征点,和一点轮廓,第三层基本就剩下光斑了。
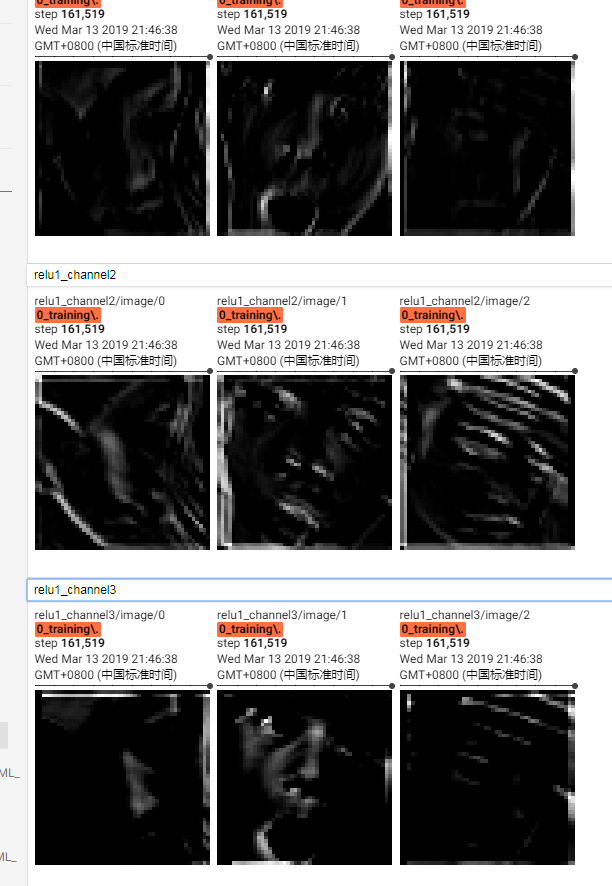
单一图片举例,看三层卷积激活输出:
原图

relu1和pool1,pool1比relu1“和谐”一点,这是肯定的,池化缩短了距离嘛,何况还是核3*3,stride(2,2)的,边缘要细致一些
保护视力,三指放大

第二层relu和pool,同样的,pool处理过后看起来更像是个人脸,“特征”更紧凑了,减少比必要的浪费

第三层relu

结果预测:
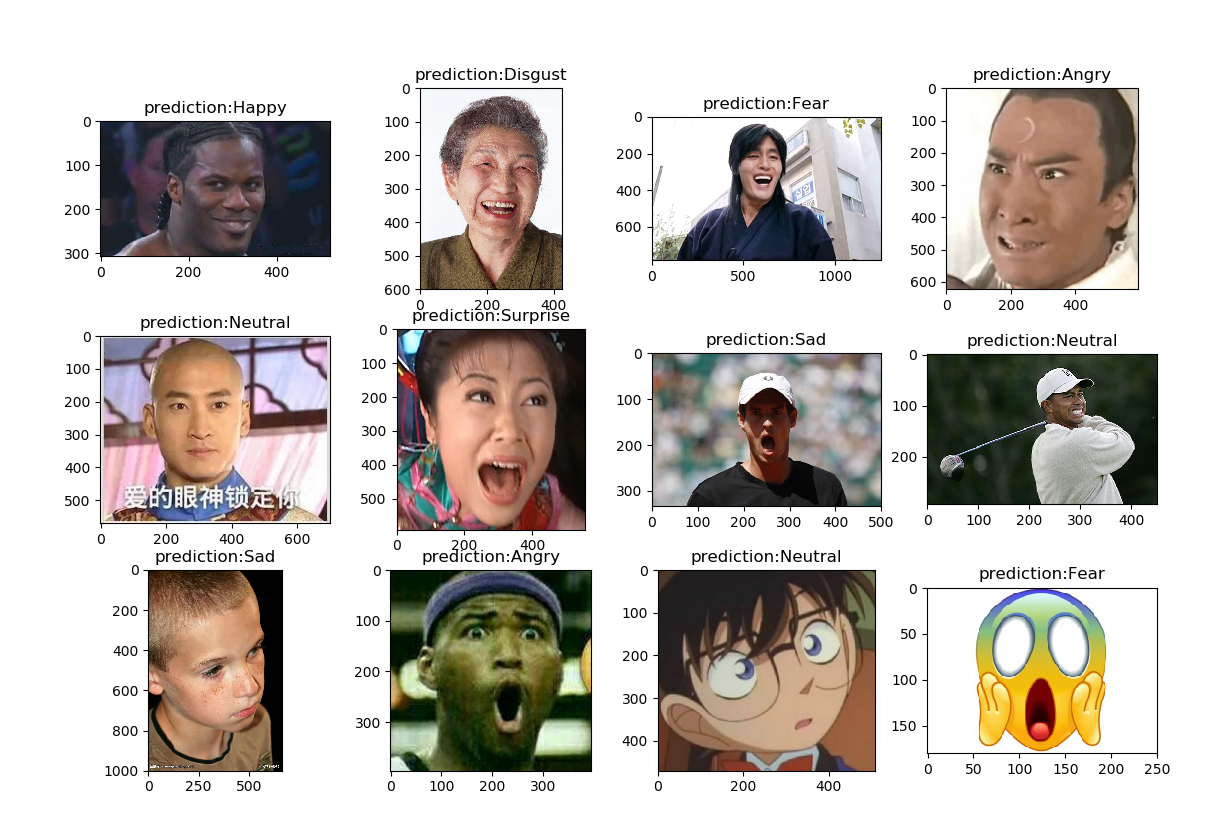
使用网络图片,进行长边居中裁剪、尺寸缩放、灰度处理,喂入神经网络,进行预测。(只裁剪到正方形,没有脸部位置的裁剪!因为没法直接识别脸的位置,随意裁剪可能会丢失面部特征,除非加一个专门的人脸识别模块。)
好像有点失败啊(手动滑稽),可能有演技超越时代的关系,不过也有面部不正的原因,毕竟训练数据几乎都是大头贴。

把面部摆正点,换几个靠谱的,再来一发,因为训练集就是很近的人脸,我的预处理代码又不够智能(原数据集好歹也是谷歌API提取出来的),所以实际预测中,人脸占比对结果影响还是很大的,多次手动裁剪调整图片,出现不一样的预测结果:
金馆长全身和近景分别是sad和happy;
老虎伍兹左边那张图,之前是全身的,预测neutral,放大到近景截图保存以后,正确预测了surprise;
紫薇是没办法抢救了;
图10黑人可能是像素不行,对比度不行,怎么调也是neutral;
柯南和表情包可能比较特殊了,识别的不准;
包拯和伍兹的哭丧脸都判断成了Angry,算是识别失败吧,如果把个别不好的图排除,整体还是有点接近66%的正确率的。

最新:处理完样本均衡后,模型变了,预测也有了新的结果,下面和老模型对比,顺便也加上个别样本的愿景和大头对比:
(图一,新模型+远景;图二:新模型+个别大头)
下面是详细预测对比,各分类的评分,越大越好,预测结果是最大的,编号对应图片顺序:
黑人表情哥没悬念,不需要再放大了(横纵比的问题,默认居中裁剪刚刚好)
pic1: Angry :-3.53 Disgust :-11.54 Fear :-5.84 Happy :5.21 Sad :-3.25 Surprise :-5.25 Neutral :2.34
相比旧模型,老太太从Happy变成了Disgust,算是有点不准了。但是考虑到有裁剪的问题,所以用一张大头照对比,大头能正确预测
pic2: Angry :1.10 Disgust :-6.84 Fear :-1.15 Happy :1.13 Sad :-3.90 Surprise :-2.43 Neutral :-3.25
(新模型用了一张新图)金馆长全身Feary,大头是Happy,变准了。
pic3: Angry :-7.13 Disgust :-26.87 Fear :-8.32 Happy :10.42 Sad :-10.23 Surprise :-2.03 Neutral :-4.32
包拯没变化,Angry占最大,其次是Fear和Sad
pic4: Angry :1.69 Disgust :-5.61 Fear :0.68 Happy :-4.63 Sad :0.89 Surprise :-4.64 Neutral :-0.32
尔康相比老模型的Happy,现在变成了Neutral,Sad还比Happy高一点。这图尔康应该是“幸福”,也就是“Happiness”,不好说,表情太淡吧也许,确实不算笑的“happy”。裁剪成大头,依然没改变!
pic5: Angry :-3.56 Disgust :-10.76 Fear :-2.81 Happy :-1.30 Sad :-0.05 Surprise :-6.55 Neutral :3.45
pic5: Angry :-0.50 Disgust :-9.01 Fear :-2.16 Happy :-4.53 Sad :2.28 Surprise :-6.62 Neutral :3.00
紫薇终于从Happy变成Surprise,算好了一点吧。(Fear也算可以,Happy也许是演技问题~~)
pic6: Angry :-1.92 Disgust :-7.96 Fear :-0.79 Happy :0.31 Sad :-3.83 Surprise :2.29 Neutral :-1.87
伍兹左侧的运动员:全身是Sad,大头Surprise还是很准的!
pic7: Angry :-2.40 Disgust :-8.55 Fear :1.04 Happy :-2.09 Sad :-3.71 Surprise :3.49 Neutral :-2.83
伍兹是Angry,虽然是击球,有点Sad的意思,不过还预测到了Happy,总的来说这个图预测的不行。
pic8: Angry :1.46 Disgust :-4.52 Fear :-0.62 Happy :0.23 Sad :-0.65 Surprise :-5.01 Neutral :-1.97
相对旧模型,小孩也从Angry变成了sad,这个更准了。
pic9: Angry :-1.43 Disgust :-7.17 Fear :-0.29 Happy :-3.19 Sad :2.04 Surprise :-4.28 Neutral :2.01
黑人张嘴从Neutral变成Angry(从经验看,应该是震惊,预测也不太对),大头照是Fear,其次是Angry和Surprise。
pic10: Angry :0.34 Disgust :-5.37 Fear :1.74 Happy :-3.44 Sad :-1.74 Surprise :0.17 Neutral :-2.65
柯南看来是太难了,本来也画的比较平静脸
pic11: Angry :-2.69 Disgust :-8.54 Fear :-2.30 Happy :0.83 Sad :0.84 Surprise :-4.88 Neutral :1.84
相比老模型,表情包的Fear预测对了,不是Angry了。
pic12: Angry :-1.35 Disgust :-6.60 Fear :2.58 Happy :-3.06 Sad :-1.77 Surprise :-0.39 Neutral :-3.43
关于snapshot(ckpt)的优化——ensemble:
训练了那么多次,training和testing的accuracy忽高忽低,究竟我截取哪一次的才最合适?看运气?看手速?这个问题就会自然衍生出一个方案——ensemble,把最后5次、10次(也不一定是特别连续的几次,有些间隔可能更好)的ckpt都保存下来,取平均,也许会更好。实际操作方法:训练时多留几个ckpt,最后预测的时候把每个ckpt都加载进来跑一次预测结果,对结果取平均(细节没想太多,比如5个ckpt,大概就是哪个label预测的多取哪个,如果5个ckpt预测不重样,可能选一个分数最多的)。
ensembles实际上是一个更通用的方法,指的是把不同模型取一个平均,比如说,把AlexNet、VGG、googLeNet、ResNet等网络的输出取一个平均,但是所谓不同模型,也不一定是结构不一样,同一个结构,不同的W矩阵构成,理论上都是不同的模型,所以,本例保存几个snapshot(ckpt)来共同预测取平均,是一个非常可操作(相对于从头训练好几个模型)的简约ensemble方案。
改进空间:接一个人脸识别模块,对数据进行预处理
现在只是手动裁剪测试数据,简单实验。实际使用不可能手动去裁剪。
================================================================================================
================================================================================================
================================================================================================
调试过程及操作等问题:
中间遇到了很多细节问题需要调试。主要是工程实现的问题。
工程都放在github了,调试放到ipynb
https://github.com/huqinwei/my_fer2013_model
更换环境,使用GPU进行训练:
https://blog.csdn.net/huqinweI987/article/details/88107750
todo:另一个问题,双GPU的训练,默认是不带的!
使用双GPU:todo,实测发现另一GPU没有运转,虽然显存占用,温度和转速都没上来。可能需要显性的使用代码进行双GPU并行,tensorboard并没有自动方案。(当然,只是训练速度的差异)
准确率打印要避免受dropout影响:
比如直接sess.run([train_op,accuracy])这种偷懒写法,其实得到的不是正确的准确率。
各种滑动平均,包括BN,保存与使用:
无论是普通weights的滑动平均ema,还是BN自带的隐藏滑动平均,保存和恢复这里都是个坑点。
尤其BN,BN是部分训练,部分滑动。很明显测试和预测时都应该用滑动的这部分,而这部分是不能train的,不包含在trainable。所以保存时也要注意。
很多坑都是不可感知的,不动脑不调试就漏掉了,但是好在tensorflow做了防呆设计,至少能保证你确实保存了变量,不然bn层是根本加载不出来的,会报错(话说回来,就算防呆不能运行,也白训练了不是~):

说起来简单,但是自己抠清楚还是花了些时间的。如果不想抠,也不要紧,TF有很多机制,可能简单的常规操作(复制正确的模板的前提下)不会碰到问题,但是最好理解并掌握。
其他都好说,但是有一个错误是没有预防机制的,就是不更新滑动平均,一定要记得更新滑动平均!!
预测的时候,一定要把BN层的training项改回False,如果保持同样的网络设置,就不对了。(其实在一定训练条件下,BN的training=False,反而看起来准确率更低)
https://github.com/huqinwei/tensorflow_demo/blob/master/batch_normalization_use_TF.ipynb
https://blog.csdn.net/huqinweI987/article/details/88071425
BN有两种写法,有一种黑盒直接使用,第二种需要自定义变量,并区分训练和测试过程维护滑动变量。学习研究用第二种,模型图方便用第一种。
因为用了第一种,没有显式的去声明变量,但是不代表没有,把模型resotre并打印出来。每个BN层包括四个变量,所有数据的滑动平均mean和variance,经过mean和variance处理后,缩放系数gamma和平移系数beta,他们未经训练的时候应该是刚好让数据保持不变,训练之后的效果是让不同的输入对应的输出都在一个相同的分布。
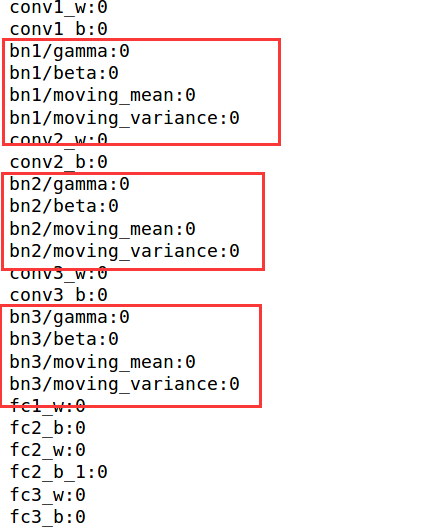
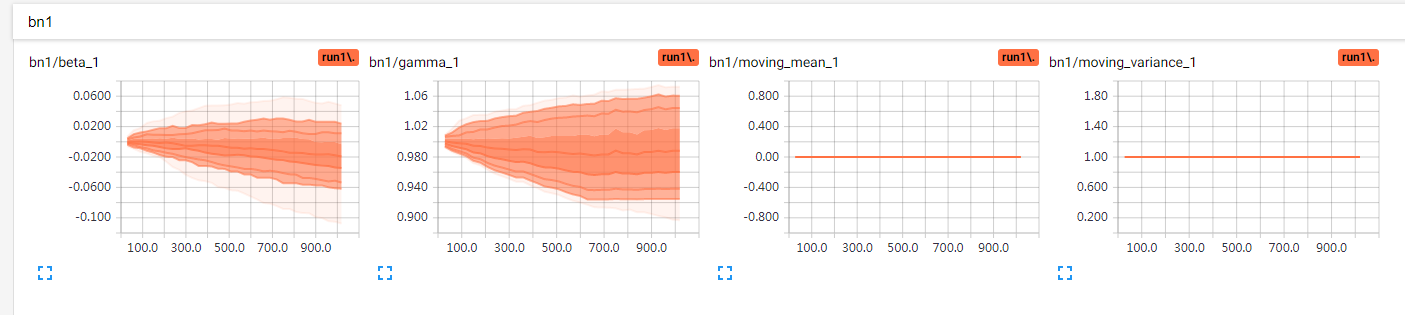
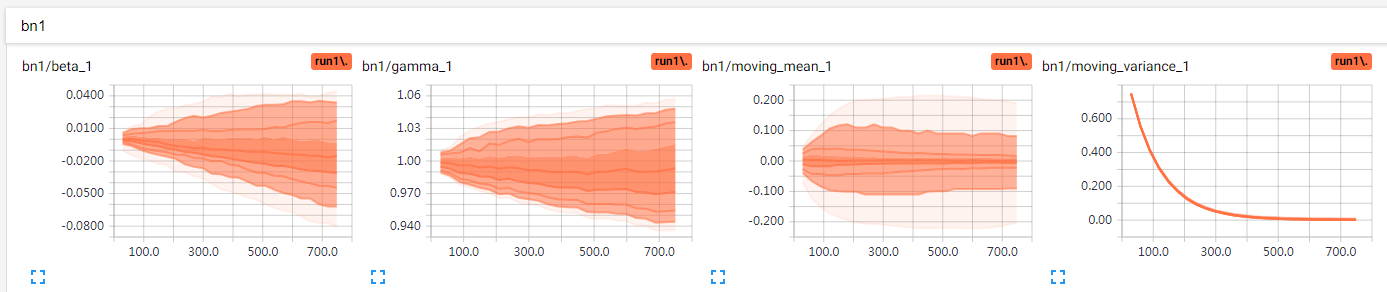
EMA更新了moving_mean和moving_variance
但是使用非训练模式的BN,结果总是不太满意,不知道是训练不充足还是什么其他原因,更新是肯定更新了,被EMA给更新了,受dropout影响?改成dropout 1.0 测试
ema的惯性方面,应该没问题,batch_normalization默认momentum=0.99。理论上是没问题,实际上效果不好,0.99还是太大了,可能要训练很久才能真正有效,不然测试的时候准确率会很难看。0.5就明显高了。
调试ema和bn,一些实际情况对比(因为算力原因,没有充分训练,仅供观察):
基础学习率0.001
ema decay=0.5,dropout=1.0,1000~2000步,训练正确率60+,测试正确率25%左右
ema decay=0.5,dropout=1.0,3600步,训练正确率80+,测试正确率15%左右
基础学习率0.0005
ema decay=0.99,dropout=0.5,0.5,0.5,1000~10000步,训练正确率60~90,测试正确率15%左右
ema decay=0.99,dropout=1.0,1000~10000步,训练正确率60~90,测试正确率15%左右
ema decay=0.99,dropout=0.6,0.6,0.6,37700步,训练正确率90-,测试正确率45%左右
ema decay=0.99,dropout=0.6,0.6,0.6,49400步,训练正确率90~95,测试正确率46%左右
由此可见,使用方法正确的前提下,加BN层,momentum=0.99,需要很多学习才能达到加BN之前的效果!
为了区分dropout、BN各种不同情况,程序结构和参数要调整好:
BN的training参数可以用tf.bool通过placeholder传入,这样能保证训练的同时用同样的网络进行验证。
prob = tf.placeholder(tf.float32)
bn_training = tf.placeholder(tf.bool)
def forward(x, keep_prob,bn_training,bn_enable = False)
#训练
sess.run([train_op, loss, accuracy, global_step, learning_rate],feed_dict={x: reshape_xs, y_: ys, prob:1.0, bn_training:True}
#使用训练集验证
sess.run([accuracy, merged], feed_dict={x: reshape_xs, y_: ys, prob: 1.0, bn_training:True})
#测试
sess.run([accuracy, test_merged], feed_dict={x: reshape_xs, y_: ys, prob: 1.0, bn_training:False})BN的问题最多:
首先,要区分训练状态和测试状态。
其次,要注意传入的是python还是tensor的bool。如果是python的boolean,通过建立网络传入,那么测试集和训练集就没法区分阶段。
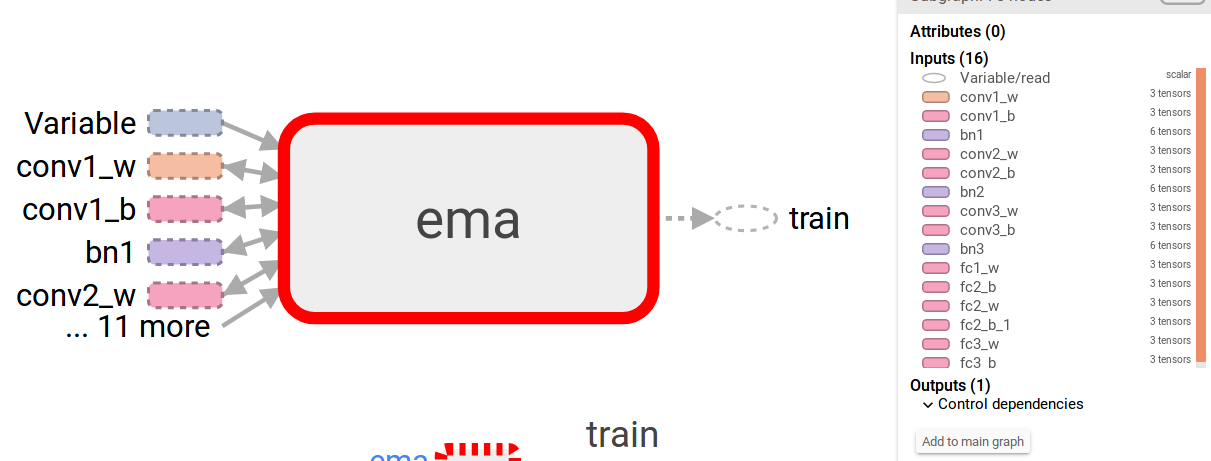
最后,BN层的更新,普通的变量被Adam更新,并被EMA调整,但是滑动平均却并不会,虽然EMA也是“滑动平均”,但是EMA是找的trainable(严格的说是可设置的参数列表,但是没意外的话直接使用所有trainable了),而这两个变量不是trainable,不包括在内。
ema_op和update_ops缺一不可
train_step = tf.train.AdamOptimizer(learning_rate).minimize(loss, global_step=global_step)
ema = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
ema_op = ema.apply(tf.trainable_variables())
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
with tf.control_dependencies([train_step, ema_op]):
train_op = tf.no_op(name='train')
关于tfrecord中的数据类型的问题:
使用PIL(Pillow)的Image.fromarray转换fer2013数据集报错
fer2013,通过pandas的read_csv得到的是这个类型 ‘<i8’
找不到typestr的key:((1, 1), ‘<i8’)
普通的,如果使用Image.open()打开一张图,得到的是 ‘|u1’,是可以在typemap中找到的。
这个类型其实就是描述内存存储的,大小端、数据类型、字节数。
PIL支持的就只有这些类型:
Image._fromarray_typemap is : {((1, 1), '|u1'): ('L', 'L'), ((1, 1), '|i1'): ('I', 'I;8'), ((1, 1), '<u2'): ('I', 'I;16'), ((1, 1), '>u2'): ('I', 'I;16B'), ((1, 1), '<i2'): ('I', 'I;16S'), ((1, 1), '>i2'): ('I', 'I;16BS'), ((1, 1), '<u4'): ('I', 'I;32'), ((1, 1), '>u4'): ('I', 'I;32B'), ((1, 1), '<i4'): ('I', 'I'), ((1, 1), '>i4'): ('I', 'I;32BS'), ((1, 1), '<f4'): ('F', 'F'), ((1, 1), '>f4'): ('F', 'F;32BF'), ((1, 1), '<f8'): ('F', 'F;64F'), ((1, 1), '>f8'): ('F', 'F;64BF'), ((1, 1, 2), '|u1'): ('LA', 'LA'), ((1, 1, 3), '|u1'): ('RGB', 'RGB'), ((1, 1, 4), '|u1'): ('RGBA', 'RGBA')}
python3.6,Pillow更新到最新,没解决问题
PILLOW_VERSION = ‘4.2.1’
(现在也想明白了,和环境版本关系不大,人家库就这样设计的,既然Image存的是图像,像素值也不需要64位整型)
array的来源就是split的字符串,也不该有什么绑定的属性自动传入array了(最开始以为和编码格式之类的有关系,所以跑偏了)
因为是array带的属性,所以去看np.array的说明,这个应该就是array的数据类型,默认情况下,应该按满足最低需求的来准备。写的是dtype=int,可能因为系统是64的,就算成64,自己主动指定dtype=np.int32(float64也支持),解决问题。。但是我要用到的样本的数值上限,只是255,所以类型随便用。后边灰度转换直接变8位。
其他要注意的,bytes确实是按8位存数据,并且只支持8位数据,转bytes存储前,灰度转换,数据已经不大于255.
TFRecord:
其他都是小问题,这个最重要,因为数据给不出来,训练过程根本无法进行,不搞清楚数据的每一步形式的话很不容易发现问题,所以把tfrecord的各种操作好好巩固一下。
数据方面容易有坑,有好几个可能的问题,类型不匹配,根本读不出去,不能训练;bytes的转化过程中把数据都丢掉,不过本例不算是个问题,因为转灰度了,灰度255以上都会强制255,最后只要decode的时候确保使用uint8就行了。
不管有没有灰度转换,留意,decode要和tobytes的源头类型一样,因为这个bytes是字节序列,和C语言的内存操作一个道理。
在restore模型时遇到的问题:
restore主要用于恢复global_step和变量,断点续训;还有在测试阶段提取出EMA变量用于测试。
先说重点:要指定var_list,每个变量都要有自己的名字!!!如果给模型改过变量名,之前的model就不能直接用了(想用的话需要找出对应关系,倒是可以改名映射)!
细说,restore会遇到两个问题:找不到对应的变量,形状不对。
前者是现在定义的变量比model存的变量多了(指定var_list=ema.variables_to_restore(),能减少一部分错误,按理说在ema范围内变量足够就行了,新定义的无关变量不会去强行匹配)
后者的话,主要可能是因为没给所有变量都命名,比如我之前所有的bias都叫Variable,然后自动重命名,这样万一新定义的模型,哪怕顺序不一样,后缀就变了,就可能出错。
我的一个报错是:两个变量错位了,一个想要64给0,一个想要0给64。(又或者是512和128不匹配)
InvalidArgumentError: Assign requires shapes of both tensors to match. lhs shape= [64] rhs shape= []
[[Node: save/Assign = Assign[T=DT_FLOAT, _class=["loc:@Variable"], use_locking=true, validate_shape=true, _device="/job:localhost/replica:0/task:0/device:CPU:0"](Variable, save/RestoreV2)]]
InvalidArgumentError (see above for traceback): Assign requires shapes of both tensors to match. lhs shape= [64] rhs shape= []关于模型的save/restore,最烦的问题就是变量的自动重命名,这一点主要体现在使用ipynb调试,如果每次都单独开一个进程,且保证没有多余动作——比如不小心多调用一次网络定义——问题应该不大。或者,用get
最好所有变量都命名,图中两段,第一个是血泪教训,好不容易扔一晚上的模型,用不了了(其实可以手动指定映射关系,但是太乱就不想弄了,参见ema笔记和demo)。第二个是规范的能用的。

restore基本练习:https://github.com/huqinwei/tensorflow_demo/save_model_practice.ipynb
示例和调试笔记:
https://blog.csdn.net/huqinweI987/article/details/88241776
https://github.com/huqinwei/DL_demos/kaggle_face_expression_recognition_challenge/my_practice/ema_restore_practice.ipynb
测试准确率时内存溢出:
一次性把测试集三千多数据都读出来,我的7G虚拟机爆了
tensorflow.python.framework.errors_impl.ResourceExhaustedError: OOM when allocating tensor with shape[3589,48,48,64]
解决方法,分批次测试,取平均值。如下:把数据改小,加个循环和平均。因为取数据用的shuffle,加上不能整除的零散部分也向上取整了,所以数据有微小变动:
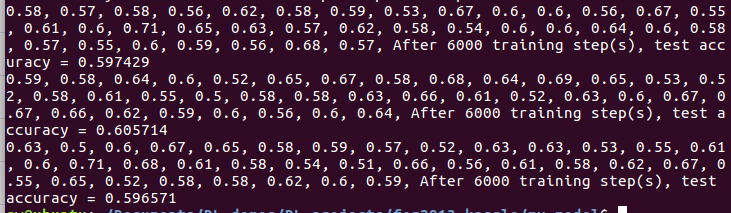
训练一半改学习率会发生什么?而这个模型用的是动态学习率
ckpt加载只有global_step,,是用基数和global_step计算得到,故而学习率可以随意更改,按相同的步数折算就好了。这样可以做的事情就多一些,比如,改了模型,断点续训,如果学习率已经衰减到很低,可能修改就看不到效果了,可以调大学习率基数,提升实际学习率,以后学习率仍然能衰减,最终仍然能收敛,这样的好处是不用重新训练。
一个测试:


线程协调器问题:
生产者和reader的定义一定要早于线程协调器启动!!不然可能卡住,什么都读不出来!
因为定义操作被get_tfrecord()封装起来了,容易看走眼。tf这个线程协调器相对来说有点透明,有时候出了问题不便于观察,害的我把一套数据流程都调了一遍,最后发现就是函数封装导致执行初始化晚了。。
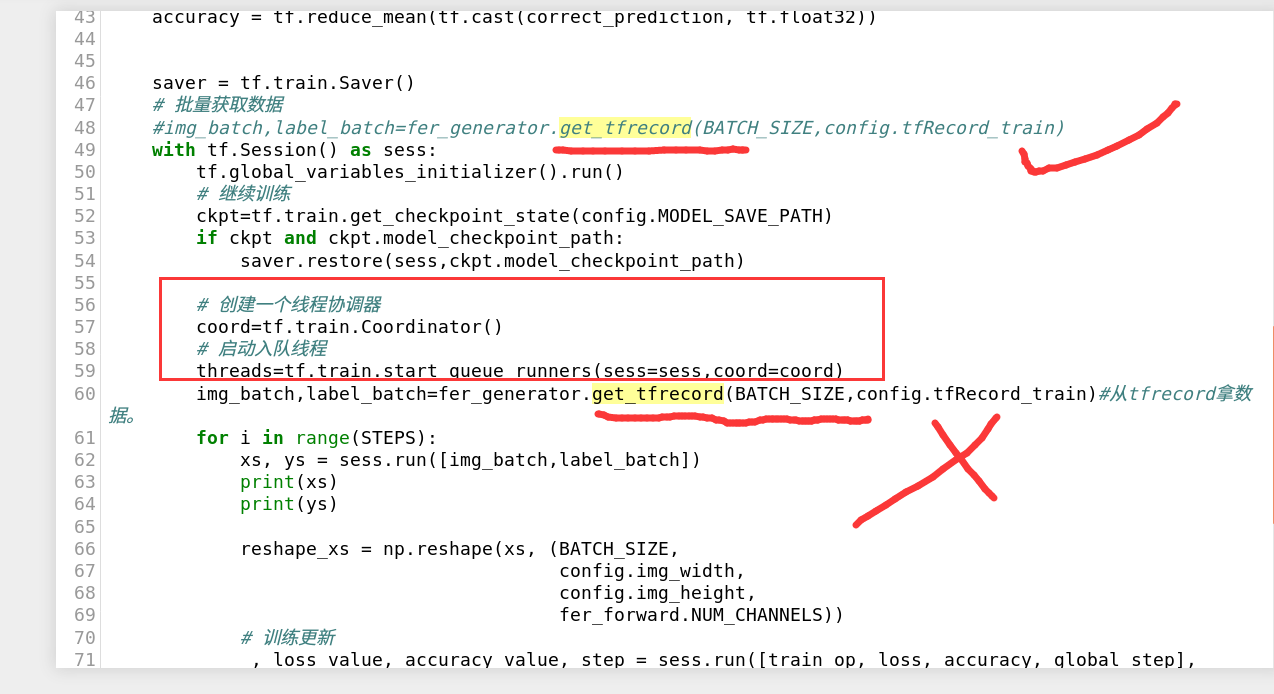
函数封装有生产者的定义

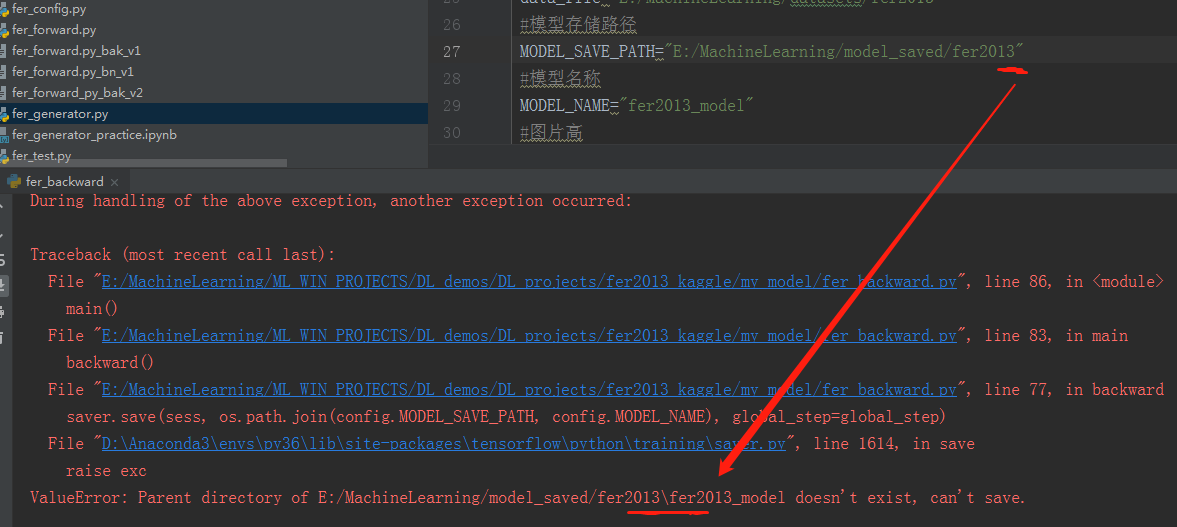
Windows路径:
为了充分利用GPU,转到windows,配置文件的路径要变,注意windows的斜杠,会成为转义字符,最好保持linux的写法。


最坑的是这种,他拼接的时候,又会加错斜杠,主动加斜杠改正
训练同时运行单独的测试程序:
GPU会不够,限制只用CPU完成。
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = '-1'各种运算图和各种阶段各种流程的兼容问题:
很多前边已经提到,像BN操作,像数据增强操作,像训练集和测试集的准确率,很多,需要搞清逻辑,处理好关系。
Nan问题和clip注意事项:
像样本均衡时的权重cross entropy,使用clip,不过也要注意情形,最好把相关变量都跟踪好,看看会不会遇到其他问题,比如因为clip而影响训练效果。
简单说,就是,一个tensor,比如是a = 100,被clip到10,那么他和target=10的loss就是0,自然无法train。
生产队列报错:
主要原因可能图片或者数据不对,我这里是因为做测试,把tfrecord动过。
TFRecordReader "OutOfRangeError (see above for traceback): RandomShuffleQueue '_1_shuffle_batch/random_shuffle_queue' is closed and has insufficient elements (requested 1, current size 0)"
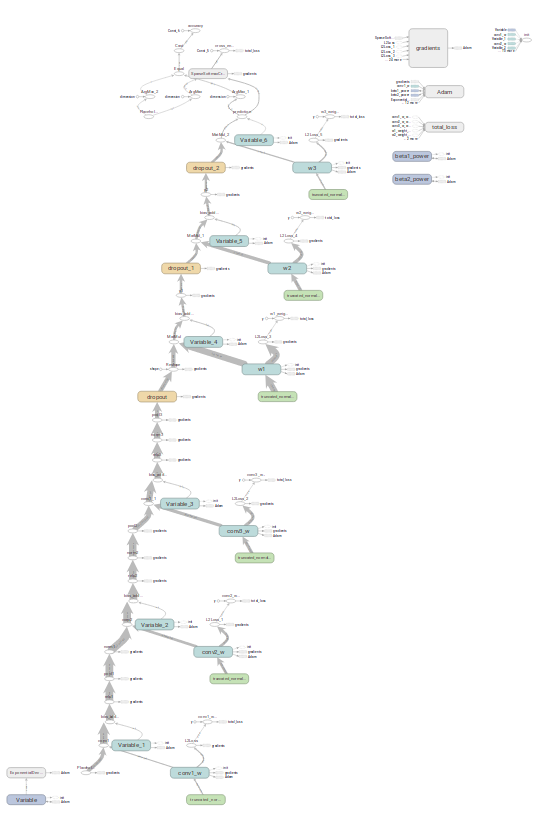
打印graph
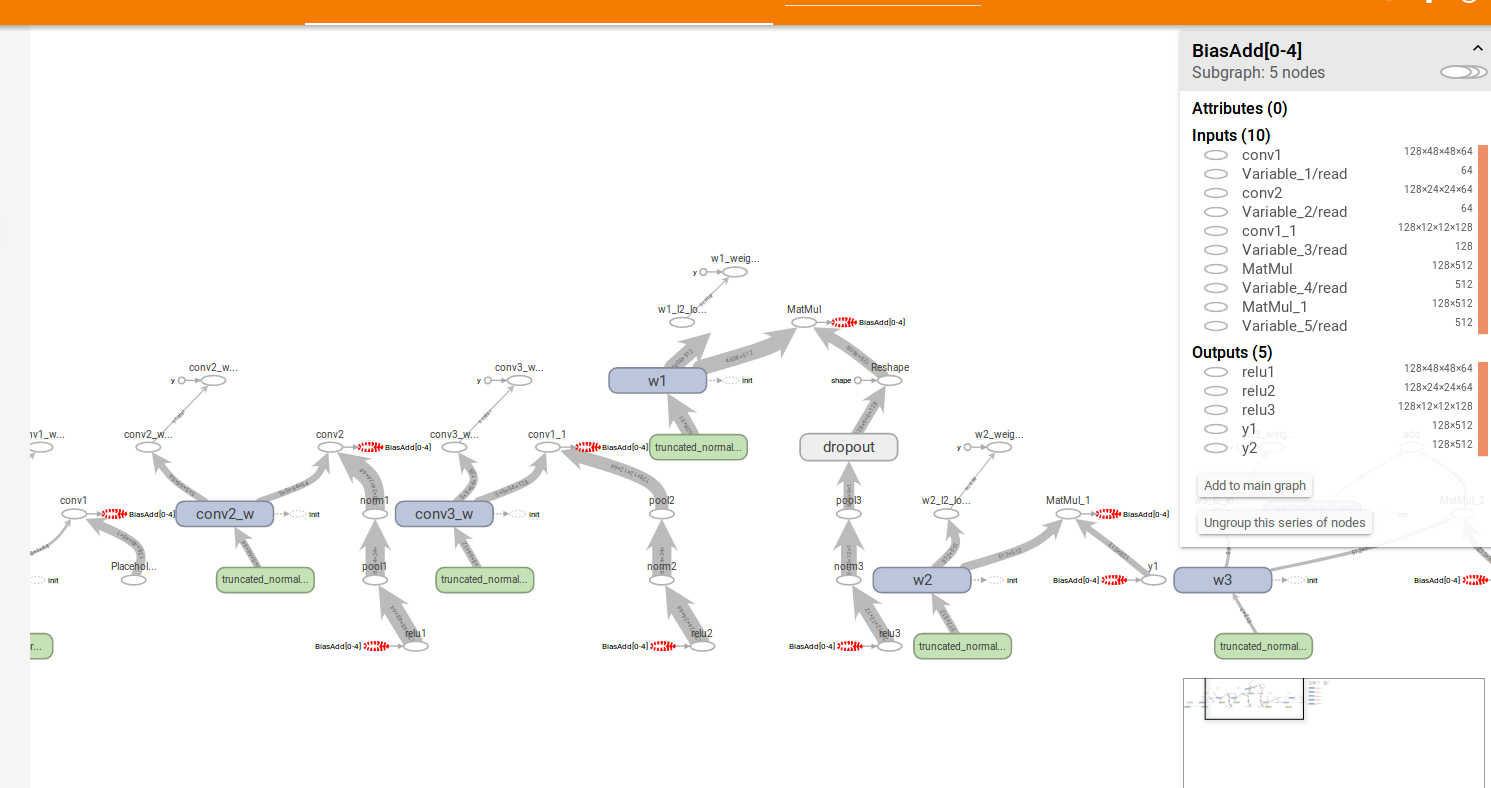
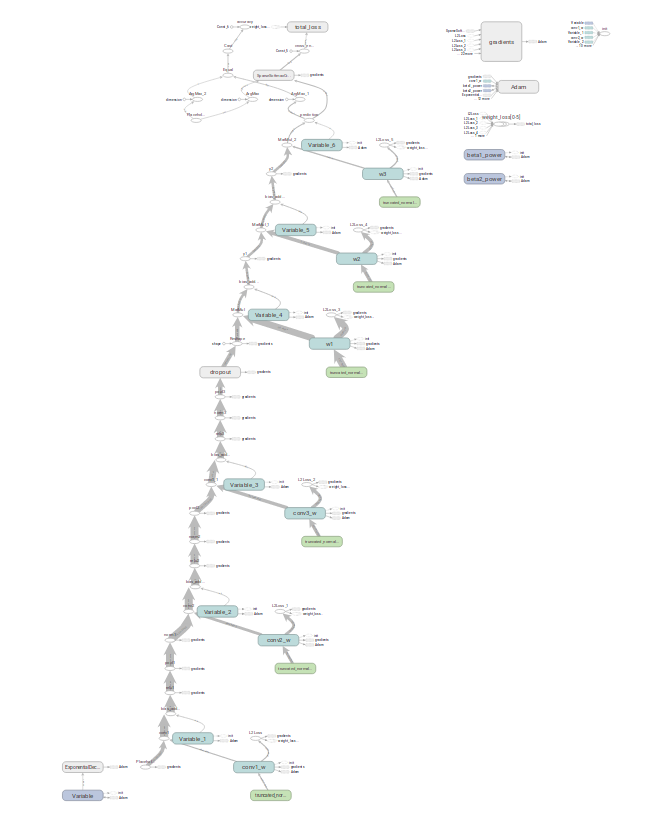
最终网络图
这是一张新的graph,已经加了很多东西,比如BN层的参数,还有各种打印


全景图

数据增强
下边的不是最新的graph,但是主体流程相同,没有太多杂项,反而更清晰一些
下图是前向传播结构,bias_add支持同名,如果不自己改名,图不是一条线,是断的,通过BiasAdd衔接的。
这是不自定义名的效果,会形成一个数组,图形会断掉,也能通过红色标记的断点观察,不过不直观。
给bias_add单独命名,保证图形连续
除了bias_add,multiply、matmul都是如此,统统改完。
改完所有重名操作,无EMA情况下的前向+反向网络结构,无EMA的图更清晰一些。
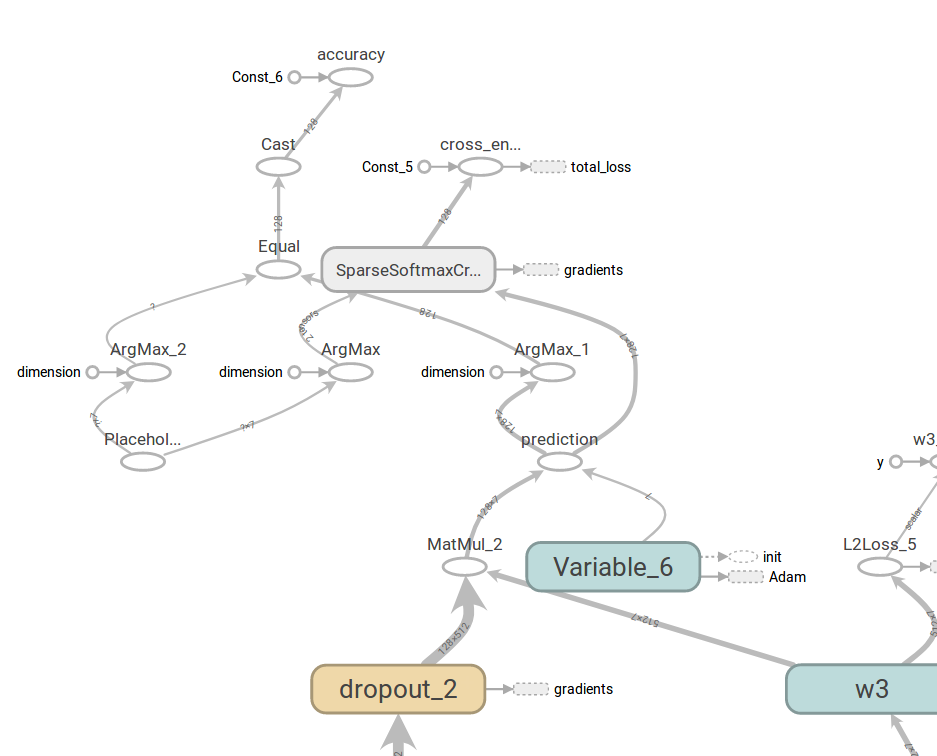
有ema的情形,加了一堆判断。图形也不完整,有重名
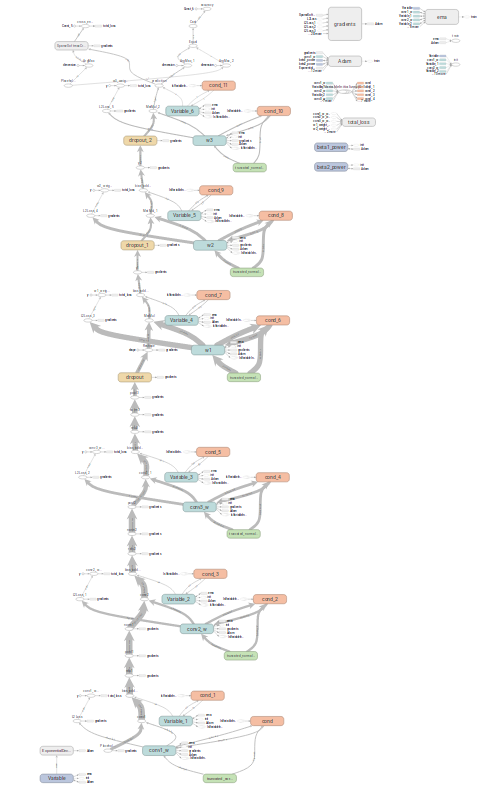
而且这个操作是隐藏了的,这个对整体结构图影响不大,应该是一个原地闭路,现在打印成开路了。
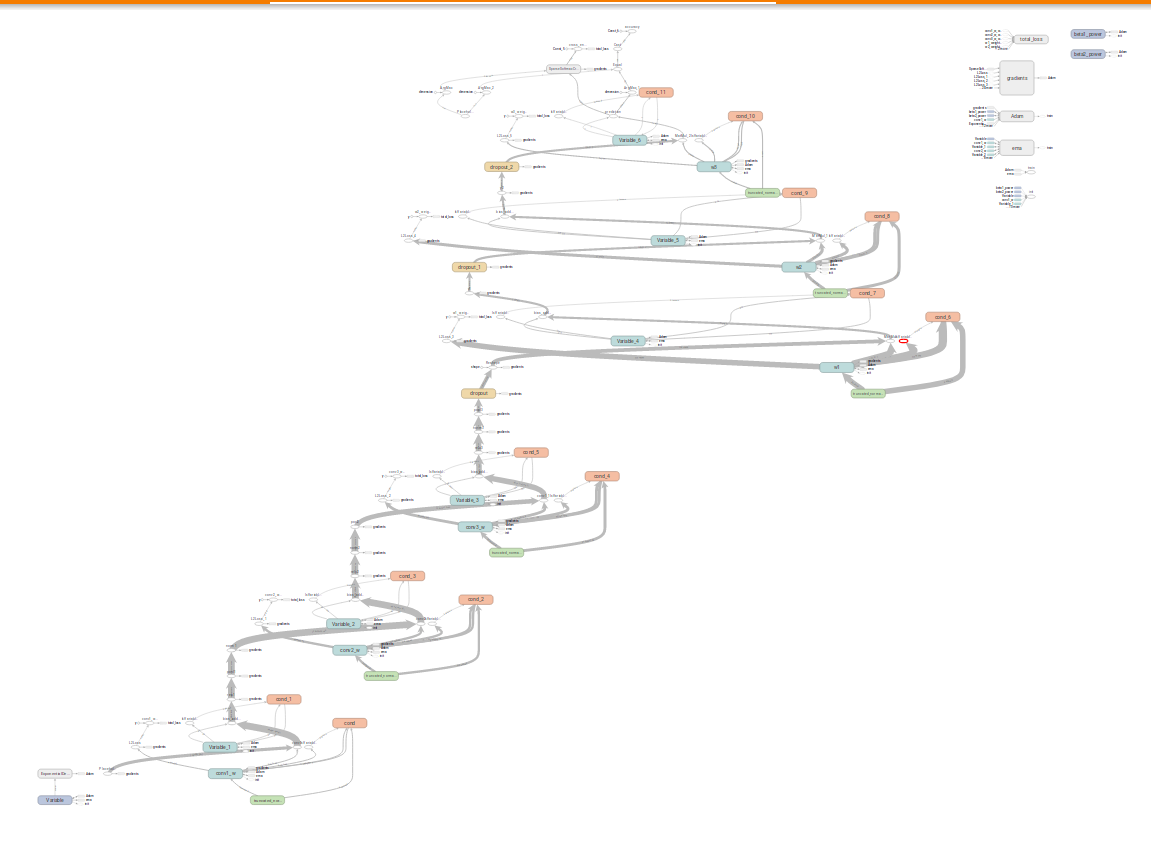
在tensorboard可以手动解开,就是看着更不舒服了。。。
其他操作失误与注意事项:
虽然定义时候不执行,但是merge也是有定义顺序的,如果先定义merge,后定义其他的summary,可能不会被包含进去。
使用ipynb调试时,file句柄没有及时close掉,最后把train的tfRecord写坏了,而这个0字节的tfrecord,在这种生产者模式下是不报错的,本来也不报错,只是负责读数据,没数据了就不读了,没毛病。。。
tensorboard删除文件夹新建文件夹的操作,只有不断点续训时才可用,不然图像不全。

————————————
————————————–\
下载:
https://download.csdn.net/download/huqinwei987/11830851
网盘
链接:https://pan.baidu.com/s/1GeaQFrn2eM5ZAbFPnQQ4eA
提取码:2qma
git链接:
https://github.com/huqinwei/my_fer2013_model
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/128307.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
