什么是Solr
Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化
Solr可以独立运行,运行在Jetty、Tomcat等这些Servlet容器中,Solr 索引的实现方法很简单,用 POST 方法向 Solr 服务器发送一个描述 Field 及其内容的 XML 文档,Solr根据xml文档添加、删除、更新索引 。Solr 搜索只需要发送 HTTP GET 请求,然后对 Solr 返回Xml、json等格式的查询结果进行解析,组织页面布局。Solr不提供构建UI的功能,Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
solr是基于lucene开发企业级搜索服务器,实际上就是封装了lucene。
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的文件,生成索引;也可以通过提出查找请求,并得到返回结果
Solr类似webservice,调用接口,实现增加,修改,删除,查询索引库。
Solr与Lucene的区别
Lucene是一个开放源代码的全文检索引擎工具包,它不是一个完整的全文检索引擎,Lucene提供了完整的查询引擎和索引引擎,目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者以Lucene为基础构建全文检索引擎。
Solr的目标是打造一款企业级的搜索引擎系统,它是一个搜索引擎服务,可以独立运行,通过Solr可以非常快速的构建企业的搜索引擎,通过Solr也可以高效的完成站内搜索功能。
Solr类似webservice,提供接口,调用接口,发送一些特点语句,实现增加,删除,修改,查询。
1、solr 下载安装
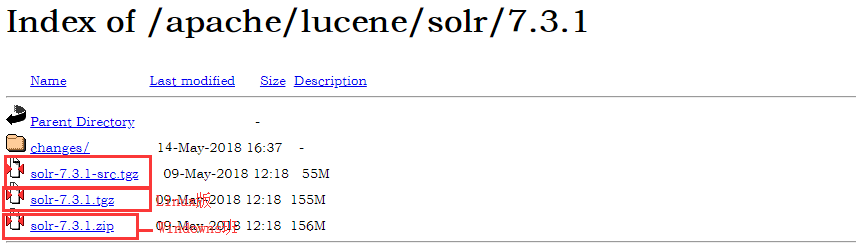
下载地址: http://www.apache.org/dyn/closer.lua/lucene/solr/7.3.1



2 安装solr
下载之后,将solr-7.3.1.zip发在自己特定的盘符下。但是注意不要此目录最好不要有空格,中文或者其他特殊字符。
3、启动solr
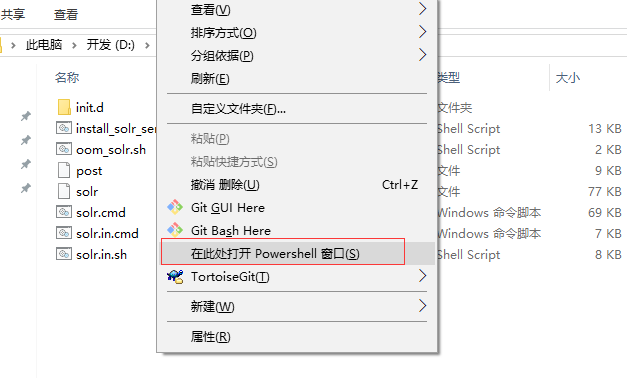
解压solr-7.3.1.zip之后,进入其bin目录:在空白处shift+鼠标右键,进入Powershell窗口:
然后输入cmd.exe
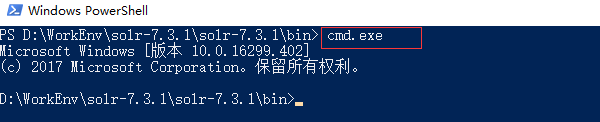
solr 7.3 自带jetty,可以独立运行,不需要使用Tomcat启动。
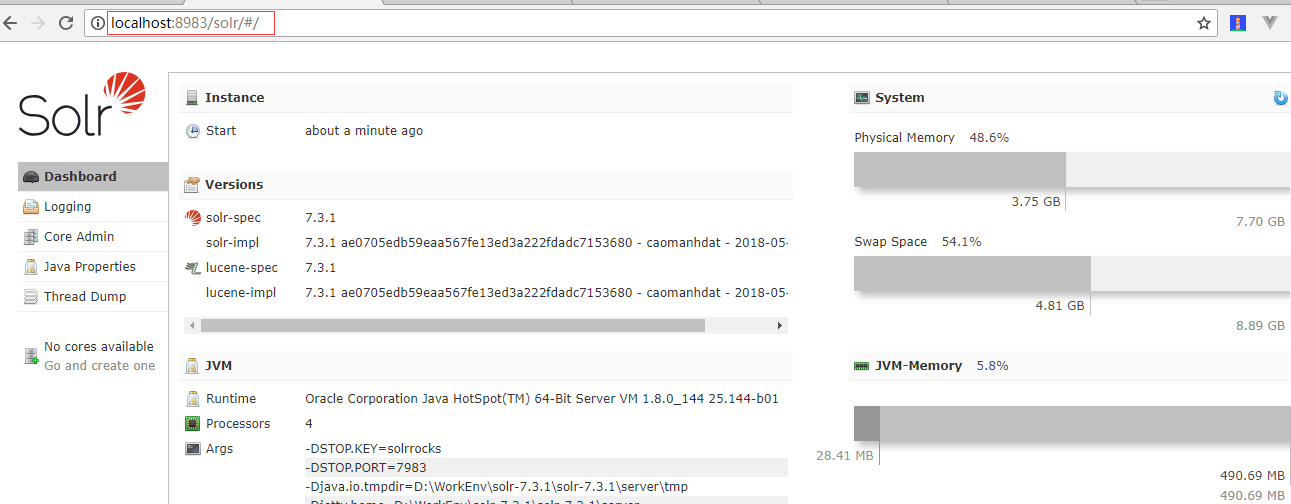
输入solr.cmd start 然后敲回车,就可以启动solr了。默认端口为:8983

在浏览器输入localhost:8983/solr,就可以看到solr已经启动了
4、创建核心core
所谓core可以类比mysql数据库来理解,就好比mysql中一个个的数据库,用来存放具体的数据表的仓库。
切记不可以直接使用管理界面提供的add core来创建core
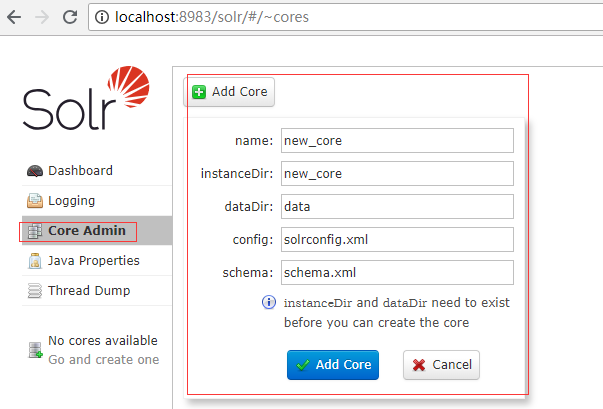
在刚刚打开的窗口,输入 solr.cmd create -c test_Core

此时进入安装目录下的server\solr,可看到创建了一个test_Core目录
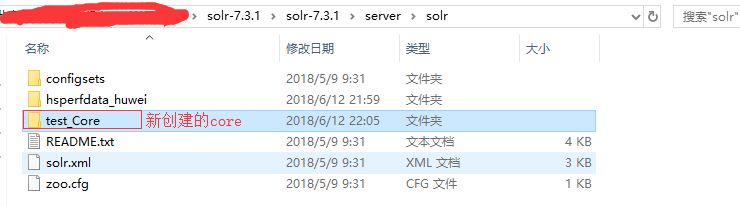
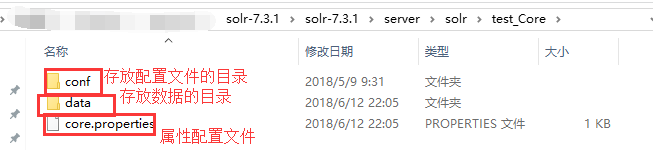
进入该目录
创建好了后,刷新页面,同时在图中下拉框就可以看到你创建的Core了。如果看不到,在dos窗口输入 solr restart -p 8983 重启solr即可
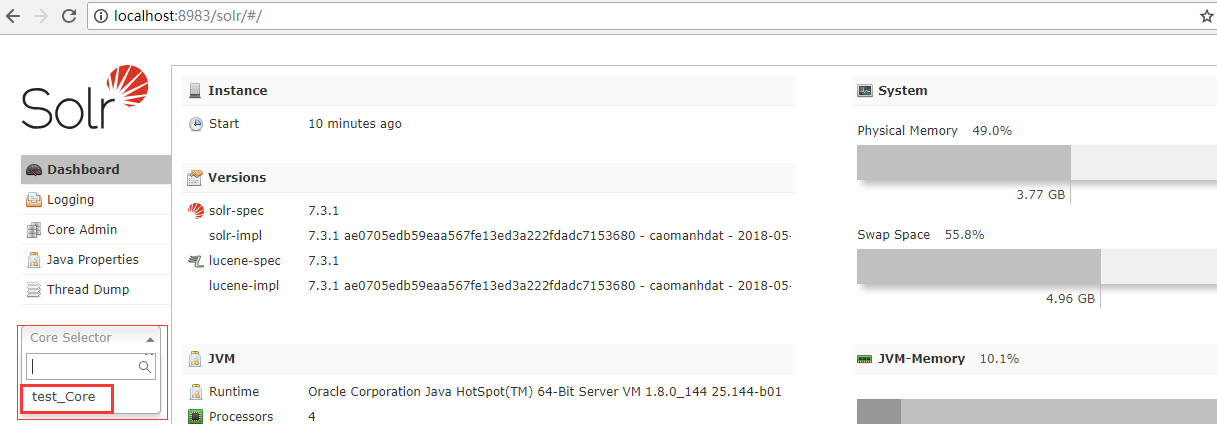
点击myCore 就可以看到如下信息:这些信息包含了分词器,还有数据导入,数据查询等功能
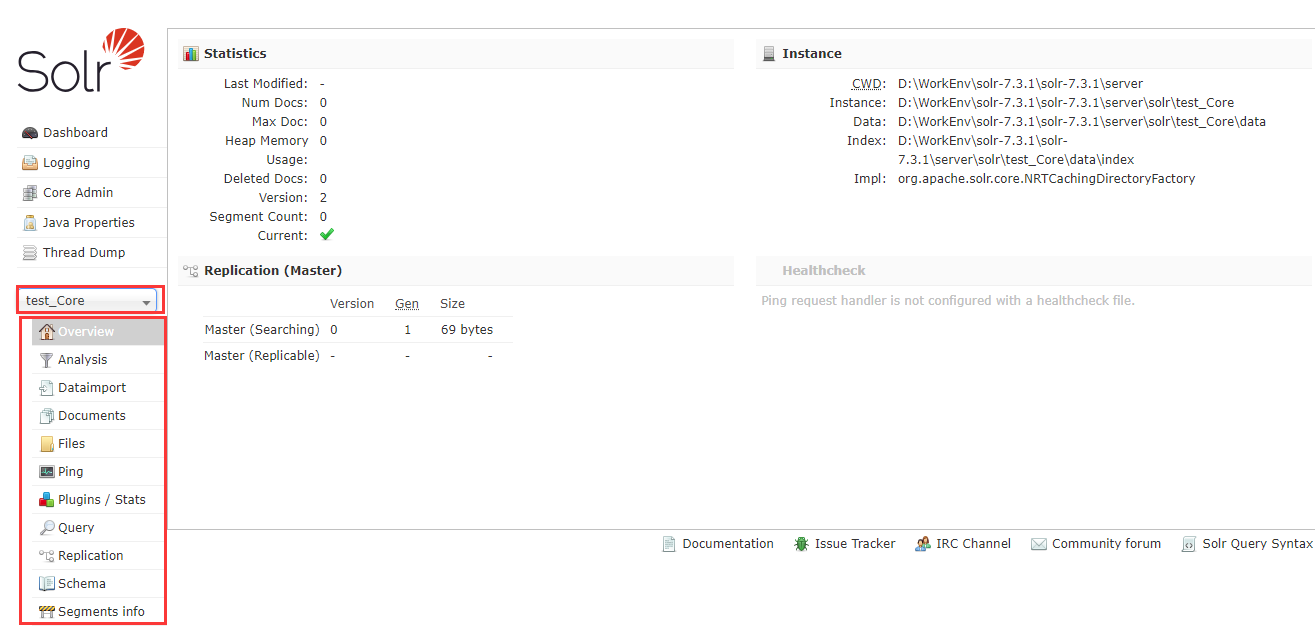
5、启动solr和创建core完成之后,这一步配置中文分词器:
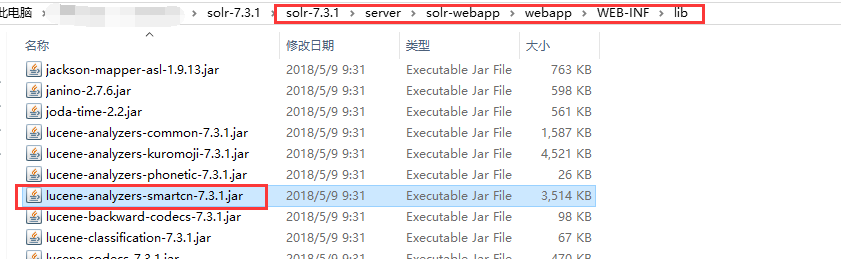
添加中文分词插件:solr 7.3.1中自带中文分词插件,将solr-7.3.1\contrib\analysis-extras\lucene-libs\lucene-analyzers-smartcn-7.3.1.jar 复制到 solr-7.3.1\server\solr-webapp\webapp\WEB-INF\lib 目录中
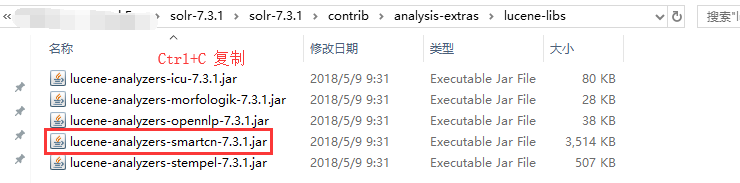
粘贴到目标路径:
配置中文分词,修改 solr-7.3.1\server\solr\test_Core**【这个test_Core是刚刚创建的core名称】**\conf\managed-schema文件,添加中文分词
文件位置:
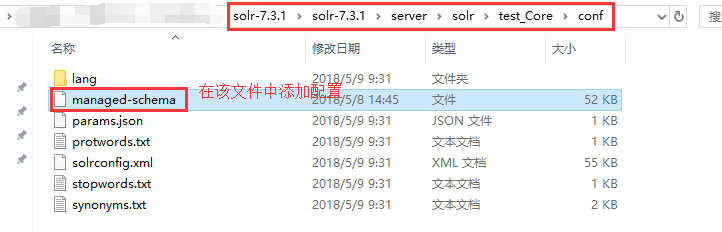
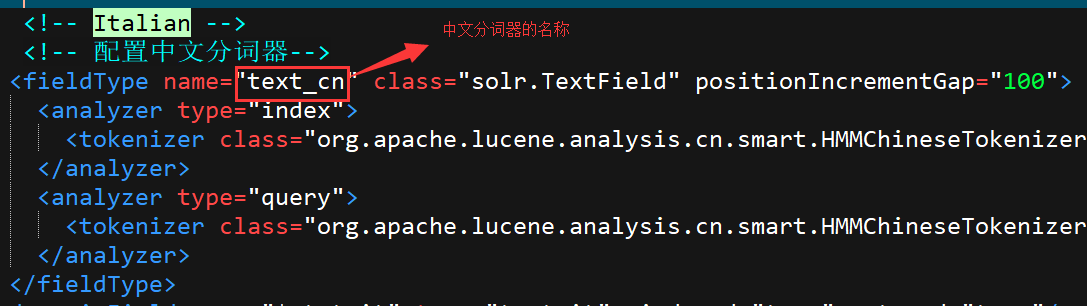
打开这个文件后,搜索 Italian,在Italian下添加我们的中文配置(复制粘贴即可):
<!-- Italian --> <!-- 配置中文分词器--> <fieldType name="text_cn" class="solr.TextField" positionIncrementGap="100"> <analyzer type="index"> <tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/> </analyzer> </fieldType> 配置完成:
使用solr restart -p 8983重启solr服务
刷新打开管理页
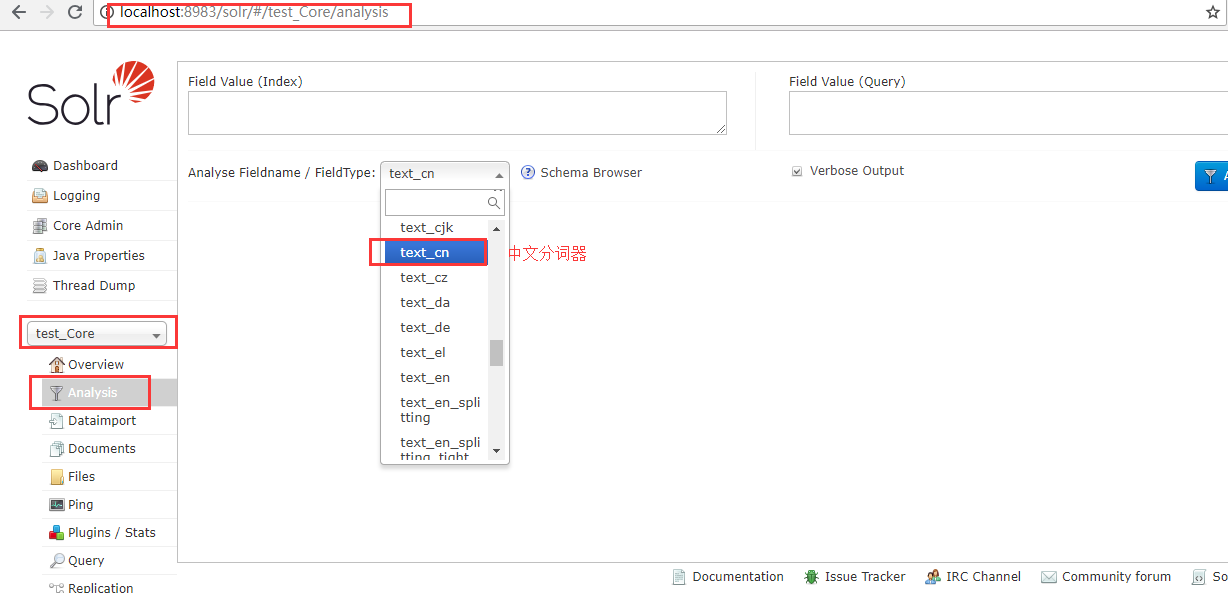
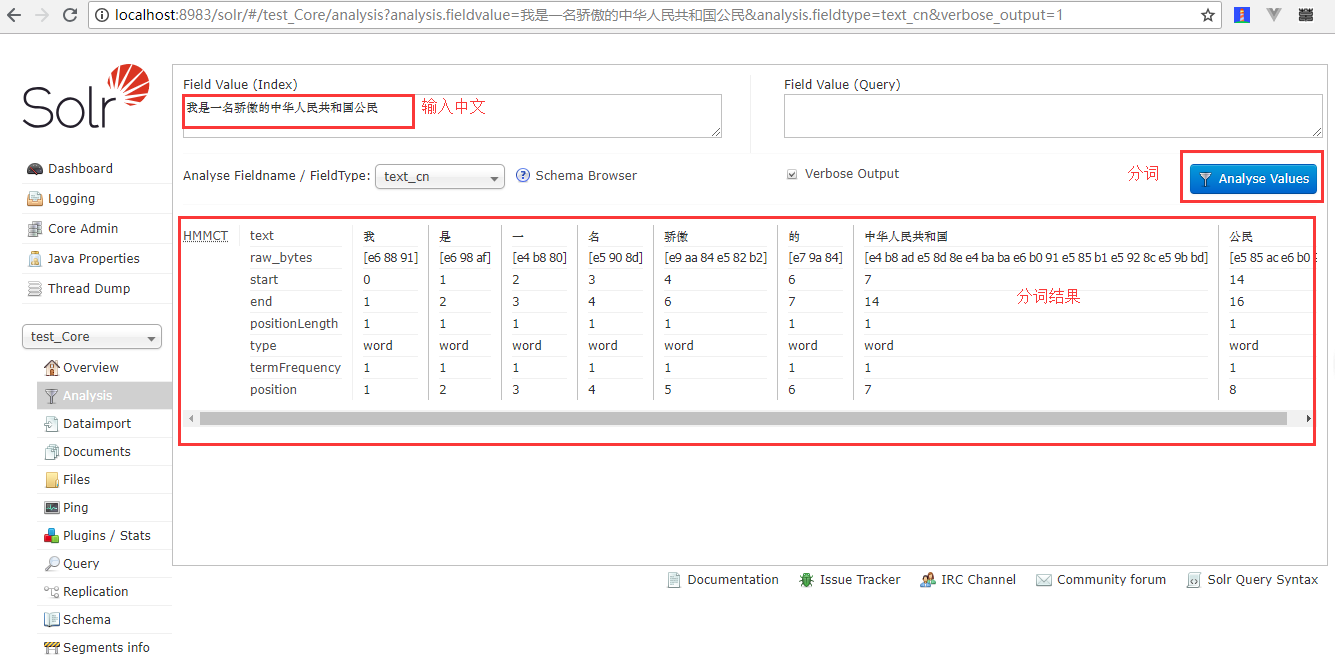
测试中文分词器:
6 、配置中文分词器 IK-Analyzer-Solr7
适配最新版solr7,并添加动态加载字典表功能;
在不需要重启solr服务的情况下加载新增的字典。
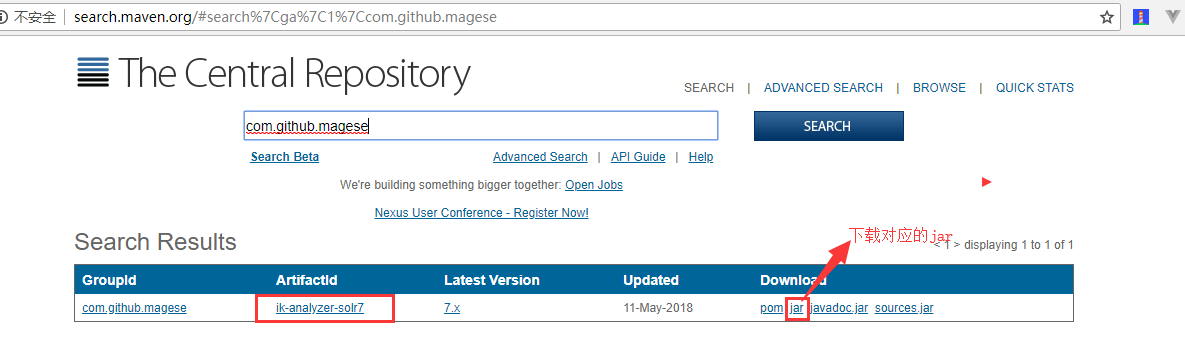
分词器GitHub源码地址:https://github.com/magese/ik-analyzer-solr7
GitHub上有分词器的使用方式
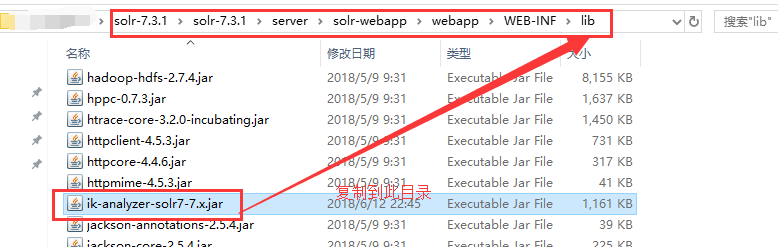
将下载好的jar包放入solr-7.3.1/server/solr-webapp/webapp/WEB-INF/lib目录中
然后到solr-7.3.1/server/solr/test_Core/conf目录中打开managed-schema文件,添加如下配置
<!-- ik分词器 --> <fieldType name="text_ik" class="solr.TextField"> <analyzer type="index"> <tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType> 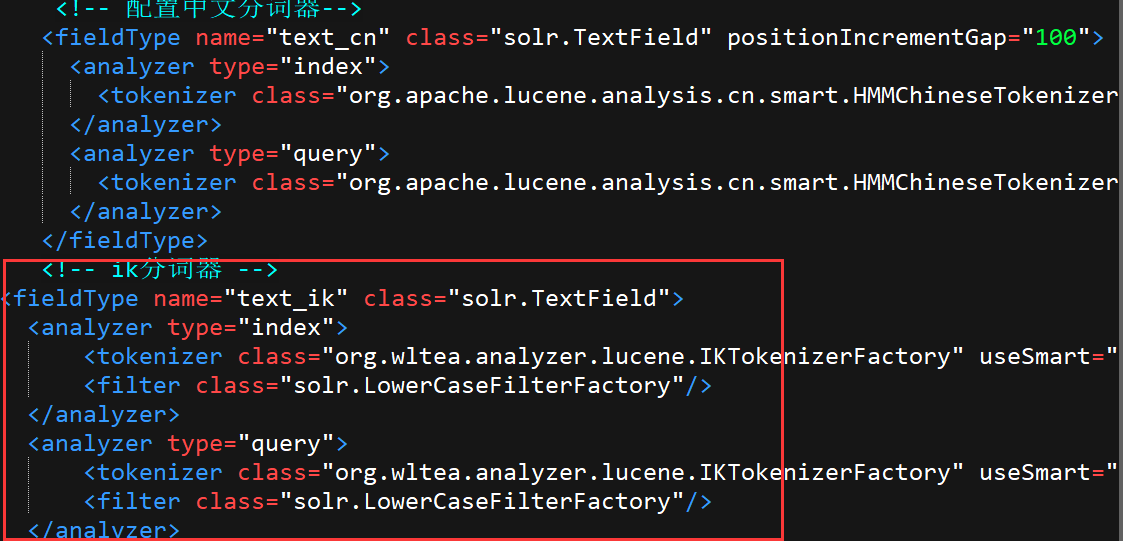
将gitHub下载的原码下的resources目录下的5个配置文件放入solr服务的jetty或tomcat的webapp/WEB-INF/classes/目录下(如果WEB-INF下没有classes目录,则自己手动创建);
①IKAnalyzer.cfg.xml
②ext.dic
③stopword.dic
④ik.conf
⑤dynamicdic.txt
ext.dic为扩展字典;

stopword.dic为停止词字典;
IKAnalyzer.cfg.xml为配置文件。
每个词单独成一行
配置完成后再次重启一次solr服务
分词测试
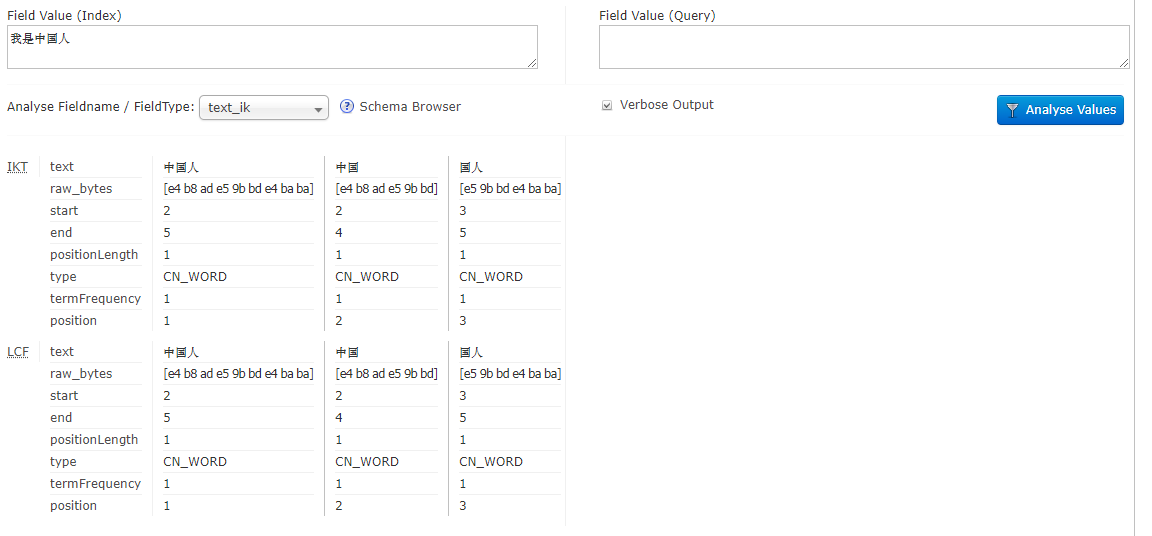
对于我,是,没有再出现(因为在stopword.dic停用词词典中进行了配置)。
至此。Solr配置完成。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/111283.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...