大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
前言
内容基本摘至官方文档,链接如下:
https://help.aliyun.com/product/92664.html
一、定义
从官方文档了解到其的定义为:
阿里云分析型数据库AnalyticDB(简称ADB),是云端托管的PB级高并发实时数据仓库,是专注于服务OLAP领域的数据仓库。在数据存储模型上,采用关系模型进行数据存储,可以使用SQL进行自由灵活的计算分析,无需预先建模。利用云端的无缝伸缩能力,AnalyticDB在处理百亿条甚至更多量级的数据时真正实现毫秒级计算。
AnalyticDB支持通过SQL来构建关系型数据仓库。具有管理简单、节点数量伸缩方便、灵活升降实例规格等特点,而且支持丰富的可视化工具以及ETL软件,极大的降低了企业建设数据化的门槛。
二、产品优势
快
- 新一代超大规模的MPP+DAG融合引擎
- 采用行列混存技术、自动索引、智能优化器,在瞬间即可对千亿级别的数据进行即时的多维度分析透视,快速发现数据价值
- 可以快速扩容至数千节点的超大规模
灵活
- 极度灵活的存储和计算分离架构,可以随时调整节点数量和动态升降配实例规格
- 同时支持在大存储SATA节点和高性能的SSD节点灵活切换
易用
- 作为云端托管的PB级SQL数据仓库,全面兼容MySQL协议和SQL:2003
- 通过标准的SQL和常用的BI工具、以及ETL工具平台即可轻松使用AnalyticDB
超大规模
- 全分布式结构,无任何单点设计,使得数据库实例支持ECU节点动态线性扩容至数千节点
- 通过横向扩容来大幅度提升查询SQL响应速度、以及增加SQL处理并发
高并发写入
- 通过横向扩容节点提升写入能力
- 实时写入数据后,约1秒左右即可查询分析。单个表最大支持2PB数据,十万亿记录
三、应用场景
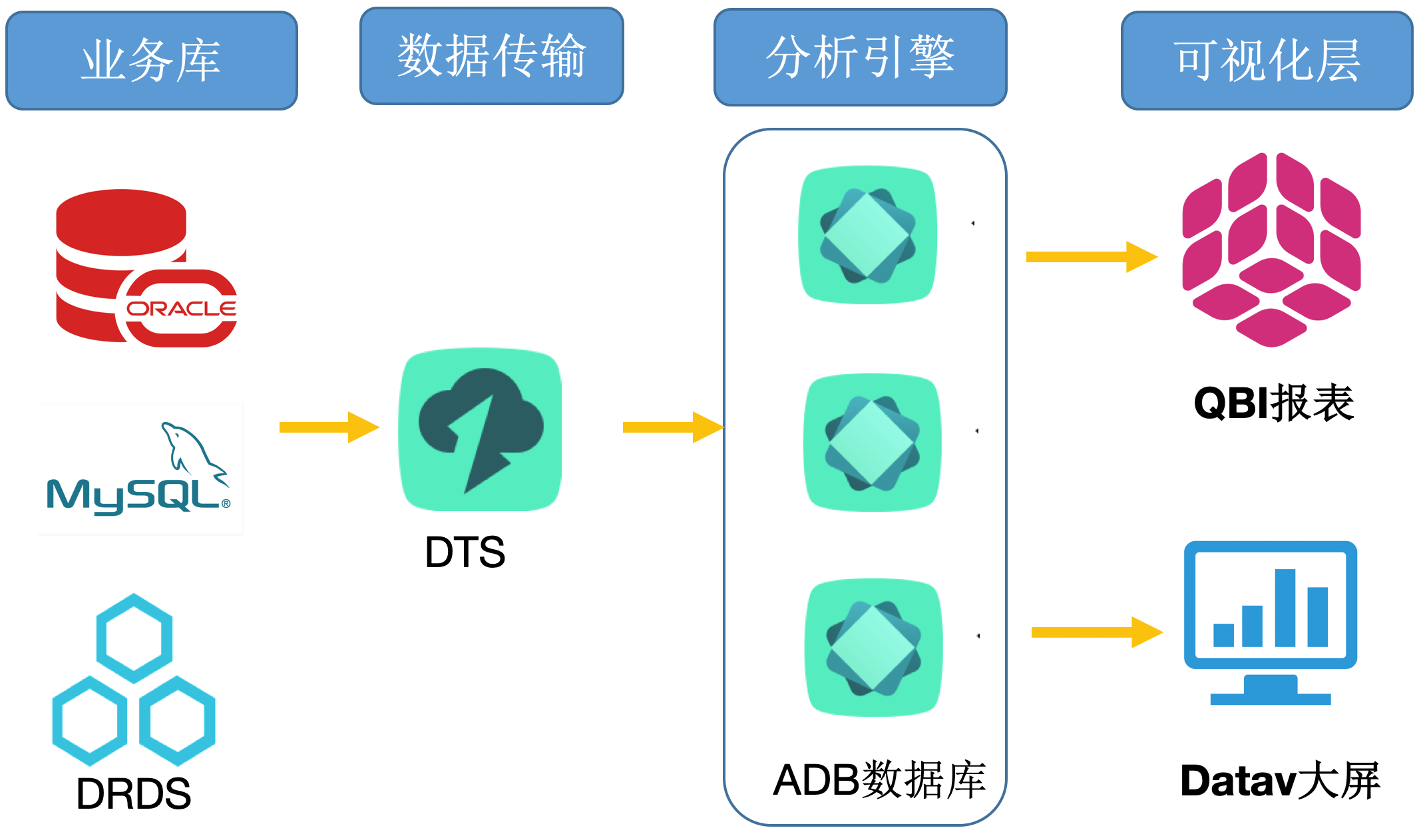
经典实时数仓场景
您可以通过数据传输DTS将关系型数据库的业务表实时镜像一份到AnalyticDB,通过Quick BI(简称QBI)拖拽式轻松生成报表,或者通过DataV快速定制您的企业实时数据大屏

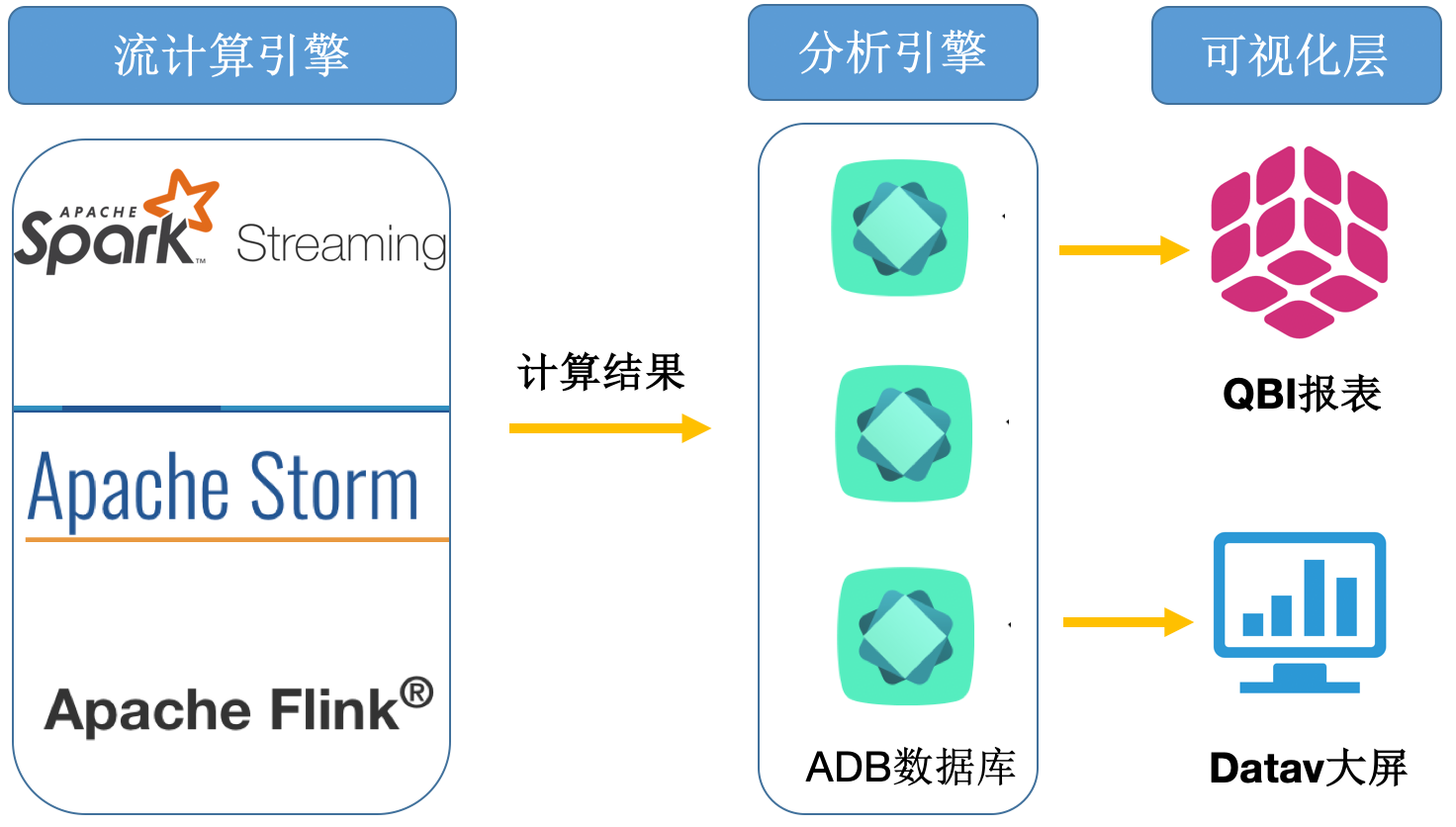
实时计算清洗回流场景
通过将流计算清洗结果数据回流至AnalyticDB来代替传统的MySQL等单机数据库,作为报表库来查询使用。由于关系型数据库分布式的查询性能优势,不需要分库分表就能解决PB级别的查询性能问题。
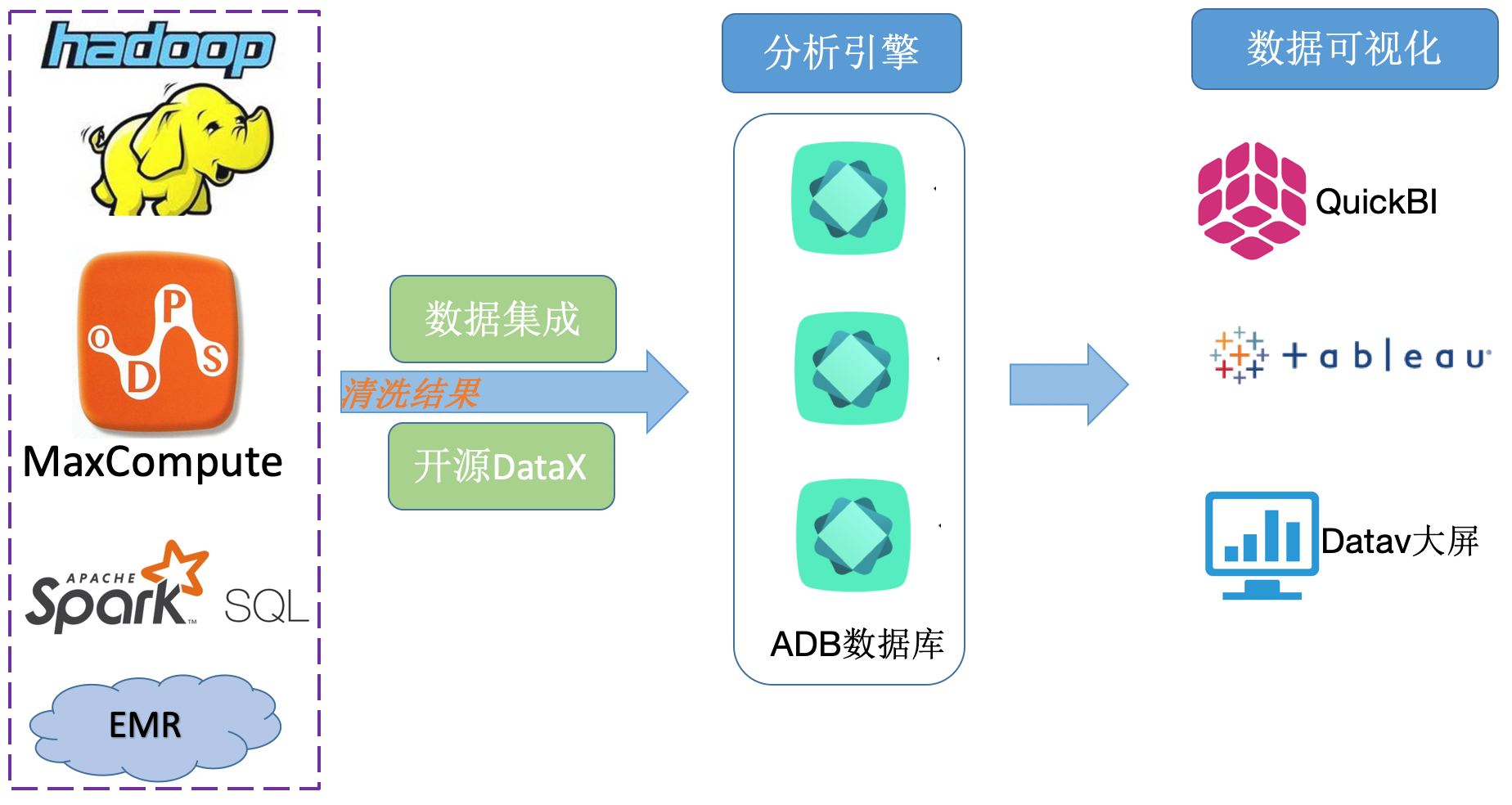
ETL清洗回流场景
大数据离线计算平台 MaxCompute、SparkSQL、Hadoop、E-MapReduce等平台产品在清洗完数据后,由于报表查询条件依然很复杂,运营报表需要钻取,导致单机数据库无法支撑性能,此时需要一个像AnalyticDB这样非常强大的报表查询引擎完成数据查询工作。常见的回流数据工具有数据集成 和业内开源产品Datax。
四、名词解释
数据库
数据库是AnalyticDB最高层的对象,按数据库进行资源的分配和管理。每个数据库独享一个服务进程,实现用户间资源的隔离。AnalyticDB中数据库的概念又称之为实例,通常说的一个AnalyticDB数据库就是一个实例,一个实例由若干个ECU节点组成。
ECU
弹性计算单元(Elastic compute units 简写ECU)是AnalyticDB用来衡量实例计算能力的元单位。一个数据库由若干个同一类型的ECU节点组成,例如数据库A,可能由4个C8组成,或者6个S2N组成,每个ECU节点配备有固定的磁盘和内存资源。
表组
表组是一系列可发生关联的数据表的集合,AnalyticDB为了管理相关联的数据表,引入了表组的概念。表组类似于传统数据库schema的概念,AnalyticDB表组分为两类:
维度表组(系统自带)
自带维度概念的表(例如省份表、银行表等),可以放到维度表组下。
普通表组
一般会把需要关联的普通表放在相同普通表组中,建议这个表组中的所有普通表的一级分区数一致,join性能会有很大提升。
表
在表组之下是表的概念,AnalyticDB提供两种类型的表:
维度表
带有维度概念的表(例如银行表),又称为复制表。默认每个ECU节点放置一份全量的维度表数据,所以维度表可以和任何普通表进行关联。由于维度表会消耗更多的存储资源,所以维度表的数据量大小有限制,一般要求维度表单表不超过5000万行。
普通表
普通表就是分区表,为充分利用分布式系统的查询能力而设计的一种表。普通表默认是指一级分区表,如果有增量数据导入需求,可以创建二级分区表。
分区
普通表才有分区的概念,AnalyticDB支持两级分区策略:一级分区采用hash算法,单表数据量在60亿以内,我们推荐您使用一级分区,通常一级分区已足够。二级分区采用list算法,二级分区部分见最佳实践章节。
主键
AnalyticDB的的表必须包含主键字段,通过主键进行记录的唯一性判断。主键由业务id、一级分区键组成,有些情况业务id与一级分区相同。对于记录量特别大的表,从存储空间和insert性能考虑,一定要减少主键的字段数。
示例
以一个电商公司购买了一个AnalyticDB Trade为例,帮助您理解上述概念。
1.客户在阿里云购买1个名为Trade的AnalyticDB(也称之为1个ADS实例),如图所示,Trade由4个C4节点构成。
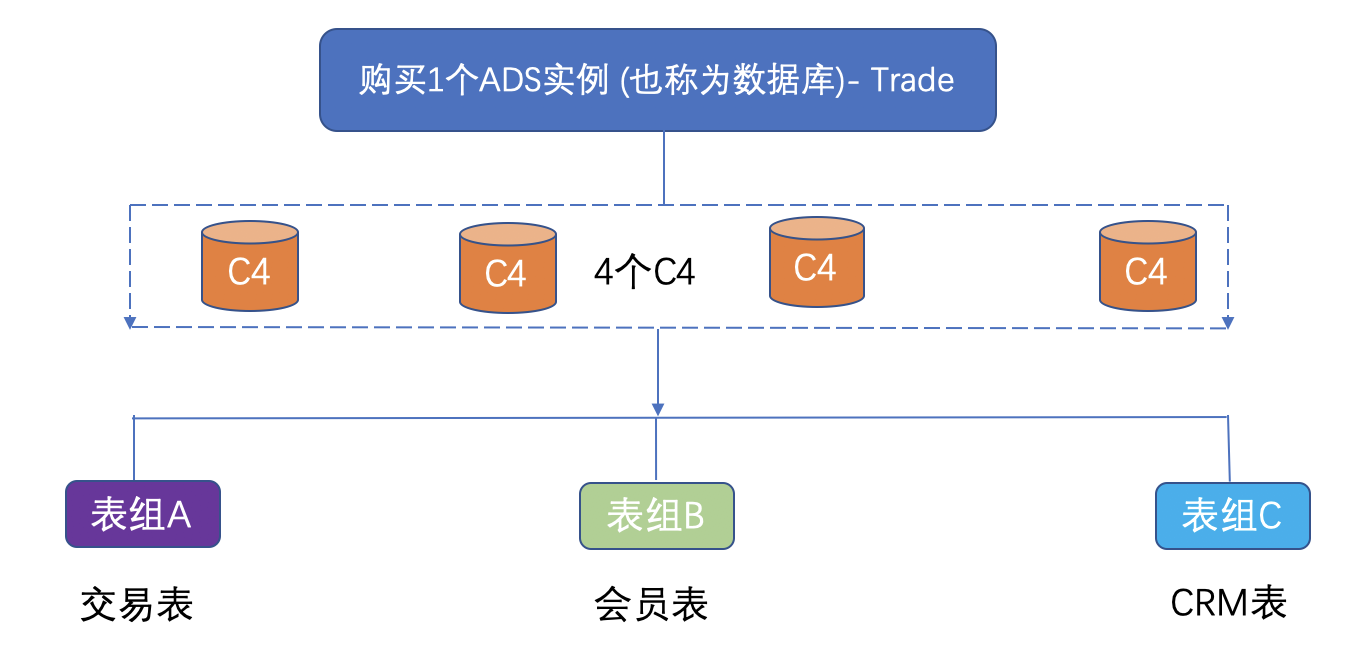
2.C4是一种ECU规格,我们还提供C8,S2N,S8N三种不同规格的ECU。
3.数据库Trade下面可以规划多个表组(类似Schema概念),不同表组用于存放不同的业务表。
4.Trade数据库创建完毕后,系统会默认创建一个维度表组,所有维度相关的表,可以放到维度表组下。普通表按照上述第3点的规则来管理。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/192477.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
