大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
深度学习最常用的优化方法就是随机梯度下降法,但是随机梯度下降法在某些情况下会失效,这是为什么呢?带着这个问题我们接着往下看。
一个经典的例子就是假设你现在在山上,为了以最快的速度下山,且视线良好,你可以看清自己的位置以及所处位置的坡度,那么沿着坡向下走,最终你会走到山底。但是如果你被蒙上双眼,那么你则只能凭借脚踩石头的感觉判断当前位置的坡度,精确性就大大下降,有时候你认为的坡,实际上可能并不是坡,走一段时间后发现没有下山,或者曲曲折折走了好多路才能下山。
类似的,批量梯度下降法(Batch Gradient Descent,BGD)就好比正常下山,而随机梯度下降法就好比蒙着眼睛下山,数学上的表达式为。
批量梯度下降法在全部训练集上计算准确的梯度,公式为
∑ i = 1 n ∇ θ f ( θ ; x i , y i ) + ∇ θ ϕ ( θ ) \sum_{i=1}^{n} \nabla_{\theta} f\left(\theta ; x_{i}, y_{i}\right)+\nabla_{\theta} \phi(\theta) i=1∑n∇θf(θ;xi,yi)+∇θϕ(θ)
其中 f ( θ ; x i , y i ) f\left(\theta ; x_{i}, y_{i}\right) f(θ;xi,yi)表示在每个样本的损失函数, ϕ ( θ ) \phi(\theta) ϕ(θ)为正则项。
随机梯度下降法则采样单个样本来估计当前的梯度,即
∇ θ f ( θ ; x i , y i ) + ∇ θ ϕ ( θ ) \nabla_{\theta} f\left(\theta ; x_{i}, y_{i}\right)+\nabla_{\theta} \phi(\theta) ∇θf(θ;xi,yi)+∇θϕ(θ)
可以看出,为了获取准确的梯度,批量梯度下降法的每一 步都把整个训练集载入进来进行计算,时间花费和内存开销都非常大,无法应用于大数据集、大模型的场景。相反,随机梯度下降法则放弃了对梯度准确性的追求,每步仅仅随机采样一个(或少量)样本来估计当前梯度,计算速度快,内存开销小。但由于每步接受的信息量有限,随机梯度下降法对梯度的估计常常出现偏差,造成目标函数曲线收敛得很不稳定,伴有剧烈波动,有时甚至出现不收敛的情况。下图展示了两种方法在优化过程中的参数轨迹,可以看出,批量梯度下降法稳定地逼近最低点,而随机梯度下降法的参数轨迹曲曲折折简直是“黄河十八弯”。
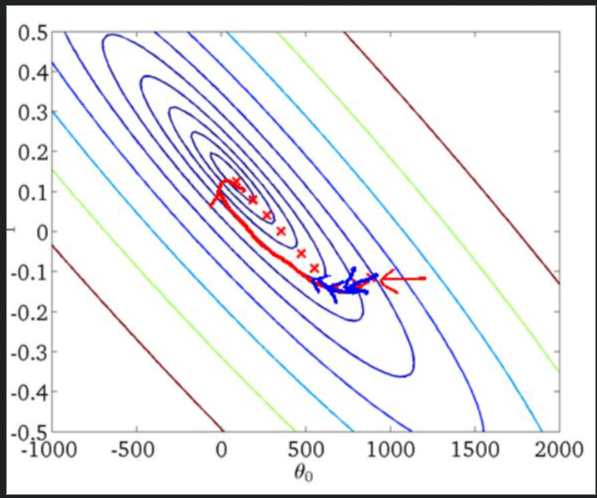

(a)批量梯度下降法
(b)随机梯度下降法
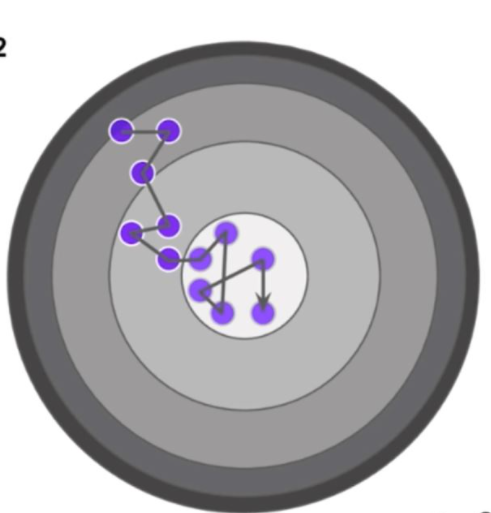
进步地,有人会说深度学习中的优化问基本身就很难,有太多局部最优点的陷阱,没错,这些陷阱对于随机梯度下降法和批量梯度下降都是普遍存在的。但对随机梯度下降法来说,可怕的不是局部最优点,而是山谷和鞍点两类地形。山谷顾名思义就是狭长的山间小道,左右两边是峭壁;鞍点的形状像是一个马鞍,一个方向上两头翘, 另一个方向上两头垂,而中心区域是一片近乎水平的平地。为什么随机梯度下降法最害怕遇上这两类地形呢?在山谷中,准确的梯度方向是沿山道向下,稍有偏离就会撞向山壁,而粗糙的梯度估计使得它在两山壁间来回反弹震荡,不能沿山道方向迅速下降,导致收敛不稳定和收敛速度慢。在鞍点处,随机梯度下降法会走入一片平坦之地(此时离最低点还很远,故也称plateau)。想象一下蒙着双眼只凭借脚底感觉坡度,如果坡度很明显,那么基本能估计出下山的大致方向;如果坡度不明显,则很可能走错方向。同样,在梯度近乎为零的区域,随机梯度下降法无法准确察觉出梯度的微小变化,结果就停滞下来。
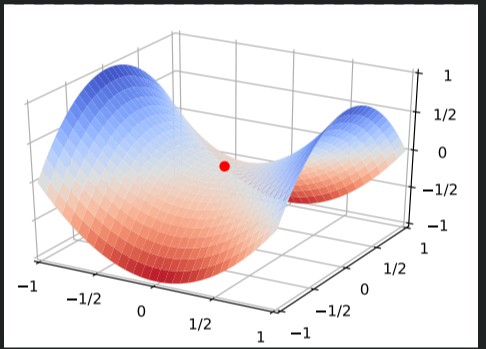
上图示例为鞍点
解决方案:动量(Momentum)方法、AdaGrad方法、Adam方法
分析:随机梯度下降本质上是采用迭代方式更新参数,每次迭代在当前位置的基础上,沿着某一方向迈一小步抵达下一位置,然后再下一位置重复上述步骤。随机梯度下降法的更新公式表示为: θ t + 1 = θ t − η g t \theta_{t+1}=\theta_{t}-\eta g_{t} θt+1=θt−ηgt,其中,当前估计的负梯度 − g t -g_{t} −gt表示步子的方向,学习速率 η \eta η,控制步幅,改造的随机梯度下降法仍然基于这个更新公式。
动量(Momentum)方法
为了解决随机梯度下降法山谷震荡和鞍点停滞的问题,我们做一个简单的思维实验。想象一下纸团在山谷和鞍点处的运动轨迹,在山谷中纸团受重力作用沿山道滚下,两边是不规则的山壁,纸团不可避免地撞在山壁上,由于质量小受山壁弹力的干扰大,从一侧山壁反弹回来撞向另一侧山壁,结果来回震荡地滚下;如果当纸团来到鞍点的一片平坦之地时,还是由于质属小,速度很快减为零。纸团的情况和随机梯度下降法遇到的问题面直如出一辙。直观地,如果换成一个铁球,当沿着山谷滚下时,不容易受到途中旁力的干扰,轨迹会更稳更直;当来到鞍点中心处,在惯性作用下继续前行,从而有机会冲出这片平坦的陷阱,因此,有了动量方法,模型参数的迭代公式为:
v t = γ v t − 1 + η g t v_{t}=\gamma v_{t-1}+\eta g_{t} vt=γvt−1+ηgt。
θ t + 1 = θ t − v t {\theta_{t+1}={\theta}_{t}-{v_{t}}} θt+1=θt−vt。
具体来说,前进步伐 v t v_{t} vt,由两部分组成。一是学习速率 η {\eta} η乘以当前估计的梯度 g t {g_{t}} gt;二是带衰减的前一次步伐 v t − 1 {v_{t-1}} vt−1这里,惯性就体现在对前一次步伐信息的重利用上。类比中学物理知识,当前梯度就好比当前时刻受力产生的加速度,前一次步伐好比前一-时刻的速度,当前步伐好比当前时刻的速度。为了计算当前时刻的速度,应当考虑前一时刻速度和当前加速度共同作用 的结果,因此 v t {v_{t}} vt直接依赖于 v t − 1 {v_{t -1}} vt−1和 g t {g_{t}} gt,而不仅仅是 g t {g_{t}} gt。另外,衰减系数 γ {\gamma} γ扮演了阻力的作用。
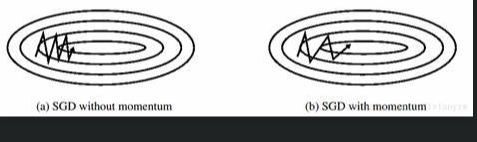
中学物理还告诉我们,刻画惯性的物理量是动量,这也是算法名字的由来。沿山谷滚下的铁球,会受到沿坡道向下的力和与左右山壁碰撞的弹力。向下的力稳定不变,产生的动量不断累积,速度越来越快;左右的弹力总是在不停切换,动量累积的结果是相互抵消,自然减弱了球的来回震荡。因此,与随机梯度下降法相比,动量方法的收敛速度更快,收敛曲线也更稳定,如下图示
AdaGrad 方法
惯性的获得是基于历史信息的,那么,除了从过去的步伐中获得一股子向前冲的劲儿,还能获得什么呢?我们还期待获得对周围环境的感知,即使蒙上双眼,依靠前几次迈步的感觉,也应该能判断出一些信息,比如这个方向总是坑坑洼洼的,那个方向可能很平坦。随机梯度下降法对环境的感知是指在参数空间中,根据不同参数的一些经验性判断,自适应地确定参数的学习速率,不同参数的更新步幅是不同的。例如,在文本处理中训练词嵌入模型的参数时,有的词或词组频繁出现,有的词或词组则极少出现。数据的稀疏性导致相应参数的梯度的稀疏性,不频繁出现的词或词组的参数的梯度在大多数情况下为零,从而这些参数被更新的频率很低。在应用中,我们希望更新频率低的参数可以拥有较大的更新步幅,而更新频率高的参数的步幅可以减小。AdaGrad方法采用“历史梯度平方和”来衡量不同参数的梯度的稀疏性,取值越小表明越稀疏,具体的更新公式表示为
θ t + 1 , i = θ t , i − η ∑ k = 0 t g k , i 2 + ϵ g t , i \theta_{t+1, i}=\theta_{t, i}-\frac{\eta}{\sqrt{\sum_{k=0}^{t} g_{k, i}^{2}+\epsilon}} g_{t, i} θt+1,i=θt,i−∑k=0tgk,i2+ϵηgt,i
其中, θ t + 1 {\theta_{t+1}} θt+1表示(t+1)时刻的参数向量 θ t + 1 {\theta_{t+1}} θt+1的第 i {i} i个参数, g k , i {g_{k,i}} gk,i表示第 k {k} k时刻的梯度向量 g k {g_{k}} gk的第 i {i} i个维度(方向)。另外,分母中求和的形式实现了退火过程,这是很多优化技术中常见的策略,意味着随着时间的推移,学习速率 η ∑ k = 0 t g k , i 2 + ϵ \frac{\eta}{\sqrt{\sum_{k=0}^{t} g_{k, i}^{2}+\epsilon}} ∑k=0tgk,i2+ϵη越来越小。从而保证了算法的最终收敛。
Adam方法
Adam方法将惯性保持和环境感知这两个优点集于一身。 一方面,Adam记录梯度的一阶矩(first moment),即过往梯度与当前梯度的平均,这体现了惯性保持;另一方面,Adam还记录梯度的二阶矩( sccond moment),即过往梯度平方与当前梯度平方的平均,这类似AdaGrad方法,体现了环境感知能力,为不同参数产生自适应的学习速率。一阶矩和二阶矩采用类似于滑动窗口内求平均的思想进行融合,即当前梯度和近一段时间内梯度的平均值,时间久远的梯度对当前平均值的贡献呈指数衰减。具体来说,一阶矩和二阶矩采用指数衰退平均( exponential decay average)技术,计算公式为
m t = β 1 m t − 1 + ( 1 − β 1 ) g t m_{t}=\beta_{1} m_{t-1}+\left(1-\beta_{1}\right) g_{t} mt=β1mt−1+(1−β1)gt
v t = β 2 v t − 1 + ( 1 − β 2 ) g t 2 v_{t}=\beta_{2} v_{t-1}+\left(1-\beta_{2}\right) g_{t}^{2} vt=β2vt−1+(1−β2)gt2,其中 β 1 {\beta_{1}} β1, β 2 {\beta_{2}} β2为衰减系数, m t {m_{t}} mt是一阶矩, v t {v_{t}} vt是二阶矩。
如何理解一-阶矩和二阶矩呢?一阶矩相当于估计 E [ g t ] \mathbb{E}\left[g_{t}\right] E[gt]:由于当下梯度g,是随机采样得到的估计结果,因此更关注它在在统计意义上的期望;二阶矩相当于估计 E [ g t ] \mathbb{E}\left[g_{t}\right] E[gt],这点与AdaGrad方法不同,不是从开始到现在的加和,而是它的期望。它们的物理意义是,当 ∥ m t ∥ \left\|m_{t}\right\| ∥mt∥大且 v t {v_{t}} vt大时,梯度大且稳定,这表明遇到一个明显的大坡,前进方向明确;当 ∥ m t ∥ \left\|m_{t}\right\| ∥mt∥趋于零且 v t {v_{t}} vt大时,梯度不稳定,表明可能遇到一个峡谷,容易引起反弹震荡;当 ∥ m t ∥ \left\|m_{t}\right\| ∥mt∥大且 v t {v_{t}} vt趋于零时,这种情况不可能出现;当 ∥ m t ∥ \left\|m_{t}\right\| ∥mt∥趋于零且 v t {v_{t}} vt趋于零时,梯度趋于零,可能到达局部最低点,也可能走到一片坡度极缓的平地,此时要避免陷入平原( plateau)。另外,Adam方法还考虑了 m t {m_{t}} mt, v t {v_{t}} vt在零初始值情况下的偏置矫正。具体来说,Adam的更新公式为
θ t + 1 = θ t − η ⋅ m ^ t v ^ t + ϵ \theta_{t+1}=\theta_{t}-\frac{\eta \cdot \hat{m}_{t}}{\sqrt{\hat{v}_{t}+\epsilon}} θt+1=θt−v^t+ϵη⋅m^t其中, m ^ t = m t 1 − β 1 t , v ^ t = v t 1 − β 2 t \hat{m}_{t}=\frac{m_{t}}{1-\beta_{1}^{t}}, \hat{v}_{t}=\frac{v_{t}}{1-\beta_{2}^{t}} m^t=1−β1tmt,v^t=1−β2tvt
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/195177.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
