大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
——————————————————————————
作者:知乎用户
链接:https://www.zhihu.com/question/26561604/answer/33275982
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
——————————————————————————
首先我们看一下 Fisher Information 的定义:
假设你观察到 i.i.d 的数据  服从一个概率分布,是你的目标参数(for simplicity, 这里是个标量,且不考虑 nuissance parameter),那么你的似然函数(likelihood)就是:
服从一个概率分布,是你的目标参数(for simplicity, 这里是个标量,且不考虑 nuissance parameter),那么你的似然函数(likelihood)就是:
为了解得Maximum Likelihood Estimate(MLE),我们要让log likelihood的一阶导数得0,然后解这个方程,得到
这个log likelihood的一阶导数也叫,Score function :
那么Fisher Information,用表示,的定义就是这个Score function的二阶矩(second moment)。
一般情况下(under specific regularity conditions)可以很容易地证明,, 从而得到:
于是得到了Fisher Information的第一条数学意义:就是用来估计MLE的方程的方差。它的直观表述就是,随着收集的数据越来越多,这个方差由于是一个Independent sum的形式,也就变的越来越大,也就象征着得到的信息越来越多。
而且,如果log likelihood二阶可导,在一般情况下(under specific regularity conditions)可以很容易地证明:
于是得到了Fisher Information的第二条数学意义:log likelihood在参数真实值处的负二阶导数的期望。这个意义好像很抽象,但其实超级好懂。
首先看一下一个normalized Bernoulli log likelihood长啥样:
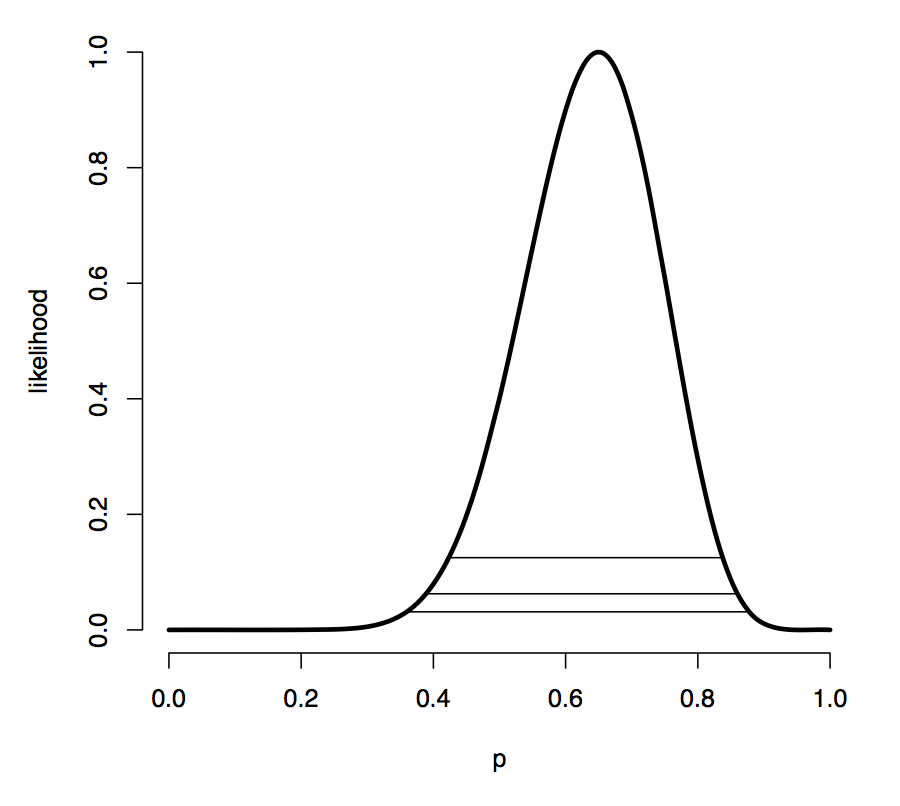 对于这样的一个log likelihood function,它越平而宽,就代表我们对于参数估计的能力越差,它高而窄,就代表我们对于参数估计的能力越好,也就是信息量越大。而这个log likelihood在参数真实值处的负二阶导数,就反应了这个log likelihood在顶点处的弯曲程度,弯曲程度越大,整个log likelihood的形状就越偏向于高而窄,也就代表掌握的信息越多。
对于这样的一个log likelihood function,它越平而宽,就代表我们对于参数估计的能力越差,它高而窄,就代表我们对于参数估计的能力越好,也就是信息量越大。而这个log likelihood在参数真实值处的负二阶导数,就反应了这个log likelihood在顶点处的弯曲程度,弯曲程度越大,整个log likelihood的形状就越偏向于高而窄,也就代表掌握的信息越多。
然后,在一般情况下(under specific regularity conditions),通过对score function在真实值处泰勒展开,然后应用中心极限定理,弱大数定律,依概率一致收敛,以及Slutsky定理,可以证明MLE的渐进分布的方差是,即, 这也就是
Fisher Information的第三条数学意义。不过这样说不严谨,严格的说,应该是, 这里是当只观察到一个X值时的Fisher Information,当有n个 i.i.d 观测值时,。所以这时的直观解释就是,Fisher Information反映了我们对参数估计的准确度,它越大,对参数估计的准确度越高,即代表了越多的信息。
—————————————————————————–
作者:小Q痴子
链接:https://www.zhihu.com/question/26561604/answer/145734266
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
——————————————————————————
参数估计的本质是,假设样本的数据来自于某一个分布,然后利用样本中蕴含的信息来估计参数。一个自然的问题就是:对于分布里的未知参数,这个样本数据给出了多少信息呢?Fisher Information 就衡量了这样的“信息”。
什么样的样本给出的信息更多?直觉上思考这个问题,如果一个事件发生的概率很大,那发生这件事并不能带来太多信息;相反,如果一个事件发生的概率很小,那发生这件事可以带来比较多的信息。
现在我们再回顾一下最大似然估计(Maximum Likelihood Estimation)的基本思想。对于随机变量 ,直觉上,当 取到参数的真实值时,似然函数的值应该很大,最大似然估计的思想就是认为 当 取到参数的真实值时似然函数的值应该取到最大值,或者(对数)似然函数的一阶导数为0。
定义对数似然函数为 ,从而,其中是关于的导数。
根据上面的两段分析,如果非常接近于0,这将是意料之中的事情,因此样本没有带来太多关于参数的信息;相反,如果很大,或者说很大,那么样本就提供了比较多的关于参数的信息。所以,我们可以用来衡量提供的信息(information)。但是是个随机变量,于是我们就考虑的期望值。
于是就有了Fisher Information的定义(1):
如果假设可以交换求导和积分的顺序,那么
容易看出,
所以Fisher Information的定义(1)可以改写成定义(2):
(其中用到。)
注意到
因此
至此我们有了关于Fisher Information的第(3)个表达式:
综上所述,我们有三个办法来计算Fisher Information。实际上在大多数问题中,(3)将是最方便的。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/192063.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
