大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
疲惫的生活里总要有些温柔梦想吧


目标URL:http://www.win4000.com/meinvtag4_1.html
爬取美桌网某个标签下的美女壁纸,点进详情页可以发现,里面是一组套图
一、网页分析
翻页查看 URL 变化规律:
http://www.win4000.com/meinvtag4_1.html
http://www.win4000.com/meinvtag4_2.html
http://www.win4000.com/meinvtag4_3.html
http://www.win4000.com/meinvtag4_4.html
http://www.win4000.com/meinvtag4_5.html
页面里看到的每张图片点击进去有详情页,里面是套图
详情页里套图URL变化规律:
http://www.win4000.com/meinv216987_1.html
http://www.win4000.com/meinv216987_2.html
http://www.win4000.com/meinv216987_3.html
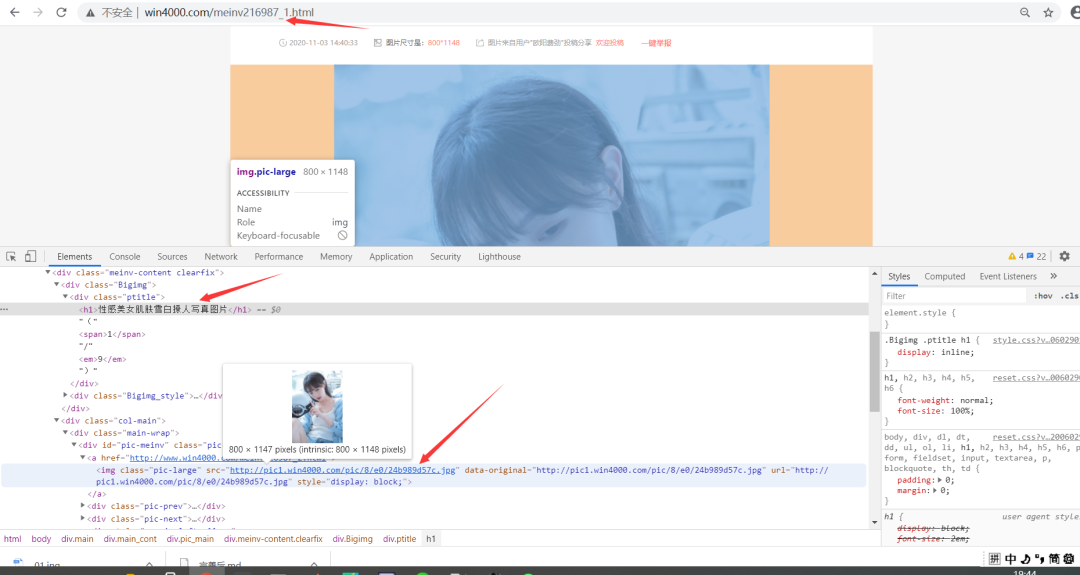
在网页源代码中也可以直接找到数据:

图片名称 下载链接
性感美女肌肤雪白撩人写真图片
http://pic1.win4000.com/pic/8/e0/24b989d57c.jpg
二、爬虫基本思路
1. 获取5页的套图的URL
def get_taotu_url():
for i in range(1, 6):
url = f'http://www.win4000.com/meinvtag4_{i}.html'
headers = {
'User-Agent': choice(user_agent)
}
# 发送请求 获取响应
rep = requests.get(url, headers=headers)
# print(rep.status_code) 状态码 200
# print(rep.text)
html = etree.HTML(rep.text)
taotu_url = html.xpath('//div[@class="tab_tj"]/div/div/ul/li/a/@href')
# 过滤掉无效的url
taotu_url = [item for item in taotu_url if len(item) == 39]
# 一个页面有24个图片
print(taotu_url, len(taotu_url), sep='\n')
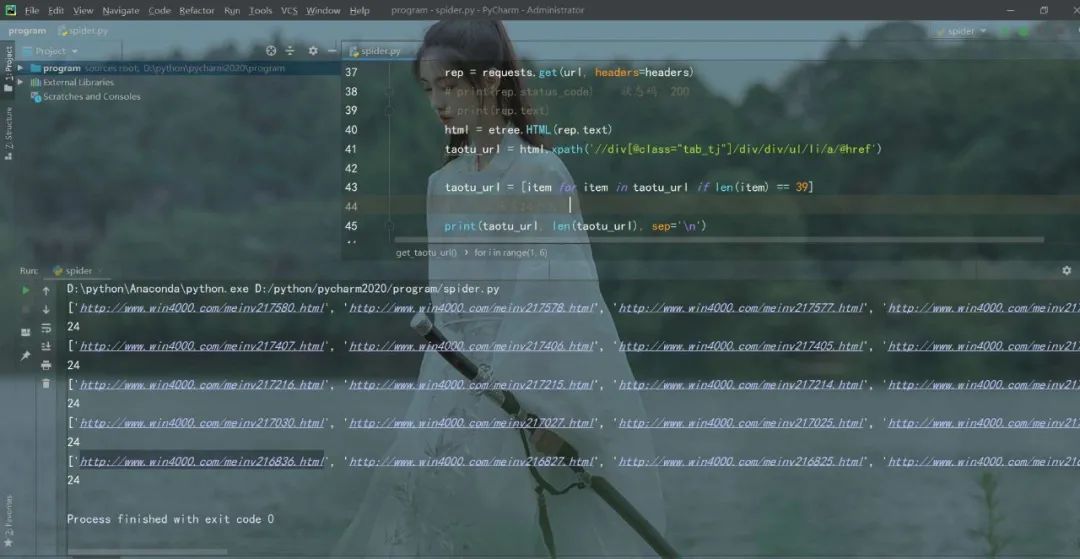
2. 进入套图详情页爬取图片
def get_img(url):
headers = {
'User-Agent': choice(user_agent)
}
# 发送请求 获取响应
rep = requests.get(url, headers=headers)
# 解析响应
html = etree.HTML(rep.text)
# 获取套图名称 最大页数
name = html.xpath('//div[@class="ptitle"]/h1/text()')[0]
os.mkdir(r'./女神套图/{}'.format(name))
max_page = html.xpath('//div[@class="ptitle"]/em/text()')
# 字符串替换 便于之后构造url请求
url1 = url.replace('.html', '_{}.html')
for i in range(1, int(max_page[0]) + 1):
url2 = url1.format(i)
sleep(randint(1, 3))
reps = requests.get(url2, headers=headers)
dom = etree.HTML(reps.text)
src = dom.xpath('//div[@class="main-wrap"]/div[1]/a/img/@data-original')[0]
file_name = name + f'第{i}张.jpg'
img = requests.get(src, headers=headers).content
with open(r'./女神套图/{}/{}'.format(name, file_name), 'wb') as f:
f.write(img)
print(f'成功下载图片:{file_name}')
3. 完整代码实现
# -*- coding: utf-8 -*-
"""
Created on Sat Nov 7 19:15:04 2020
微信公众号: 凹凸数据
@File :spider.py
@Author :叶庭云
@CSDN :https://yetingyun.blog.csdn.net/
"""
import requests
from random import choice, randint
from lxml import etree
import os
from concurrent.futures import ThreadPoolExecutor
from time import sleep
# 自己构造请求头池 用于切换
user_agent = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
# 不存在文件夹 就创建
if not os.path.exists('女神套图'):
os.mkdir('女神套图')
# 获取5页的套图的URL
def get_taotu_url():
taotu_urls = []
for i in range(1, 6):
url = f'http://www.win4000.com/meinvtag4_{i}.html'
headers = {
'User-Agent': choice(user_agent)
}
# 发送请求 获取响应
rep = requests.get(url, headers=headers)
# print(rep.status_code) 状态码 200
# print(rep.text)
html = etree.HTML(rep.text)
taotu_url = html.xpath('//div[@class="tab_tj"]/div/div/ul/li/a/@href')
# 过滤掉无效的url
taotu_url = [item for item in taotu_url if len(item) == 39]
# 一个页面有24个图片
# print(taotu_url, len(taotu_url), sep='\n')
taotu_urls.extend(taotu_url)
return taotu_urls
# 进入套图详情页爬取图片
def get_img(url):
headers = {
'User-Agent': choice(user_agent)
}
# 发送请求 获取响应
rep = requests.get(url, headers=headers)
# 解析响应
html = etree.HTML(rep.text)
# 获取套图名称 最大页数
name = html.xpath('//div[@class="ptitle"]/h1/text()')[0]
os.mkdir(r'./女神套图/{}'.format(name))
max_page = html.xpath('//div[@class="ptitle"]/em/text()')
# 字符串替换 便于之后构造url请求
url1 = url.replace('.html', '_{}.html')
# 翻页爬取这组套图的图片
for i in range(1, int(max_page[0]) + 1):
# 构造url
url2 = url1.format(i)
# 休眠
sleep(randint(1, 3))
# 发送请求 获取响应
reps = requests.get(url2, headers=headers)
# 解析响应
dom = etree.HTML(reps.text)
# 定位提取图片下载链接
src = dom.xpath('//div[@class="main-wrap"]/div[1]/a/img/@data-original')[0]
# 构造图片保存的名称
file_name = name + f'第{i}张.jpg'
# 请求下载图片 保存图片 输出提示信息
img = requests.get(src, headers=headers).content
with open(r'./女神套图/{}/{}'.format(name, file_name), 'wb') as f:
f.write(img)
print(f'成功下载图片:{file_name}')
# 主函数调用 开多线程
def main():
taotu_urls = get_taotu_url()
with ThreadPoolExecutor(max_workers=4) as exector:
exector.map(get_img, taotu_urls)
print('=================== 图片全部下载成功啦!=====================')
if __name__ == '__main__':
main()运行效果如下:
程序运行一会,图片就全部爬取下来保存在本地文件夹,5页的120组套图,美滋滋。
四、其他说明
-
不建议抓取太多数据,容易对服务器造成负载,浅尝辄止即可。
-
通过本文爬虫,可以帮助你了解套图的爬取,如何通过字符串的拼接来构造URL请求。
-
本文利用 Python 爬虫实现批量下载女神套图,实现过程中也会遇到一些问题,多思考和调试,最终解决问题,也能理解得更深刻。
推荐阅读:
入门: 最全的零基础学Python的问题 | 零基础学了8个月的Python | 实战项目 |学Python就是这条捷径
干货:爬取豆瓣短评,电影《后来的我们》 | 38年NBA最佳球员分析 | 从万众期待到口碑扑街!唐探3令人失望 | 笑看新倚天屠龙记 | 灯谜答题王 |用Python做个海量小姐姐素描图 |
趣味:弹球游戏 | 九宫格 | 漂亮的花 | 两百行Python《天天酷跑》游戏!
AI: 会做诗的机器人 | 给图片上色 | 预测收入 | 碟中谍这么火,我用机器学习做个迷你推荐系统电影
年度爆款文案
点阅读原文,领廖雪峰视频资料!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/193874.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
