大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
舆情系统 中数据采集是一个关键部分,此部分核心技术虽然由爬虫技术框架构建,但抓取海量的互联网数据绝不是靠一两个爬虫程序能搞定,特别是抓取大量网站的情况下,每天有大量网站的状态和样式发生变化以后,爬虫程序能快速的反应和维护。
一旦分布式的爬虫规模大了以后会出现很多问题,都是种种技术挑战,会有很多门槛,例如:
1.检测出你是爬虫,拉黑你IP(人家究竟是通过你的ua、行为特则还是别的检测出你是爬虫的?你怎么规避?)
2人家给你返回脏数据,你怎么辨认?
3对方被你爬死,你怎么设计调度规则?
4要求你一天爬完10000w数据,你一台机器带宽有限,你如何用分布式的方式来提高效率?
5数据爬回来,要不要清洗?对方的脏数据会不会把原有的数据弄脏?
6对方的部分数据没有更新,这些未更新的你也要重新下载吗?怎么识别?怎么优化你的规则?
7数据太多,一个数据库放不下,要不要分库?
8对方数据是JavaScript渲染,那你怎么抓?要不要上PhantomJS?
9对方返回的数据是加密的,你怎么解密?
10对方有验证码,你怎么激活成功教程?
11对方有个APP,你怎么去得到人家的数据接口?
12数据爬回来,你怎么展示?怎么可视化?怎么利用?怎么发挥价值?
13等等…
在大规模互联网数据采集时,必须要构建一个完整的数据采集系统。否则,你的项目开发效率和数据采集效率会很低下。同时,还会很多让你意想不到的问题发生。
开源舆情系统
目录
在线体验系统
- 环境地址:http://open-yuqing.stonedt.com/
- 用户名:13900000000
- 密码:stonedt
开源技术栈
- 开发平台:Java EE & SpringBoot
- 爬虫框架:Spider-flow & WebMagic & HttpClient
- APP爬虫:Xposed框架
- URL仓库:Redis
- web应用服务器:Nginx&Tomcat
- 数据处理和储存任务发送:Kafka&Zookeeper
- 抓取任务发送:RabbitMQ
- 配置管理:MySQL
- 前端展示:Bootstrap & VUE
总体架构
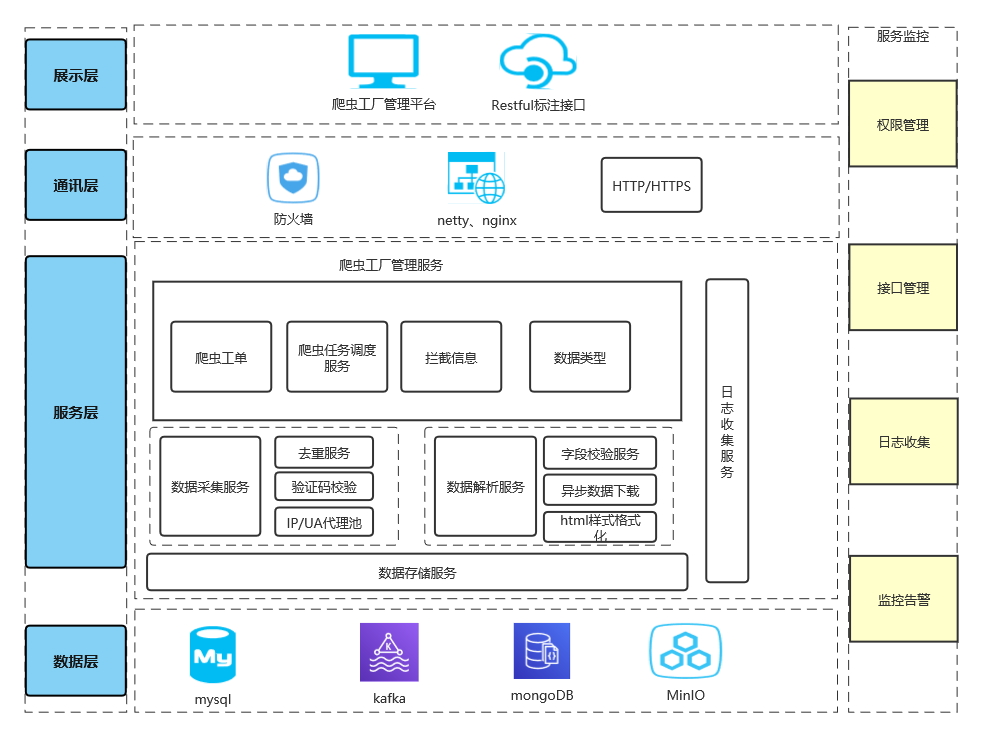

(这是最早期系统架构图)
数据处理流程
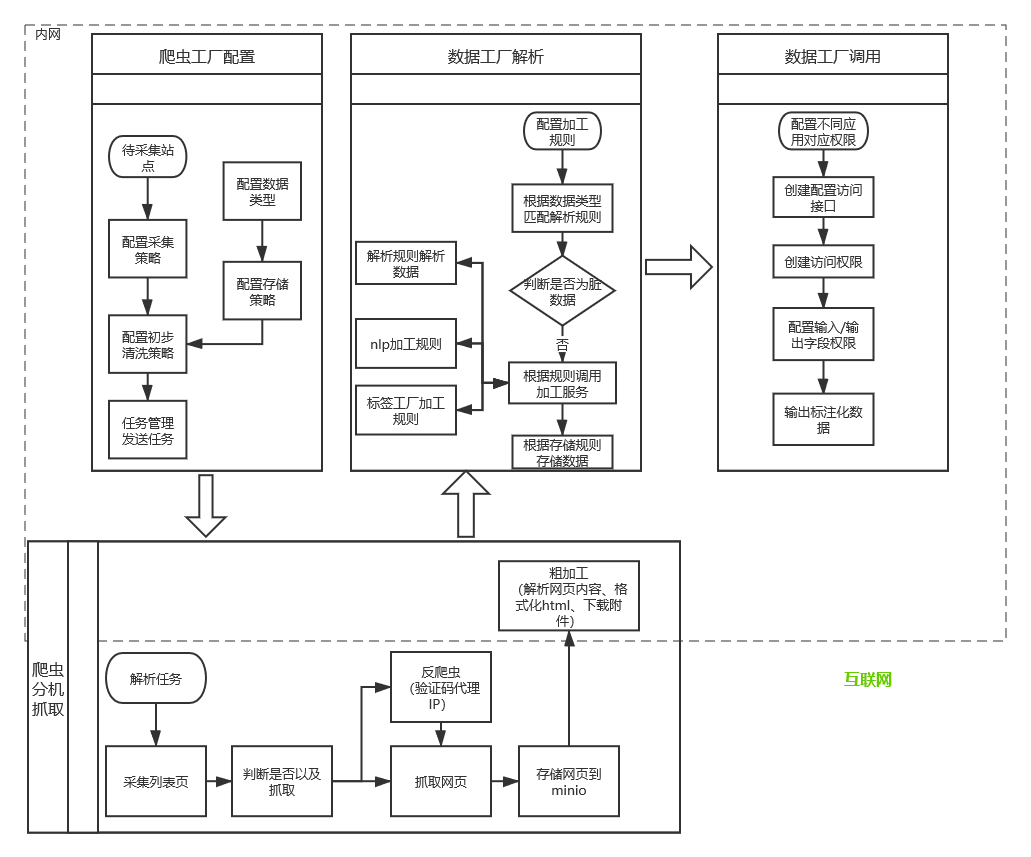
(这是最早期系统设计图)
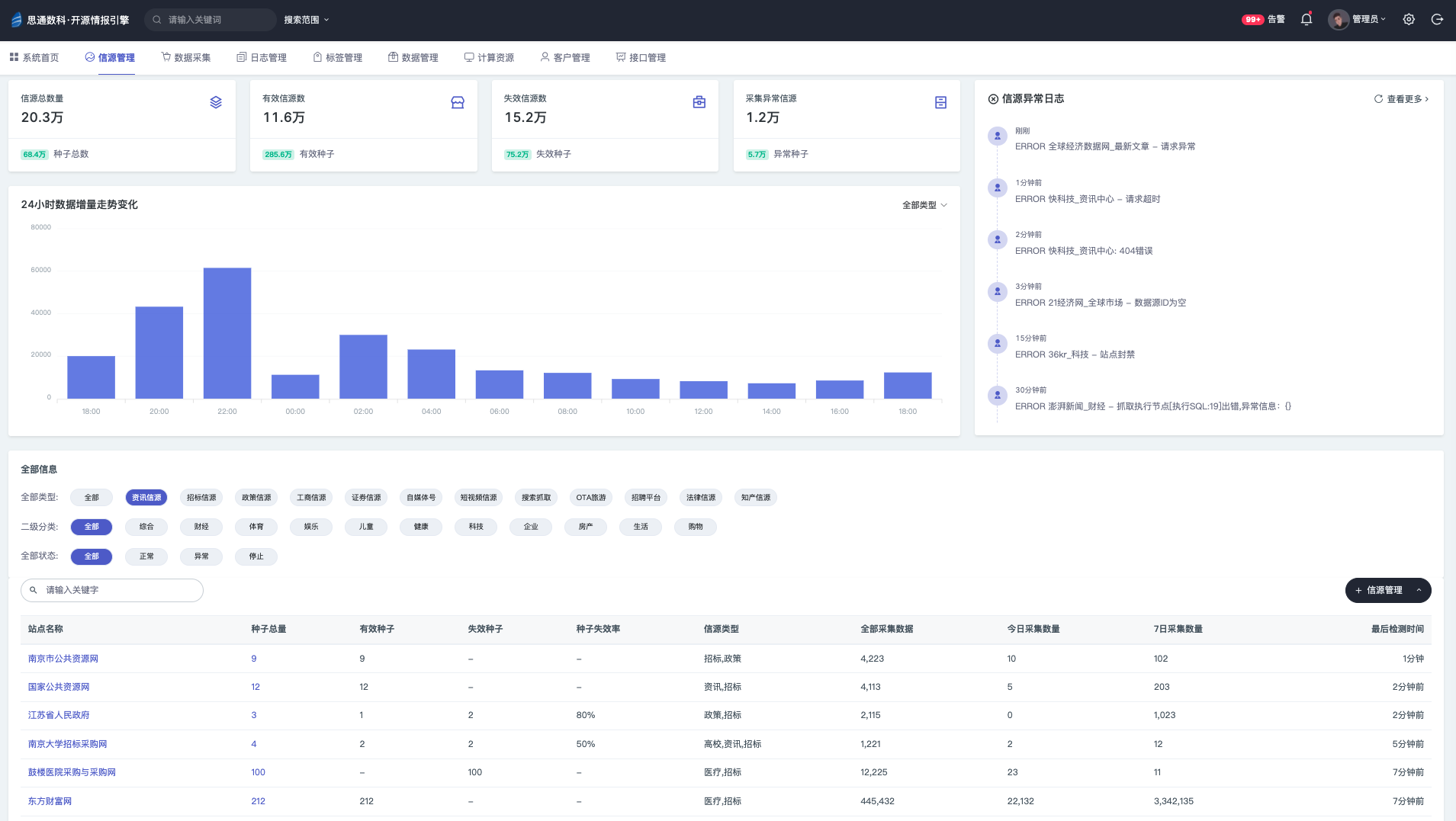
信源管理
信源,信息来源的简称。
我们需要对采集 类型,内容,平台,地区 等多种属性进行管理。我们对此开发了三代信源管理平台。
一代产品形态
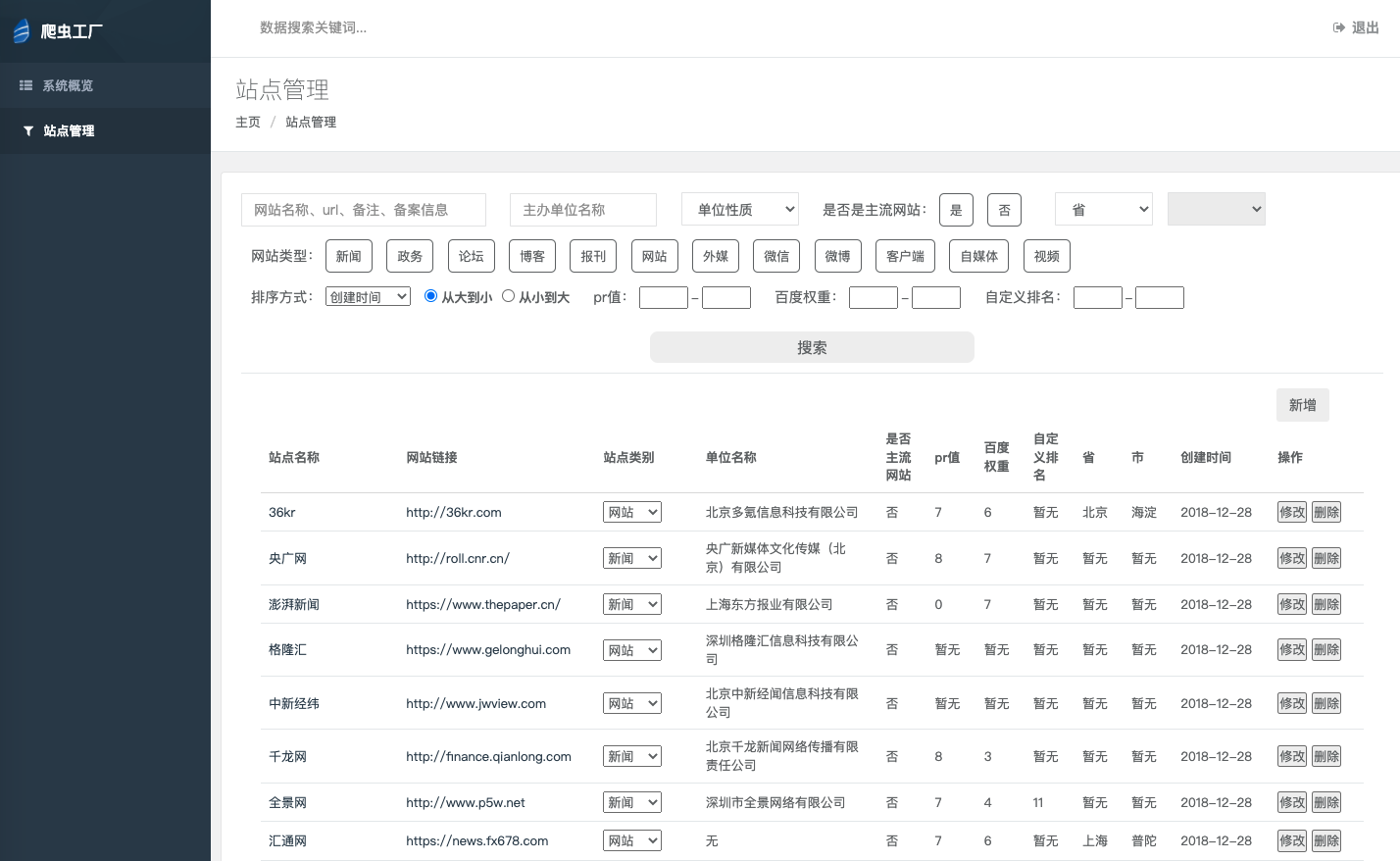
二代产品形态
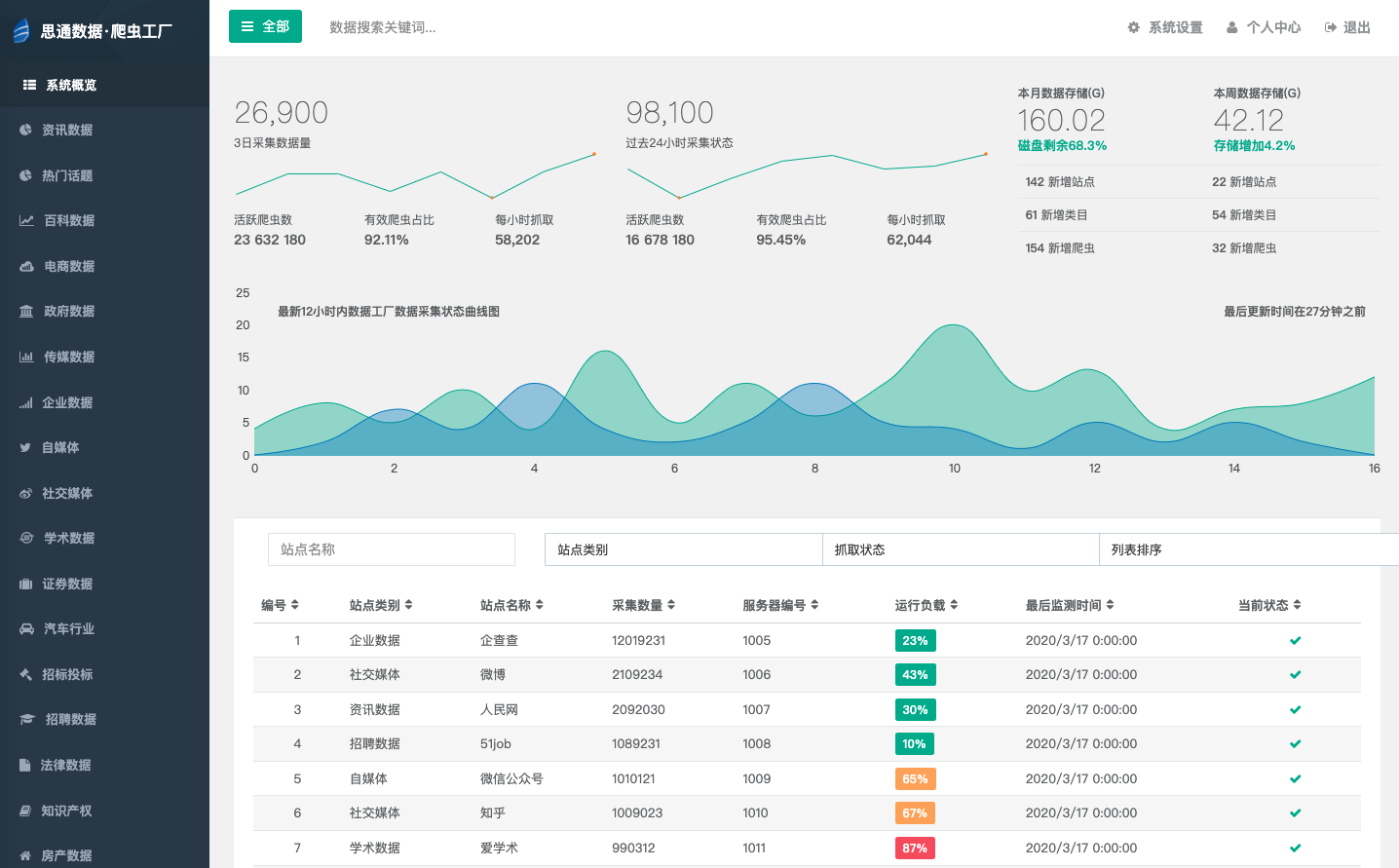
三代产品形态
站点画像
采用模拟浏览器请求技术实现深度和广度抓取算法,总体分3个环节,对整个站点进行 1)全站扫描、2)数据储存、3)特性分析。
-
siteMeta
识别整个网站的结构,并且解析存储,给每一个抓取的网站都建立一个“小档案”库。
-
siteIndex
在识别基础上把所有网页都预存储下来,并且提取各种特征值进行分析计算,从站点目录,到站点栏目,以及每个抓取目标页面都会标记不同的特性参数。
-
siteFeatures
最后将整体分析演算的结果,还原成这个网站的抓取画像和特性,以便于机器将会知道采用哪种抓取策略自动去匹配这个网站的特性抓取,基于这样的设计可以实现大规模数据采集无人值守的效果,也就是百度、谷歌 这些大型搜索引擎实现的数据效果。用“探头机器人”对整个网站预抓取一遍,相当于一个先头部队,把抓取网站的情况搞清楚以后,很快机器就知道采取哪种采集策略,大量需要采集的网站,只有极小的部分需要人工干预采集,而且更不需要编写一行爬虫采集代码,完全是自动化及低代码化大规模数据采集。
数据抓取
-
自动抓取
有了网站的画像属性,就知道匹配那种采集抓取策略了,大部分网站就能自动抓取就自动识别抓取数据,无需人工干预。 -
人工配置
有的网站抓取难度大,采用可视化技术将整个站点的标签提取出来给开发工程师,他们将可以快速的对网站的抓取进行配置。 我们在采集任何一个网站的时候将会有各种“探头”对网站的结构,广告位,关键性内容,导航栏,分页,列表,站点特性,站点数据量,抓取难易度,站点更新频率,等等。
- 采集模板
为了简化人工操作,提高工作效率,我们还提供了爬虫模板。爬虫模板的意义在于,用户遇到一个配置繁琐的站点,不用从头开始,只需要到爬虫模板库里面找类似的模板即可,如图所示: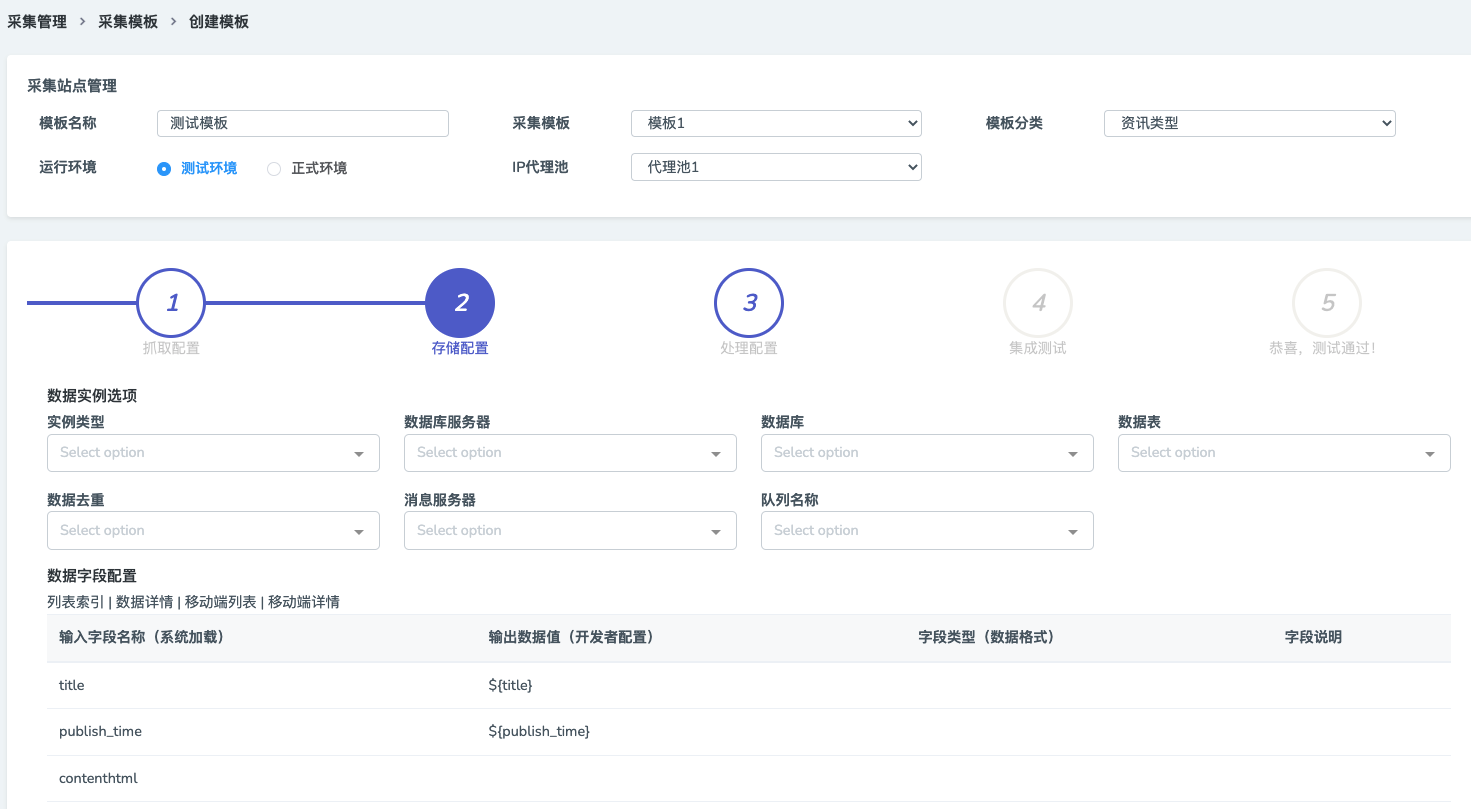
数据暂存
- 暂存
如果把数据直接储存到系统大数据库里,一旦有大量采集的脏数据下来就是浪费时间和精力,所有数据都会预演储存一遍,储存完成后会有程序对此核对监测,以免数据字段漏存,错存。 - 预警
如果在暂存环节发现储存错误,将会及时通过邮件发送对研发工程师提醒,告知错误内容,让其对此修正。
低代码开发
-
配置
目前的爬虫工厂已经一个低代码化开发的平台了,更准确的说,我们不是在上面开发,而且在上面进行爬虫配置对数据采集抓取。如图所示: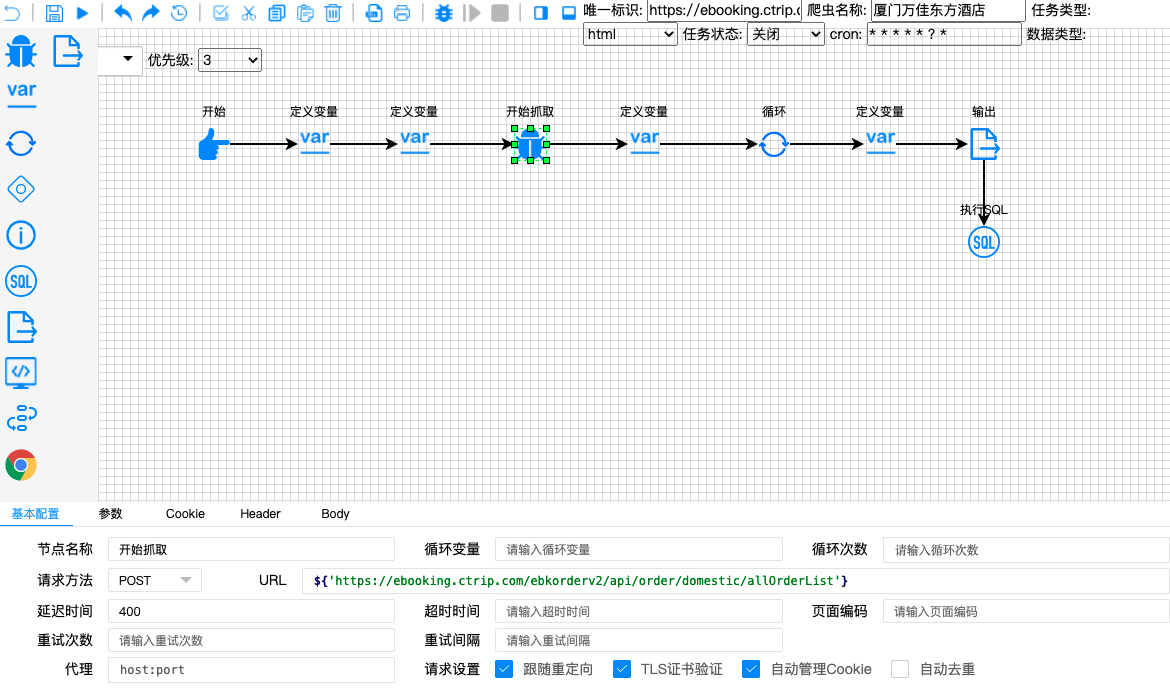
-
维护
通过低代码的方式的开发,我们对爬虫的维护更加方便,只需要在web管理界面中,修改爬虫抓取配置即可,同时还可以在线调试,查看具体的抓取错误日志。否则某一个站点抓取出现问题,都不知道是哪台服务器上的哪个爬虫抓取错误。各种站点爬虫的量一旦大起来,维护成本极高。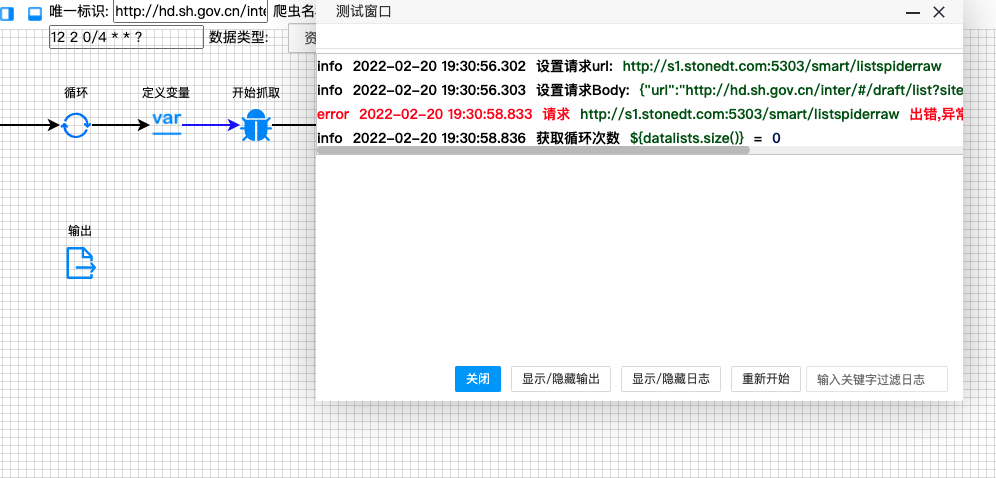
分布式采集
-
控制器(master)
爬虫工厂有一个web控制管理后台,开发者可以在上面添加需要采集的任务计划和数据采集抓取的规则策略,控制器只对采集任务下发抓取指令,不做任何抓取操作。
-
分发器(dispatch)
控制器(master)通过rabbitMQ消息将抓取的任务下发给任何一台执行端, 消息中包含抓取的策略指令及采集目标,分发器只管发送指令和策略。
-
执行器 (downloader)
执行端可以部署在全世界任何一台能连接互联网的机器上,只要这台机器能上网,能接受分发器下发的采集任务 就能把数据采集下来,同时把采集的数据回传给中央数据仓库。
爬虫管理
-
爬虫状态
爬虫分布式在很多台服务器上,不知道在哪个服务器上的哪个爬虫程序出了问题是很痛苦的事情,甚至抓取数据量猛增导致服务器挂掉都不知道。所以,需要能对服务器监控,对服务器上每一个爬虫程序进行监控。监控每个爬虫运行是否正常,监控每个运行爬虫的服务器是否正常。
-
采集状态
抓取的站点时常发生变化,我们就需要知道每个目标采集的站点抓取的数据是否都正常的采集下来了,通过给每个爬虫编上采集任务编号,展示在web界面上,就可以直观的看见数据采集下来的效果。通过邮件告警和每天发送邮件统计数据,可以实时对采集状态进行监控。
采集分类
-
网站采集
一般采取两种模式,直接http请求查看HTML代码;另一种是模拟浏览器技术,把请求的JS渲染结果还原成HTML代码,找到HTML标签和URL路径进行抓取。
-
公众号采集
目前基本上就两个路径:通过搜狗微信 和 通过公众号管理后台。但是这两个都封的实在太厉害了,经过多种尝试采用RPA的模式模拟请求人工的操作+代理IP地址,对公众号数据抓取。但是同时需要有大量的微信公众号,因为,这种抓取方法是根据公众号的号进行采集的,没有公众号就不知道抓取的目标。
-
app 采集
之前采用在开发环境的电脑上搭建一个WIFI共享让手机APP连接电脑就能看见传输的数据了。目前app的数据采集代价越来越高,上档次的APP几乎没有不加密的。所以,采用Xposed框架对数据采集是最稳定的采集方案了。
反爬策略
-
模拟请求头
专门有一个数据表记录存储及更新各种浏览器请求的模拟请求头,例如:Host、Connection、Accept、User-Agent、Referrer、Accept-Encoding、Accept-Language 等各种组合请求头参数。
-
代理IP池
光是有代理IP是不够的,一般稳定的ip池都很贵,而且代理IP资源对于需要采集的数据源来说永远是匮乏的。换句话说,就需要能充分的利用好代理IP资源。主要实现两大功能:1)实时检查代理IP的有效性,抛弃无效的IP,提高爬虫 请求效率。2) IP_1抓取过 A_网站被封掉了,但是不代表IP_1马上抓取 B_网站和N_网站也会被封掉,这样就充分的利用了代理IP。
采集日志
-
日志收集
系统采用了一台独立强劲的服务器专门做日志处理的服务器。这台服务器收集来自四面八方爬虫执行端和各个不同电信机房传输过来的错误日志信息。每个应用程序通过logback的kafak插件,写入消息队列,再批量写入专门的 Elasticsearch 日志分析服务器。
-
跟踪ID
为了能更加有效对问题排查,我们从抓取请求开始到数据存储完毕。系统就给每个作业打上了唯一的日志标号,这样的话,无论中间出了什么问题,上一步做了什么操作,执行了什么程序,都能有效的跟踪和追溯。
-
日志分析
通过数据分析能看出目前哪类采集的数据有问题,当天或者这段时间内大面积的问题主要集中在什么地方,以及具体是哪些网站出了问题,这些抓取出问题的网站是不是重点关注的对象,等等。从面到点的去分析问题。
数据解析
-
自动解析
自动解析主要是用于资讯、招标、招聘,系统采用文本密度算法实现。因为这3个类型的数据虽然大致相同,但是网站多了以后还是千差万别。如果依靠人工的方式一个个配置或者编写代码,将会是一场灾难。
-
手动解析
只有在机器无法自动识别的情况下,采用人工配置,将网页上的字段一一对应的填写到低代码爬虫开发平台。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/191641.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
