大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
手写数字识别(小白入门)
今早刚刚上了节实验课,关于逻辑回归,所以手有点刺挠就想发个博客,作为刚刚入门的小白,看到代码运行成功就有点小激动,这个实验没啥含金量,所以路过的大牛不要停留,我怕你们吐槽哈哈。
实验结果:


1.数据预处理
其实呢,原理很简单,就是使用多变量逻辑回归,将训练28*28图片的灰度值转换成一维矩阵,这就变成了求784个特征向量1个标签的逻辑回归问题。代码如下:
#数据预处理
trainData = np.loadtxt(open('digits_training.csv', 'r'), delimiter=",",skiprows=1)#装载数据
MTrain, NTrain = np.shape(trainData) #行列数
print("训练集:",MTrain,NTrain)
xTrain = trainData[:,1:NTrain]
xTrain_col_avg = np.mean(xTrain, axis=0) #对各列求均值
xTrain =(xTrain- xTrain_col_avg)/255 #归一化
yTrain = trainData[:,0]2.训练模型
对于数学差的一批的我来说,学习算法真的是太太太扎心了,好在具体算法封装在了sklearn库中。简单两行代码即可完成。具体参数的含义随随便便一搜到处都是,我就不班门弄斧了,每次看见算法除了头晕啥感觉没有。
model = LogisticRegression(solver='lbfgs', multi_class='multinomial', max_iter=500)
model.fit(xTrain, yTrain)
3.测试模型,保存
接下来测试一下模型,准确率能达到百分之90,也不算太高,训练数据集本来也不是很多。
为了方便,所以把模型保存下来,不至于运行一次就得训练一次。
#测试模型
testData = np.loadtxt(open('digits_testing.csv', 'r'), delimiter=",",skiprows=1)
MTest,NTest = np.shape(testData)
print("测试集:",MTest,NTest)
xTest = testData[:,1:NTest]
xTest = (xTest-xTrain_col_avg) /255 # 使用训练数据的列均值进行处理
yTest = testData[:,0]
yPredict = model.predict(xTest)
errors = np.count_nonzero(yTest - yPredict) #返回非零项个数
print("预测完毕。错误:", errors, "条")
print("测试数据正确率:", (MTest - errors) / MTest)
'''================================='''
#保存模型
# 创建文件目录
dirs = 'testModel'
if not os.path.exists(dirs):
os.makedirs(dirs)
joblib.dump(model, dirs+'/model.pkl')
print("模型已保存")https://download.csdn.net/download/qq_45874897/12427896[这里是训练好的模型,免费下载]
4.调用模型
既然模型训练好了,就来放几张图片调用模型试一下看看怎么样
导入要测试的图片,然后更改大小为28*28,将图片二值化减小误差。
为了让结果看起来有逼格,所以最后把图片和识别数字同实显示出来。
import cv2
import numpy as np
from sklearn.externals import joblib
map=cv2.imread(r"C:\Users\lenovo\Desktop\[DX6@[C$%@2RS0R2KPE[W@V.png")
GrayImage = cv2.cvtColor(map, cv2.COLOR_BGR2GRAY)
ret,thresh2=cv2.threshold(GrayImage,127,255,cv2.THRESH_BINARY_INV)
Image=cv2.resize(thresh2,(28,28))
img_array = np.asarray(Image)
z=img_array.reshape(1,-1)
'''================================================'''
model = joblib.load('testModel'+'/model.pkl')
yPredict = model.predict(z)
print(yPredict)
y=str(yPredict)
cv2.putText(map,y, (10,20), cv2.FONT_HERSHEY_SIMPLEX,0.7,(0,0,255), 2, cv2.LINE_AA)
cv2.imshow("map",map)
cv2.waitKey(0)
5.完整代码
test1.py
import numpy as np
from sklearn.linear_model import LogisticRegression
import os
from sklearn.externals import joblib
#数据预处理
trainData = np.loadtxt(open('digits_training.csv', 'r'), delimiter=",",skiprows=1)#装载数据
MTrain, NTrain = np.shape(trainData) #行列数
print("训练集:",MTrain,NTrain)
xTrain = trainData[:,1:NTrain]
xTrain_col_avg = np.mean(xTrain, axis=0) #对各列求均值
xTrain =(xTrain- xTrain_col_avg)/255 #归一化
yTrain = trainData[:,0]
'''================================='''
#训练模型
model = LogisticRegression(solver='lbfgs', multi_class='multinomial', max_iter=500)
model.fit(xTrain, yTrain)
print("训练完毕")
'''================================='''
#测试模型
testData = np.loadtxt(open('digits_testing.csv', 'r'), delimiter=",",skiprows=1)
MTest,NTest = np.shape(testData)
print("测试集:",MTest,NTest)
xTest = testData[:,1:NTest]
xTest = (xTest-xTrain_col_avg) /255 # 使用训练数据的列均值进行处理
yTest = testData[:,0]
yPredict = model.predict(xTest)
errors = np.count_nonzero(yTest - yPredict) #返回非零项个数
print("预测完毕。错误:", errors, "条")
print("测试数据正确率:", (MTest - errors) / MTest)
'''================================='''
#保存模型
# 创建文件目录
dirs = 'testModel'
if not os.path.exists(dirs):
os.makedirs(dirs)
joblib.dump(model, dirs+'/model.pkl')
print("模型已保存")
运行结果
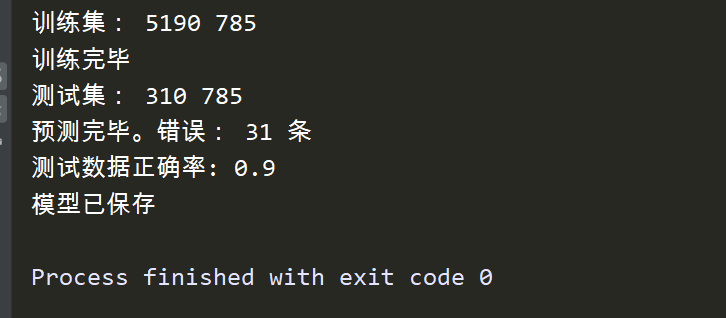
test2.py
import cv2
import numpy as np
from sklearn.externals import joblib
map=cv2.imread(r"C:\Users\lenovo\Desktop\[DX6@[C$%@2RS0R2KPE[W@V.png")
GrayImage = cv2.cvtColor(map, cv2.COLOR_BGR2GRAY)
ret,thresh2=cv2.threshold(GrayImage,127,255,cv2.THRESH_BINARY_INV)
Image=cv2.resize(thresh2,(28,28))
img_array = np.asarray(Image)
z=img_array.reshape(1,-1)
'''================================================'''
model = joblib.load('testModel'+'/model.pkl')
yPredict = model.predict(z)
print(yPredict)
y=str(yPredict)
cv2.putText(map,y, (10,20), cv2.FONT_HERSHEY_SIMPLEX,0.7,(0,0,255), 2, cv2.LINE_AA)
cv2.imshow("map",map)
cv2.waitKey(0)
提供几张样本用来测试:

实验中还有很多地方需要优化,比如数据集太少,泛化能力太差,用样本的数据测试正确率挺高,但是用我自己手写的字正确率就太低了,可能我字写的太丑,哎,还是自己太菜了,以后得多学学算法了。
训练好的模型放在了上面。最后我也把数据集放到这儿。链接:https://pan.baidu.com/s/1PfQ5Jp3A8eN4SxFnA12-1Q
提取码:tpy6
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/193983.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
