大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
加了个小目录~方便定位查看~
前言
网上有很多博客讲解遗传算法,但是大都只是“点到即止”,虽然给了一些代码实现,但也是“浅尝辄止”,没能很好地帮助大家进行扩展应用,抑或是进行深入的研究。
这是我的开篇之作~之前没有写博客的习惯,一般是将笔记存本地,但久而久之发现回看不便,而且无法与大家交流和学习。现特此写下开篇之作,若有疏漏之处,敬请指正,谢谢!
本文对遗传算法的原理进行梳理,相关代码是基于国内高校学生联合团队开源的高性能实用型进化算法工具箱geatpy来实现,部分教程引用了geatpy的官方文档:
geatpy官网:Geatpy
若有错误之处,恳请同志们指正和谅解,谢谢!
因为是基于geatpy遗传和进化算法工具箱,所以下文的代码部分在执行前,需要安装geatpy:
pip install geatpy安装时会自动根据系统版本匹配下载安装对应的版本。这里就有个小坑:如果最新版Geatpy没有与当前版本相匹配的包的话,会自动下载旧版的包。而旧版的包在Linux和Mac下均不可用。
安装好后,在Python中输出版本检查是否是最新版(version 2.6.0):
import geatpy as ea
print(ea.__version__)
下面切入主题:
自然界生物在周而复始的繁衍中,基因的重组、变异等,使其不断具有新的性状,以适应复杂多变的环境,从而实现进化。遗传算法精简了这种复杂的遗传过程而抽象出一套数学模型,用较为简单的编码方式来表现复杂的现象,并通过简化的遗传过程来实现对复杂搜索空间的启发式搜索,最终能够在较大的概率下找到全局最优解,同时与生俱来地支持并行计算。
下图展示了常规遗传算法(左侧) 和某种在并行计算下的遗传算法(右侧) 的流程。
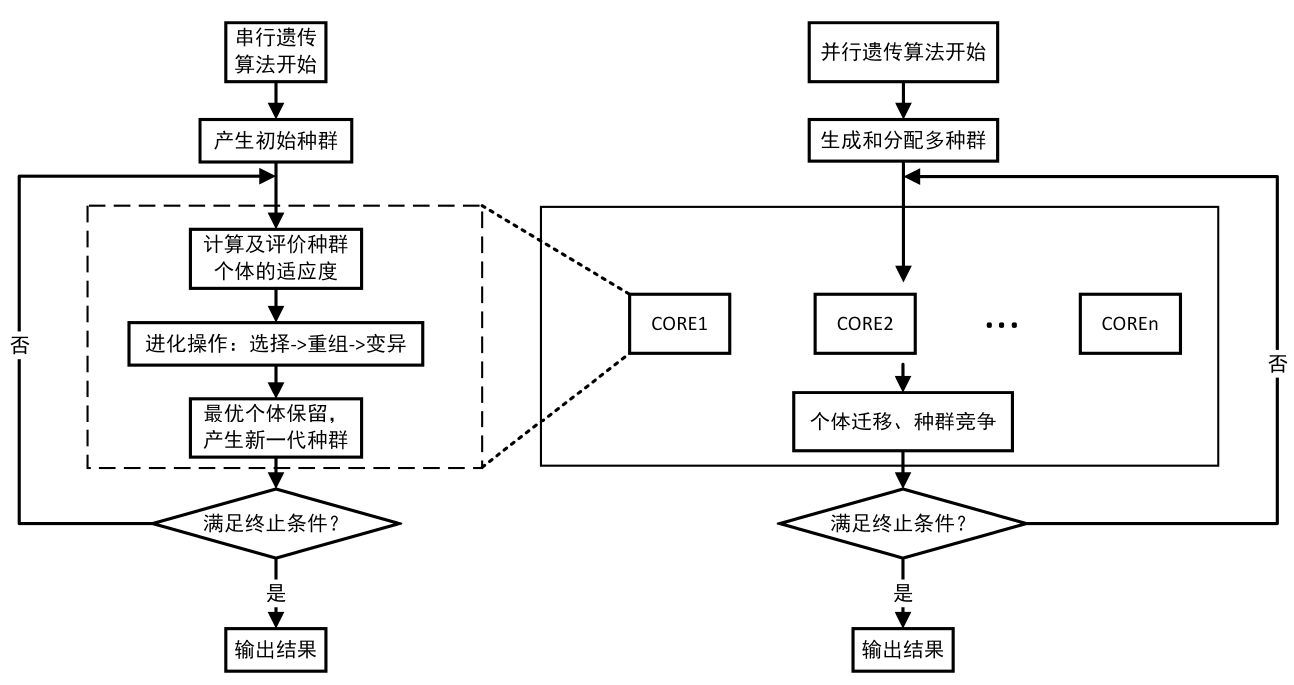

本文只研究经典的遗传算法,力求最后能够解决各种带约束单目标优化问题,并能够很轻松地进行扩展,让大家不仅学到算法理论,还能轻松地通过“复制粘贴”就能够将相关遗传算法代码结合到各类不同的现实问题的求解当中。
从上面的遗传算法流程图可以直观地看出,遗传算法是有一套完整的“固定套路”的,我们可以把这个“套路”写成一个“算法模板”,即把:种群初始化、计算适应度、选择、重组、变异、生成新一代、记录并输出等等这些基本不需要怎么变的“套路”写在一个函数里面,而经常要变的部分:变量范围、遗传算法参数等写在这个函数外面,对于要求解的目标函数,由于在遗传进化的过程中需要进行调用目标函数进行计算,因此可以把目标函数、约束条件写在另一个函数里面。
另外我们还可以发现,在遗传算法的“套路”里面,执行的“初始化种群”、“选择”、“重组”、“变异”等等,其实是一个一个的“算子”,在geatpy工具箱里,已经提供现行的多种多样的进化算子了,因此直接调用即可。
Geatpy工具箱提供一个面向对象的进化算法框架,因此一个完整的遗传算法程序就可以写成这个样子:
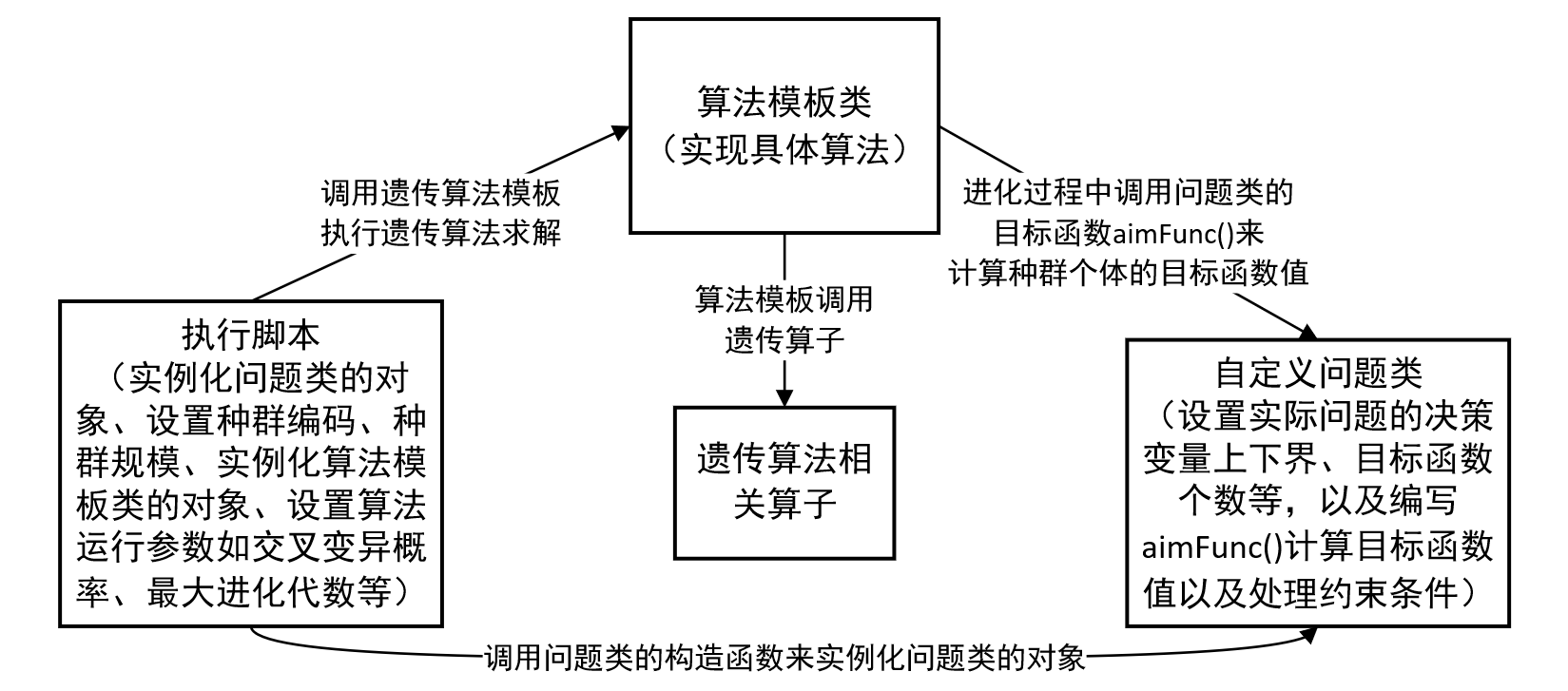
关于算法框架的详细介绍可参见:Geatpy教程 – Geatpy
下面就来详细讲一下相关的理论和代码实现:
正文
一. 基础术语:
先介绍一下遗传算法的几个基础的术语,分别是:”个体“、”种群“、”编码与解码“、”目标函数值“、”适应度值“。
1.个体:“个体”其实是一个抽象的概念,与之有关的术语有:
(1)个体染色体:即对决策变量编码后得到的行向量。
比如:有两个决策变量x1=1,x2=2,各自用3位的二进制串去表示的话,写成染色体就是:

(2)个体表现型:即对个体染色体进行解码后,得到的直接指代各个控制变量的值的行向量。
比如对上面的染色体“0 0 1 0 1 0”进行解码,得到 “1 2”,它就是个体的表现型,可看出该个体存储着两个变量,值分别是1和2。
注意:遗传算法中可以进行“实值编码”,即可以不用二进制编码,直接用变量的实际值来作为染色体。这个时候,个体的染色体数值上是等于个体的表现型的。
(3)染色体区域描述器:用于规定染色体每一位元素范围,详细描述见下文。
2. 种群:“种群”也是一个抽象的概念,与之有关的术语有:
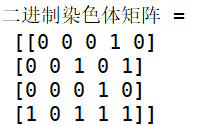
(1)种群染色体矩阵(Chrom):它每一行对应一个个体的染色体。此时会发出疑问:一个个体可以有多条染色体吗?答:可以有,但一般没有必要,一条染色体就可以存储很多决策变量的信息了,如果要用到多条染色体,可以用两个种群来表示。
例如:
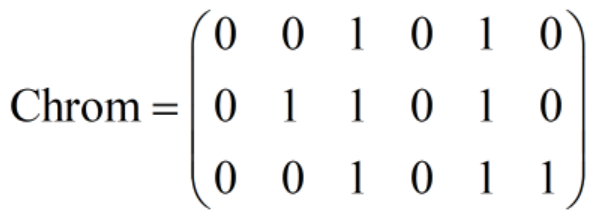
它表示有3个个体(因为有3行),因此有3条染色体。此时需要注意:这些染色体代表决策变量的什么值,我们是不知道的,我们也不知道该种群的染色体采用的是什么编码。染色体具体代表了什么,取决于我们采用什么方式去解码。假如我们采用的是二进制的解码方式,并约定上述的种群染色体矩阵中前3列代表第一个决策变量,后3列代表第二个决策变量,那么,该种群染色体就可以解码成:
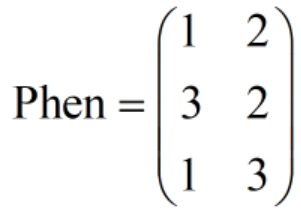
(2)种群表现型矩阵(Phen):它每一行对应一个个体的表现型。比如上图就是根据Chrom种群染色体矩阵解码得到的种群表现型矩阵。同样地,当种群染色体采用的是“实值编码”时,种群染色体矩阵与表现型矩阵实际上是一样的。
(3)种群个体违反约束程度矩阵(CV):它每一行对应一个个体,每一列对应一种约束条件(可以是等式约束或不等式约束)。CV矩阵中元素小于或等于0表示对应个体满足对应的约束条件,大于0则表示不满足,且越大表示违反约束条件的程度越高。比如有两个约束条件:
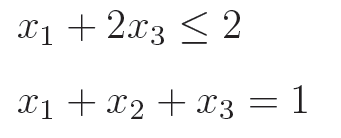
如何计算CV矩阵?可以创建两个列向量CV1和CV2,然后把它们左右拼合而成一个CV矩阵。
假设x1、x2、x3均为存储着种群所有个体的决策变量值的列向量(这里可以利用种群表现型矩阵Phen得到,比如x1=Phen[:, [0]];x2=Phen[:, [1]]);x3=Phen[:, [2]]),这样就可以得到种群所有个体对应的x1、x2和x3)。
那么:
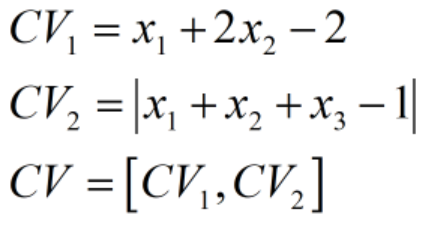
比如在某一代中,种群表现型矩阵Phen为:
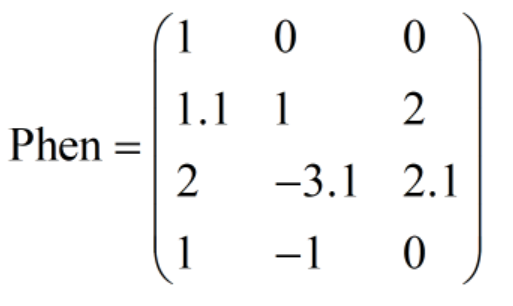
则有:
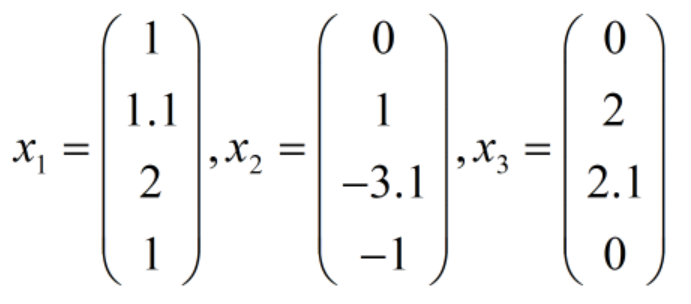
此时CV矩阵的值为:
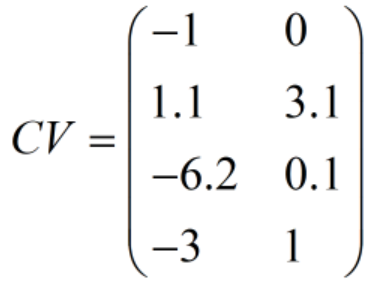
由此可见,第一个个体满足两个约束条件;第二个个体违反了2个约束条件;第三和第四个个体满足第一个约束条件但违反了第二个约束条件。
下面看下如何用代码来生成一个种群染色体矩阵:
代码1. 实整数值种群染色体矩阵的创建:
import numpy as np
from geatpy import crtpc
help(crtpc) # 查看帮助
# 定义种群规模(个体数目)
Nind = 4
Encoding = 'RI' # 表示采用“实整数编码”,即变量可以是连续的也可以是离散的
# 创建“区域描述器”,表明有4个决策变量,范围分别是[-3.1, 4.2], [-2, 2],[0, 1],[3, 3],
# FieldDR第三行[0,0,1,1]表示前两个决策变量是连续型的,后两个变量是离散型的
FieldDR=np.array([[-3.1, -2, 0, 3],
[ 4.2, 2, 1, 5],
[ 0, 0, 1, 1]])
# 调用crtri函数创建实数值种群
Chrom=crtpc(Encoding, Nind, FieldDR)
print(Chrom)
代码1的运行结果:

这里要插入讲一下“区域描述器”(见代码1中的FieldDR),它是用于描述种群染色体所表示的决策变量的一些信息,如变量范围、连续/离散性。另外还有一种区域描述器(FIeldD),用于描述二进制/格雷码的种群染色体。FieldDR和FieldD两个合称“Field”,又可以认为它们是“译码矩阵”。FieldDR具有以下的数据结构:

代码1中的FieldDR矩阵的第三行即为这里的varTypes。它如果为0,表示对应的决策变量是连续型的变量;为1表示对应的是离散型变量。
另一种则是用于二进制/格雷编码种群染色体解码的译码矩阵FieldD,它是具有以下结构的矩阵:
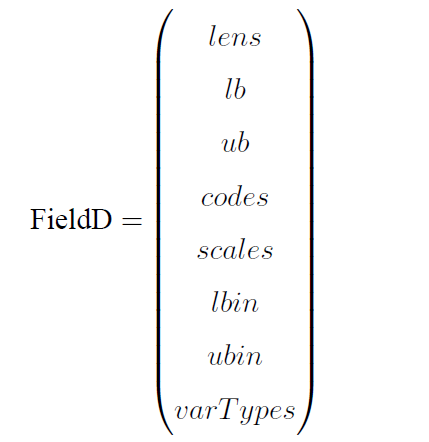
其中,lens, lb, ub, codes, scales, lbin, ubin, varTypes均为长度等于决策变量个数的行向量。
lens 包含染色体的每个子染色体的长度。sum(lens) 等于染色体长度。
lb 和ub 分别代表每个决策变量的上界和下界。
codes 指明染色体子串用的是二进制编码还是格雷编码。codes[i] = 0 表示第i 个变量使用的是标准二进制编码;codes[i] = 1 表示使用格雷编码。
scales 指明每个子串用的是算术刻度还是对数刻度。scales[i] = 0 为算术刻度,scales[i] = 1 为对数刻度。对数刻度可以用于变量的范围较大而且不确定的情况,对于大范围的参数边界,对数刻度让搜索可用较少的位数,从而减少了遗传算法的计算量。(注意:当某个变量是对数刻度时,其取值范围中不能有0,即要么上下界都大于0,要么上下界都小于0。)
从2.5.0版本开始,取消了对对数刻度的支持,该参数暂时保留,但不在起作用。
lbin 和ubin 指明了变量是否包含其范围的边界。0 表示不包含边界;1 表示包含边界。
varTypes 指明了决策变量的类型,元素为0 表示对应位置的决策变量是连续型变量;1 表示对应的是离散型变量。
对于二进制编码,二进制种群的染色体具体代表决策变量的什么含义是不由染色体本身决定的,而是由解码方式决定的。因此在创建二进制种群染色体之初就要设定好译码矩阵(又称“区域描述器”)。
因此,可以通过以下代码构建一个二进制种群染色体矩阵:
代码2. 二进制种群染色体矩阵的创建:
import numpy as np
from geatpy import crtpc
help(crtpc) # 查看帮助
# 定义种群规模(个体数目)
Nind = 4
Encoding = 'BG' # 表示采用“实整数编码”,即变量可以是连续的也可以是离散的
# 创建“译码矩阵”
FieldD = np.array([[3, 2], # 各决策变量编码后所占二进制位数,此时染色体长度为3+2=5
[0, 0], # 各决策变量的范围下界
[7, 3], # 各决策变量的范围上界
[0, 0], # 各决策变量采用什么编码方式(0为二进制编码,1为格雷编码)
[0, 0], # 各决策变量是否采用对数刻度(0为采用算术刻度)
[1, 1], # 各决策变量的范围是否包含下界(对bs2int实际无效,详见help(bs2int))
[1, 1], # 各决策变量的范围是否包含上界(对bs2int实际无效)
[0, 0]])# 表示两个决策变量都是连续型变量(0为连续1为离散)
# 调用crtpc函数来根据编码方式和译码矩阵来创建种群染色体矩阵
Chrom=crtpc(Encoding, Nind, FieldD)
print(Chrom)
代码2运行结果:
3. 编码与解码
对于实整数编码(即上面代码1所创建的实整数种群染色体),它是不需要解码,染色体直接就对应着它所代表的决策变量值。而对于代码2生成的二进制种群染色体矩阵,它需要根据译码矩阵FieldD来进行解码。在代码2后面添加以下语句即可解码:
代码3(上接代码2):
from geatpy import bs2ri
help(bs2ri)
Phen = bs2ri(Chrom, FieldD)
print('表现型矩阵 = \n', Phen)运行效果如下:

4.目标函数值:
种群的目标函数值存在一个矩阵里面(一般命名为ObjV),它每一行对应一个个体的目标函数值。对于单目标而言,这个目标函数值矩阵只有1列,而对于多目标而言,就有多列了,比如下面就是一个含两个目标的种群目标函数值矩阵:
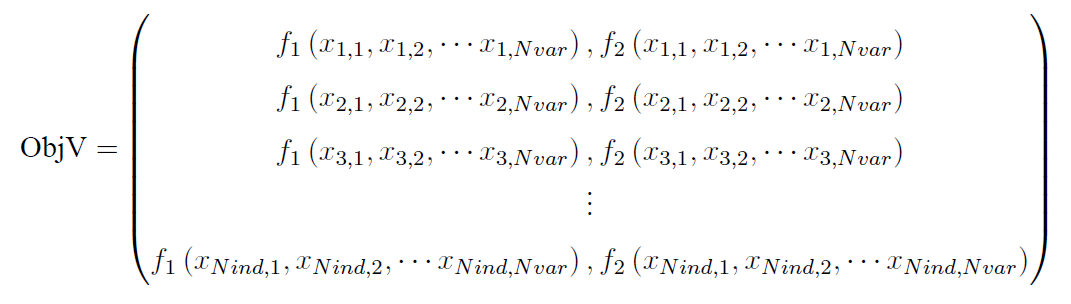
(这里Nind表示种群的规模,即种群含多少个个体;Nvar表示决策变量的个数)
下面来跑一下代码,接着代码3,在对二进制染色体解码成整数值种群后,我们希望计算出f(x,y)=x+y这个目标函数值。同时设置一个等式约束:要求x + y = 3。于是完整代码如下:
代码4:
import numpy as np
from geatpy import crtpc
from geatpy import bs2ri
def aim(Phen):
x = Phen[:, [0]] # 取出种群表现型矩阵的第一列,得到所有个体的决策变量x
y = Phen[:, [1]] # 取出种群表现型矩阵的第二列,得到所有个体的决策变量y
CV = np.abs(x + y - 3) # 生成种群个体违反约束程度矩阵CV,以处理等式约束:x + y == 3
f = x + y # 计算目标函数值
return f, CV # 返回目标函数值矩阵
# 定义种群规模(个体数目)
Nind = 4
Encoding = 'BG' # 表示采用“实整数编码”,即变量可以是连续的也可以是离散的
# 创建“译码矩阵”
FieldD = np.array([[3, 2], # 各决策变量编码后所占二进制位数,此时染色体长度为3+2=5
[0, 0], # 各决策变量的范围下界
[7, 3], # 各决策变量的范围上界
[0, 0], # 各决策变量采用什么编码方式(0为二进制编码,1为格雷编码)
[0, 0], # 各决策变量是否采用对数刻度(0为采用算术刻度)
[1, 1], # 各决策变量的范围是否包含下界(对bs2int实际无效,详见help(bs2int))
[1, 1], # 各决策变量的范围是否包含上界(对bs2int实际无效)
[0, 0]])# 表示两个决策变量都是连续型变量(0为连续1为离散)
# 调用crtpc函数来根据编码方式和译码矩阵来创建种群染色体矩阵
Chrom=crtpc(Encoding, Nind, FieldD)
print('二进制染色体矩阵 = \n', Chrom)
# 解码
Phen = bs2ri(Chrom, FieldD)
print('表现型矩阵 = \n', Phen)
# 计算目标函数值矩阵
ObjV, CV = aim(Phen)
print('目标函数值矩阵 = \n', ObjV)
print('CV矩阵 = \n', CV)
运行结果如下:

由上面对CV矩阵的描述可知,第三个个体的CV值为0,表示第三个个体满足x+y=3这个等式约束。其他都大于0,表示不满足该约束。
疑问:CV矩阵有什么用呢?
答:CV矩阵既可用于标记非可行解,在含约束条件的优化问题中有用,又可用于度量种群个体违反各个约束条件的程度的高低。对于含约束条件的优化问题,我们可以采用罚函数或者是可行性法则来进行处理。罚函数法这里就不展开赘述了,最简单的罚函数可以是直接找到非可行解个体的索引,然后修改其对应的ObjV的目标函数值即可。
对于可行性法则,它需要计算每个个体违反约束的程度,并把结果保存在种群类的CV矩阵中。CV矩阵的每一行对应一个个体、每一列对应一个约束条件(可以是等式约束也可以是不等式约束),CV矩阵中元素小于或等于0表示对应个体满足对应的约束条件,否则是违反对应的约束条件,大于0的值越大,表示违反约束的程度越高。生成CV标记之后,在后面调用适应度函数计算适应度时,只要把CV矩阵作为函数传入参数传进函数体,就会自动根据CV矩阵所描述的种群个体违反约束程度来计算出合适的种群个体适应度。
5.适应度值:
适应度值通俗来说就是对种群个体的”生存能力的评价“。对于简单的单目标优化,我们可以简单地把目标函数值直接当作是适应度值(注意:当用geatpy遗传和进化算法工具箱时,则需要对目标函数值加个负号才能简单地把它当作适应度值,因为geatpy遵循的是”目标函数值越小,适应度值越大“的约定。)
对于多目标优化,则需要根据“非支配排序”或是其他方法来确定种群个体的适应度值,本文不对其展开叙述。
种群适应度(FitnV):它是一个列向量,每一行代表一个个体的适应度值:
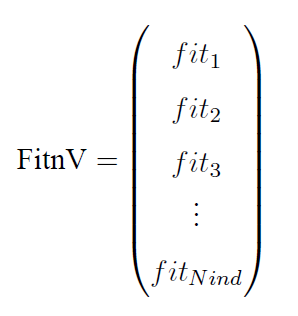
(这里Nind表示种群的规模,即种群含多少个个体)
geatpy遗传和进化算法工具箱里面有几个函数可以计算种群个体的适应度 ,分别是:
ranking、indexing、powing、scaling。具体的用法,可以用help命令查看,如help(ranking)。
下面接着代码4,利用ranking(基于目标函数值排序的适应度分配)计算种群的适应度:
代码5(接着代码4):
from geatpy import ranking
help(ranking)
FitnV = ranking(ObjV, CV)
print('种群适应度矩阵 = \n', FitnV)运行结果:

分析这个结果我们发现,由于第1、2、4个体违反约束条件,而第三个个体满足约束条件,因此第3个个体的适应度最高。而在第1、2、4个体中,个体1的目标函数值最大,因此适应度最低。可见遵循“最小化目标”的约定,即目标函数值越小,适应度越大。
好了,基本的术语和用法讲完后,下面讲一下遗传算法的基本算子:
二. 遗传算法基本算子:
我们不用破费时间去写底层的遗传算子,因为geatpy工具箱提供丰富的进化算子,以下所列算子不仅限于遗传算子:







(如果是在iPython 控制台中调用可视化绘图函数(例如使用Spyder 开发工具),一般图像会默认显示在控制台或者是开发工具中。此时可以在iPython控制台下执行%matplotlib 来设置把图像显示在一个独立窗口中。)
对于多目标优化,Geatpy中内置以下算子:

可以用help(算子名)来查看对应的API文档,查看更详细的用法和例子。
下面讲一下理论:
1.选择:
在进化算法中存在两个阶段的选择。第一次是参与进化操作的个体的选择。这个阶段的选择可以是基于个体适应度的、也可以是完全随机地选择交配个体。一旦个体被选中,那么它们就会参与交叉、变异等进化操作。未被选中的个体不会参与到进化操作中。
第二次是常被称为“重插入”或“环境选择”的选择,它是指在个体经过交叉、变异等进化操作所形成的子代(或称“育种个体”)后用某种方法来保留到下一代从而形成新一代种群的过程。这个选择过程对应的是生物学中的” 自然选择”。它可以是显性地根据适应度(再次注意:适应度并不等价于目标函数值)来进行选择的,也可以是隐性地根据适应度(即不刻意去计算个体适应度)来选择。例如在多目标优化的NSGA-II 算法中,父代与子代合并后,处于帕累托分层中第一层级的个体以及处于临界层中的
且拥挤距离最大的若干个个体被保留到下一代。这个过程就没有显性地去计算每个个体的适应度。
经典的选择算子有:“轮盘赌选择”、“随机抽样选择”、“锦标赛选择”、“本地选择”、“截断选择”、“一对一生存者竞争选择”等等,这里不展开叙述了,可以参考:
这里要注意:遗传算法选择出的后代是可以有重复的。
下面以低级选择函数:锦标赛选择算子(tour)为例,使用help(tour)查看其API,得到:

实战演练如下:
代码6:
import numpy as np
from geatpy import tour
help(tour)
FitnV = np.array([[1.2],[0.8],[2.1], [3.2],[0.6],[2.2],[1.7],[0.2]])
chooseIdx = tour(FitnV, 6)
print('个体的适应度为:\n', FitnV)
print('选择出的个体的下标为:\n', chooseIdx)
运行结果:

光这样还不够,这里只是得出了选择个体的下标,如果我们需要得到被选中个体的染色体,同时尝试改用高级选择函数“selecting”来调用低级选择算子“tour”来进行选择,则可以如下操作:
代码7:
import numpy as np
from geatpy import selecting
help(selecting)
Chrom=np.array([[1,11,21],
[2,12,22],
[3,13,23],
[4,14,24],
[5,15,25],
[6,16,26],
[7,17,27],
[8,18,28]])
FitnV = np.array([[1.2],[0.8],[2.1], [3.2],[0.6],[2.2],[1.7],[0.2]])
SelCh = Chrom[selecting('tour', FitnV, 6), :] # 使用'tour'锦标赛选择算子,同时片取Chrom得到所选择个体的染色体
print('个体的适应度为:\n', FitnV)
print('选择后得到的种群染色矩阵为:\n', SelCh)
代码7运行结果如下:

将代码7中的’tour’换成工具箱中的其他选择算子的名称(如etour, rws, sus),就可以使用相应的选择算子进行选择。
2.重组:
在很多的国内教材、博客文章、论文中,只提到“交叉”的概念。事实上,遗传算法的“交叉”是属于“重组”算子里面的。因为交叉算子经常使用,而对于“离散重组”、“中间重组”、“线性重组”等等,因为用的很少,所以我们常常只谈“交叉”算子了。交叉算子实际上是“值互换重组”(Values exchanged recombination)。这里就不展开叙述了,可以参考:
与重组有关的遗传算法参数是“重组概率”(对于交叉而言就是“交叉概率”)(Pc),它是指两个个体的染色体之间发生重组的概率。
下面以两点交叉(xovdp)为例,类似上面的“tour”那样我们使用help(xovdp)查看其API:

代码实战演练如下:
代码8:
from geatpy import xovdp
import numpy as np
help(xovdp)
OldChrom=np.array([[1,1,1,1,1],[1,1,1,1,1],[0,0,0,0,0],[0,0,0,0,0]]) #创建一个二进制种群染色体矩阵
print('交叉前种群染色矩阵为:\n', OldChrom)
NewChrom = xovdp(OldChrom, 1) # 设交叉概率为1
print('交叉后种群染色矩阵为:\n', NewChrom)
代码8运行结果如下:

由此可见,xovdp是将前一半个体和后一半个体进行配对交叉的,有人认为应该随机选择交叉个体。事实上,在遗传算法进化过程中,各个位置的个体是什么,本身是随机的,不必要在交叉这里再增添一个随机(当然,可以在执行xovdp两点交叉之前,将种群染色体矩阵按行打乱顺序然后再交叉,从而满足自身需求)。
3.变异:

下面以均匀突变(mutuni)为例,编写代码实现实数值编码的种群染色体的均匀突变,使用help(mutuni)查看API文档。
代码9:
from mutuni import mutuni
import numpy as np
# 自定义种群染色体矩阵,表示有3个个体,且染色体元素直接表示变量的值(即实值编码)
OldChrom = np.array([[9,10],
[10,10],
[10,10]])
# 创建区域描述器(又称译码矩阵)
FieldDR = np.array([[7,8],
[10,10],
[1, 1]])
# 此处设编码方式为实值编码中的“实整数编码”RI,表示染色体可代表实数和整数
NewChrom = mutuni('RI', OldChrom, FieldDR, 1)
print(NewChrom)
代码9的运行结果如下:

4.重插入:
经典遗传算法通过选择、重组和变异后,我们得到的是育种后代,此时育种后代的个体数有可能会跟父代种群的个体数不相同。这时,为了保持种群的规模,这些育种后代可以重新插入到父代中,替换父代种群的一部分个体,或者丢弃一部分育种个体,最终形成新一代种群。前面曾提到过“重插入”也是一种选择,但它是环境选择,是用于生成新一代种群的;而前面在交叉变异之前的选择是用于选择个体参与交叉变异,那个选择常被称作“抽样”。
现考虑使用精英个体保留的遗传算法“EGA”,则重插入操作如下:
代码10:
from mutuni import mutuni
import numpy as np
# 自定义父代种群染色体(仅作为例子):
Chrom = np.array([[1.1, 1.3],
[2.4, 1.2],
[3, 2.1],
[4, 3.1]])
# 若父代个体的适应度为:
FitnV = np.array([[1],
[2],
[3],
[4]])
# 考虑采用“精英保留策略”的遗传算法,此时从父代选择出4-1=3个个体,经过交叉变异后假设子代的染色体为:
offChrom = np.array([[2.1, 2.3],
[2.3, 2.2],
[3.4, 1.1]])
# 假设直接把目标函数值当作适应度,且认为适应度越大越好。则通过以下代码重插入生成新一代种群:
bestIdx = np.argmax(FitnV) # 得到父代精英个体的索引
NewChrom = np.vstack([Chrom[bestIdx, :], offChrom]) # 得到新一代种群的染色体矩阵
print('新一代种群的染色体矩阵为:\n', NewChrom)
在“EGA”中,假设父代种群规模为N,则选择出(N-1)个个体进行交叉变异,然后找出父代的精英个体,用着个精英个体和交叉变异得到的子代个体进行“拼合”,得到新一代种群。
除了这种重插入生成新一代种群的方法外,还有“父子两代个体合并选择”等更优秀的生成新一代种群的方法,这里就不一一赘述了。
讲完上面的基本术语以及遗传算法基本算子后,我们就可以来利用遗传算法的“套路”编写一个遗传算法求解问题的程序了:
三.完整实现遗传算法:
上文提到遗传算法程序可以写成这个样子:
其核心是算法模板类。在遗传算法模板里,我们根据遗传算法的“套路”,进行:初始化种群、目标函数值计算、适应度评价、选择、重组、变异、记录各代最优个体等操作。geatpy工具箱内置有开源的“套路模板”,源代码参见:
https://github.com/geatpy-dev/geatpy/tree/master/geatpy/source-code/templets
这些内置算法模板有详细的输入输出参数说明,以及遗传算法整个流程的完整注释,它们可以应对简单或复杂的、单目标优化的、多目标优化的、约束优化的、组合优化的等等的问题。
但为了学习,我这里先不采用框架,直接利用工具箱提供的库函数来写一个带精英个体保留的遗传算法。这样代码量比较大,但有利于入门。
编写代码 11、12,分别放在同一个文件夹下:
代码11(目标函数aimfuc.py)(这里要回顾一下前面,Phen是种群表现型矩阵,存储的是种群所有个体的表现型,而不是单个个体。因而计算得到的目标函数值矩阵也是包含所有个体的目标函数值):
# -*- coding: utf-8 -*-
"""
aimfunc.py - 目标函数文件
描述:
目标:max f = 21.5 + x1 * np.sin(4 * np.pi * x1) + x2 * np.sin(20 * np.pi * x2)
约束条件:
x1 != 10
x2 != 5
x1 ∈ [-3, 12.1] # 变量范围是写在遗传算法的参数设置里面
x2 ∈ [4.1, 5.8]
"""
import numpy as np
def aimfunc(Phen, CV):
x1 = Phen[:, [0]] # 获取表现型矩阵的第一列,得到所有个体的x1的值
x2 = Phen[:, [1]]
f = 21.5 + x1 * np.sin(4 * np.pi * x1) + x2 * np.sin(20 * np.pi * x2)
exIdx1 = np.where(x1 == 10)[0] # 因为约束条件之一是x1不能为10,这里把x1等于10的个体找到
exIdx2 = np.where(x2 == 5)[0]
CV[exIdx1] = 1
CV[exIdx2] = 1
return [f, CV]
然后是编写算法:
代码12:
# -*- coding: utf-8 -*-
"""main.py"""
import numpy as np
import geatpy as ea # 导入geatpy库
from aimfunc import aimfunc # 导入自定义的目标函数
import time
"""============================变量设置============================"""
x1 = [-3, 12.1] # 第一个决策变量范围
x2 = [4.1, 5.8] # 第二个决策变量范围
b1 = [1, 1] # 第一个决策变量边界,1表示包含范围的边界,0表示不包含
b2 = [1, 1] # 第二个决策变量边界,1表示包含范围的边界,0表示不包含
ranges=np.vstack([x1, x2]).T # 生成自变量的范围矩阵,使得第一行为所有决策变量的下界,第二行为上界
borders=np.vstack([b1, b2]).T # 生成自变量的边界矩阵
varTypes = np.array([0, 0]) # 决策变量的类型,0表示连续,1表示离散
"""==========================染色体编码设置========================="""
Encoding = 'BG' # 'BG'表示采用二进制/格雷编码
codes = [0, 0] # 决策变量的编码方式,设置两个0表示两个决策变量均使用二进制编码
precisions =[4, 4] # 决策变量的编码精度,表示二进制编码串解码后能表示的决策变量的精度可达到小数点后6位
scales = [0, 0] # 0表示采用算术刻度,1表示采用对数刻度
FieldD = ea.crtfld(Encoding,varTypes,ranges,borders,precisions,codes,scales) # 调用函数创建译码矩阵
"""=========================遗传算法参数设置========================"""
NIND = 100; # 种群个体数目
MAXGEN = 200; # 最大遗传代数
maxormins = [-1] # 列表元素为1则表示对应的目标函数是最小化,元素为-1则表示对应的目标函数是最大化
selectStyle = 'rws' # 采用轮盘赌选择
recStyle = 'xovdp' # 采用两点交叉
mutStyle = 'mutbin' # 采用二进制染色体的变异算子
pc = 0.7 # 交叉概率
pm = 1 # 整条染色体的变异概率(每一位的变异概率=pm/染色体长度)
Lind = int(np.sum(FieldD[0, :])) # 计算染色体长度
obj_trace = np.zeros((MAXGEN, 2)) # 定义目标函数值记录器
var_trace = np.zeros((MAXGEN, Lind)) # 染色体记录器,记录历代最优个体的染色体
"""=========================开始遗传算法进化========================"""
start_time = time.time() # 开始计时
Chrom = ea.crtpc(Encoding, NIND, FieldD) # 生成种群染色体矩阵
variable = ea.bs2ri(Chrom, FieldD) # 对初始种群进行解码
CV = np.zeros((NIND, 1)) # 初始化一个CV矩阵(此时因为未确定个体是否满足约束条件,因此初始化元素为0,暂认为所有个体是可行解个体)
ObjV, CV = aimfunc(variable, CV) # 计算初始种群个体的目标函数值
FitnV = ea.ranking(maxormins * ObjV, CV) # 根据目标函数大小分配适应度值
best_ind = np.argmax(FitnV) # 计算当代最优个体的序号
# 开始进化
for gen in range(MAXGEN):
SelCh = Chrom[ea.selecting(selectStyle,FitnV,NIND-1),:] # 选择
SelCh = ea.recombin(recStyle, SelCh, pc) # 重组
SelCh = ea.mutate(mutStyle, Encoding, SelCh, pm) # 变异
# 把父代精英个体与子代的染色体进行合并,得到新一代种群
Chrom = np.vstack([Chrom[best_ind, :].astype(int), SelCh])
Phen = ea.bs2ri(Chrom, FieldD) # 对种群进行解码(二进制转十进制)
ObjV, CV = aimfunc(Phen, CV) # 求种群个体的目标函数值
FitnV = ea.ranking(maxormins * ObjV, CV) # 根据目标函数大小分配适应度值
# 记录
best_ind = np.argmax(FitnV) # 计算当代最优个体的序号
obj_trace[gen,0]=np.sum(ObjV)/ObjV.shape[0] #记录当代种群的目标函数均值
obj_trace[gen,1]=ObjV[best_ind] #记录当代种群最优个体目标函数值
var_trace[gen,:]=Chrom[best_ind,:] #记录当代种群最优个体的染色体
# 进化完成
end_time = time.time() # 结束计时
ea.trcplot(obj_trace, [['种群个体平均目标函数值', '种群最优个体目标函数值']]) # 绘制图像
"""============================输出结果============================"""
best_gen = np.argmax(obj_trace[:, [1]])
print('最优解的目标函数值:', obj_trace[best_gen, 1])
variable = ea.bs2ri(var_trace[[best_gen], :], FieldD) # 解码得到表现型(即对应的决策变量值)
print('最优解的决策变量值为:')
for i in range(variable.shape[1]):
print('x'+str(i)+'=',variable[0, i])
print('用时:', end_time - start_time, '秒')执行代码12得到如下结果:
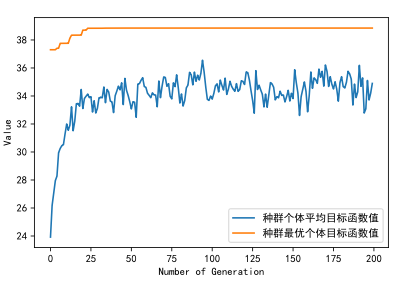

终于,我们把遗传算法完整地实现了,但扩展性还不够高。下面学习下如何使用Geatpy提供的进化算法框架来求解上述问题:(关于使用框架来优化的介绍可详见Geatpy教程 – Geatpy)
在这里我们可以回顾以下在本文开头提到的采用遗传算法的“套路”来编程求解问题的基本流程:
其中执行脚本和问题类是需要编写的,算法模板类我直接调用Geatpy内置的”soea_EGA_templet”(带精英个体保留的单目标遗传算法模板)。下面开始编写代码:
代码13:问题类”MyProblem”的编写:
# -*- coding: utf-8 -*-
"""
MyProblem.py
该案例展示了一个简单的连续型决策变量最大化目标的单目标优化问题。
max f = x * np.sin(10 * np.pi * x) + 2.0
s.t.
-1 <= x <= 2
"""
import numpy as np
import geatpy as ea
class MyProblem(ea.Problem): # 继承Problem父类
def __init__(self):
name = 'MyProblem' # 初始化name(函数名称,可以随意设置)
M = 1 # 初始化M(目标维数)
maxormins = [-1] # 初始化maxormins(目标最小最大化标记列表,1:最小化该目标;-1:最大化该目标)
Dim = 2 # 初始化Dim(决策变量维数)
varTypes = [0] * Dim # 初始化varTypes(决策变量的类型,元素为0表示对应的变量是连续的;1表示是离散的)
lb = [-3, 4.1] # 决策变量下界
ub = [12.1, 5.8] # 决策变量上界
lbin = [1] * Dim # 决策变量下边界
ubin = [1] * Dim # 决策变量上边界
# 调用父类构造方法完成实例化
ea.Problem.__init__(self, name, M, maxormins, Dim, varTypes, lb, ub, lbin, ubin)
def aimFunc(self, pop): # 目标函数
x1 = pop.Phen[:, [0]] # 获取表现型矩阵的第一列,得到所有个体的x1的值
x2 = pop.Phen[:, [1]]
f = 21.5 + x1 * np.sin(4 * np.pi * x1) + x2 * np.sin(20 * np.pi * x2)
exIdx1 = np.where(x1 == 10)[0] # 因为约束条件之一是x1不能为10,这里把x1等于10的个体找到
exIdx2 = np.where(x2 == 5)[0]
pop.CV = np.zeros((pop.sizes, 2))
pop.CV[exIdx1, 0] = 1
pop.CV[exIdx2, 1] = 1
pop.ObjV = f # 计算目标函数值,赋值给pop种群对象的ObjV属性
第二步:编写执行脚本“main.py”
# -*- coding: utf-8 -*-
import numpy as np
import geatpy as ea # import geatpy
from MyProblem import MyProblem # 导入自定义问题接口
# 实例化问题对象
problem = MyProblem()
# 构建算法
algorithm = ea.soea_EGA_templet(problem,
ea.Population(Encoding='BG', NIND=100),
MAXGEN=200, # 最大进化代数
logTras=1) # 表示每隔多少代记录一次日志信息
# 求解
res = ea.optimize(algorithm, verbose=True, drawing=1, outputMsg=True, drawLog=False, saveFlag=True, dirname='result')运行”main.py”执行脚本即可得到以下结果:
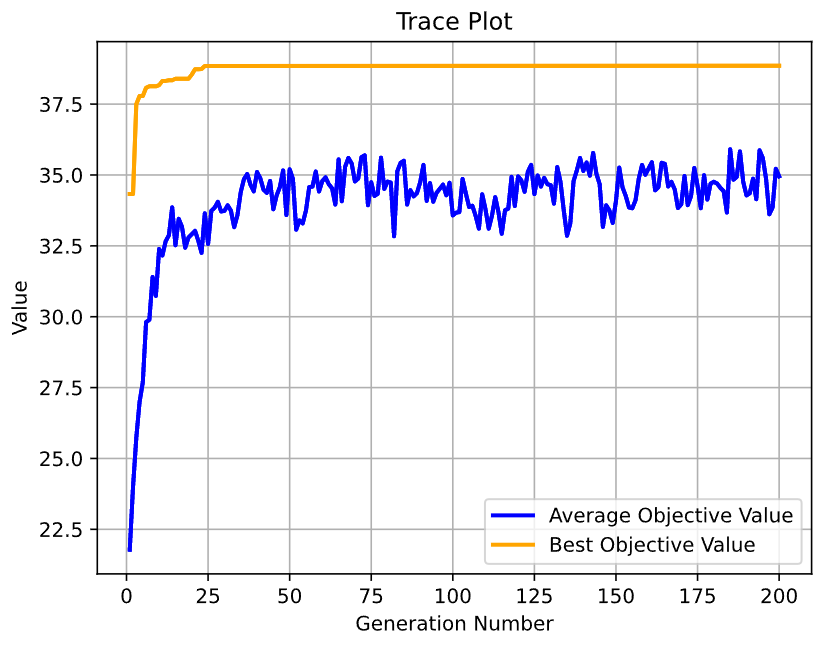
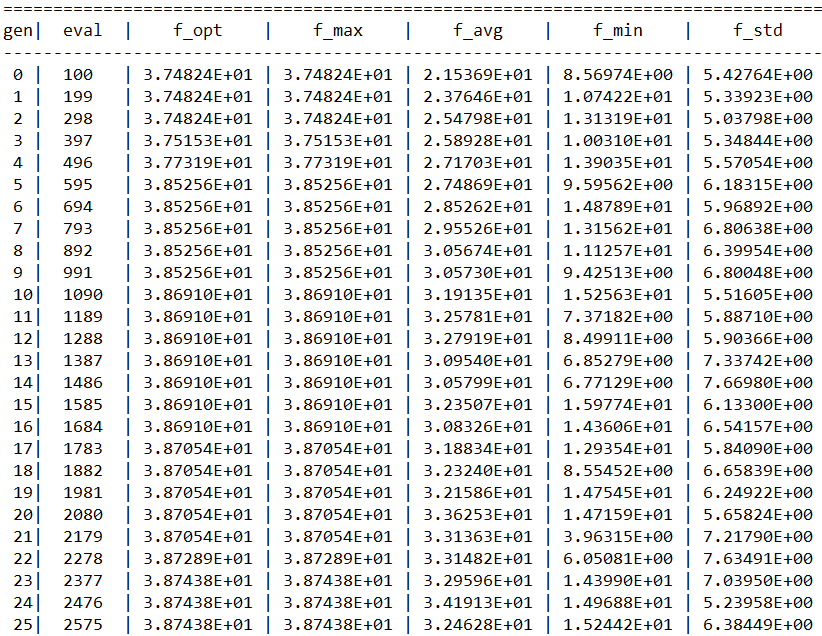
……
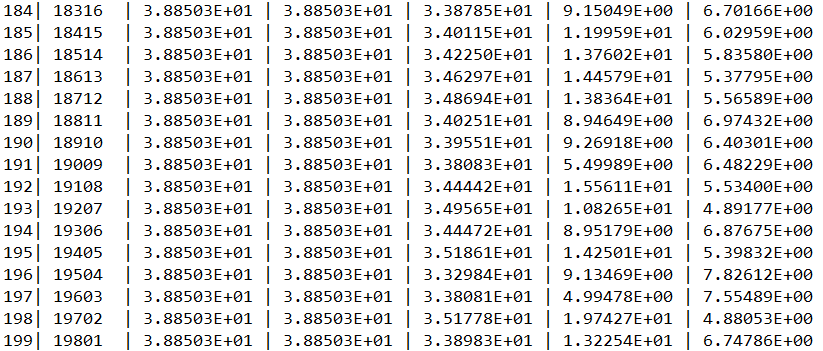
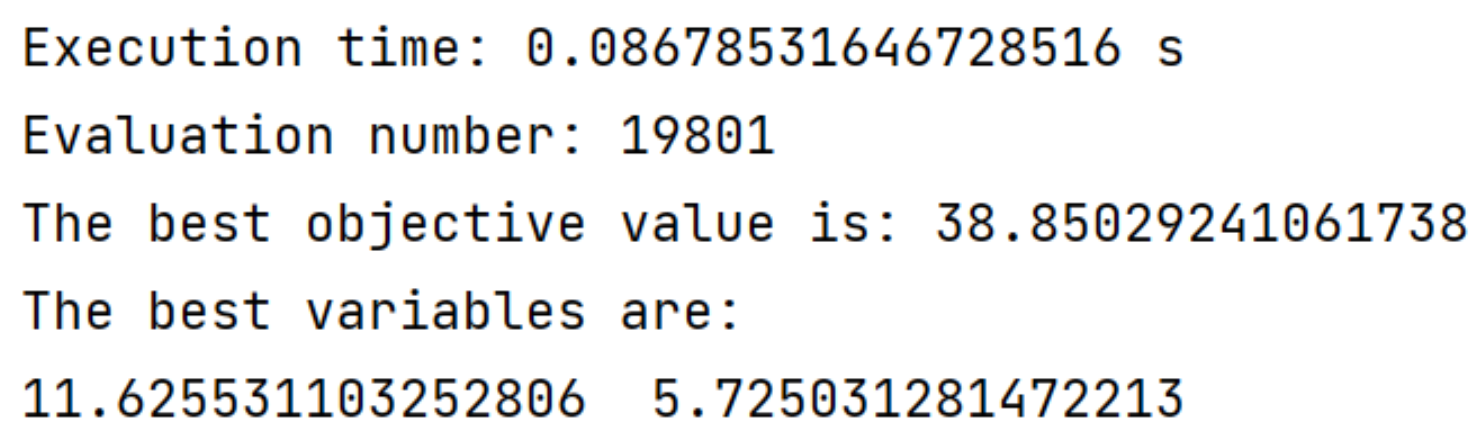
代码解析:在“main.py”执行脚本中,一开始需要实例化一个问题对象。然后是种群对象的实例化。在实例化种群对象前,需要设定种群的编码方式Encoding、种群规模NIND,并且生成区域描述器Field(或称译码矩阵),因为种群类的构造方法中需要至少用到这三个参数(详见“Population.py”中种群类的构造方法)。
在完成了问题类对象和种群对象的实例化后,将其传入算法模板类的构造方法来实例化一个算法模板对象。这里我实例化的是单目标优化的EGA算法(即带精英个体保留的遗传算法)的模板类对象,即代码中的”soea_EGA_templet”。里面的进化算法具体是如何操作的,可详见https://github.com/geatpy-dev/geatpy/blob/master/geatpy/templates/soeas/GA/EGA/soea_EGA_templet.py
采用Geatpy提供的进化算法框架可以既能最大程度地描述清楚所要求解的问题,而且与进化算法是高度脱耦的,即上面在编写问题类的时候完全不需要管后面采用什么算法、采用什么样编码的种群,只需把问题描述清楚即可。
而且,遗传算法有个好处是:目标函数可以写得相当复杂,可以解决各种复杂的问题,比如神经网络。以BP神经网络为例,可以把神经网络的参数作为决策变量,神经网络的训练误差作为目标函数值,只需把上面的例子修改一下就行了。
而且,一般而言我们不需要像我刚刚最开始那样刻意去手写进化算法,可以直接调用geatpy内置的算法模板就可以解决问题了。geatpy工具箱提供这些内置的算法模板:

应用Geatpy求解数学建模、工业设计、资源调度等实际优化问题的的朋友们可以直接使用这些算法模板快速解决各种灵活的优化问题。
四.后记:
最后十分感谢由Geatpy团队提供的高性能实用型遗传和进化算法工具箱,它提供开源的进化算法框架为遗传算法求解单目标/多目标优化、约束优化、组合优化等等给出了相当准确和快捷的解决方案。据称,geatpy的运行性能相当的高,远高于matlab的遗传算法工具箱、以及采用JAVA、matlab或者Python编写的一些进化优化平台或框架,比如jMetal、platemo、pymoo、deap等,后面有时间我将进行详细的性能对比实验分析,有相关经验的读者也可以自行对比性能。而且依我的体验来看,这是我网上到处找代码、找资料学习、碰了无数次壁后所看到的比较易学易用的工具箱了。
最后值得注意的是Geatpy的顶层是面向对象的进化算法框架,底层是面向过程的进化算子。下面放一张geatpy的UML类图、算法调用的层次结构和库函数调用关系图,以此记录方便查看:
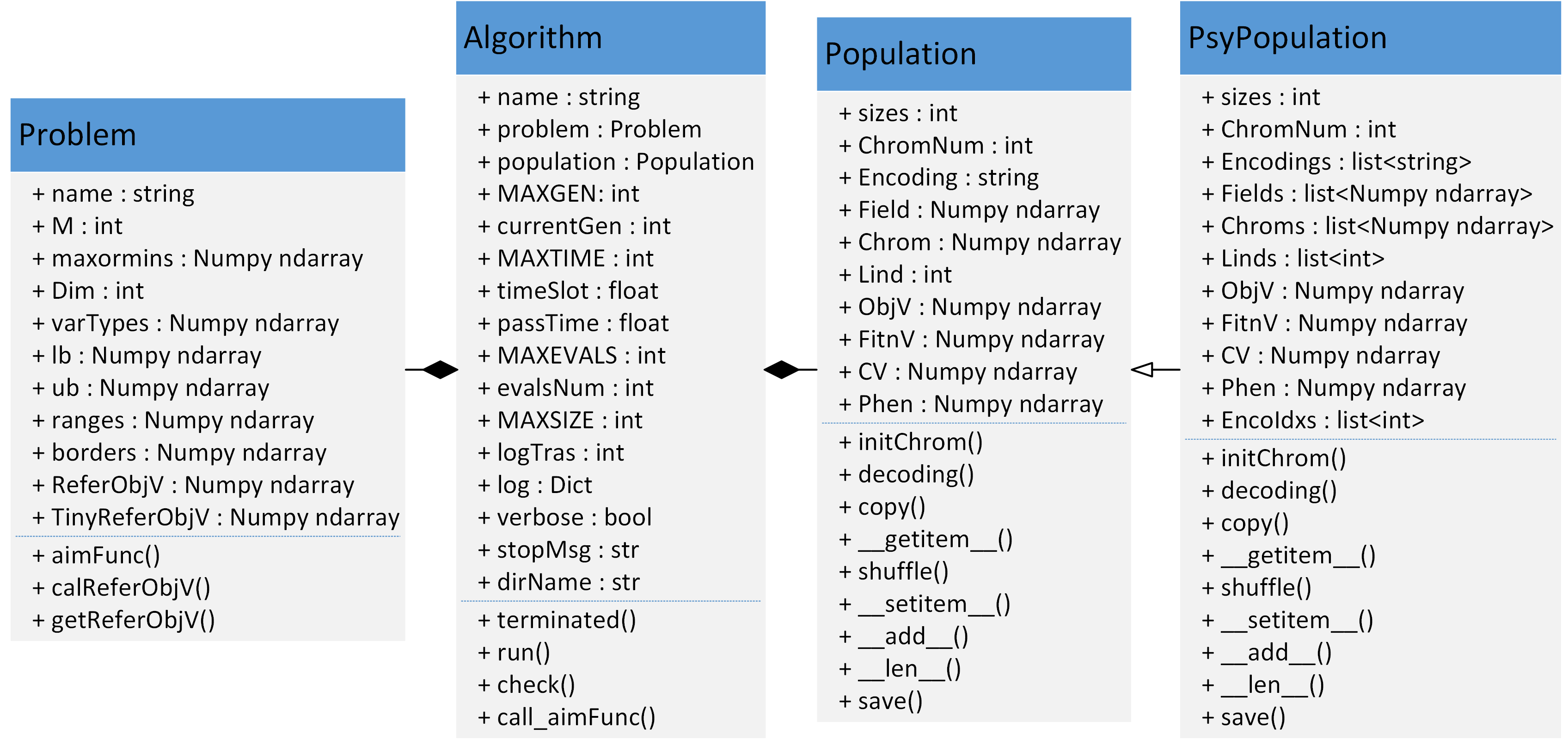
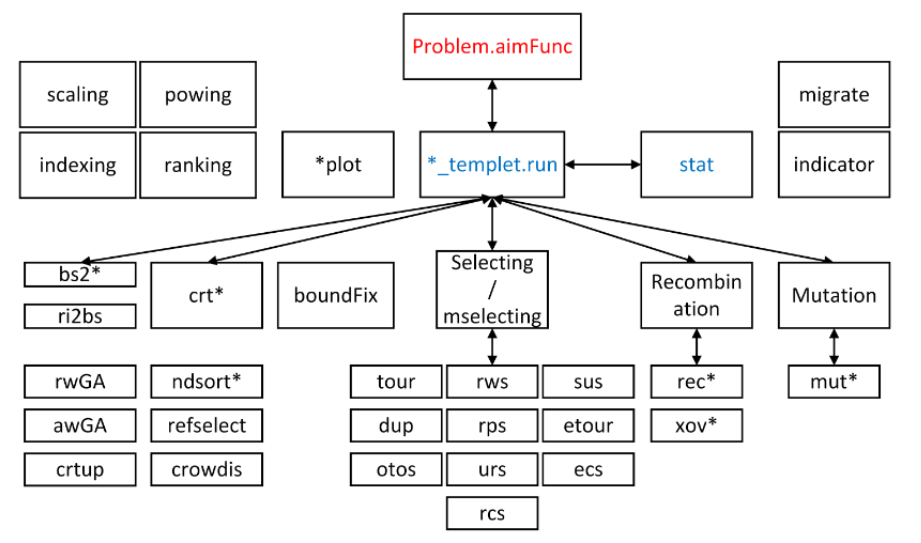
下面附一张一位同行朋友使用犀牛软件(Rhinoceros)结合geatpy工具箱进行产品优化设计的截图:
很多工程软件都提供Python接口,当需要用到进化优化时,就可以编写Python代码进行优化了。
下一篇博客将介绍如何用遗传算法求解有向图的最短路径问题:
https://blog.csdn.net/weixin_37790882/article/details/100622338
后续我将继续学习和挖掘该工具箱的更多深入的用法。希望这篇文章在帮助自己记录学习点滴之余,也能帮助大家!
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/194546.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
