一、缓存雪崩:
1、什么是缓存雪崩:
如果缓在某一个时刻出现大规模的key失效,那么就会导致大量的请求打在了数据库上面,导致数据库压力巨大,如果在高并发的情况下,可能瞬间就会导致数据库宕机。这时候如果运维马上又重启数据库,马上又会有新的流量把数据库打死。这就是缓存雪崩。
2、问题分析:
造成缓存雪崩的关键在于同一时间的大规模的key失效,为什么会出现这个问题,主要有两种可能:第一种是Redis宕机,第二种可能就是采用了相同的过期时间。搞清楚原因之后,那么有什么解决方案呢?
3、解决方案:
(1)事前:
① 均匀过期:设置不同的过期时间,让缓存失效的时间尽量均匀,避免相同的过期时间导致缓存雪崩,造成大量数据库的访问。
② 分级缓存:第一级缓存失效的基础上,访问二级缓存,每一级缓存的失效时间都不同。
③ 热点数据缓存永远不过期。
永不过期实际包含两层意思:
物理不过期,针对热点key不设置过期时间
逻辑过期,把过期时间存在key对应的value里,如果发现要过期了,通过一个后台的异步线程进行缓存的构建
④ 保证Redis缓存的高可用,防止Redis宕机导致缓存雪崩的问题。可以使用 主从+ 哨兵,Redis集群来避免 Redis 全盘崩溃的情况。
(2)事中:
① 互斥锁:在缓存失效后,通过互斥锁或者队列来控制读数据写缓存的线程数量,比如某个key只允许一个线程查询数据和写缓存,其他线程等待。这种方式会阻塞其他的线程,此时系统的吞吐量会下降
② 使用熔断机制,限流降级。当流量达到一定的阈值,直接返回“系统拥挤”之类的提示,防止过多的请求打在数据库上将数据库击垮,至少能保证一部分用户是可以正常使用,其他用户多刷新几次也能得到结果。
(3)事后:
① 开启Redis持久化机制,尽快恢复缓存数据,一旦重启,就能从磁盘上自动加载数据恢复内存中的数据。
二、缓存击穿:
1、什么是缓存击穿:
缓存击穿跟缓存雪崩有点类似,缓存雪崩是大规模的key失效,而缓存击穿是某个热点的key失效,大并发集中对其进行请求,就会造成大量请求读缓存没读到数据,从而导致高并发访问数据库,引起数据库压力剧增。这种现象就叫做缓存击穿。
2、问题分析:
关键在于某个热点的key失效了,导致大并发集中打在数据库上。所以要从两个方面解决,第一是否可以考虑热点key不设置过期时间,第二是否可以考虑降低打在数据库上的请求数量。
3、解决方案:
(1)在缓存失效后,通过互斥锁或者队列来控制读数据写缓存的线程数量,比如某个key只允许一个线程查询数据和写缓存,其他线程等待。这种方式会阻塞其他的线程,此时系统的吞吐量会下降
(2)热点数据缓存永远不过期。
永不过期实际包含两层意思:
-
物理不过期,针对热点key不设置过期时间
-
逻辑过期,把过期时间存在key对应的value里,如果发现要过期了,通过一个后台的异步线程进行缓存的构建
三、缓存穿透:
1、什么是缓存穿透:
缓存穿透是指用户请求的数据在缓存中不存在即没有命中,同时在数据库中也不存在,导致用户每次请求该数据都要去数据库中查询一遍。如果有恶意攻击者不断请求系统中不存在的数据,会导致短时间大量请求落在数据库上,造成数据库压力过大,甚至导致数据库承受不住而宕机崩溃。
2、问题分析:
缓存穿透的关键在于在Redis中查不到key值,它和缓存击穿的根本区别在于传进来的key在Redis中是不存在的。假如有黑客传进大量的不存在的key,那么大量的请求打在数据库上是很致命的问题,所以在日常开发中要对参数做好校验,一些非法的参数,不可能存在的key就直接返回错误提示。
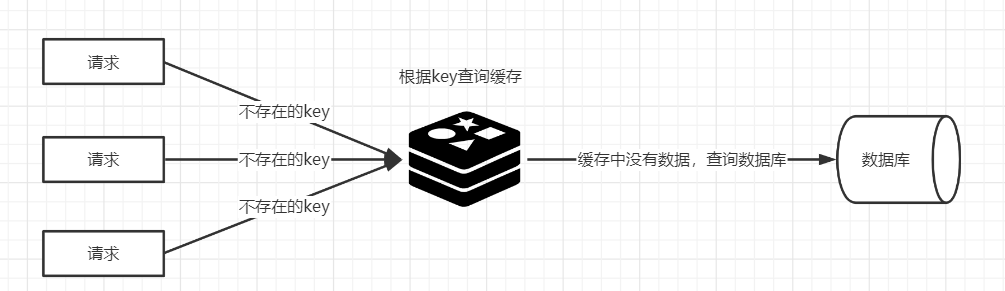

3、解决方法:
(1)将无效的key存放进Redis中:
当出现Redis查不到数据,数据库也查不到数据的情况,我们就把这个key保存到Redis中,设置value=”null”,并设置其过期时间极短,后面再出现查询这个key的请求的时候,直接返回null,就不需要再查询数据库了。但这种处理方式是有问题的,假如传进来的这个不存在的Key值每次都是随机的,那存进Redis也没有意义。
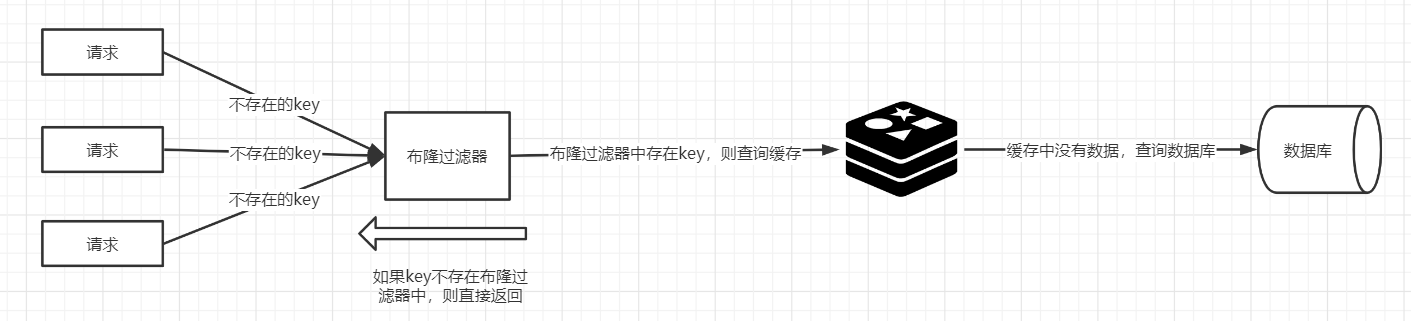
(2)使用布隆过滤器:
如果布隆过滤器判定某个 key 不存在布隆过滤器中,那么就一定不存在,如果判定某个 key 存在,那么很大可能是存在(存在一定的误判率)。于是我们可以在缓存之前再加一个布隆过滤器,将数据库中的所有key都存储在布隆过滤器中,在查询Redis前先去布隆过滤器查询 key 是否存在,如果不存在就直接返回,不让其访问数据库,从而避免了对底层存储系统的查询压力。
如何选择:针对一些恶意攻击,攻击带过来的大量key是随机,那么我们采用第一种方案就会缓存大量不存在key的数据。那么这种方案就不合适了,我们可以先对使用布隆过滤器方案进行过滤掉这些key。所以,针对这种key异常多、请求重复率比较低的数据,优先使用第二种方案直接过滤掉。而对于空数据的key有限的,重复率比较高的,则可优先采用第一种方式进行缓存。
四、缓存预热:
1、什么是缓存预热:
缓存预热是指系统上线后,提前将相关的缓存数据加载到缓存系统。避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题,用户直接查询事先被预热的缓存数据。
如果不进行预热,那么Redis初始状态数据为空,系统上线初期,对于高并发的流量,都会访问到数据库中, 对数据库造成流量的压力。
2、缓存预热解决方案:
(1)数据量不大的时候,工程启动的时候进行加载缓存动作;
(2)数据量大的时候,设置一个定时任务脚本,进行缓存的刷新;
(3)数据量太大的时候,优先保证热点数据进行提前加载到缓存。
五、缓存降级:
缓存降级是指缓存失效或缓存服务器挂掉的情况下,不去访问数据库,直接返回默认数据或访问服务的内存数据。降级一般是有损的操作,所以尽量减少降级对于业务的影响程度。
在项目实战中通常会将部分热点数据缓存到服务的内存中,这样一旦缓存出现异常,可以直接使用服务的内存数据,从而避免数据库遭受巨大压力。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/100027.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
