大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
R中的统计分析通过使用许多内置函数来执行的,这些函数大部分是R基础包的一部分,并且它们将R向量与参数一起作为输入,并在执行计算后给出结果。
先来看如何求平均值。
平均值是通过取数值的总和并除以数据序列中的值的数量来计算,函数mean()用于在R中计算平均值,语法如下:
mean(x, trim = 0, na.rm = FALSE, ...)参数描述如下:
- x – 是输入向量。
- trim – 用于从排序的向量的两端删除一些观测值。
- na.rm – 用于从输入向量中删除缺少的值。
当我们提供trim参数时,向量中的值进行排序,然后从计算平均值中删除所需数量的观察值,例如,当trim = 0.3时,每一端的3个值将从计算中删除以找到均值。在这种情况下,排序的向量为(-21,-5,2,3,42,7,8,12,18,54),从用于计算平均值的向量中从左边删除:(-21,-5,2)和从右边删除:(12,18,54)这几个值。
如果缺少值,则平均函数返回NA,我们如果要从计算中删除缺少的值,可以使用na.rm = TRUE, 这意味着删除NA值。
好啦,来综合看下实例:

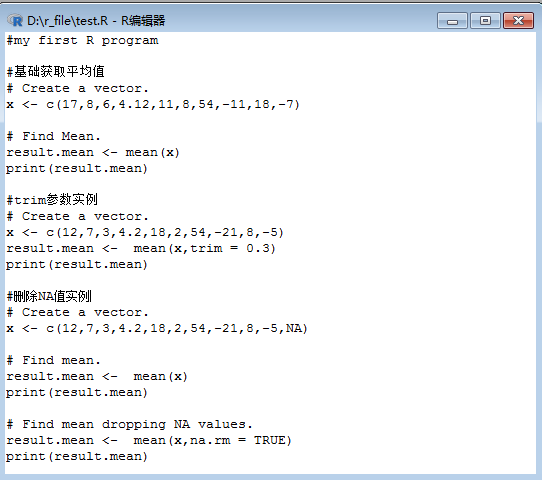
输出结果为:
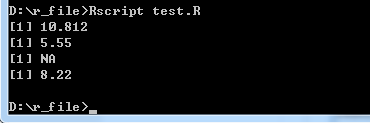
数据系列中的中间值被称为中位数,在R中使用median()函数来计算中位数,语法如下:
median(x, na.rm = FALSE)参数描述如下:
- x – 是输入向量。
- na.rm – 用于从输入向量中删除缺少的值。
众数是指给定的一组数据集合中出现次数最多的值,不同于平均值和中位数,众数可以同时具有数字和字符数据。R没有标准的内置函数来计算众数,因此,我们将创建一个用户自定义函数来计算R中的数据集的众数。该函数将向量作为输入,并将众数值作为输出,来分别看下实例:
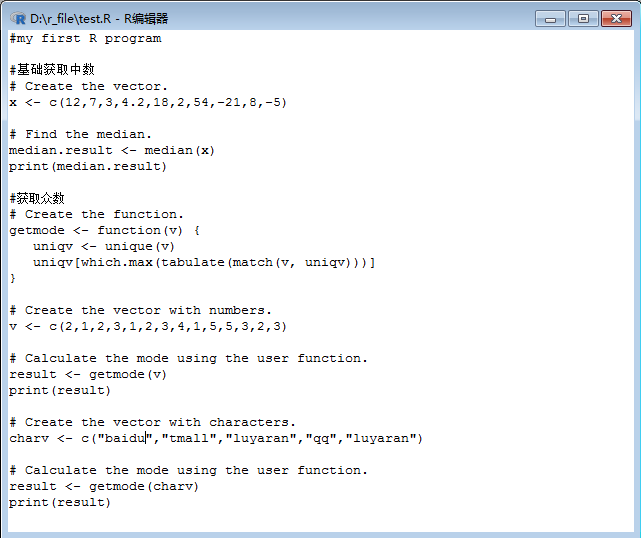
输出结果为:
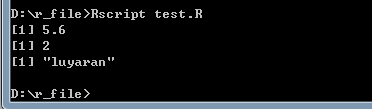
好啦,本次记录就到这里了。
如果感觉不错的话,请多多点赞支持哦。。。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/193626.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
