大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
第一篇:世界观安全
第一章:我的安全世界观
一个网站的数据库,在没有任何保护的情况下,数据库服务端口是允许任何人随意连接的;在有了防火墙的保护后,通过ACL可以控制只允许信任来源的访问。这些措施在很大程度上保证了系统软件处于信任边界之内,从而杜绝了绝大部分的攻击来源。
1.1.3Web安全的兴起
常见攻击:SQL注入,XSS(跨站脚本攻击)
“破坏往往比建设容易”,但凡事都不是绝对的。一般来说,白帽子选择的方法,是克服某种攻击方法,而并非抵御单次的攻击。比如设计一个解决方案,在特定环境下能够抵御所有已知的和未知的SQL Injection问题。假设这个方案的实施周期是3个月,那么执行3个月之后,所有的SQL Injection问题都得到了解决,也就意味着黑客再也无法利用SQL Injection这一可能存在的弱点入侵网站了。如果做到了这一点,那么白帽子们就在SQL Injection的局部对抗中化被动为主动了。
跟机场安全检查进行类比。通过一个安全检查(过滤,净化)的过程,可以梳理未知的人或物,使其变得可信任。被划分出来的具有不同信任级别的区域,我们成为信任域,划分两个不同信任域之间的边界,我们称之为信任边界。
数据从高等级的信任域流向低等级的信任域,是不需要经过安全检查的;数据从低等级的信任域流向高等级的信任域,是需要经过信任边界的安全检查。
安全问题的本质是信任的问题。
一切的安全方案设计的基础,都是建立在信任关系上的。我们必须相信一些东西,必须要有一些最基本的假设,安全方案才能得以建立。
1.5安全的三要素
安全的三要素是安全的基本组成元素,分别为机密性(Confidentiality),完整性(Integrity),可用性(Availability)。
机密性要求数据内容不能泄露,加密是实现机密性要求的常见手段。如果不将文件存在抽屉里,而是放在透明的盒子里,那么虽然无法得到这个文件,但是文件的内容将会被泄露。
完整性则要求保护数据内容是完整,没有被篡改的。常见的保证一致性的技术手段是数字签名。
可用性要求保护资源是“随需而得”。
举例来说,假如有100个车位,有一天一个坏人搬了100块大石头将车位全占了,那么停车场无法再提供正常服务。在安全领域中叫做拒绝服务攻击,简称DoS(Denial of Service)。拒绝服务攻击破坏的是安全的可用性。
1.6如何实施安全评估
一个安全评估的过程,可以简单地分为4个阶段:1.资产等级划分,2.威胁分析,3.风险分析,4.确认解决方案。
1.6.1资产等级划分
资产等级划分是所有工作的基础,这项工作能够帮助我们明确目标是什么,要保护什么。
互联网安全的核心问题,就是数据安全的问题。
1.6.2威胁分析
在安全领域,我们把可能造成危害的来源成为威胁(Threat),而把可能会出现的额损失称为风险(Risk)。
威胁分析:
1.头脑风暴
2.STRIDE模型

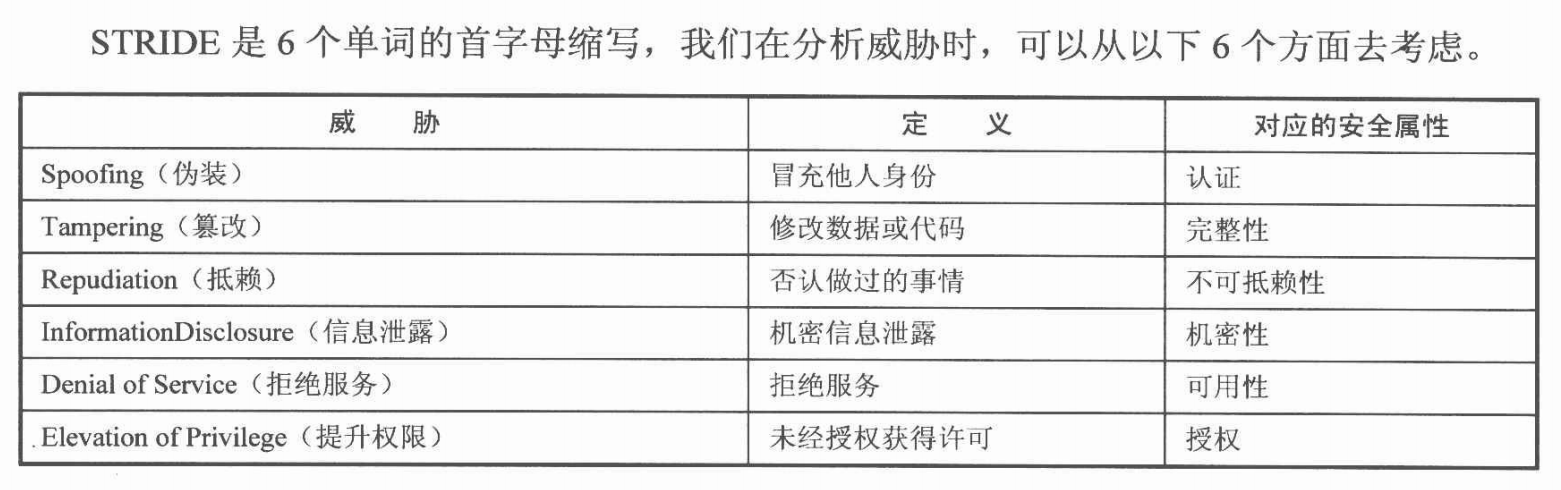
1.6.2风险分析
风险是由以下因素组成:
Risk=Probability * Damage Potential
衡量风险:
1.DREAD模型
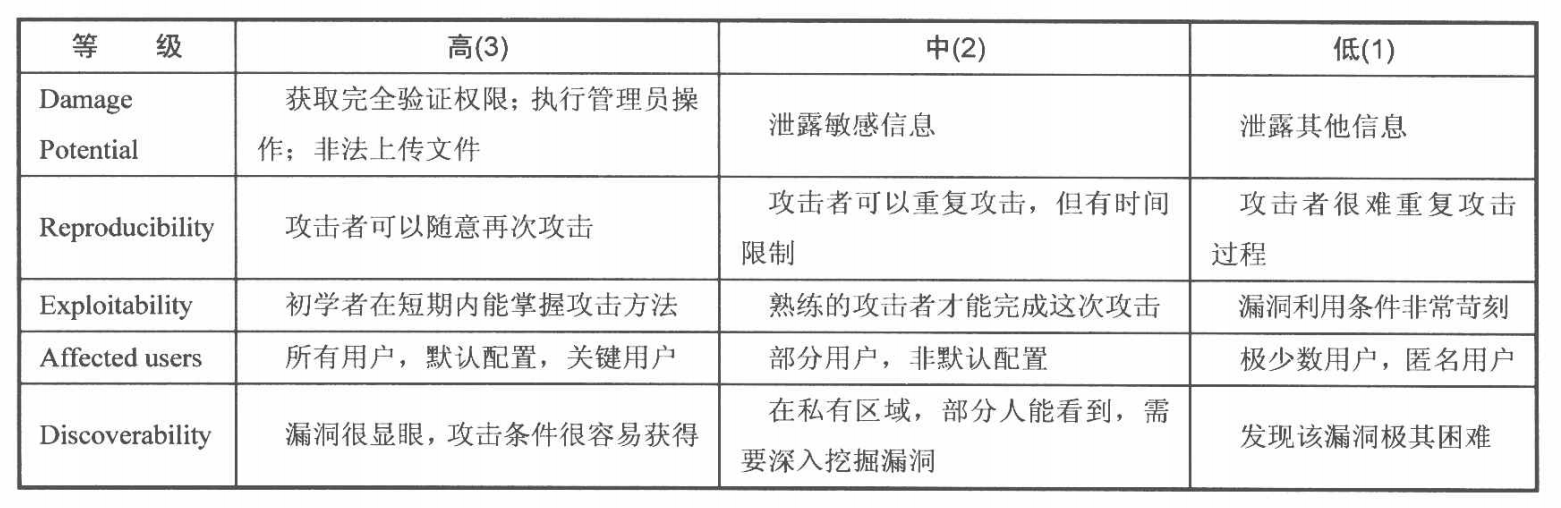
1.7白帽子兵法
1.7.1Secure By Default原则
白名单,黑名单:
实际上,Secure By Default原则,也可以归纳为白名单,黑名单的思想。如果更多地使用白名单,那么系统就会变得更安全。
最小权限原则:
最小原则要求系统只授予主体必要的权限,而不要过度授权,这样能有效地减少系统,网络,应用,数据库出错的机会。
纵深防御原则:
纵深防御原则包含两层含义:1.要在各个不同层面,不同方面实施安全方案,避免出现疏漏,不同安全方案之间需要相互配合,构成一个整体;2.要在正确的地方做正确的事情,即:在解决根本问题的地方实施针对性的安全方案。
1.7.3数据与代码分离原则
这一原则适用于各种由于“注入”而引发安全问题的场景。
实际上,缓冲区溢出,也可以认为是程序违背了这一原则的后果——程序在栈或者堆中,将用户数据当做代码执行,混淆了代码与数据的边界,从而导致安全问题的发生。
1.7.4不可预测性原则
微软使用的ASLR技术,在较新版本的Linux内核中也支持。在ASLR的控制下,一个程序每次启动时,其进程的栈基址都不相同,具有一定的随机性,对于攻击者来说,这就是“不可预测性”。
不可预测性,能有效地对抗基于篡改,伪造的攻击。
不可预测性的实现往往需要用到加密算法,随机数算法,哈希算法,好好利用这条规则,在设计安全方案时往往会事半功倍。
1.8小结
第二篇:客户端脚本安全
第二章:浏览器安全
一些主要浏览器的安全功能:
2.1同源策略
这一策略极其重要,如果没有同源策略,可能a.com的一段JS脚本,在b.com未曾加载此脚本时,也可以随意修改b.com的页面(在浏览器显示中)。为了不发生混乱,浏览器提出“Origin”(源)的概念。来自不同Origin的对象无法相互干扰。
从上表可以看出,影响”源”的因素有:
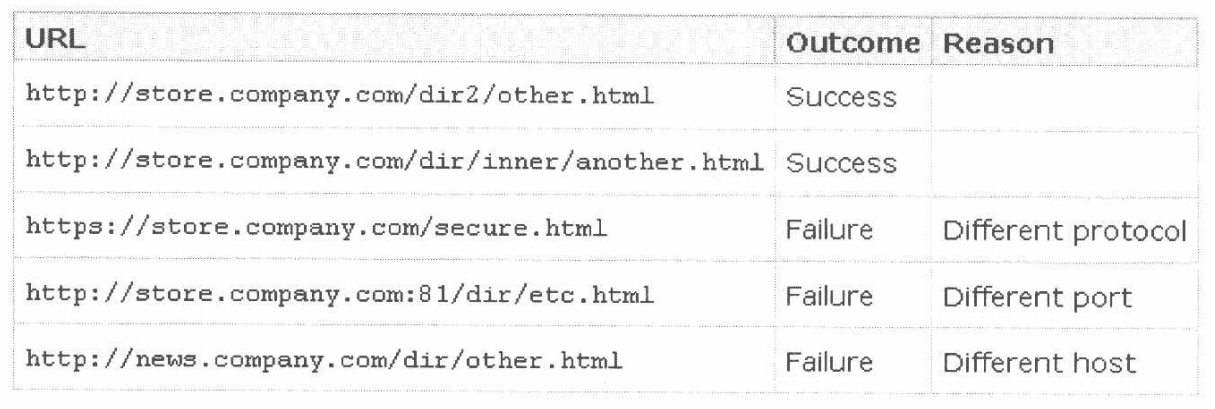
1.host(域名或IP地址)
2.子域名
3.端口
4.协议
需要注意的是,对于当前页面来说,页面内存放JS文件的域并不重要,重要的是加载JS的页面所在的域是什么。举例说明:
a.com通过代码<script src=http://b.com/b.js ></script>加载了b.com上的b.js。因为b.js是运行在a.com上的,所以b.js的域就是a.com。
在浏览器中,<script>,<img>,<iframe>,<link>等标签都可以跨域加载资源,而不受同源策略的限制。这些带”src”属性的标签每次加载时,实际上是由浏览器发起了一次GET请求。不同于XMLHttpRequest的是,通过src属性加载的资源,浏览器限制了JS的权限,使其不能读,写返回的内容。
对于XMLHttpRequest,它收到同源策略的约束,不能跨域访问资源,在AJAX应用的开发中尤其需要注意到这一点。
2.2浏览器沙箱
2.3恶意网站拦截
2.4高速发展的浏览器安全
第三章:跨站脚本攻击(XSS)
3.1XSS简介
跨站脚本攻击,英文全称为Cross Site Script,在安全领域叫做”XSS”。XSS攻击,通常指黑客通过”HTML注入”篡改了网页,插入了恶意的脚本,从而在用户浏览网页时,控制用户浏览器的一种攻击。
XSS根据效果的不同可以分为如下几类。
一:反射型XSS
反射型XSS只是简单地把用户输入的数据“反射”给浏览器。也就是说,黑客往往需要诱使用户“点击”一个恶意链接,才能攻击成功。反射型XSS也叫做“非持久型XSS”(Non-persistent XSS)。
二:存储型XSS
存储型XSS会把用户输入的数据“存储”在服务器端。这种XSS具有很强的稳定性。也叫做“持久型XSS”(Persistent XSS)。
三:DOM Based XSS
通过修改页面的DOM节点形成的XSS,称之为DOM Based XSS。
3.2XSS攻击进阶
可以利用XSS payload来窃取Cookie。但”Cookie劫持”并非所有的时候都会有效,有的网站可能会在Set-Cookie时给关键的Cookie**植入HttpOnly标识;有的网站会把Cookie与客户端IP绑定**。
3.3XSS的防御
1.四两拨千斤:HttpOnly
浏览器将禁止页面的JS访问带有HttpOnly属性的Cookie。只能防止XSS后的Cookie劫持攻击。
一个Cookie的使用过程如下:
STEP1.浏览器向服务器发起请求,这个时候没有Cookie
STEP2.服务器返回时发送Set-Cookie头,向客户端浏览器写入Cookie
STEP3.在该Cookie到期前,浏览器访问该域下的所有页面,都将发送该Cookie
在java EE中,给Cookie设置HttpOnly代码如下:
response.setHeader("Set-Cookie","cookieName=value;path=/;Domain=domainValue;Max-Age=seconds;HTTPOnly");但是HttpOnly不是万能的,添加了HttpOnly不等于解决了XSS问题。
XSS攻击带来的不光是Cookie劫持的问题,还有窃取用户信息,模拟用户身份执行操作等诸多严重的后果。如前文所述,攻击者利用AJAX构造HTTP请求,以用户身份完成的操作,就是在不知道用户Cookie的情况下进行的。
使用HttpOnly有助于缓解XSS攻击,但仍然需要其他能够解决XSS漏洞的方案。
2.输入检查
常见的Web漏洞如XSS,SQL Injection等,都要求攻击者构造一些特殊字符,这些特殊字符可能是正常用户用不到的,所以输入检查就有必要了。
格式检查,有点像一种”白名单”,也可以让一些基于特殊字符的攻击失效。
输入检查的逻辑,必须放在服务器端代码中实现。如果只是在客户端使用JS进行输入检查,是很容易被攻击者绕过的。
目前Web开发的普遍做法,是同时在客户端JS中和服务器端代码中实现相同的输入检查。客户端JS的输入检查,可以阻挡大部分误操作的正常用户,从而节约服务器资源。
比较智能的”输入检查”,会匹配XSS的特征。这种输入检查的方式,可以称为”XSS Filter”。有很多”XSS Filter”的实现。
XSS Filter在用户提交数据时获取变量,并进行XSS检查;但此时用户数据并没有结合渲染页面的HTML代码,因此XSS Filter对语境的理解并不完整。
XSS攻击主要发生在MVC架构中的View层。大部分的XSS漏洞可以在模板系统中解决。比如Python的开发框架Django自带的模板系统”Django Templates”,或者其他的”Thymeleaf Templates”。
3.正确地防御XSS
为了更好设计XSS防御方案,需要了解其本质。
XSS的本质还是一种“HTML注入”,用户的数据被当成了HTML代码一部分来执行,从而混淆了原本的语义,产生了新的语义。
如果网站使用了MVC架构,那么XSS就发生在View层——在应用拼接变量到HTML页面时产生。所以在用户提交数据处进行输入检查的方案,其实并不是在真正发生攻击的地方做防御。
3.3.7换个角度看XSS的风险
一般来说,存储型XSS的风险会高于反射型XSS。因为存储型XSS会保存在服务器上,有可能会跨页面存在。
从攻击过程来说,反射型XSS,一般要求攻击者诱使用户点击一个包含XSS代码的URL链接;而存储型XSS,则只需要让用户查看一个正常的URL链接,比如一个Web邮箱的邮件正文页面存在一个存储型的XSS漏洞,当页面打开一封新邮件时,XSS Payload会被执行。这样的漏洞极其隐蔽,且埋伏在用户的正常业务中,风险颇高。
第四章:跨站请求伪造(CSRF)
CSRF的全名是Cross Site Request Forgery,翻译成中文就是跨站点请求伪造。
4.2CSRF进阶
在上节提到的例子里,攻击者伪造的请求之所以能够被搜狐服务器验证通过,是因为用户的浏览器成功发送了Cookie的缘故。
浏览器所持有的Cookie分为两种:一种是“Session Cookie”,又称”临时Cookie”;另一种是”Third-party Cookie”,也称为“本地Cookie”。
两者的区别在于:
Third-party Cookie是服务器在Set-Cookie时指定了Expire时间,只有到了Expire时间后Cookie才会失效,所以这种Cookie会保存在本地,而Session Cookie则没有指定Expire时间,所以浏览器关闭后,Session Cookie就失效了。
在浏览网站的过程中,若是一个网站设置了Session Cookie,那么在浏览器进程的生命周期内,即使浏览器新打开了Tab页,Session Cookie也都是有效的。Session Cookie保存在浏览器进程的内存空间中,而Third-party Cookie则保存在本地。
如果浏览器从一个域的页面中,要加载另一个域的资源,由于安全的原因,某些浏览器会阻止Third-party Cookie的发送。
举例说明:
在http://www.a.com/cookie.php中,会给浏览器写入两个Cookie,一个为Session Cookie,一个为Third-party Cookie。
<?php
header("Set-Cookie:cookie1=123;");
header("Set-Cookie:cookie2=456;expires=Thu,01-Jan-2030 00:00:01 GMT;",false);
?>访问该页面,发现浏览器同时接收了这两个Cookie。
这时再打开一个新的浏览器Tab页,访问同一个域中的不同页面。因为新Tab页在同一个浏览器进程中,因此Session Cookie将被发送。
此时在另外一个域中,有一个页面http://www.b.csrf-test.html,此页面构造了CSRF以访问www.a.com。<iframe src="http://www.a.com"></iframe>,这时会发现,只能发送出Session Cookie,而Third-party Cookie被禁止了。
对于第三方Cookie的默认拦截策略,不同浏览器的策略不一样,不能一概而论。
若CSRF攻击的目标并不需要使用Cookie,那也不必顾虑浏览器的Cookie策略了。
4.3CSRF的防御
1.验证码
验证码被认为是对抗CSRF攻击最简洁而有效的防御方法。
CSRF攻击的过程,往往是在用户不知情的情况下构造了网络请求。而验证码,则强制用户必须与应用进行交互,才能完成最终请求,因此在通常情况下,验证码能够很好地遏制CSRF攻击。
出于用户体验考虑,网站不能给所有的操作都加上验证码。因此,验证码只能作为防御CSRF的一种辅助手段。
2.Referer Check
3.Anti CSRF Token
业界针对CSRF的防御,一致的做法是使用一个Token。
CSRF的本质:
CSRF为什么能够攻击成功?其本质原因是重要操作的所有参数都是可以被攻击者猜测到的。
攻击者只有预测出URL的所有参数与参数值,才能成功地构造一个伪造的请求;反之,攻击者将无法攻击成功。
出于这个原因,可以想到一个解决方案:把参数加密,或者使用一些随机数,从而让攻击者无法猜测到参数值,这是”不可预测性原则”的一种应用。
举例说明,一个删除操作的URL是:
http://host/path/delete?username=abc&item=123把其中的username参数改成哈希值:
http://host/path/delete?username=md5(salt+abc)&item=123这样在攻击者不知道salt的情况下,是无法构造出这个URL的。
但是!这个方法存在一些问题。
1.加密或混淆后的URL变得非常难读,对普通用户非常不友好;
2.如果加密的参数每次都改变,则某些URL无法被用户收藏;
3.普通的参数如果也被加密或者哈希,会给数据分析工作带来很大的困扰。
更常用的方案就是要讲的Anti CSRF Token。
会上面的URL中,新增加一个参数Token。这个Token的值是随机的,不可预测:
http://host/path/delete?username=md5(salt+abc)&item=123&token=[random(seed)]Token需要足够随机,必须使用安全的随机数生成算法,或者采用真随机数生成器(物理随机)。Token应该作为一个”秘密”,为用户与服务器所共同持有,不能被第三者知晓。在实际应用中,Token可以放在用户的Session中,或者浏览器的Cookie中。
Token需要同时放在表单和Session中。这提交请求时,服务器只需验证表单中的Token,与用户Session(或Cookie)中的Token是否一致。
在使用Token时,应该尽量把Token放在表单中。把敏感操作由GET改为POST,以form表单(或者AJAX)的形式提交,可以避免Token泄露。
4.4总结
CSRF攻击是攻击者利用用户的身份操作用户账户的一种攻击方式。
第五章:点击劫持(clickjacking)
点击劫持:
点击劫持是一种视觉上的欺骗手段。攻击者使用一个透明的,不可见的iframe,覆盖在一个网页上,然后诱使用户在该网页上进行操作,此时用户在不知情的情况下点击透明的iframe页面。恰好在功能性按钮上,进而欺骗。
第六章:HTML5安全
第三篇:服务器端应用安全
第七章:注入攻击
注入攻击的本质,是把用户输入的数据当做代码执行。这里有两个关键条件:
1.用户能够控制输入
2.原本程序要执行的代码,拼接了用户输入的数据
7.1SQL注入
在SQL注入的过程中,如果网站的Web服务器开启了错误回显,则会为攻击者提供极大的便利。
7.1.1盲注(Blind Injection)
没有错误回显的情况,实行盲注。
举例说明:
一个应用的URL如下:
http://newspaper/items.php?id=2执行的SQL语句为:
SELECT title,body FROM items WHERE ID=2如果攻击者构造如下的条件语句:
http://newspaper/items.php?id=2 and 1=2实际执行的SQL语句为:
SELECT title,body FROM items WHERE ID=2 and 1=2“and 1=2”永远是一个假命题,攻击者将看到一个空的结果或者出错页面。
为了进一步确认注入是否存在,还要构造”and 1=1”,如果能够返回,说明该参数存在SQL注入漏洞!
怎样防御SQL注入呢?
一般来说,防御SQL注入的最佳方式,就是使用预编译语句,绑定变量。也就是常用的用?代替将要填充的值。
还可以使用常用的手段来加固,比如检查数据类型,使用安全函数等。
在对抗注入攻击时,只需要牢记”数据与代码分离原则”,在”拼凑”发生的地方进行安全检查,就能避免这方面的问题。
第八章:文件上传漏洞
文件上传漏洞是指用户上传了一个可执行的脚本文件,并通过此脚本文件获得了执行服务器端命令的能力。
“文件上传”功能本身没有问题,但有问题的是文件上传后,服务器怎么处理,解释文件。如果服务器的处理逻辑做的不够安全,则会导致严重的后果。
大多数情况下,文件上传漏洞一般都是指“上传Web脚本能够被服务器解析”的问题,也就是通常说的webshell的问题。要完成这个攻击,要满足几个条件:
1.上传的文件能够被Web容器解释执行。所以文件上传后所在目录要是Web容器所覆盖到的路径。
2.用户能够从Web上访问这个文件。如果文件上传了,但用户无法通过Web访问,或者无法使得Web容器解释这个脚本,就不能称之为漏洞。
3.用户上传的文件若被安全检查,格式化,图片压缩等功能改变了内容,则可能导致攻击不成功。
Apache文件解析问题:
Apache对于文件名的解析是从后往前解析的,直到遇见一个Apache认识的文件类型为止。比如: phpShell.php.rar.rar.rar。
如果Apache不认识.rar这个文件类型,所以一直遍历后缀到.php,然后认为这时一个PHP类型的文件。如果不考虑这些因素,写出的安全检查功能可能会存在缺陷。比如.rar是一个合法的上传需求,在应用里只判断文件的后缀是否是.rar,最终用户上传的是phpShell.php.rar.rar.rar,从而导致脚本被执行。
Apache默认的定义哪些文件是能够被认识的,是在/conf/web.xml中。
<!-- ===================== Default MIME Type Mappings =================== -->
<!-- When serving static resources, Tomcat will automatically generate -->
<!-- a "Content-Type" header based on the resource's filename extension, -->
<!-- based on these mappings. Additional mappings can be added here (to -->
<!-- apply to all web applications), or in your own application's web.xml -->
<!-- deployment descriptor. -->
<!-- Note: Extensions are always matched in a case-insensitive manner. -->
//如果想添加自定义的mapping,可以在这里添加或者在自己项目中的web.xml中
<mime-mapping>
<extension>rar</extension>
<mime-type>application/x-rar-compressed</mime-type>
</mime-mapping>
<mime-mapping>
<extension>mp3</extension>
<mime-type>audio/mpeg</mime-type>
</mime-mapping>利用上传文件钓鱼:
钓鱼网站在传播时,会通过利用XSS,服务器端302跳转等功能,从正常的网站跳转到钓鱼网站。在一开始,看到的是正常的域名,但这种钓鱼,仍然会在URL中暴露真实的钓鱼网站地址,细心点的用户可能不会上当,这是一般的钓鱼做法。
而利用文件上传功能,钓鱼者可以先将包含了HTML的文件(比如一张图片)上传到目标网站,然后通过传播这个文件的URL进行钓鱼,则URL中不会出现钓鱼地址,更具有欺骗性。
8.3设计安全的文件上传功能
总结为3点:
1.文件上传的目录设置为不可执行
只要Web容器无法解析该目录下的文件,即使攻击者上传了脚本文件,服务器本省也不会收到影响。
在实际应用中,很多大型网站的上传应用,文件上传后会放到独立的存储上,做静态文件处理,一方面方便使用缓存加速,降低性能损耗;另一方面也杜绝了脚本执行的可能。
2.判断文件类型
强烈推荐白名单的方式,不再使用黑名单。此外,对于图片的处理,可以使用压缩函数或者resize函数,在处理图片的同时破坏图片中可能包含的HTML代码。
3.使用随机数改写文件名和文件路径
文件上传如果要执行代码,则需要用户能够访问到这个文件。在某些情况中,用户能上传,但不能访问。如果应用使用随机数改写文件名和文件路径,将极大地增加攻击的成本。
4.单独设置文件服务器的域名
由于浏览器同源策略的关系,一系列客户端攻击将失效,比如上传crossdomain.xml,上传包含JS的XSS利用等问题将得到解决。但能否如此设置,还需要看具体的业务环境。
第九章:认证与会话管理
“认证”是最容易理解的一种安全。最常见的认证方式就是用户名和密码,但认证的手段远远不止于此。
9.1Who am I?
认证的目的是为了认出用户是谁,而授权的目的是为了决定用户能够做什么。
钥匙在认证的过程中,被称为“凭证”(Credential),开门的过程,对应的是登录(Login)。
可是开门之后,什么事情能做,什么事情不能做,就是“授权”的管理范围了。
开门之后,“能否进入卧室”这个权限被授予的前提,是需要识别出来的人到底是主人还是客人,所以如何授权是取决于认证的。
持有主人钥匙的人一定是主人吗?钥匙仅仅是一个很脆弱的凭证,其他的有诸如指纹,人脸,声音等生物特征来识别一个人的凭证。
认证实际上就是一个验证凭证的过程。
9.2密码那些事儿
密码的保存:
密码必须以不可逆的加密算法,或者是单向散列函数算法,加密后存储在数据库中。这样做是为了尽最大可能保证密码的私密性。即使是网站的管理人员,也不能够看到用户的密码。这种情况下,即使黑客入侵了网站,导出了数据库中的数据,也无法获取到密码的明文。
因为MD5是不可逆加密算法,一般采用彩虹表进行激活成功教程。彩虹表的思路是收集尽可能多的密码明文和明文对应的MD5值。这样只需要查询MD5值,就能找到该MD5值对应的明文。
为了避免密码哈希值泄露后,黑客能够直接通过彩虹表查询出密码明文,在计算密码明文的哈希值时,增加一个“Salt”。“Salt”是一个字符串,它的作用是增加明文的复杂度,并使得彩虹表一类的攻击失效。
Salt的使用如下:
MD5(Username+Password+Salt)其中,Salt=acjjfdk…(随机字符串)
Salt应该保存在服务器端的配置文件中,并妥善保管。
9.3多因素认证
9.4Session与认证
密码与证书等认证手段,一般仅仅用于登录(Login)的过程。当登录完成后,用户访问网站的页面,不可能每次浏览器请求时都再使用密码认证一次。因此,当认证成功后,就需要替换一个对用户透明的凭证,这就是SessionID。
当用户登录完成后,在服务器端就会创建一个新的会话(Session),会话会保存用户的状态和相关信息。服务器端维护所有用户的Session,此时的认证,只需要知道是哪个用户在浏览当前的页面即可。
为了告诉服务器应该使用哪一个Session,浏览器需要把当前用户持有的SessionID告知服务器。
最常见的做法就是把SessionID加密后保存在Cookie中,因为Cookie会随着HTTP请求头发送,且受到浏览器同源策略的保护。
SessionID一旦在生命周期内被窃取,等同于账户失窃。同时由于SessionID是用户登录之后才持有的认证凭证,因此黑客不需要再攻击登录过程,在设计安全方案时需要意识到这一点。
SessionID劫持就是一种通过窃取用户SessionID后,使用该SessionID登录进目标账户的攻击方法,此时攻击者实际上是使用了目标账户的有效Session。如果SessionID是保存在Cookie中的,则这种攻击可以成为Cookie劫持。
SessionID除了可以保存在Cookie中外,还可以保存在URL中,作为请求的一个参数。但这种方式的安全性难以经受考验。
9.5Session Fixation攻击
什么是Session Fixation呢?举个例子,如果A将汽车买个了B,但是A并没有把所有的车钥匙都交给B,自己私藏了一把。这时候如果B没有给车换锁的话,A仍然可能用私藏的钥匙使用汽车。
这个没有换“锁”而导致的安全问题,就是Session Fixation问题。对比到网站当中,如果登录前后用户的SessionID没有发生改变,则会存在Session Fixation问题。
具体攻击的过程是,用户X(攻击者)先获取到一个未经认证的SessionID,然后将这个SessionID交给用户Y去认证,Y完成认证后,服务器并未更新此SessionID的值(注意是未改变SessionID,而不是未改变Session,未改变SessionID是最大的错误啊),所以X可以直接凭借此SessionID登录进Y的账户。
X如果才能让Y使用这个SessionID呢?如果SessionID保存在Cookie中,比较难做到这一点。但若SessionID保存在URL中,则X只需要诱使Y打开这个URL即可。
解决Session Fixation的正确做法当然是,登录完成后,重写SessionID。
值得庆幸的是,在今天使用Cookie才是互联网的主流,sid的方式逐渐被淘汰。而由于网站想保存到Cookie中的东西越来越多,因此用户登录后,网站将一些数据保存到关键的Cookie中,已经成为一种普遍的做法。
9.6Session保持攻击
一般来说,Session是由生命周期的,当用户长时间未活动后,或者用户点击退出后,服务器将销毁Session。
一般的应用都会给Session设置一个失效时间,当到达失效时间后,Session将会被销毁。
但有一些系统,处于用户体验的考虑,只要这个用户还”活着“,就不会让这个用户的Session失效。从而攻击者可以通过不停地发起访问请求,让Session一直“活”下去。
在Web开发中,网站访问量如果比较大,维护Session可能会给网站带来巨大的负担。因此,有一种做法,就是服务器端不维护Session,而把Session放在Cookie中加密保存。当浏览器访问网站时,会自动带上Cookie,服务器端只需要解密Cookie即可得到当前用户的Session了。这样的Session如何使其过期呢?很多应用都是利用Cookie的Expire标签来控制Session的失效时间,这就给了攻击者可乘之机。
Cookie的Expire时间是完全可以由客户端控制的。篡改这个时间,并使之永久有效,就有可能获得一个永久有效的Session,而服务器端是完全无法察觉的。
9.7单点登录(SSO)
单点登录的全称是Single Sign On,简称SSO。它希望用户只需要登录一次,就可以访问所有的系统。
第十章:访问控制
10.1What Can I Do?
上一章”认证”解决了“Who am I”的问题,这一章“授权”则解决了“Who can I do”的问题。
权限控制,抽象地说,都是某个主体(subject)对某个客体(object)需要实施某种操作(operation),而系统对这种操作的限制就是权限控制。
在一个安全系统中,确定主体的身份是“认证”解决的问题;而客体是一种资源,是主体发起的请求的对象。在主体对客体进行操作的过程中,系统控制主体不能“无限制”地对客体进行操作,这个过程就是“访问控制”。
在Web应用中,根据访问客体的不同,常见的访问控制可以分为:
1.“基于URL的访问控制”,
2.“基于方法的访问控制”,
3.“基于数据的访问控制”。
10.2垂直权限管理
访问控制实际上是建立用户与权限之间的对应关系。现在广泛的做法是,“基于角色的访问控制(Role-Based Access Control)”,简称RBAC。
Spring Security提供了一系列的“Filter Chain”,每个安全检查的功能都会插入在这个链条中。在与Web系统集成时,开发者只需要将所有用户请求的URL都引入到Filter Chain中即可。
10.3水平权限管理
但是“垂直权限管理”是否够用呢?不是。
比如优酷网发生的用户越权访问问题。
用户登录后,可以通过以下方式查看他人的来往邮件(只需要改变下面地址的数值id即可),查看和修改他人的专辑信息。
http://u.youku.com/my_mail/inbox_id123456漏洞分析:
用户访问了原本不属于他的数据。
用户A与用户B可能属于同一个角色RoleX,但是用户A与用户B都各自拥有一些私有数据,在正常情况下,应该只有用户自己才能访问自己的私有数据。
但是在上面的RBAC模型下,系统只会验证用户A是否属于角色RoleX,而不会判断用户A是否能访问只属于用户B的数据dataB,因此,发生了越权访问。这种问题,我们称之为“水平权限管理问题”。
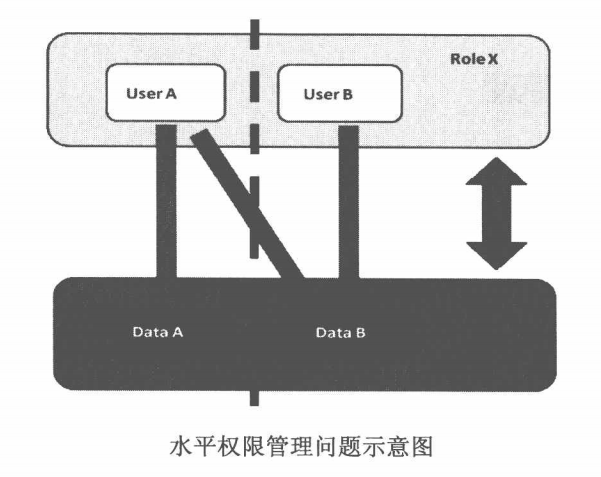
相对于垂直权限管理来说,水平权限问题出在同一个角色上。系统只验证了能访问数据的角色,既没有对角色内的用户做细分,也没有对数据的子集做细分,因此缺乏一个用户到数据之间的对应关系。由于水平权限管理是系统缺乏一个数据级的访问控制所造成的,因此水平权限管理又可以称之为”基于数据的访问控制“。
10.4OAuth简介
OAuth是一个在不提供用户名和密码的情况下,授权第三方应用访问Web资源的安全协议。
OAuth与OpenID都致力于让互联网变得更加的开放。OpenID解决的是认证问题,OAuth则更注重授权。认证和授权的关系其实是一脉相承的,后来人们发现,其实更多的时候真正需要的是对资源的授权。
第十一章:加密算法与随机数
11.6密钥管理
密码学里的基本原则:
密码系统的安全性应该依赖于密钥的复杂性,而不应该依赖于算法的保密性。
在安全领域里,选择一个足够安全的加密算法不是困难的事情,难的是密钥管理。
最常见的错误,就是将密钥硬编码在代码里。
对于Web应用来说,常见的做法是将密钥(包括密码)保存在配置文件或者数据库中。密钥所在的配置文件或数据库需要严格的控制访问权限。同时也要确保运维或DBA中具有访问权限的人越少越好。
一个比较安全的密钥管理系统,可以将所有的密钥(包括一些敏感配置文件)都集中保存在一个服务器(集群)上,并通过Web Service的方式提供获取密钥的API。每个Web应用在需要使用密钥时,通过带认证信息的API请求密钥管理系统,动态获取密钥。Web应用不能把密钥写入本地文件中,值加载到内存,这样动态获取密钥最大程度地保护了密钥的私密性。密钥集中管理,降低了系统对于密钥的耦合性,也有利于定期更换密钥。
11.7.4使用安全的随机数
在重要或者敏感的系统中,一定要使用足够强壮的随机数生成算法。在Java中,可以使用java.security.SecureRandom。
在算法上还可以通过多个随机数的组合,以增加随机数的复杂性。比如通过给随机数使用MD5算法后,再连接一个随机字符,然后再使用一个MD5算法一次。这些方法,都可以极大地增加攻击的难度。
第十二章:Web框架安全
在现代Web开发中,使用MVC架构是一种流行的做法。MVC是Model-View-Controller的缩写,它将Web应用分为三层,View成负责用户视图、页面展示等工作;Controller负责应用的逻辑实现,接受View层传入的用户请求,并转发给对应的Model做处理;Model层则负责实现模型,完成数据的处理。
从数据的流入来看,用户提交的数据先后流经了View层,Controller层,Model层,数据的流出则反过来。
第十三章:应用层拒绝服务攻击
13.1网络层DDOS
在正常情况下,TCP**三次握手过程**如下:
1.客户端向服务器端发送一个SYN包,包含客户端使用的端口号和初始序列号x;
2.服务器端收到客户端发送来的SYN包后,向客户端发送一个SYN和ACK都置位的TCP报文,包含确认号x+1和服务器端的初始序列号y;
3.客户端收到服务器端返回的SYN+ACK报文后,向服务器端返回一个确认号为y+1,序号为x+1的ACK报文,一个标准的TCP连接完成。
而SYN flood在攻击时,首先伪造大量的源IP地址,分别向服务器端发送大量的SYN包,此时服务器端会返回SYN/ACK包,因为源地址是伪造的,所以伪造的IP并不会回答,服务器端没有收到伪造IP的回应,会重试3到5次并且等待一个SYN Time(一般为30秒到2分钟),如果超时则丢弃这个连接。攻击者大量使用这种伪造源地址的SYN请求,服务器端将会消耗非常多的资源(CPU和内存)来处理这种半连接,同时还要不断对这些IP进行SYN+ACK重试。最后的结果是服务器无暇理睬正常的连接请求,导致拒绝服务。
对抗SYN flood的一种方法:SYN Cookie。
SYN Cookie的主要思想是为每一个IP地址分配一个“Cookie”,并统计每个IP地址的访问频率。如果在短时间内收到大量的来自同一个IP地址的数据包,则认为受到攻击,之后来自这个IP地址的包将被丢弃。
13.2应用层DDOS
应用层DDOS,不同于网络层DDOS,由于发生在应用层,因此TCP三次握手已经完成,连接已经建立,所以发起的攻击IP都是真实的。但应用层DDOS有时甚至比网络层DDOS攻击更为可怕。
说明应用层DDOS是怎么回事,需要先说”CC攻击”。
13.2.1CC攻击
CC攻击的原理非常简单,就是对一些消耗资源比较大的应用不断发起正常的请求,以达到消耗服务器资源的目的。在Web应用中,查询数据库,读/写硬盘文件等操作,相对都会消耗比较多的资源。比如下面的这段PHP代码:
$sql = "select * from post where tagid='$tagid' order by postid desc limit $start,30";当post表数据庞大,翻页频繁,$start数字急剧增加时,查询结果集=$start+30。该查询效率呈现明显下降趋势,而多并发频繁调用,因查询无法立即完成,资源无法立即释放,会导致数据库请求连接过多,数据库阻塞,网站无法正常打开。
应用层DDOS攻击说白了,是针对服务器性能的一种攻击,那么许多优化服务器性能的方法,都或多或少地能缓解这种攻击。比如将使用频率高的数据放在memcache中,相对于查询数据库所消耗的资源来说,查询memcache所消耗的资源可以忽略不计。
13.2.2限制请求频率
最常见的针对应用层DDOS攻击的防御手段,是在应用中针对每个“客户端”做一个请求频率的限制。
但道高一尺,魔高一丈。基于IP地址和Cookie的防御机制可能会随着IP的改变而失效。比如使用“代理服务器”,联想到了之前写爬虫是用的同样的IP轮换策略。
13.5资源耗尽攻击
几种攻击策略:
1.以极低的速度往服务器发送HTTP请求。由于Web Server对于并发的连接数都有一定的上限,因此若是恶意地占用住这些连接不释放,那么Web Server的所有连接都被恶意连接占用,从而无法接受新的请求,导致拒绝服务。要保持住这个连接,要构造一个畸形的HTTP请求,准确地说,是不完整的HTTP请求,让服务器以为后面还有数据没有传输完成,从而一直保持住连接。
从这里,可以看出所有拒绝服务供给的本质,实际上是对有限资源的无限制滥用。
比如,上面的“有限”的资源是Web Server的连接数。这是一个有上限的值,比如在Apache中这个值是由MaxClinets定义。如果恶意客户端可以无限制地将连接数占满,就完成了对有限资源的恶意消耗,导致拒绝服务。
所以拒绝应用层DDOS的核心思路是,限制住每个不可信任的资源使用者的配额。
等等。
第十五章:Web Server配置安全
15.1Apache安全
需要注意的是,Apache以root身份或者admin身份运行是一个非常糟糕的决定。
使用高权限身份来运行Apache的结果可能是灾难性的,它会带来两个可怕的后果:
1.当黑客入侵Web成功时,将直接获得一个高权限(比如root或admin)的shell
2.应用程序本身具备比较高权限,当出现bug时,可能会带来较高风险,比如删除本地重要文件,杀死进程等不可预知的结果。
比较好的做法是使用专用的用户身份运行Apache,这个用户身份不应该具备shell,它唯一的作用就是用来运行Web应用。
Apache还提供了一些配置参数,可以用来优化服务器的性能:
TimeOut
KeepAlive
LimitRequestBody
LimitRequestFields
LimitRequestFieldSize
LimitRequestLine
LimitXMLRequestBody
AcceptFilter
MaxRequestWokers在Apache官方文档中,对如何使用这些参数给出了指导。
15.2Nginx安全
第四篇:互联网公司安全运营
第十六章:互联网业务安全
第十七章:安全开发流程(SDL)
安全开发流程,能够帮助企业以最小的成本提高产品的安全性,它符合“Secure at the source”的战略思想。实施好安全开发流程,对企业安全的发展来说,可以起到事半功倍的效果。
第十八章:安全运营
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/193601.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
