大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
Hsql函数.上(关系/数学/逻辑/数值/日期/条件/字符串/集合统计/复杂类型)
- 原文链接:https://blog.csdn.net/scgaliguodong123_/article/details/60881166
hive常见函数
-
准备数据
zhangsa dfsadsa323 new 67.1 2 lisi 543gfd old 43.32 1 wanger 65ghf new 88.88 3 liiu fdsfagwe new 66.0 1 qibaqiu fds new 54.32 1 wangshi f332 old 77.77 2 liwei hfd old 88.44 3 wutong 543gdfsd new 56.55 6 lilisi dsfgg new 88.88 5 qishili fds new 66.66 5create external table if not exists order_detail(user_id string,device_id string,user_type string, price decimal,sales int) row format delimited fields terminated by '\t' location '/hive-data/data';
1、关系运算
1.1、String 的比较要注意(常用的时间比较可以先 to_date 之后再比较)
## > < =
##注意: String 的比较要注意(常用的时间比较可以先 to_date 之后再比较)
select long_time>short_time, long_time<short_time,long_time=short_time, to_date(long_time)=to_date(short_time)
from
(
select '2017-01-11 00:00:00' as long_time, '2017-01-11' as short_time
from
order_detail limit 1
)bb;
result:
true false false true
1.2、空值判断
select 1 from order_detail where NULL is Null limit 1;
select 1 from order_detail where 1 is not null limit 1;
1.3、like与rlike、regexp
-
LIKE
语法: A LIKE B
描述: 字符串A符合表达式B的正则语法,则为TRUE;否则为FALSE. B中字符”_”表示任意单个字符,而字符”%”表示任意数量的字符。 -
RLIKE
语法: A RLIKE B
描述: 字符串A符合JAVA正则表达式 B 的正则语法,则为 TRUE;否则为 FALSE。 -
REGEXP
语法: A REGEXP B
描述: 功能与 RLIKE 相同
2、数学运算
2.1、hive的数据类型 double,只精确到小数点后16位,在做除法运算的时候要特别注意
-
注意:
精度在 hive 中是个很大的问题,类似这样的操作最好通过round 指定精度select 8.4 % 4,round(8.4 % 4 , 2) from order_detail limit 1; --round(xxx,2),小数点后一位 -
用decimal可以表示任意精度的带符号小数;
2.2、位与& 位或| 位异或^ 位取反~(要转换成二进制运算)
select 4&6, 8&4, 4|8,6|8,4^8,6^4,~6,~3 from order_detail limit 1;
--4 0 12 14 12 2 -7 -4
--00000100(4)
--00000110(6)
--00001000(8)
--00000011(3)
2.3、逻辑与AND 逻辑或OR 逻辑非NOT
- 注意:优先级依次为NOT AND OR,分不清的时候用括号解决一切-。-
3、数值计算函数
-
取整: round
- 语法: round(double a)
说明: 遵循四舍五入
- 语法: round(double a)
-
指定精度取整: round
- 语法: round(double a, int d)
-
向下取整: floor
- 说明: 返回等于或者小于该 double 变量的最大的整数
-
向上取整: ceil
- 说明: 返回等于或者大于该 double 变量的最小的整数
-
向上取整: ceiling
- 说明: 与ceil功能相同
-
取随机数: rand
- 说明: 返回一个 0 到 1 范围内的随机数。如果指定种子 seed(整数),则会得到一个稳定的随机数序列。
-
自然指数: exp 自然对数: ln
-
以10为底对数: log10 以2为底对数: log2
-
对数: log
- 语法: log(double base, double a)
- 说明: 返回以 base 为底的 a 的对数
select log10(100),log2(8),log(4,256) from order_detail limit 1; -
幂运算: pow, power 开平方: sqrt
- pow(a,b)—>ab
-
二进制: bin 十六进制: hex 反转十六进制: unhex
-
进制转换: conv
- 语法: conv(BIGINT num, int from_base, int to_base)
- 说明: 将数值 num 从 from_base 进制转化到 to_base 进制
-
绝对值:abs 正取余:pmod 正弦:sin 反正弦:asin 余弦:cos 反余弦:acos 返回A的值:positive 返回A的相反数:negative
4、日期函数
-
UNIX时间戳转日期: from_unixtime
-
日期转UNIX时间戳,指定格式日期转UNIX 时间戳,获取当前UNIX时间戳: unix_timestamp
-
说明: 转换格式为”yyyy-MM-dd HH:mm:ss”的日期到 UNIX 时间戳。如果转化失败,则返回 0。
select from_unixtime(1323308943), from_unixtime(1323308943,'yyyyMMdd'), unix_timestamp(), unix_timestamp('2017-12-07 16:01:03'), unix_timestamp('20171207 16-01-03','yyyyMMdd HH-mm-ss') from order_detail limit 1; --2011-12-08 09:49:03 20111208 1566829811 1512633663 1512633663
-
-
当前时间:current_timestamp()(注意:unix_timestamp(void)已经过时,用curren_timestamp替代)
--2019-08-26 22:17:32.622
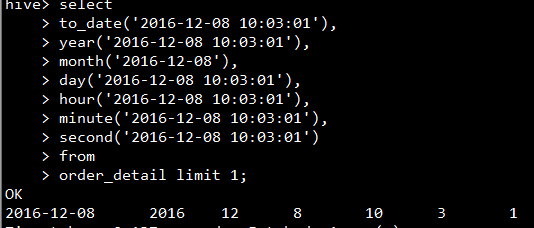
- 日期时间转日期:to_date 日期转年:year 日期转月:month 日期转天:day 日期转小时:hour 日期转分钟:minute 日期转秒:second
select
to_date('2016-12-08 10:03:01'),
year('2016-12-08 10:03:01'),
month('2016-12-08'),
day('2016-12-08 10:03:01'),
hour('2016-12-08 10:03:01'),
minute('2016-12-08 10:03:01'),
second('2016-12-08 10:03:01')
from
order_detail limit 1;
select to_date(current_timestamp());

- 日期转周:weekofyear 日期比较:datediff
select
weekofyear('2016-12-08 10:03:01'),
datediff('2016-12-08','2016-11-27')
from order_detail limit 1;
--49 11
- 日期增加: date_add 日期减少: date_sub
select date_add('2016-12-08',10),date_add('2016-12-08',-10),
date_sub('2016-12-08',-10),date_sub('2016-12-08',10) from order_detail limit 1;
--2016-12-18 | 2016-11-28 | 2016-12-18 | 2016-11-28
select
date_add('20161208',10),
from_unixtime(unix_timestamp(date_add('2016-12-08',10)),'yyyyMMdd'),
from_unixtime(unix_timestamp(date_add('2016-12-08',10),'yyyy-MM-dd'),'yyyyMMdd')
from order_detail limit 1;
5、条件函数
- IF CASE COALESCE
- 说明: COALESCE返回参数中的第一个非空值;如果所有值都为 NULL,那么返回 NULL
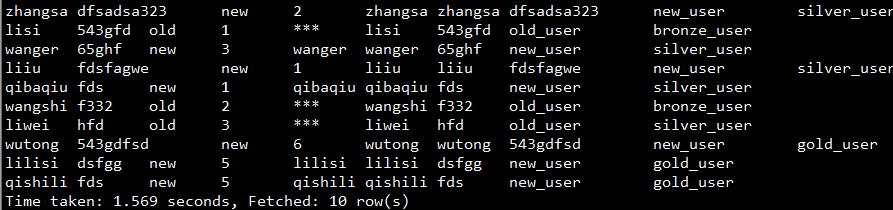
select user_id,device_id,user_type,sales,
if(user_type='new',user_id,'***'),
COALESCE(null,user_id,device_id,user_type),
COALESCE(null,null,device_id,user_type),
case user_type
when 'new' then 'new_user'
when 'old' then 'old_user'
else 'others' end,
case
when user_type='new' and sales>=5 then 'gold_user'
when user_type='old' and sales<3 then 'bronze_user'
else 'silver_user' end
from order_detail;
6、字符串函数
- 字符串长度:length 字符串反转:reverse 字符串连接:concat 带分隔符字符串连接:concat_ws
select
user_id,device_id,user_type,length(user_id),
reverse(user_id),
concat(user_id,device_id,user_type),
concat_ws('_',user_id,device_id,user_type)
from order_detail;
- 字符串截取函数: substr,substring
- 语法: substr(string A, int start),substring(string A, int start)
说明:返回字符串 A 从 start 位置到结尾的字符串 - 语法: substr(string A, int start, int len),substring(string A, int start, int len)
说明:返回字符串A从start位置开始,长度为len的字符串
- 语法: substr(string A, int start),substring(string A, int start)
- 字符串转大写:upper,ucase 字符串转小写:lower,lcase
- 去两边的空格:trim 左边去空格:ltrim 右边去空格:rtrim
- 正则表达式替换: regexp_replace
- 说明:将字符串 A 中的符合 java 正则表达式 B 的部分替换为 C。注意,在有些情况下要使用转义字符,类似 oracle 中的 regexp_replace 函数。
- 正则表达式解析: regexp_extract
将字符串 subject 按照 pattern 正则表达式的规则拆分,返回 index 指定的字符。
注意,在有些情况下要使用转义字符,如等号要用双竖线转义,这是java正则表达式的规则。
select user_id,regexp_replace(user_id, 'li|ng', '**'),
regexp_extract(user_id,'li(.*?)(si)',1),
regexp_extract(user_id,'li(.*?)(si)',2),
regexp_extract(user_id,'li(.*?)(si)',0)
from order_detail;

- URL解析:parse_url
- 语法: parse_url(string urlString, string partToExtract [, string keyToExtract])
- 说明:返回 URL 中指定的部分。
- partToExtract 的有效值为: HOST, PATH, QUERY, REF,PROTOCOL, AUTHORITY, FILE, and USERINFO。
select
parse_url('http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1', 'HOST'),
parse_url('http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1', 'PATH'),
parse_url('http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1', 'QUERY'),
parse_url('http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1', 'QUERY','k2'),
parse_url('http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1', 'REF'),
parse_url('http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1', 'PROTOCOL'),
parse_url('http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1', 'AUTHORITY'),
parse_url('http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1', 'FILE')
from order_detail limit 1;
- json解析: get_json_object
- 语法: get_json_object(string json_string, string path)
- 说明:解析 json 的字符串 json_string,返回 path 指定的内容。如果输入的 json 字符串无效,那么返回 NULL。
select
get_json_object(
'{"store": {"fruit":\[{"weight":8,"type":"apple"},{"weight":9,"type":"pear"}], "bicycle":{"price":19.95,"color":"red"} }, "email":"amy@only_for_json_udf_test.net", "owner":"amy" }',
'$.owner'),
get_json_object(
'{"store": {"fruit":\[{"weight":8,"type":"apple"},{"weight":9,"type":"pear"}], "bicycle":{"price":19.95,"color":"red"} }, "email":"amy@only_for_json_udf_test.net", "owner":"amy" }',
'$.store.fruit[0].type')
from order_detail limit 1;
- json_tuple
- 语法: json_tuple(string jsonStr,string k1,string k2, …)
- 参数为一组键k1,k2……和JSON字符串,返回值的元组。该方法比 get_json_object 高效,因为可以在一次调用中输入多个键.
select a.user_id, b.*
from order_detail a
lateral view
json_tuple('{"store": {"fruit":\[{"weight":8,"type":"apple"},{"weight":9,"type":"pear"}], "bicycle":{"price":19.95,"color":"red"} }, "email":"amy@only_for_json_udf_test.net", "owner":"amy" }', 'email', 'owner') b as email, owner limit 1;
- parse_url_tuple
SELECT b.*
from (
select 'http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1' as urlstr
from
order_detail
limit 1
)a
LATERAL VIEW
parse_url_tuple(a.urlstr, 'HOST', 'PATH', 'QUERY', 'QUERY:k1') b
as host, path, query, query_k1
LIMIT 1;
--facebook.com | /path1/p.php | k1=v1&k2=v2 | v1
- 空格字符串:space 重复字符串:repeat 首字符ascii:ascii

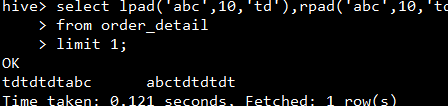
- 左补足函数:lpad 右补足函数:rpad
- 语法: lpad(string str, int len, string pad)
- 说明:lpad将 str 进行用 pad 进行左补足到 len 位, rpad将 str 进行用 pad 进行右补足到 len 位
- 注意:与 GP,ORACLE 不同; pad不能默认
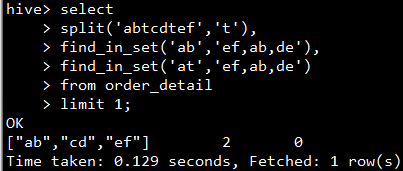
- 分割字符串函数: split
- 集合查找函数: find_in_set
语法: find_in_set(string str, string strList)
说明: 返回 str 在 strlist 第一次出现的位置, strlist 是用逗号分割的字符串。如果没有找该 str 字符,则返回 0
-
string转map:str_to_map
- 语法:str_to_map(text[, delimiter1, delimiter2])
- 说明:使用两个分隔符将文本拆分为键值对。 Delimiter1将文本分成K-V对,Delimiter2分割每个K-V对。
- 对于delimiter1默认分隔符是’,’,对于delimiter2默认分隔符是’:’。
select str_to_map('aaa:11&bbb:22', '&', ':')

7、集合统计函数
- 个数统计:count 总和统计:sum
- 语法: count(*), count(expr), count(DISTINCT expr[, expr_.])
- 说明:
count(*)统计检索出的行的个数,包括 NULL 值的行;
count(expr)返回指定字段的非空值的个数;
count(DISTINCT expr[, expr_.])返回指定字段的不同的非空值的个数
- 说明:
- sum(col), sum(DISTINCT col)
- 说明: sum(col)统计结果集中 col 的相加的结果; sum(DISTINCT col)统计结果中 col 不同值
- 语法: count(*), count(expr), count(DISTINCT expr[, expr_.])
select
count(*),count(user_type),count(distinct user_type),
sum(sales),sum(distinct sales)
from order_detail;
- 平均值统计:avg 最小值统计:min 最大值统计:max
- 标准差:stddev_samp, stddev, stddev_pop
- stddev_pop <==> stddev
- 方差:var_samp, var_pop
- 当我们需要真实的标准差/方差的时候最好是使用: stddev stddev_pop var_pop
而只是需要得到少量数据的标准差/方差的近似值可以选用: stddev_samp var_samp
- 当我们需要真实的标准差/方差的时候最好是使用: stddev stddev_pop var_pop
- 百分位数: percentile 近似百分位数: percentile_approx 直方图: histogram_numeric
- 语法: percentile_approx(DOUBLE col, p [, B])
- 返回值: double
- 说明: 求近似的第 pth 个百分位数, p 必须介于 0 和 1 之间,返回类型为 double,但是col 字段支持浮点类型。参数 B 控制内存消耗的近似精度, B越大,结果的准确度越高。默认为 10,000。当 col 字段中的 distinct 值的个数小于 B 时,结果为准确的百分位数
- 后面可以输入多个百分位数,返回类型也为 array,其中为对应的百分位数。
8、复杂类型访问操作及统计函数
测试数据集:
tony 1338 hello,woddd 1,2 a1,a2,a3 k1:1.0,k2:2.0,k3:3.0 s1,s2,s3,4
mark 5453 kke,ladyg 2,3 a4,a5,a6 k4:4.0,k5:5.0,k2:6.0 s4,s5,s6,6
ivyfd 4323 aa,thq,dsx 3,6 a7,a8,a9 k7:7.0,k8:8.0,k2:9.0 s7,s8,s9,9
drop table employees;
create external table if not exists employees(
name string,
salary string,
happy_word string,
happy_num array<int>,
subordinates array<string>,
deductions map<string,float>,
address struct<street:string,city:string,state:string,zip:int>
)
row format delimited fields terminated by '\t'
collection items terminated by ','
map keys terminated by ':'
lines terminated by '\n'
stored as textfile;
hdfs dfs -put /home/liguodong/data/muldata.txt /temp/lgd
load data inpath '/temp/lgd/muldata.txt' overwrite into table employees;
select * from employees;
Getting log thread is interrupted, since query is done!
+--------+---------+--------------+------------+-------------------+-------------------------------+---------------------------------------------------+--+
| name | salary | happy_word | happy_num | subordinates | deductions | address |
+--------+---------+--------------+------------+-------------------+-------------------------------+---------------------------------------------------+--+
| tony | 1338 | hello,woddd | [1,2] | ["a1","a2","a3"] | {
"k1":1.0,"k2":2.0,"k3":3.0} | {
"street":"s1","city":"s2","state":"s3","zip":4} |
| mark | 5453 | kke,ladyg | [2,3] | ["a4","a5","a6"] | {
"k4":4.0,"k5":5.0,"k2":6.0} | {
"street":"s4","city":"s5","state":"s6","zip":6} |
| ivyfd | 4323 | aa,thq,dsx | [3,6] | ["a7","a8","a9"] | {
"k7":7.0,"k8":8.0,"k2":9.0} | {
"street":"s7","city":"s8","state":"s9","zip":9} |
+--------+---------+--------------+------------+-------------------+-------------------------------+---------------------------------------------------+--+
## 访问数组 Map 结构体
select
name,salary,
subordinates[1],deductions['k2'],deductions['k3'],address.city
from employees;
+--------+---------+------+------+-------+-------+--+
| name | salary | _c2 | _c3 | _c4 | city |
+--------+---------+------+------+-------+-------+--+
| tony | 1338 | a2 | 2.0 | 3.0 | s2 |
| mark | 5453 | a5 | 6.0 | NULL | s5 |
| ivyfd | 4323 | a8 | 9.0 | NULL | s8 |
+--------+---------+------+------+-------+-------+--+
## Map类型长度 Array类型长度
select size(deductions),size(subordinates) from employees limit 1;
+------+------+--+
| _c0 | _c1 |
+------+------+--+
| 3 | 3 |
+------+------+--+
## 类型转换: cast
select cast(salary as int),cast(deductions['k2'] as bigint) from employees;
+---------+------+--+
| salary | _c1 |
+---------+------+--+
| 1338 | 2 |
| 5453 | 6 |
| 4323 | 9 |
+---------+------+--+
### LATERAL VIEW 行转列
SELECT
name, ad_subordinate
FROM employees
LATERAL VIEW explode(subordinates) addTable AS ad_subordinate;
+--------+-----------------+--+
| name | ad_subordinate |
+--------+-----------------+--+
| tony | a1 |
| tony | a2 |
| tony | a3 |
| mark | a4 |
| mark | a5 |
| mark | a6 |
| ivyfd | a7 |
| ivyfd | a8 |
| ivyfd | a9 |
+--------+-----------------+--+
SELECT
name, count(1)
FROM employees
LATERAL VIEW explode(subordinates) addTable AS ad_subordinate
group by name;
+--------+------+--+
| name | _c1 |
+--------+------+--+
| ivyfd | 3 |
| mark | 3 |
| tony | 3 |
+--------+------+--+
SELECT ad_subordinate, ad_num
FROM employees
LATERAL VIEW explode(subordinates) addTable AS ad_subordinate
LATERAL VIEW explode(happy_num) addTable2 AS ad_num;
+-----------------+---------+--+
| ad_subordinate | ad_num |
+-----------------+---------+--+
| a1 | 1 |
| a1 | 2 |
| a2 | 1 |
| a2 | 2 |
| a3 | 1 |
| a3 | 2 |
| a4 | 2 |
| a4 | 3 |
| a5 | 2 |
| a5 | 3 |
| a6 | 2 |
| a6 | 3 |
| a7 | 3 |
| a7 | 6 |
| a8 | 3 |
| a8 | 6 |
| a9 | 3 |
| a9 | 6 |
+-----------------+---------+--+
### 多个LATERAL VIEW
SELECT
name, count(1)
FROM employees
LATERAL VIEW explode(subordinates) addTable AS ad_subordinate
LATERAL VIEW explode(happy_num) addTable2 AS ad_num
group by name;
+--------+------+--+
| name | _c1 |
+--------+------+--+
| ivyfd | 6 |
| mark | 6 |
| tony | 6 |
+--------+------+--+
### 不满足条件产生空行
SELECT AA.name, BB.* FROM employees AA
LATERAL VIEW
explode(array()) BB AS a limit 10;
+-------+----+--+
| name | a |
+-------+----+--+
+-------+----+--+
### OUTER 避免永远不产生结果,无满足条件的行,在该列会产生NULL值。
SELECT AA.name, BB.* FROM employees AA
LATERAL VIEW
OUTER explode(array()) BB AS a limit 10;
+--------+-------+--+
| name | a |
+--------+-------+--+
| tony | NULL |
| mark | NULL |
| ivyfd | NULL |
+--------+-------+--+
### 字符串切分成多列
SELECT
name, word
FROM employees
LATERAL VIEW explode(split(happy_word,',')) addTable AS word;
+--------+--------+--+
| name | word |
+--------+--------+--+
| tony | hello |
| tony | woddd |
| mark | kke |
| mark | ladyg |
| ivyfd | aa |
| ivyfd | thq |
| ivyfd | dsx |
+--------+--------+--+
### OUTER 避免永远不产生结果,无满足条件的行,在该列会产生NULL值。
SELECT AA.name, BB.* FROM employees AA
LATERAL VIEW
OUTER explode(array()) BB AS a limit 10;
+--------+-------+--+
| name | a |
+--------+-------+--+
| tony | NULL |
| mark | NULL |
| ivyfd | NULL |
+--------+-------+--+
### 字符串切分成多列
SELECT
name, word
FROM employees
LATERAL VIEW explode(split(happy_word,',')) addTable AS word;
+--------+--------+--+
| name | word |
+--------+--------+--+
| tony | hello |
| tony | woddd |
| mark | kke |
| mark | ladyg |
| ivyfd | aa |
| ivyfd | thq |
| ivyfd | dsx |
+--------+--------+--+
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/193121.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
