大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
今天在和同时讨论HashMap的时候,提到了扩容和冲哈希的事情,然后我发现大家都是一种半懂不懂的状态。于是回去做了一番功课,写下这篇文章。
HashMap的扩容,又被很多人叫rehash、重哈希,我本人是很反对这个叫法的,事实上HashMap扩容的时候,Node中存储的Key的hash值并没有发生变化,只是Node的位置发生了变化。
首先说为什么需要扩容?这个问题好像有点简单,不就是因为容量满了就需要库容了吗?这种思想对于链表来说是没有问题的,但是对于HashMap来说,并不是因为这个原因,而是HashMap认为性能不够好时。
原因我简单说下,当然关于哈希表我就不再过多说了,还不懂的同学赶紧百度。
为什么扩容?
我们知道理论上哈希表的读时间复杂度是O(1),但是没有一种哈希方法能保证绝对的哈希均匀,为了解决哈希冲突又往往采用链地址法解决,那这样时间复杂度愈发偏离O(1)了,此时进行扩容,其实是让哈希表分散的更均匀,解决性能不够好的问题。
关于JDK1.8中的HashMap结构,在这里我就不多说了,哈希表+链表,长度达到一定时链表转换成红黑树(这时候是不是得有面试官出来问,长度多长才转红黑树啊?),为了让小伙伴们看的更直观,我这里偷一张图上来:
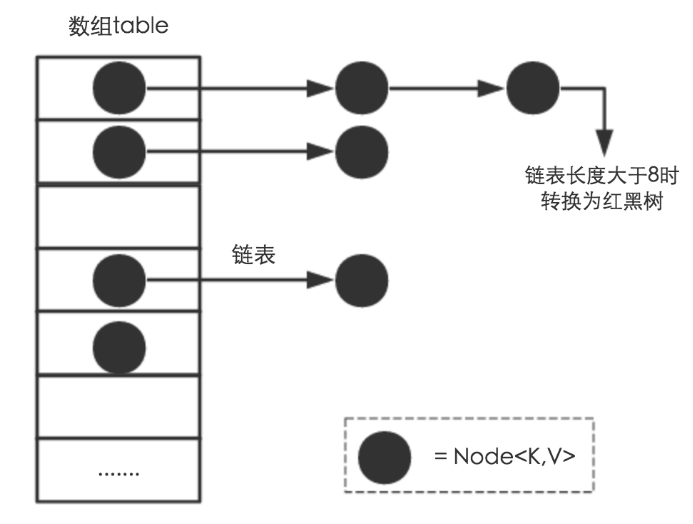

什么时候扩容?
那么什么时候需要扩容?答案也很简单:1.初始化后放入元素时 2.达到阈值时
-
创建对象以后,
HashMap并不是立即初始化table,而是在第一次放入元素时,才会初始化table,这很HashMap节省内存得一种机制,而table的初始化其实是resize方法实现的。 -
达到阈值时,这个就比较有意思,所谓阈值,就是
HashMap中threshold这个属性,阈值的计算方式很简单,基本上就是capacity(table容量) * loadFactor(负载因子),这里我觉得capacity应该称为理论容量,是因为正常情况下达到阈值就扩容了,达到阈值时HashMap认为哈希冲突的次数会不能接受,因此需要扩容。
因为这里我是以JDK1.8源码作为样本分析的,如果我没记错的话,JDK1.7中还存在rehash方法,但是JDK1.8中已经改名叫resize方法了,那我们就不管JDK1.7中是如何实现扩容,直接上JDK1.8源码。
如何扩容?
先来看扩容函数的前半部分:
final Node<K,V>[] resize() {
// 扩容前原本的table
Node<K,V>[] oldTab = table;
// 这里进行判断,区分尚未初始化的情况
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
// 非初始化情况
/* * 当原本的capacity已经超过最大值以后 * HashMap选择不再扩容,然后threshold置为最大值 */
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
/* * 这种是常见的的扩容情况,table容量会扩大两倍 * 同时HashMap的阈值也跟着扩大两倍 */
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // 2倍阈值
}
else if (oldThr > 0) // 指定大小n的初始化情况下,table容量取>n的最小2倍数
newCap = oldThr;
else {
// 不指定初始化大小,table容量取默认值16
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
// 指定大小初始化情况下,阈值 = table容量 * 负载因子(默认0.75)
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
// 最后确定阈值
threshold = newThr;
待续......
}
resize()方法的前半部分主要是对于新阈值和新容量的确定,这里有三种情况:
- 初始化已完成的正常扩容逻辑:table容量和阈值都扩大2倍
- 指定大小的初始化逻辑:算出大于等于指定初始化容量的最小2的倍数,作为table容量
- 未指定大小的初始化逻辑:默认table容量16,阈值为16 * 0.75 = 12
关于第二种逻辑,简单来说就是,指定初始化值为3,那么table容量就是4,如果指定初始化大小是10,那么table容量就是16,如果是2的次幂,就直接作为table容量。
再看resize方法的后半段:
final Node<K,V>[] resize() {
......接上文
@SuppressWarnings({
"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
// 遍历原本的table
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null; // 为了GC
if (e.next == null)
// 如果table上没有链表的情况下,直接转移到对应位置
// 转移到的位置就是get方法中取的下标位置,tab[(n - 1) & hash]
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
// 如果是红黑树,就进入红黑树的拆分逻辑,这里不展开来说
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else {
// 原本槽内的一个链表,会被拆分成两个两个链表
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
// 如果entry的哈希值高位为0,会被拆分到lo链表
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
// 如果entry的哈希值高位为1,会被拆分到hi链表
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
// 高位是0,因此lo链表不需要移位,
// hash & (newCap-1)和hash & (oldCap-1)获得下标位置一样
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
// 高位是1,hi链表移位到 j+oldCap位置,
// j + oldCap相当于高位补1,直接移到这个位置
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
这里为了能说的更通俗易懂一些,我举个简单的例子:
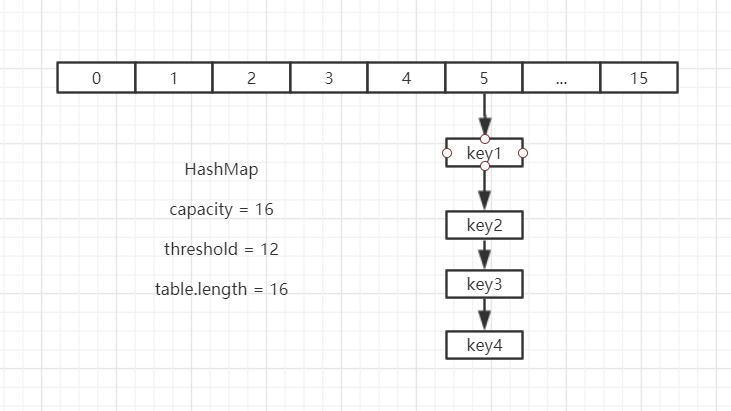
首先假设原本有几个key,他们的的hash值为:
| key | hash值 | 下标 hash & (length-1) |
|---|---|---|
| key1 | 00000101 | 00000101 = 5 |
| key2 | 00010101 | 00000101 = 5 |
| key3 | 00100101 | 00000101 = 5 |
| key4 | 00110101 | 00000101 = 5 |
而假设原本table容量 oldCap = 16;
他们在table中存储的下标位置都是:
hash & (table.length-1) = 0101 & 0111
那么这几个key都会存储在table[5]位置,如下图 :
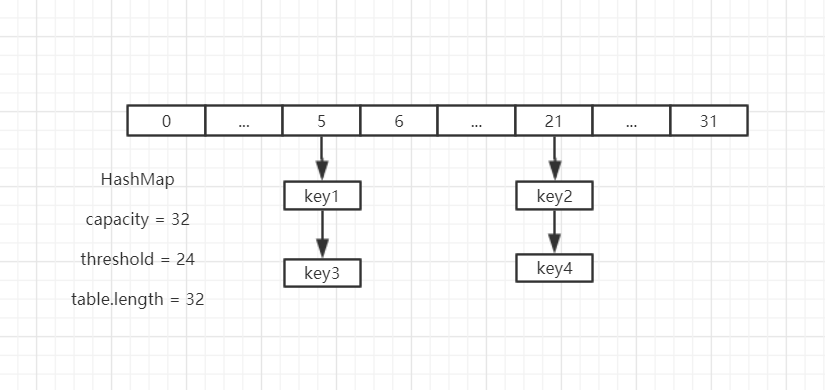
当进行扩容时,容量扩大一倍也就是newCap = 32,此时table.length -1 = 31
hash & (table.length – 1) 就会出现两种情况:
- key1 和 key3 的下标还是5 (0000 0101)
- key2 和 key4 的下标变为了 21 (0001 0101)
| key | hash值 | 下标 hash & (length-1) |
|---|---|---|
| key1 | 00000101 | 00000101 = 5 |
| key2 | 00010101 | 00001101 = 21 |
| key3 | 00100101 | 00000101 = 5 |
| key4 | 00110101 | 00001101 = 21 |
到这应该能明白,resize方法里的lo列表和hi列表是什么意思了,其实就是看key高一位的哈希值是1还是0,来决定是放到哪个队列里。 移位后的HashMap如下图:
这里HashMap非常精妙的实现了扩容,没有重新计算对象的哈希值,甚至连下标的重新计算也只需要进行一位相与的计算(hash高位 & newCap-1 )。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/193523.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
