大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
前文是一些针对IRL,IL综述性的解释,后文是针对《Generative adversarial imitation learning》文章的理解及公式的推导。
- 通过深度强化学习,我们能够让机器人针对一个任务实现从0到1的学习,但是需要我们定义出reward函数,在很多复杂任务,例如无人驾驶中,很难根据状态特征来建立一个科学合理的reward。
- 人类学习新东西有一个重要的方法就是模仿学习,通过观察别人的动作来模仿学习,不需要知道任务的reward函数。模仿学习就是希望机器能够通过观察模仿专家的行为来进行学习。
- OpenAI,DeepMind,Google Brain目前都在向这方面发展。
[1] Model-Free Imitation Learning with Policy Optimization, OpenAI, 2016
[2] Generative Adversarial Imitation Learning, OpenAI, 2016
[3] One-Shot Imitation Learning, OpenAI, 2017
[4] Third-Person Imitation Learning, OpenAI, 2017
[5] Learning human behaviors from motion capture by adversarial imitation, DeepMind, 2017
[6] Robust Imitation of Diverse Behaviors, DeepMind, 2017
[7] Unsupervised Perceptual Rewards for Imitation Learning, Google Brain, 2017
[8] Time-Contrastive Networks: Self-Supervised Learning from Multi-View Observation, Google Brain, 2017
[9] Imitation from Observation/ Learning to Imitate Behaviors from Raw Video via Context Translation, OpenAI, 2017
[10] One Shot Visual Imitation Learning, OpenAI, 2017
模仿学习
- 从给定的专家轨迹中进行学习。
- 机器在学习过程中能够跟环境交互,到那时不能直接获得reward。
- 在任务中很难定义合理的reward(自动驾驶中撞人reward,撞车reward,红绿灯reward),人工定义的reward可能会导致失控行为(让agent考试,目标为考100分,但是reward可能通过作弊的方式)。
- 三种方法:
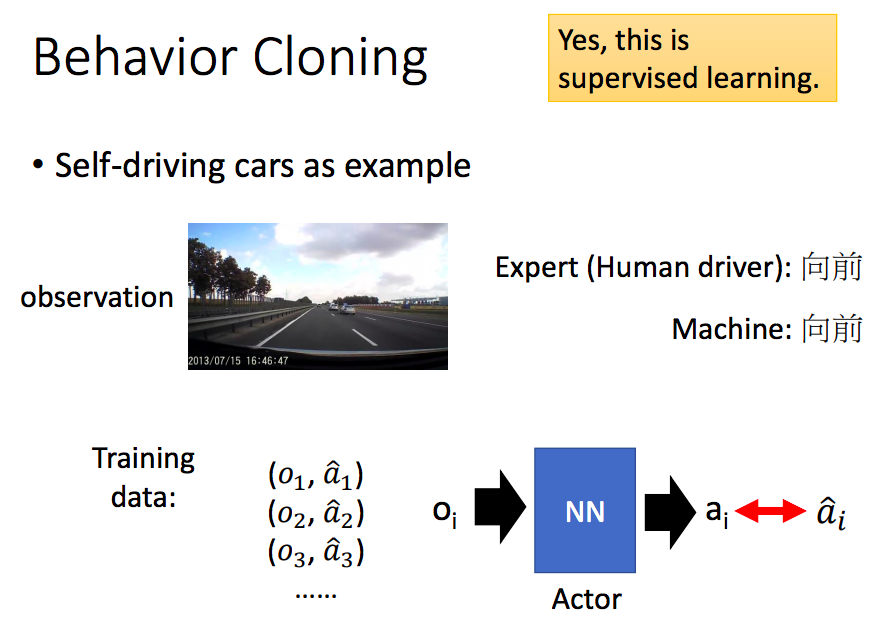
a. 行为克隆(Behavior Cloning)
b. 逆向强化学习(Inverse Reinforcement Learning)
c. GAN引入IL(Generative Adversarial Imitation Learning) - 行为克隆
有监督的学习,通过大量数据,学习一个状态s到动作a的映射。

但是专家轨迹给定的数据集是有限的,无法覆盖所有可能的情况。如果更换数据集可能效果会不好。则只能不断增加训练数据集,尽量覆盖所有可能发生的状态。但是并不实际,在很多危险状态采集数据成本非常高。 - 逆向强化学习
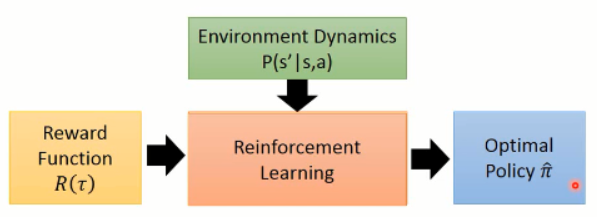
RL是通过agent不断与environment交互获取reward来进行策略的调整,最终得到一个optimal policy。但IRL计算量较大,在每一个内循环中都跑了一遍RL算法。
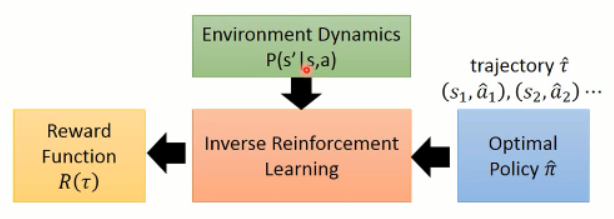
IRL不同之处在于,无法获取真实的reward函数,但是具有根据专家策略得到的一系列轨迹。假设专家策略是真实reward函数下的最优策略,IRL学习专家轨迹,反推出reward函数。
得到复原的reward函数后,再进行策略函数的估计。
RL算法:
IRL算法:
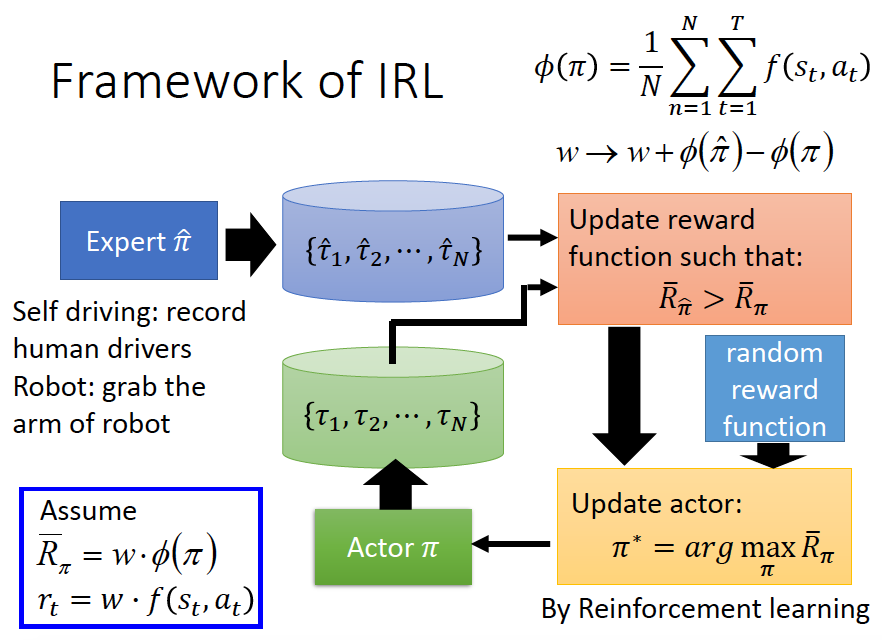
在给定的专家策略后(expert policy),不断寻找reward function来使专家策略是最优的。(解释专家行为,explaining expert behaviors)。具体流程图如下:
- 生成对抗模仿学习(GAN for Imitation Learning)
我们可以假设专家轨迹是属于某一分布(distribution),我们想让我们的模型也去预测一个分布,并且使这两个分布尽可能的接近。
算法流程如下:
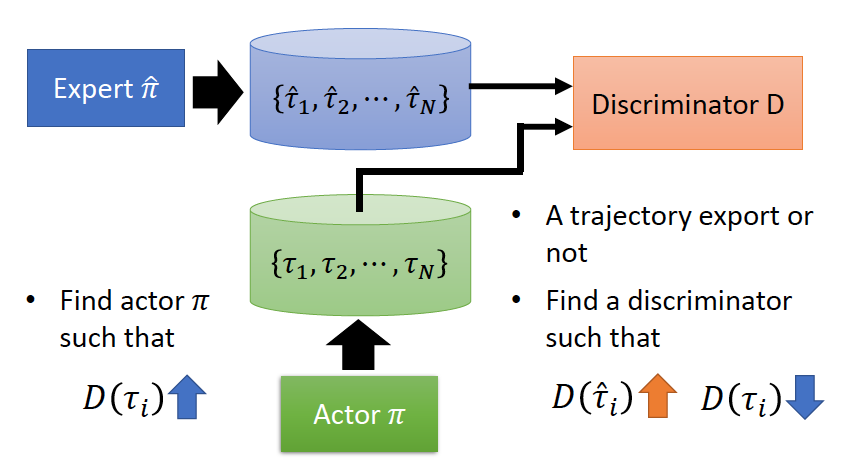
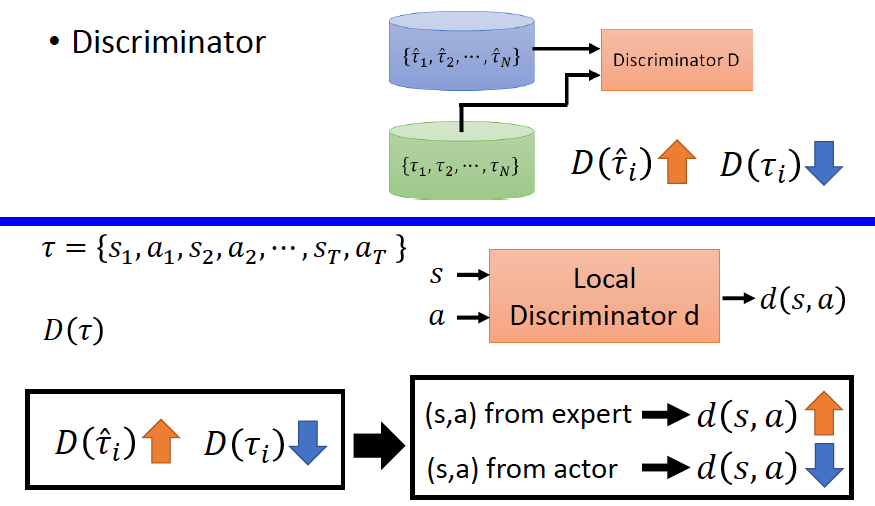
Discriminator:尽可能的区分轨迹是由expert生成还是Generator生成。
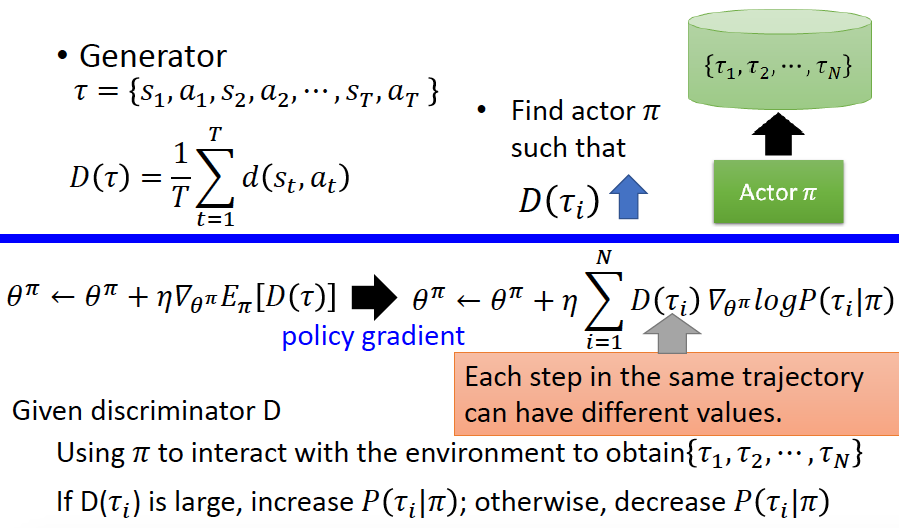
Generator(Actor):产生出一个轨迹,使其与专家轨迹尽可能相近,使Discriminator无法区分轨迹是expert生成的还是Generator生成的。
其算法可以写为:




生成对抗模仿学习(Generative Adversarial Imitation Learning)
GAIL能够直接从专家轨迹中学得策略,绕过很多IRL的中间步骤。
逆向强化学习(IRL)
假定cost function的集合为 C \mathcal{C} C, π E \pi_E πE为专家策略。带有正则化项 ψ \psi ψ最大熵逆向强化学习是想找到一个cost function似的专家策略的效果优于其余所有策略(cost越小越优):
I R L ψ ( π E ) = arg m a x c ∈ C − ψ ( c ) + ( min π ∈ Π − H ( π ) + E π [ c ( s , a ) ] ) − E π E [ c ( s , a ) ] \rm{IRL}_{\psi}(\pi_E) = \arg max_{c\in\mathcal{C}} -\psi(c)+(\min_{\pi \in \Pi}- \it {H}(\pi) + \mathbb E_\pi[c(s,a)]) – \mathbb E_{\pi_E}[c(s,a)] IRLψ(πE)=argmaxc∈C−ψ(c)+(π∈Πmin−H(π)+Eπ[c(s,a)])−EπE[c(s,a)]
其中 E π [ c ( s , a ) ] = E [ ∑ t = 0 ∞ γ t c ( s t , a t ) ] \mathbb E_\pi[c(s,a)]=\mathbb E[\sum\limits_{t=0}^\infty \gamma^tc(s_t,a_t)] Eπ[c(s,a)]=E[t=0∑∞γtc(st,at)] , H ( π ) = E π [ − log π ( a ∣ s ) ] H(\pi)=\mathbb E_\pi[-\log \pi(a|s)] H(π)=Eπ[−logπ(a∣s)]是一个 γ \gamma γ折扣累积熵。IRL过程中包含一个RL过程:
R L ( c ) = arg m i n π ∈ Π − H ( π ) + E π [ c ( s , a ) ] \rm{RL}(c) = \arg min_{\pi \in \Pi} -\it H(\pi)+\mathbb E_\pi [c(s,a)] RL(c)=argminπ∈Π−H(π)+Eπ[c(s,a)]
Defination 1.
对于一个策略 π \pi π,定义其占用率度量(occupancy measure) ρ π : S × A → R \rho_\pi:\mathcal{S}\times\mathcal{A}\to \mathbb R ρπ:S×A→R为
ρ π ( s , a ) = π ( a ∣ s ) ∑ t = 0 ∞ γ t P ( s t = s ∣ π ) \rho_\pi(s,a) = \pi(a|s)\sum\limits_{t=0}^\infty\gamma^tP(s_t=s|\pi) ρπ(s,a)=π(a∣s)t=0∑∞γtP(st=s∣π)
占用率度量可以近似看做是使用策略 π \pi π时,状态-动作对的分布。 D \mathcal D D是有效的占用率度量的集合。
[1] U. Syed, M. Bowling, and R. E. Schapire. Apprenticeship learning using linear programming. In
Proceedings of the 25th International Conference on Machine Learning, pages 1032–1039, 2008. 证明 π ∈ Π \pi \in \Pi π∈Π与 ρ ∈ D \rho\in\mathcal D ρ∈D是一一对应关系。
Lemma 3.1.
若 ρ ∈ D \rho\in\mathcal D ρ∈D,则 ρ \rho ρ是策略 π ρ = ρ ( s , a ) / ∑ a ′ ρ ( s , a ′ ) \pi_{\rho}=\rho(s,a)/\sum\limits_{a'}\rho(s,a') πρ=ρ(s,a)/a′∑ρ(s,a′)的占用率度量,并且 π ρ \pi_{\rho} πρ是唯一的。
根据Definition 1,可以将 γ \gamma γ折累计代价写为
E π [ c ( s , a ) ] = ∑ s , a ρ π ( s , a ) c ( s , a ) \mathbb E_\pi[c(s,a)]=\sum\limits_{s,a}\rho_\pi(s,a)c(s,a) Eπ[c(s,a)]=s,a∑ρπ(s,a)c(s,a)
Lemma 3.2.
若 H ( π ) = E π [ − log π ( a ∣ s ) ] H(\pi)=\mathbb E_\pi[-\log\pi(a|s)] H(π)=Eπ[−logπ(a∣s)], H ‾ ( ρ ) = − ∑ s , a ρ ( s , a ) log ( ρ ( s , a ) / ∑ a ′ ρ ( s , a ′ ) ) \overline H(\rho)=-\sum\limits_{s,a}\rho(s,a)\log(\rho(s,a)/ \sum_{a'}\rho(s,a')) H(ρ)=−s,a∑ρ(s,a)log(ρ(s,a)/∑a′ρ(s,a′))。可知 H ‾ \overline H H是强凹的,并且对于任意 π ∈ Π , ρ ∈ D \pi \in \Pi, \rho \in \mathcal D π∈Π,ρ∈D,可得 H ( π ) = H ‾ ( ρ π ) H(\pi)=\overline H(\rho_\pi) H(π)=H(ρπ)和 H ( π ρ ) = H ‾ ( ρ ) H(\pi_\rho)=\overline H(\rho_) H(πρ)=H(ρ)。
Lemma 3.3.
若 L ( π , c ) = − H ( π ) + E π [ c ( s , a ) ] L(\pi,c)=-H(\pi)+\mathbb E_\pi[c(s,a)] L(π,c)=−H(π)+Eπ[c(s,a)], L ‾ ( ρ , c ) = − H ‾ ( ρ ) + ∑ s , a ρ ( s , a ) c ( s , a ) \overline L(\rho,c) = -\overline H(\rho) + \sum_{s,a}\rho(s,a)c(s,a) L(ρ,c)=−H(ρ)+∑s,aρ(s,a)c(s,a)。对于所有的代价函数 c c c,如下成立:
1.对于任意 π ∈ Π \pi\in\Pi π∈Π, L ( π , c ) = L ‾ ( ρ π , c ) L(\pi,c)=\overline L(\rho_\pi,c) L(π,c)=L(ρπ,c).
2.对于任意 ρ ∈ D \rho\in\mathcal D ρ∈D, L ( π ρ , c ) = L ‾ ( ρ , c ) L(\pi_\rho,c)=\overline L(\rho,c) L(πρ,c)=L(ρ,c)
Definition 2
对于一个方程 f : R R × A → R ‾ f:\mathbb R^{\mathcal R \times \mathcal A}\to \overline \mathbb R f:RR×A→R,其凸共轭 f ∗ : R R × A → R ‾ f^*:\mathbb R^{\mathcal R \times \mathcal A} \to \overline \mathbb R f∗:RR×A→R定义为 f ∗ ( x ) = sup y ∈ R S × A x T y − f ( y ) f^*(x) = \sup_{y\in\mathbb R^{\mathcal S \times \mathcal A}}x^Ty-f(y) f∗(x)=supy∈RS×AxTy−f(y).
Proposition 1
$RL(\widetilde c) $是利用IRL恢复的cost,通过RL学得的policy。可得
R L ∘ I R L ψ ( π E ) = a r g m i n π ∈ Π − H ( π ) + ψ ∗ ( ρ π − ρ π E ) RL\circ IRL_\psi(\pi_E) = argmin_{\pi\in\Pi}-H(\pi) + \psi^*(\rho_\pi – \rho_{\pi_{E}}) RL∘IRLψ(πE)=argminπ∈Π−H(π)+ψ∗(ρπ−ρπE)
上述表明, ψ \psi ψ正则化逆向强化学习就只隐性的找到policy,该policy的占用率度量(occupancy measure)逼近专家策略的占用率度量,使用凸函数 ψ ∗ \psi^* ψ∗来衡量占用率度量的差异。
通过上式可得,最优代价函数(cost function)与学得的policy可以组成上式的一个鞍点,IRL寻找鞍点的一个坐标维度,RL根据IRL的结果寻找鞍点坐标的另一个维度。 ( c , π ) (c,\pi) (c,π)为一个鞍点。
可得,不同的正则化函数 ψ \psi ψ构成不同的模仿学习算法,可以直接求解上式得到 ( c , π ) (c,\pi) (c,π)。
在本文中将会主要介绍三种不同的正则化函数:恒定正则化函数,示性正则化函数,生成对抗正则化函数(GA)
Corollary 1
若 ψ \psi ψ是一个恒定值, c ~ ∈ I R L ψ ( π E ) \widetilde c\in IRL_\psi(\pi_E) c
∈IRLψ(πE)并且 π ~ ∈ R L ( c ~ ) \widetilde \pi\in RL(\widetilde c) π
∈RL(c
),则 ρ π ~ = ρ π E \rho_{\widetilde \pi} = \rho_{\pi_E} ρπ
=ρπE.
- 若没有正则化项,则RL得到的policy将会精确匹配专家policy
- 但该算法无法应用于实际系统中,因为实际系统的环境非常大,计算复杂。
若正则化项为一个恒定值,则只能学习到专家轨迹中采样到的状态动作对,但是在大规模环境中,专家轨迹有限无法探索到所有的状态动作对,因此学得的policy几乎不会涉及到未出现过的状态动作对。
示性正则化学徒学习
学徒算法是想要找到一个policy并且比专家policy效果在学得的cost function C \mathcal C C情况下更好,通过解如下方程:
min π max c ∈ C E π [ c ( s , a ) ] − E π E [ c ( s , a ) ] \min_\pi \max_{c\in\mathcal C} \mathbb E_\pi[c(s,a)] – \mathbb E_{\pi_E}[c(s,a)] πminc∈CmaxEπ[c(s,a)]−EπE[c(s,a)]
C \mathcal C C是一个有约束的凸集,是由一系列基础方程 f 1 , f 2 , … , f d f_1,f_2,\dots,f_d f1,f2,…,fd的线性组合而成。 Abbeel 和 Ng使用 C l i n e a r = { ∑ i w i f i : ∥ w ∥ 2 ≤ 1 } \mathcal C_{linear} = \{ \sum_i w_if_i:\|w\|_2\le1\} Clinear={
∑iwifi:∥w∥2≤1},Syde使用 C c o n v e x = { ∑ i w i f i : ∑ i w i = 1 , w i ≥ 0 ∀ i } \mathcal C_{convex}=\{ \sum_i w_if_i:\sum_iw_i=1,w_i\ge 0 \forall i\} Cconvex={
∑iwifi:∑iwi=1,wi≥0∀i}.
对于示性函数 δ c : R S × A → R ‾ \delta_c:\mathbb R^{\mathcal S \times \mathcal A}\to \overline \mathbb R δc:RS×A→R,定义如下
δ C ( c ) = { 0 , c ∈ C + ∞ , o t h e r w i s e \delta_{\mathcal C}(c) =\left\{ \begin{array}{lr} 0, & c\in\mathcal C \\ +\infty, & otherwise \end{array} \right. δC(c)={
0,+∞,c∈Cotherwise
学徒学习的目标函数可以化为
max c ∈ C E π [ c ( s , a ) ] − E π E [ c ( s , a ) ] = max c ∈ C − δ C ( c ) + ∑ s , a ( ρ π ( s , a ) − ρ π E ( s , a ) ) c ( s , a ) = δ C ∗ ( ρ π − ρ π E ) \begin{aligned} &\max_{c\in\mathcal C} \mathbb E_\pi[c(s,a)] – \mathbb E_{\pi_E}[c(s,a)] \\ &=\max_{c\in\mathcal C} -\delta_{\mathcal C}(c)+\sum_{s,a}(\rho_\pi(s,a)-\rho_{\pi_E}(s,a))c(s,a) \\ &=\delta_{\mathcal C}^*(\rho_\pi – \rho_{\pi_E}) \end{aligned} c∈CmaxEπ[c(s,a)]−EπE[c(s,a)]=c∈Cmax−δC(c)+s,a∑(ρπ(s,a)−ρπE(s,a))c(s,a)=δC∗(ρπ−ρπE)
无法精确匹配专家经验的占用率度量。
熵-正则化学徒学习
min π − H ( π ) + max c ∈ C E π [ c ( s , a ) ] − E π E [ c ( s , a ) ] = min π − H ( π ) + δ C ∗ ( ρ π − ρ π E ) \min_\pi – H(\pi)+\max_{c\in\mathcal C}\mathbb E_\pi[c(s,a)] – \mathbb E_{\pi_E}[c(s,a)] = \min_{\pi} -H(\pi)+\delta_{\mathcal C}^*(\rho_\pi-\rho_{\pi_E}) πmin−H(π)+c∈CmaxEπ[c(s,a)]−EπE[c(s,a)]=πmin−H(π)+δC∗(ρπ−ρπE)
熵-正则化学徒学习等价于在有示性函数 ψ = δ C \psi=\delta_{\mathcal C} ψ=δC的IRL后运行RL。
GA正则化
ψ G A ( c ) = { E π E [ g ( c ( s , a ) ) ] , c < 0 + ∞ , o t h e r w i s e g ( x ) = { − x − log ( 1 − e x ) , x < 0 0 , o t h e r w i s e \psi_{GA}(c) = \left\{ \begin{array}{lr} \mathbb E_{\pi_E}[g(c(s,a))],\qquad &c<0 \\ +\infty, & otherwise \end{array} \right. \\ g(x)=\left\{ \begin{array}{lr} -x-\log(1-e^x),\qquad &x<0 \\ 0, & otherwise \end{array} \right. ψGA(c)={
EπE[g(c(s,a))],+∞,c<0otherwiseg(x)={
−x−log(1−ex),0,x<0otherwise
- ψ G A \psi_{GA} ψGA是一个针对专家数据求期望的函数,因此可以适用于任意专家数据集。
- 不像 δ C \delta_{\mathcal C} δC将cost function约束在小的子空间中。 ψ G A \psi_{GA} ψGA允许任意的cost function只要是负数空间中。
选择 ψ G A \psi_{GA} ψGA的目的是因为其具有一个非常优秀的凸共轭函数,如下
ψ G A ∗ ( ρ π − ρ π E ) = max D ∈ ( 0 , 1 ) S × A E π E [ log ( D ( s , a ) ) ] + E π [ log ( 1 − D ( s , a ) ) ] \psi_{GA}^*(\rho_\pi-\rho_{\pi_E}) = \max_{D\in(0,1)^{\mathcal S \times \mathcal A}} \mathbb E_{\pi_E}[\log(D(s,a))] + \mathbb E_\pi[\log(1-D(s,a))] ψGA∗(ρπ−ρπE)=D∈(0,1)S×AmaxEπE[log(D(s,a))]+Eπ[log(1−D(s,a))]
上式等价于一个对数损失函数来区分 π \pi π与 π E \pi_E πE。这个最优损失等价于Jensen-Shannon散度
D J S ( ρ π , ρ π E ) = D K L ( ρ π ∥ ( ρ π − ρ π E ) / 2 ) + D K L ( ρ π E ∥ ( ρ E + ρ π E ) / 2 ) D_{JS}(\rho_\pi,\rho_{\pi_E}) = D_{KL}(\rho_\pi \|(\rho_\pi – \rho_{\pi_E})/2)+D_{KL}(\rho_{\pi_E}\|(\rho_E+\rho_{\pi_E})/2) DJS(ρπ,ρπE)=DKL(ρπ∥(ρπ−ρπE)/2)+DKL(ρπE∥(ρE+ρπE)/2)
则有如下等价关系
min π ψ G A ∗ ( ρ π − ρ π E ) − λ H ( π ) ⟺ min π max D E π E [ log ( D ( s , a ) ) ] + E π [ log ( 1 − D ( s , a ) ] − λ H ( π ) ⟺ min π D J S ( ρ π , ρ π E ) − λ H ( π ) \min_{\pi}\psi_{GA}^*(\rho_\pi – \rho_{\pi_E})-\lambda H(\pi) \Longleftrightarrow \\ \min_{\pi}\max_{D}\mathbb E_{\pi_E}[\log(D(s,a))]+\mathbb E_{\pi}[\log(1-D(s,a)]-\lambda H(\pi) \Longleftrightarrow \\ \min_{\pi}D_{JS}(\rho_\pi,\rho_{\pi_E}) – \lambda H(\pi) πminψGA∗(ρπ−ρπE)−λH(π)⟺πminDmaxEπE[log(D(s,a))]+Eπ[log(1−D(s,a)]−λH(π)⟺πminDJS(ρπ,ρπE)−λH(π)
找到一个policy,其占用率度量(occupancy measure)能够最小化与专家经验的Jensen-Shannon散度。
生成对抗网络
min G max D E x ∼ P d a t a ( x ) [ log D ( x ) ] + E z ∼ P z ( z ) [ log ( 1 − D ( G ( z ) ) ) ] \min_G\max_D \mathbb E_{x\sim P_{data}(x)}[\log D(x)] + \mathbb E_{z\sim P_z(z)}[\log(1-D(G(z)))] GminDmaxEx∼Pdata(x)[logD(x)]+Ez∼Pz(z)[log(1−D(G(z)))]
D的任务是区分G生成的数据与真实数据。
- 学习到的policy的占用率度量 ρ π \rho_\pi ρπ类比于G生成的数据分布。
- 专家经验的占用率度量 ρ π E \rho_{\pi_E} ρπE类比于真实数据分布。
GAIL算法
- 期望找到如下式的鞍点 ( π , D ) (\pi,D) (π,D)
E π E [ log ( D ( s , a ) ) ] + E π [ log ( 1 − D ( s , a ) ) ] − λ H ( π ) \mathbb E_{\pi_E}[\log(D(s,a))] + \mathbb E_\pi[\log(1-D(s,a))]-\lambda H(\pi) EπE[log(D(s,a))]+Eπ[log(1−D(s,a))]−λH(π) - π θ \pi_\theta πθ是一个参数化的policy, θ \theta θ为权重。 D ω D_\omega Dω是一个参数化的鉴别器,权重为 ω \omega ω。
- 对 ω \omega ω使用Adam梯度算法,从而使上式上升。
- 对 θ \theta θ使用TRPO算法,从而使上式下降。
- TPRO能够保证 π θ i + 1 \pi_{\theta_{i+1}} πθi+1不远离 π θ i \pi_{\theta_{i}} πθi
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/191837.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
