大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
RabbitMQ使用以及原理解析
RabbitMQ是一个由erlang开发的AMQP(Advanved Message Queue)的开源实现;在RabbitMQ官网上主要有这样的模块信息, Work queues消息队列,Publish/Subscribe发布订阅服务,Routing, Topics, RPC等主要应用的模块功能.
几个概念说明:
Broker:它提供一种传输服务,它的角色就是维护一条从生产者到消费者的路线,保证数据能按照指定的方式进行传输,
Exchange:消息交换机,它指定消息按什么规则,路由到哪个队列。
Queue:消息的载体,每个消息都会被投到一个或多个队列。
Binding:绑定,它的作用就是把exchange和queue按照路由规则绑定起来.
Routing Key:路由关键字,exchange根据这个关键字进行消息投递。
vhost:虚拟主机,一个broker里可以有多个vhost,用作不同用户的权限分离。
Producer:消息生产者,就是投递消息的程序.
Consumer:消息消费者,就是接受消息的程序.
**Channel:**消息通道,在客户端的每个连接里,可建立多个channel.
RabbitMQ的流程图


AMQP(高级消息队列协议 Advanced Message Queue Protocol)
Rabbitmq系统最核心的组件是Exchange和Queue,上图是系统简单的示意图。Exchange和Queue是在rabbitmq server(又叫做broker)端,producer和consumer在应用端。
流程思路
左边的Client向右边的Client发送消息,流程:
1, 获取Conection
2, 获取Channel
3, 定义Exchange,Queue
4, 使用一个RoutingKey将Queue Binding到一个Exchange上
5, 通过指定一个Exchange和一个RoutingKey来将消息发送到对应的Queue上,
6, 接收方在接收时也是获取connection,接着获取channel,然后指定一个Queue直接到它关心的Queue上取消息,它对Exchange,RoutingKey及如何binding都不关心,到对应的Queue上去取消息就OK了;
通信过程
假设P1和C1注册了相同的Broker,Exchange和Queue。P1发送的消息最终会被C1消费。基本的通信流程大概如下所示:
P1生产消息,发送给服务器端的Exchange
Exchange收到消息,根据ROUTINKEY,将消息转发给匹配的Queue1
Queue1收到消息,将消息发送给订阅者C1
C1收到消息,发送ACK给队列确认收到消息
Queue1收到ACK,删除队列中缓存的此条消息
注意要点:
Consumer收到消息时需要显式的向rabbit broker发送basic.ack消息或者consumer订阅消息时设置auto_ack参数为true。在通信过程中,队列对ACK的处理有以下几种情况:
如果consumer接收了消息,发送ack,rabbitmq会删除队列中这个消息,发送另一条消息给consumer。
如果cosumer接受了消息, 但在发送ack之前断开连接,rabbitmq会认为这条消息没有被deliver,在consumer在次连接的时候,这条消息会被redeliver。
如果consumer接受了消息,但是程序中有bug,忘记了ack,rabbitmq不会重复发送消息。
rabbitmq2.0.0和之后的版本支持consumer reject某条(类)消息,可以通过设置requeue参数中的reject为true达到目地,那么rabbitmq将会把消息发送给下一个注册的consumer。
vhosts(broker)
一个RabbitMQ的实体上可以有多个vhosts,用户与权限设置就是依附于vhosts。
在rabbitmq server上可以创建多个虚拟的message broker,又叫做virtual hosts (vhosts)。每一个vhost本质上是一个mini-rabbitmq server,分别管理各自的exchange,和bindings。vhost相当于物理的server,可以为不同app提供边界隔离,使得应用安全的运行在不同的vhost实例上,相互之间不会干扰。producer和consumer连接rabbit server需要指定一个vhost。
connection 与 channel(连接与信道)
connection是指物理的连接,一个client与一个server之间有一个连接;一个连接上可以建立多个channel,可以理解为逻辑上的连接。一般应用的情况下,有一个channel就够用了,不需要创建更多的channel。
exchange 与 routingkey(交换机与路由键)
Exchange类似于数据通信网络中的交换机,提供消息路由策略。rabbitmq中,producer不是通过信道直接将消息发送给queue,而是先发送给Exchange。一个Exchange可以和多个Queue进行绑定,producer在传递消息的时候,会传递一个ROUTING_KEY,Exchange会根据这个ROUTING_KEY按照特定的路由算法,将消息路由给指定的queue。和Queue一样,Exchange也可设置为持久化,临时或者自动删除。
Exchange有4种类型:direct(默认),fanout, topic, 和headers,不同类型的Exchange转发消息的策略有所区别:
Direct 直接交换器,工作方式类似于单播,Exchange会将消息发送完全匹配ROUTING_KEY的Queue;

fanout 广播是式交换器,不管消息的ROUTING_KEY设置为什么,Exchange都会将消息转发给所有绑定的Queue。
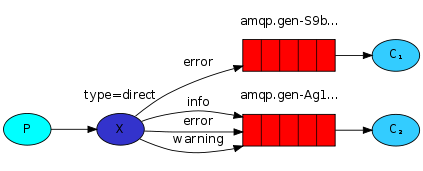
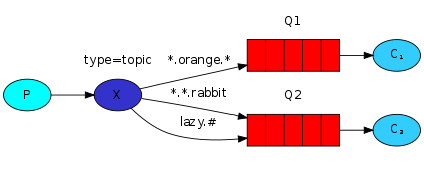
topic 主题交换器,工作方式类似于组播,Exchange会将消息转发和ROUTING_KEY匹配模式相同的所有队列,比如,ROUTING_KEY为user.stock的Message会转发给绑定匹配模式为 * .stock,user.stock, * . * 和#.user.stock.#的队列。( * 表是匹配一个任意词组,#表示匹配0个或多个词组)
headers 消息体的header匹配(ignore)
queue(队列)
消息队列,提供了FIFO的处理机制,具有缓存消息的能力。rabbitmq中,队列消息可以设置为持久化,临时或者自动删除。
设置为持久化的队列,queue中的消息会在server本地硬盘存储一份,防止系统crash,数据丢失
设置为临时队列,queue中的数据在系统重启之后就会丢失
设置为自动删除的队列,当不存在用户连接到server,队列中的数据会被自动删除;
Binding(绑定)
所谓绑定就是将一个特定的Exchange和一个特定的 Queue 绑定起来。Exchange和Queue的绑定可以是多对多的关系。
client(Producer&Consumer)
producer指的是消息生产者,consumer消息的消费者。
Rabbit的消息任务机制
1.Round-robin dispathching循环分发
RabbbitMQ的分发机制非常适合扩展,而且它是专门为并发程序设计的,如果现在load加重,那么只需要创建更多的Consumer来进行任务处理。
2.Message acknowledgment消息确认
为了保证数据不被丢失,RabbitMQ支持消息确认机制,为了保证数据能被正确处理而不仅仅是被Consumer收到,那么我们不能采用no-ack,而应该是在处理完数据之后发送ack.
在处理完数据之后发送ack,就是告诉RabbitMQ数据已经被接收,处理完成,RabbitMQ可以安强调内容全的删除它了.
如果Consumer退出了但是没有发送ack,那么RabbitMQ就会把这个Message发送到下一个Consumer,这样就保证在Consumer异常退出情况下数据也不会丢失.
RabbitMQ它没有用到超时机制.RabbitMQ仅仅通过Consumer的连接中断来确认该Message并没有正确处理,也就是说RabbitMQ给了Consumer足够长的时间做数据处理。
如果忘记ack,那么当Consumer退出时,Mesage会重新分发,然后RabbitMQ会占用越来越多的内存.
消息序列化
RabbitMQ使用ProtoBuf序列化消息,它可作为RabbitMQ的Message的数据格式进行传输,由于是结构化的数据,这样就极大的方便了Consumer的数据高效处理,当然也可以使用XML,与XML相比,ProtoBuf有以下优势:
1.简单
2.size小了3-10倍
3.速度快了20-100倍
4.易于编程
6.减少了语义的歧义.
另外,ProtoBuf具有速度和空间的优势,使得它现在应用非常广泛;
rabbitmq组件断链重连机制
方案一:
Rabbitmq在启动时,为rabbitmq设置一个status,在第一次建立连接的时候将其变为true,rabbitmq client在初始化时启动一个定时器,每隔一段时间开启一个线程,查询当前status的状态,如果status变为false,重新建立连接(包括connection、channel的连接)。
方案二:
Implement shutdown listener,如果rabbitmq断线,在shutdown方法执行相应的重连方法。
关于消息的重复执行
首先我们可以确认的是,触发消息重复执行的条件会是很苛刻的! 也就说 在大多数场景下不会触发该条件!!! 一般出在任务超时,或者没有及时返回状态,引起任务重新入队列,重新消费! 在rabbtimq里连接的断开也会触发消息重新入队列。
消费任务类型最好要支持幂等性,这样的好处是 任务执行多少次都没关系,顶多消耗一些性能! 如果不支持幂等,比如发送信息? 那么需要构建一个map来记录任务的执行情况! 不仅仅是成功和失败,还要有心跳!!! 这个map在消费端实现就可以了!!! 这里会出现一个问题,有两个消费者 c1, c2 ,一个任务有可能被c1消费,如果再来一次,被c2执行? 那么如何得知任务的情况? 任务派发! 任务做成hash,固定消费者!
坚决不要想方设法在mq扩展这个future。
一句话,要不保证消息幂等性,要不就用map记录任务状态.
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/189571.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...